
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 56
56
 4
4


过去几年,大语言模型 (LLM) 的进程主要由训练时计算缩放主导。尽管这种范式已被证明非常有效,但预训练更大模型所需的资源变得异常昂贵,数十亿美元的集群已经出现。这一趋势引发了人们对其互补方法的浓厚兴趣, 即推理时计算缩放。推理时计算缩放无需日趋庞大的预训练预算,而是采用动态推理策略,让模型能够对难题进行“更长时间的思考”。最著名的案例是 OpenAI 的 o1 模型,随着推理时计算量的增加,该模型在数学难题上获得了持续的改进

尽管我们无从得知 o1 是如何训练的,但 DeepMind 最新的研究表明,使用迭代式自完善或让奖励模型在解空间上搜索等策略,可以较好地实现优化推理时计算缩放。通过根据提示自适应地分配推理时计算,较小的模型可以与更大、更耗资源的模型相媲美,有时甚至优于它们。当内存受限或可用硬件不足以运行更大的模型时,缩放推理时计算尤其有利。然而,目前所有对于该方法的效果报告都是基于闭源模型的,并且没有公开任何实现细节或代码😢.
过去几个月,我们一直在深入尝试逆向工程这些报告并成功重现了其中的一些结果,现在,我们很高兴向大家分享我们的收获。具体来说,本文将介绍
那么计算最优缩放实际效果如何呢?参见下图,如果你给够“思考时间”,小型的 1B 和 3B Llama Instruct 模型在颇具挑战性的 MATH-500 基准测试中的表现优于比其大得多的 8B 和 70B 大哥大姐 🤯

本文的剩余部分,我们将深入探讨该结果背后的要点,并向大家介绍一些在实现推理时计算缩放时的实用策略.
对推理时计算进行缩放主要有两种策略
本文,我们集中讨论基于搜索的方法,因为其实用且扩展性很好。特别地,我们将研究如下三种搜索策略
了解了主要的搜索策略后,我们继续讨论如何在实践中评估它们.

如上图所示,实验流水线如下
为了比较各种搜索策略,我们选用了下述开放模型及数据集
meta-llama/Llama-3.2-1B-Instruct 作为推理时计算缩放的主要模型。该模型仅 1B 参数,其轻量级特性可实现快速迭代,并且其在数学基准上的不饱和性能使其成为突出缩放优势的理想选择。RLHFlow/Llama3.1-8B-PRM-Deepseek-Data ,这是一个使用过程监督进行训练的 8B 奖励模型。过程监督是一种训练方法,模型会收到推理过程每一步的反馈,而不仅仅是对最终结果的反馈。我们选择这个模型是因为它与我们的策略属于同一模型系,并且效果比我们在此量级上测试的其他 PRM (例如 Math-Shepherd) 更好。MATH 基准的 MATH-500 子集作为评估数据集,该数据集由 OpenAI 发布,作为其过程监督研究的一部分。这些数学问题横跨七个数学模块,对人类和大多数 LLM 来说都颇具挑战性。你可以看看下面的数据集视图,体会一下问题的难度!
数据集地址: https://hf.co/datasets/HuggingFaceH4/MATH-500 。
我们为每个提示生成 1 到 256 个补全,以测试不同的计算预算下的每种搜索策略的表现,并使用五个随机种子分别运行每个实验以估计其性能方差。你可以在 此处 找到我们使用的模型和数据集.
我们先热个身,从一个简单的基线开始,并逐步将各种技术加入进来以提高性能.
多数投票 —— 如果想要时髦一点,你也可以叫它自洽解码 —— 是聚合 LLM 输出的最直接的方法。顾名思义,对于给定的数学问题,我们生成 \(N\) 个候选解并选择出现次数最多的那个作为最终答案。所有的实验,我们都设温度 \(T=0.8\),采样数 \(N=256\),每个问题的最大生成词元数为 2048.
MATH 基准测试的一个奇特要求是: 答案必须写在 LaTeX 框中 (例如 \boxed{answer} )。起初,我们对 Llama 3.2 1B 尝试了以下简单的系统提示
Please think step by step and put your final answer within \boxed{}. 。
但很快发现贪心解码 (\(T=0\)) 的准确度远低于 Meta 报告的 30.6%。幸运的是,Meta 还发布了他们使用的提示,我们就把系统提示换成他们的,一切就大为改观
Solve the following math problem efficiently and clearly:
- For simple problems (2 steps or fewer):
Provide a concise solution with minimal explanation.
- For complex problems (3 steps or more):
Use this step-by-step format:
## Step 1: [Concise description]
[Brief explanation and calculations]
## Step 2: [Concise description]
[Brief explanation and calculations]
...
Regardless of the approach, always conclude with:
Therefore, the final answer is: $\boxed{answer}$. I hope it is correct.
Where [answer] is just the final number or expression that solves the problem.
评估数学问题答案的一个微妙之处是: 如何处理像 \(1/\sqrt{3}\) 和 \(\sqrt{3}/3\) 这样字符串不同但数学上等效的答案。标准方法是将一对答案转换为 SymPy 对象,然后让这两个对象相减并使用 sympy.simplify 判断其结果是否为零.
这种方法在候选答案较少时效果很好,但我们发现当 \(N\) 变大时,对候选答案列表中的每一对进行比对速度会非常慢; 在某些情况下,比一开始生成候选答案还要慢!为了解决这个问题,我们首先将每个答案简化为其规范式,然后对每种规范式的票数进行计数以确定多数票。如果你对代码感兴趣,可以展开以下实现细节.
实现细节 。
为了获取代数表达式的规范式,我们首先将 LaTeX 字符串转换为 SymPy ,调用 sympy.simplify ,最后转回 LaTeX
from latex2sympy2 import latex2sympy
from sympy import latex, simplify
def get_canonical_form(expression: str) -> str:
parsed_expr = latex2sympy(expression)
simplified_expr = simplify(parsed_expr)
return latex(simplified_expr)
通过这个函数,我们可以迭代列表中的所有候选解,并对每个规范式出现的次数进行计数,最后计算最终多数票
def find_majority_answer(answers: List[str]) -> str:
canonical_groups = defaultdict(int)
canonical_to_original = {}
for answer in answers:
canonical_form = get_canonical_form(answer)
# Increment count for the canonical form
canonical_groups[canonical_form] += 1
# Track the original answer for this canonical form
if canonical_form not in canonical_to_original:
canonical_to_original[canonical_form] = answer
# Find the canonical form with the largest count
max_count = max(canonical_groups.values())
for canonical_form, count in canonical_groups.items():
if count == max_count:
# Return the first occurring group in case of a tie
return canonical_to_original[canonical_form]
这种方法比对候选解进行两两对比要快得多.
以下是多数投票策略在 Llama 3.2 1B Instruct 上的表现

结果表明,多数投票相对于贪心解码基线有显著改进,但其增益在大约 \(N=64\) 后开始趋于稳定。出现这种现象的原因是多数投票难以解决需要细致推理的问题以及各候选答案出现一致错误的情形。此外你可能还注意到多数投票准确性比 \(N=1\) 和 \(N=2\) 的 0-样本 CoT 基线差,这是因为我们的采样温度为 \(T=0.8\),这使得我们不太可能在少量几个结果中得到正确候选答案.
了解了多数投票的局限性,我们看看加入奖励模型后效果如何.
拔萃法对多数投票进行了简单而有效的改进,它使用奖励模型来确定最合理的答案。该方法有两种主要变体
朴素拔萃: 生成 N 个独立答案,并选择 RM 得分最高的作为最终答案。该方法确保了最终选择最有信心的响应,但并没有考虑到答案之间的一致性.
加权拔萃: 对所有相同答案的分数进行累加,再选择总分最高的答案。这种方法奖励重复出现的答案,从而提高高质量答案的优先级。从数学上讲,答案 \(a\) 的加权得分如下
其中 \(RM(p,s_i)\) 是问题 p 的第 i 个候选解 \(s_i\) 的奖励模型得分.
通常,人们使用结果奖励模型 (ORM,outcome reward model) 来获得某个解的分数。但为了与稍后讨论的其他搜索策略进行公平比较,我们使用相同的 PRM 对拔萃法的解进行评分。如下图所示,PRM 为每个解按步骤生成一个累积的分数序列,因此我们需要对步骤进行归约以获得整个解的得分

在文献中,最常见的归约如下
我们对每一个归约方法都进行了实验,我们的结论与 DeepMind 一致,即“最终分”在我们的任务上与 PRM 配合表现最好。因此,后面得所有实验,我们都用了该归约.
以下是使用拔萃法的两种变体得到的结果
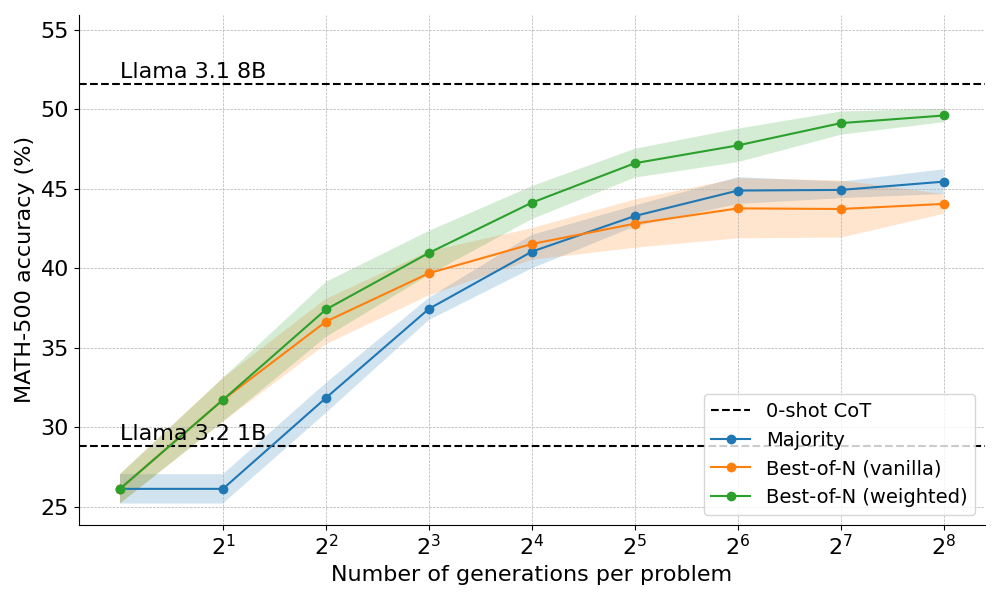
结果表明: 加权拔萃法始终优于朴素拔萃法,尤其是在计算预算较高的情况下。其能够汇总相同答案的分数,同时确保频率较低但质量较高的答案也能得到有效的优先处理.
然而,尽管有这些改进,我们仍然达不到 Llama 8B 模型的性能,并且拔萃法在 \(N=256\) 时开始趋于饱和。可以通过逐步监督搜索过程来进一步突破界限吗?我们继续吧🚀! 。
波束搜索是一种结构化的搜索方法,可以系统地探索解空间,这让它成为在推理时改进模型输出的强大工具。与 PRM 结合使用时,波束搜索可以优化解题中间步骤的生成和评估。其工作方式如下
\n 或双新行 \n\n 时终止。通过允许 PRM 评估中间步骤的正确性,波束搜索可以在流程早期识别并优先考虑有潜力的路径。这种逐步评估的方式对数学等复杂推理任务特别有用,对部分解进行验证可以显著改善最终结果.
实现细节 。
在我们实现基于流程监督的波束搜索时,我们遇到了与 Llama 3 聊天模板相关的问题,如下
\n 或 \n\n 来终止一个中间步骤,这些词元会在后续步骤中丢失,这会导致模型产生奇怪的输出。Llama 的 BOS 词元为前缀。当将格式化后的字符串输入给 vLLM 时,vLLM 还会再加一个 BOS 词元,这会导致效果变差,尽管大多数情况下输出是一致的🤯。解决方案是覆盖 Llama 3 聊天模板以防止其删新行,并避免重复 BOS 前缀.
在实验中,我们选择了跟 DeepMind 相同的超参并使用以下配置运行波束搜索
如下所示,结果相当惊人: 在 \(N=4\) 的推理时预算下,波束搜索的精度与拔萃法在 \(N=16\) 时的精度相同,即计算效率提高了 4 倍!此外,在 \(N=32\) 时,波束搜索与 Llama 3.1 8B 的性能相当。考虑到计算机专业的博士生的数学平均成绩约为 40%,因此近 55% 的得分对 1B 模型来讲相当不错了 💪! 。

尽管总的来说,波束搜索显然比拔萃法或多数投票表现更好,但 DeepMind 论文表明,每种策略都有其舒适区,具体取决于问题难度和推理时的计算预算.
为了了解哪些问题和哪种策略最配,DeepMind 对问题难度的分布进行了统计,并将结果分成五个等级。换句话说,每个问题都被分配至 5 个等级中得一个等级,其中等级 1 表示最简单的问题,等级 5 表示最难的问题。为了对问题的难度进行估计,DeepMind 对每个问题进行标准采样,生成了 2048 个候选解,并提出了以下启发式方法
以下是各方法在 \(N=[4,16,64,256]\) 这四个推理时计算预算上及各等级问题上的 \(pass@1\) 得分表现

图中,每个柱子表示一个推理时计算预算,并且在每个柱子中我们用不同颜色显示了每种方法的准确度。例如,在难度等级 2 的四个柱子中,我们看到
尽管我们看到波束搜索在中等和困难问题 ( 3-5 级) 中均表现较佳,但在较简单的问题上,尤其是在计算预算较大的情况下,其表现往往逊于拔萃法 (甚至逊于多数投票!).
通过观察波束搜索生成的结果树,我们意识到,如果某一中间步骤得到了高分,那么整个树就会围绕该中间步骤生成,从而影响最终解的多样性。这促使我们探索改进波束搜索,以最大限度地提高多样性 —— 请看下文! 。
正如上文所述,波束搜索比拔萃法性能更好,但在更简单的问题上以及大推理时计算预算时却表现不佳。为了解决这个问题,我们开发了一个称为多样化验证器树搜索 (DVTS,Diverse Verifier Tree Search) 的改进算法,旨在最大限度地提高大 \(N\) 时的多样性.
DVTS 的工作方式与波束搜索类似,改进点如下
以下是将 DVTS 应用于 Llama 1B 的结果

如你所见,DVTS 提供了波束搜索的补充策略: 在 \(N\) 较小时,波束搜索能更有效地找到正确解; 但在 \(N\) 较大时,DVTS 所带来的候选多样性开始发挥作用,并获得了更好的表现.
我们还可以从下图中看到,DVTS 增强了大 \(N\) 时简单/中等问题的性能,而波束搜索在各难度等级的小 \(N\) 时效果最好

有了各种搜索策略,一个自然的问题是哪一个最好?在 DeepMind 论文中,他们提出了一种计算最优缩放策略,它可以帮助我们选择搜索方法和超参数 \(\theta\),以在给定的计算预算下获得最佳性能.
其中 \(y^*(q)\) 是问题 \(q\) 的解,\(\theta_{q,a^*(q)}^*(N)\) 表示计算最优缩放策略。由于直接计算 \(\theta_{q,a^*(q)}^*(N)\) 有点棘手,因此 DeepMind 提出了一种基于问题难度的近似方法,即根据在给定难度等级的情况下哪个搜索策略性能最佳来分配推理时计算.
举个例子,对于简单问题和较低的计算预算,最好使用拔萃法等策略,而对于难题,波束搜索是更好的选择。为了实现这一点,我们计算出了给定难度级别和推理时计算预算时每种方法的准确度。瞧,我们现在有了计算最优曲线! 。
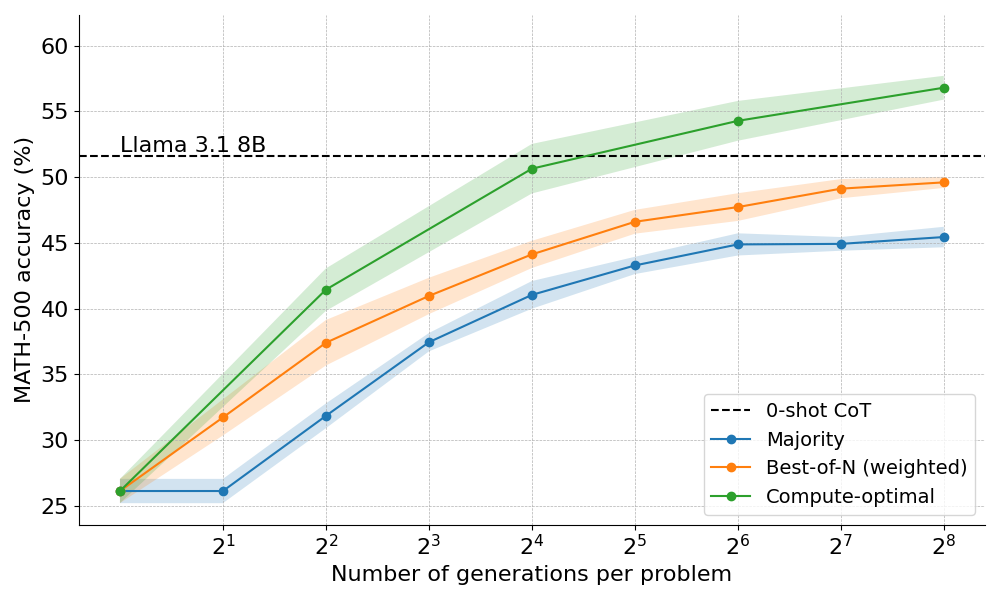
我们还探索了将上述计算最优策略扩展到 Llama 3.2 3B Instruct ,以了解与策略本身的能力相比,PRM 的优势在什么时候会减弱。令我们惊讶的是,计算最优缩放效果非常好,3B 模型的性能超越了 Llama 3.1 70B Instruct (大小为 22 倍!)

对推理时计算缩放的探索揭示了基于搜索的方法的潜力和挑战。展望未来,有不少令人兴奋的方向
强验证器的力量
强大的验证器在提高性能方面发挥着关键作用。然而,正如 ProcessBench 等基准测试所表明的,当前验证器模型有比较明显的局限性。提高验证器的鲁棒性和泛化性对于推进该路线至关重要.
自验证的挑战
最终目标 (或“圣杯”) 是实现自验证,模型可以自主验证自己的输出。这种方法似乎是 o1 等模型正在做的事情,但在实践中仍然很难实施。与标准的有监督微调 (SFT) 不同,自验证需要更细致的微调策略。 DeepMind 最近发表的关于自验证及评分的论文揭示了这一挑战,并为未来的研究提供了途径.
在过程中“思考”
在生成过程中纳入明确的中间步骤或“思考”,可以进一步增强推理和决策。通过将结构化推理集成到搜索过程中,我们可以在复杂任务上获得更好的性能.
搜索作为数据生成工具
搜索还可以用作强大的数据生成工具,以创建高质量的训练数据集。例如,根据搜索产生的正确轨迹对 Llama 1B 等模型进行微调可以产生显著的收益。这种同策方法类似于 ReST 或 V-StaR 等技术,但搜索带来了更大的优势,其为迭代式改进带来了新的希望.
呼吁开发开放更多 PRM
开放的 PRM 相对较少,限制了其更广泛的应用。为不同领域开发和分享更多 PRM 是社区可以做出重大贡献的关键领域.
扩展到可验证领域之外
虽然当前的方法在数学和代码等领域表现出色,这些领域的解本质上是可验证的,但将这些技术扩展到其他领域仍然是一个重大挑战。我们如何调整这些策略来应对结构化程度较低的或主观性的任务?这是未来探索的一个重要议题.
感谢 Charlie Snell 和 Aviral Kumar 就推理时计算缩放进行的多次讨论,并向我们分享了他们工作中的实现细节。我们感谢 Chun Te Lee 设计了可爱的横幅,感谢 Thomas Wolf、Leandro von Werra、Colin Raffel 和 Quentin Gallouédec 为改进博文提供了许多有用的建议。我们还感谢 Hugo Larcher 和 Mathieu Morlon 不断优化 Hugging Face Science 集群,使 GPU 变得更快 🔥! 。
如引用本文,请按如下方式引用
Beeching, Edward, and Tunstall, Lewis, and Rush, Sasha, "Scaling test-time compute with open models.", 2024.
BibTeX 引用 。
@misc{beeching2024scalingtesttimecompute,
title={Scaling test-time compute with open models},
author={Edward Beeching and Lewis Tunstall and Sasha Rush},
url={https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute},
}
英文原文: https://hf.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute 。
原文作者: Edward Beeching, Lewis Tunstall, Sasha Rush 。
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理.
最后此篇关于基于开放模型的推理时计算缩放的文章就讲到这里了,如果你想了解更多关于基于开放模型的推理时计算缩放的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
56
4
 0
0
我在 div 和 jquery ui slider 中有一个图像列表,当用户滑动栏时,图像应该调整大小/缩放(无论你想怎么调用它),我尝试选择所有图像并更改 css 的宽度和使用 jquery 的高度
我正在制作一张具有缩放和平移功能的世界地图。我在某些城市上画了圆圈,圆圈的半径由数据决定。当鼠标悬停在这些圆圈上时,将出现一个工具提示来显示数据。 代码结构为 //在此选择上调用缩放行为 - 让我们调
我正在使用 jquery UI slider (http://jqueryui.com/slider/)。 我需要对整个站点进行缩放。使用 css 样式在 IE+Chrome im 中缩放 - “缩放
我花了很多时间试图找到一种使用 CGAffineScale 将 View 转换为给定点的方法,包括摆弄 anchor 、在转换前后移动 View 的中心以及全面的谷歌搜索。我知道使用 UIScroll
我希望能够用手指旋转和缩放/缩放我的位图,我已经为此寻找了所有示例项目,但它们都与我的代码不匹配。这是我的 onTouchListener 代码。 public class MyView extend
在我的页面中间,我有一个 div 元素,其中包含一些内容(其他 div、图像等)。 before something inside another something
我一直在尝试使用 google maps API V3 的绘图管理器(绘制矩形)。使用 -webkit-transform 缩放谷歌地图 Canvas (包含 div)后像这样 var transf
这个问题在这里已经有了答案: How to resize the iPhone/iPad Simulator? (12 个答案) 关闭 5 年前。 我正在编写 iOS 应用 我使用 Xcode 6.
这几天一直在研究微服务,我想知道人们是如何着手自动化负载平衡和扩展这些东西的? 我心中有一个特定的场景,我想实现什么,但不确定是否可行,或者我的想法有误。就这样吧…… 假设我有一个由 3 台名为 A、
我正在使用 ffmpeg for android 来制作 mp4 格式的视频。我无法让这个命令在 FFMPEG 中工作,基本上我正在尝试添加两个图像,缩放它们,添加缩放效果,最后将结果连接到一个视频文
使用 OpenGL 我正在尝试绘制我校园的原始 map 。 谁能向我解释一下平移、缩放和旋转通常是如何实现的? 例如,通过平移和缩放,这仅仅是我调整我的视口(viewport)吗?所以我绘制并绘制了构
我需要在 iphone sdk 界面生成器中将按钮旋转 30 度,该怎么做? 最佳答案 您无法在 Interface Builder 中执行此操作,但代码非常简单。 确保您已将 IB 中的按钮连接到
假设默认级别等于“1”,是否可以检测触摸设备的捏合(缩放)级别?原因是我希望根据捏合级别禁用页面元素(显示:无)。 如果可以将其放在一个设置缩放级别值的函数中,那就太好了,例如: var ZOOM =
我正在努力找出并确定如何根据这个例子放大我的鼠标位置。 (https://stackblitz.com/edit/js-fxnmkm?file=index.js) let node, scal
我已将 UIWebView 的“scalesPageToFit”属性设置为 YES。 它正在缩放,但是当页面加载时,内容的字体很小,不捏就无法阅读。我们可以将缩放比例设置为默认值吗? 最佳答案 这更多
我仍在学习 jQuery mobile 的技巧,并且在 data-role="page"上放大和缩小图片/图像时遇到问题。有没有办法使用 jquery mobile 在 iPhone 上的图像上进行捏
给定一组 n 个维度为 d 的向量,存储在 (n,d) 数组中,以及第二组 m 相同维度的向量(存储在 (m,d) 数组中)我想计算向量之间的平方点距离,由大小为 的某个矩阵 A 缩放>(d,d)。
我想知道是否有人可以指出我正确的方向。 我使用 CSS3 过渡创建了缩放效果。将鼠标悬停在该对象上,它会转换为更大的版本。这看起来很棒并且效果很棒,但问题是这种效果在 IE 中不起作用,所以我需要在
mapbox-gl-js 版本:0.38.0在 ionic 2.2.11 上通过 npm repo 使用 正如您在这张 gif 上看到的 https://giphy.com/gifs/ionic-an
所以我花了几个小时在网上搜索帮助,但所有论坛和文档都没有向我正确解释我应该采取的最佳方式。 目前我有一个具有 XML 相对布局的 Activity (背景设置为 map 图片),我想实现多手势缩放功能

我是一名优秀的程序员,十分优秀!