
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 57
57
 4
4


动机(Data Level Parallelism,DLP):
SIMD 结构可有效地挖掘数据级并行:
基于矩阵运算的科学计算 。
图像和声音处理 。
...... 。
SIMD 比 MIMD 更节能 。
SIMD 允许程序员继续以串行模式思考 。
三种变体:
向量体系结构 。
SIMD/Multimedia 指令级扩展 。
Graphics Processor Units (GPUs) 。
对于X86处理器:
MIMD 每年增加2 cores/chip 。
SIMD 宽度每 4 年翻一番 。
SIMD 潜在加速比是 MIMD 的2倍 。

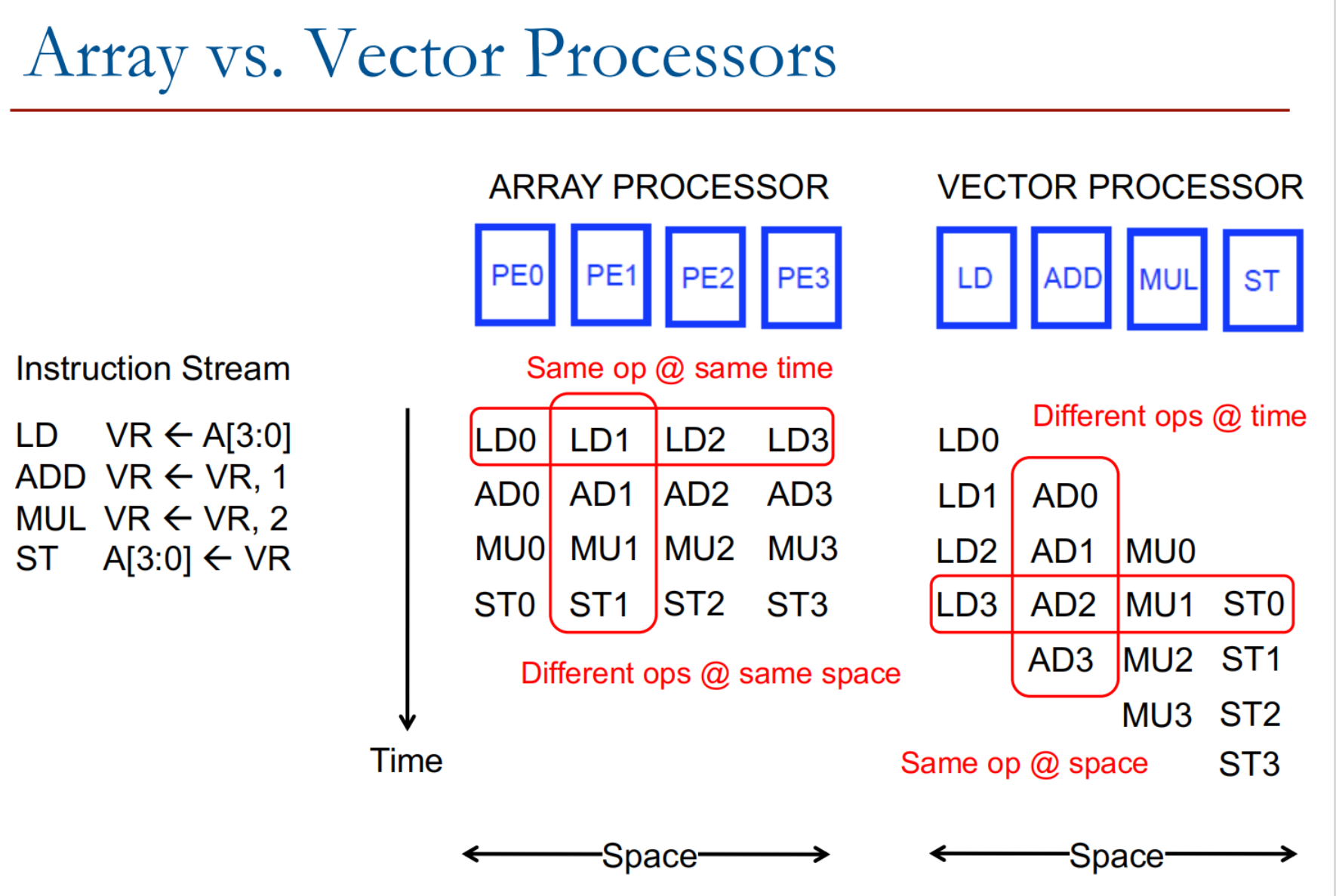
如上图所示:
阵列处理器 。
阵列处理器有多个处理单元(PE0、PE1、PE2、PE3),每个单元独立处理一部分数据.
相同操作同时执行(SIMD: Single Instruction Multiple Data) 阵列处理器的每个处理单元同时执行相同的操作,但作用在不同的数据元素上:
第一行:LD0, LD1, LD2, LD3 同时完成数据加载.
第二行:AD0, AD1, AD2, AD3 同时完成加法操作.
第三行:MU0, MU1, MU2, MU3 同时完成乘法操作.
第四行:ST0, ST1, ST2, ST3 同时完成数据存储.
时间维度:同一时刻,各个 PE 执行相同的指令.
空间维度:不同 PE 处理不同的数据.
向量处理器 。
向量处理器中,每个处理单元的功能不同,分别负责加载(LD)、加法(ADD)、乘法(MUL)和存储(ST).
时间维度: 同一时刻,各个 PE 执行不同的指令.
空间维度: 同一 PE 执行相同的功能.
每个向量数据寄存器存储 N 个 M 位值 。

VLIW(超长指令字):将多个独立操作打包在一起组成一个“长指令” 。
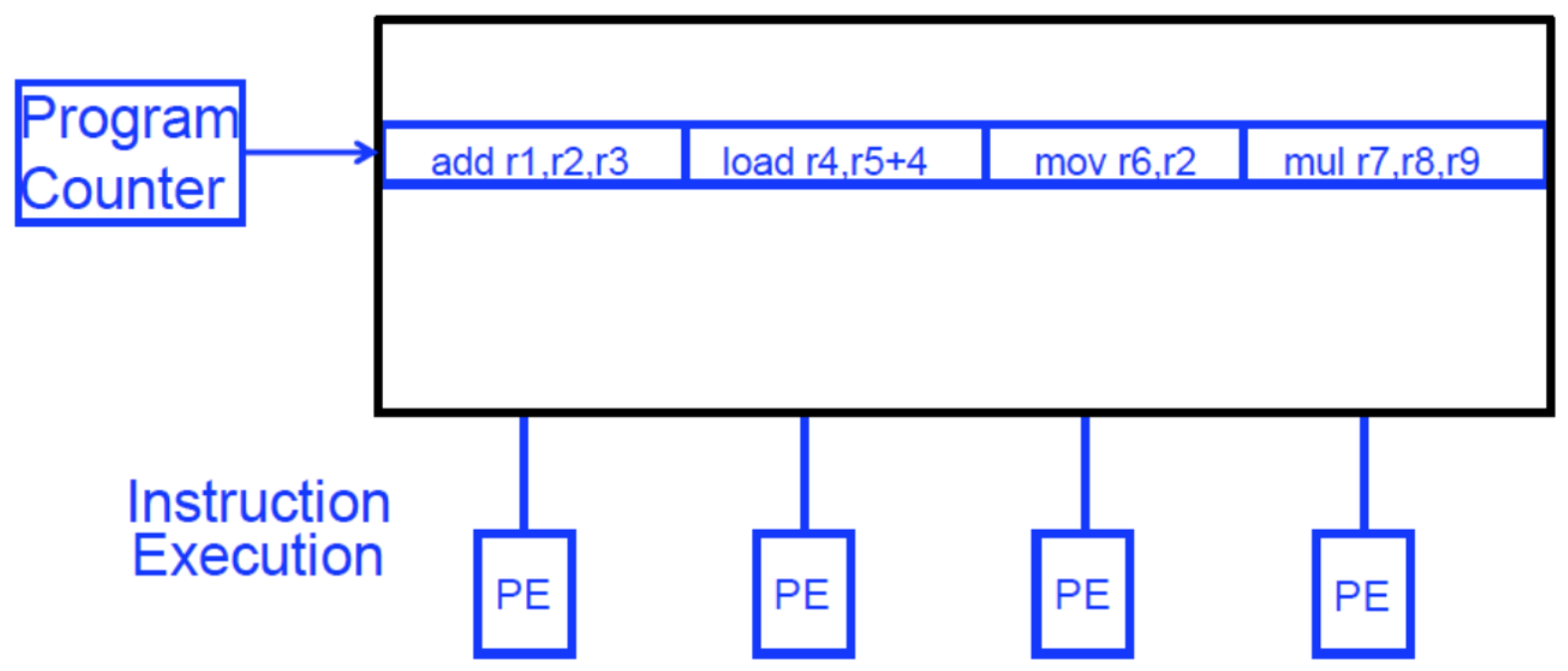
阵列处理器:对多个(不同的)数据元素执行单一操作 。

基本思想:
结果独立性:
存储器访问模式:
流水线控制的优化 。
向量处理器具有更高层次的操作,一条向量指令可以同时处理N个或N对操作数(处理对象是向量) 。

向量是一个一维的数字数组.
示例代码:这段代码通过遍历数组对每个元素进行操作,实际上是典型的向量运算.
for (i = 0; i <= 49; i++) {
C[i] = (A[i] + B[i]) / 2;
}
向量处理器是一种指令直接对向量进行操作的处理器,而不是像标量处理器那样只能处理单个数据值.
基本需求:
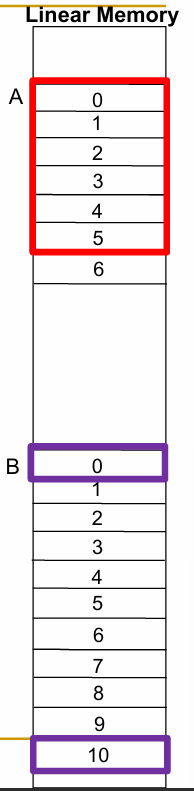
矩阵 A 和矩阵 B 的数据均以 行优先(row-major order) 存储在内存中.
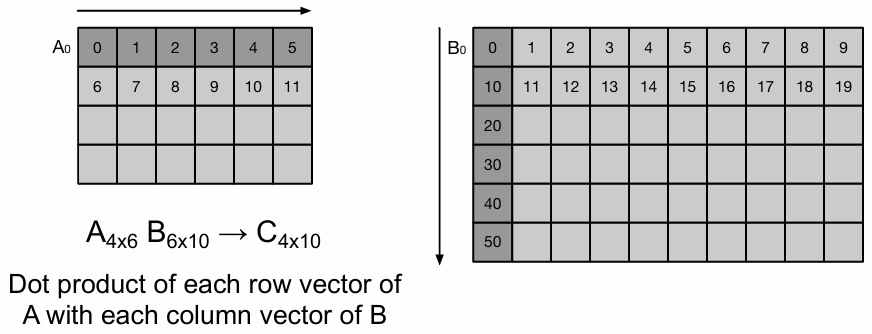
加载 A 的第 0 行(A0 到 A5)到向量寄存器 V1:
加载 B 的第 0 列(B0 到 B50)到向量寄存器 V2:
一条向量指令在连续的时钟周期中对向量中的每个元素执行操作.
向量指令支持更深的流水线设计:
+ 向量内部没有数据相关性 。
+ 每条指令产生大量的工作(操作) 。
+ 不需要显式编写循环代码 。
+ 非常规则的内存访问模式 。
-- 仅在并行性是规则的情况下(数据/SIMD并行)工作良好 。
Fisher 在论文“Very Long Instruction Word architectures and the ELI-512”中提到:
Amdahl定律 。
f:程序中可并行化的部分 。
N:处理器的数量 。
Amdahl,"单处理器方法在实现大规模计算能力中的有效性",AFIPS 1967年 。
最大加速比受限于串行部分:串行瓶颈 。
所有并行计算机都会“受到”串行瓶颈的影响.

内存(带宽)可能很容易成为瓶颈,尤其是在以下情况:
计算/内存操作平衡没有得到保持 。
向量处理器的性能很大程度上取决于计算和内存访问的平衡。如果计算速度过快,而内存访问速度跟不上,处理器就会变得空闲,无法充分利用计算资源,导致效率下降。因此,程序的设计需要确保计算与内存操作之间的平衡.
数据没有适当映射到 memory banks 。
向量处理器通常依赖于多个 Memory Banks 并行处理数据。如果数据没有合理地分布到不同的 Memory Banks,就可能导致内存访问冲突或带宽瓶颈。例如,多个计算任务可能会尝试访问相同的内存位置,从而造成等待和性能下降。因此,正确地映射数据到不同的 Memory Banks 是确保高效执行的关键.
每个向量数据寄存器包含 N 个 M 位的值 。
向量控制寄存器:VLEN、VSTR、VMASK 。
最大 VLEN 可以是 N 。
向量掩码寄存器(VMASK) 。
VMASK[i] = (Vk[i] == 0)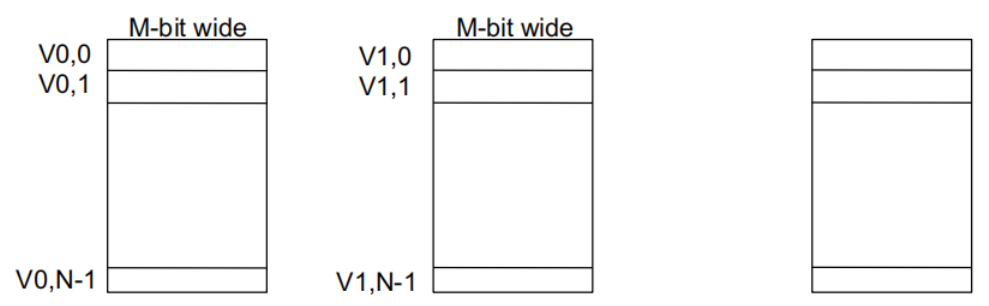
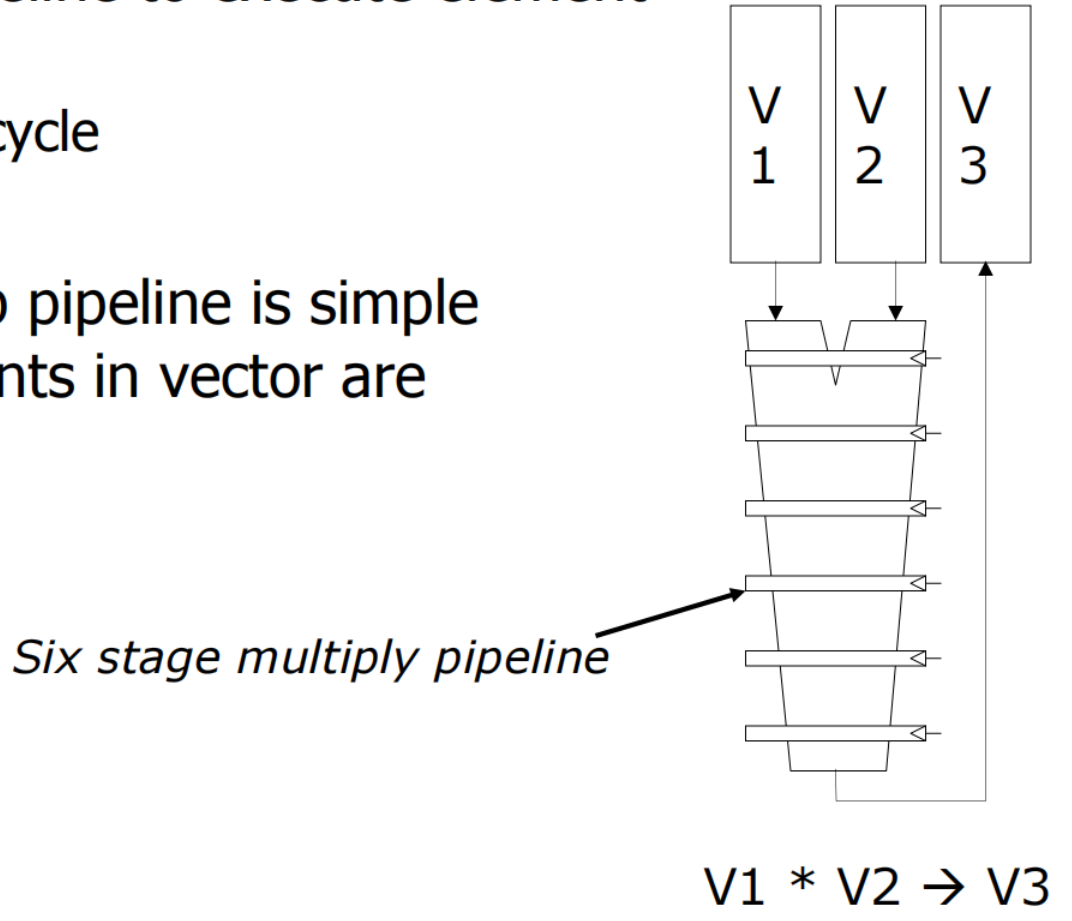
使用深流水线执行元素操作 。
向量功能单元利用深度流水线(Deep Pipeline)来加速元素操作。深流水线指的是流水线有更多的阶段,这样可以使得每个时钟周期内能够执行更多的操作.
深流水线的控制相对简单,因为向量中的元素是独立的 。
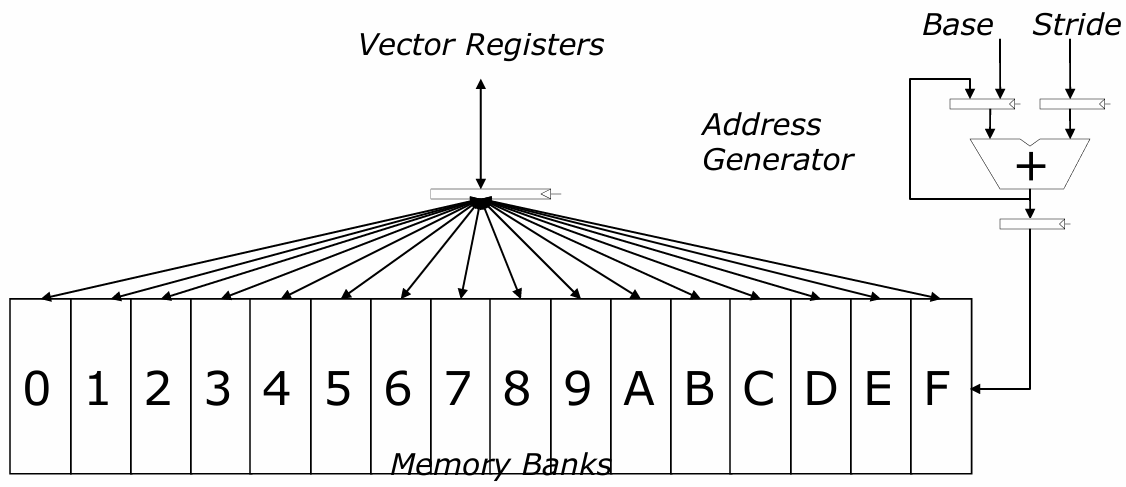
需要加载/存储多个元素 。
元素之间有固定的距离(步长) 。
如果每个周期可以启动一个元素的加载,那么元素可以在连续的周期内加载 。
问题:如何在内存访问需要多个周期的情况下实现这一点?
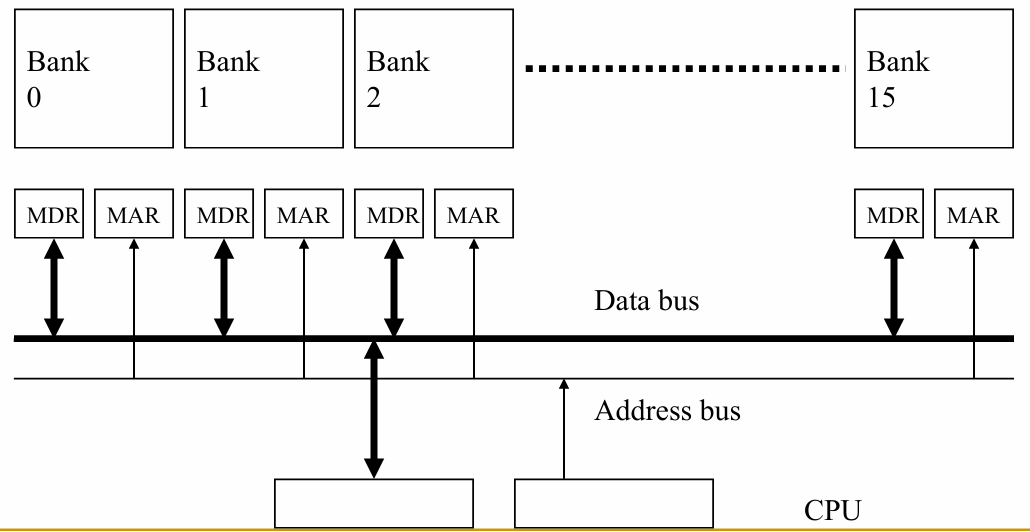
答案:将内存分成多个存储单元;将元素交错存储到不同的存储单元中 。
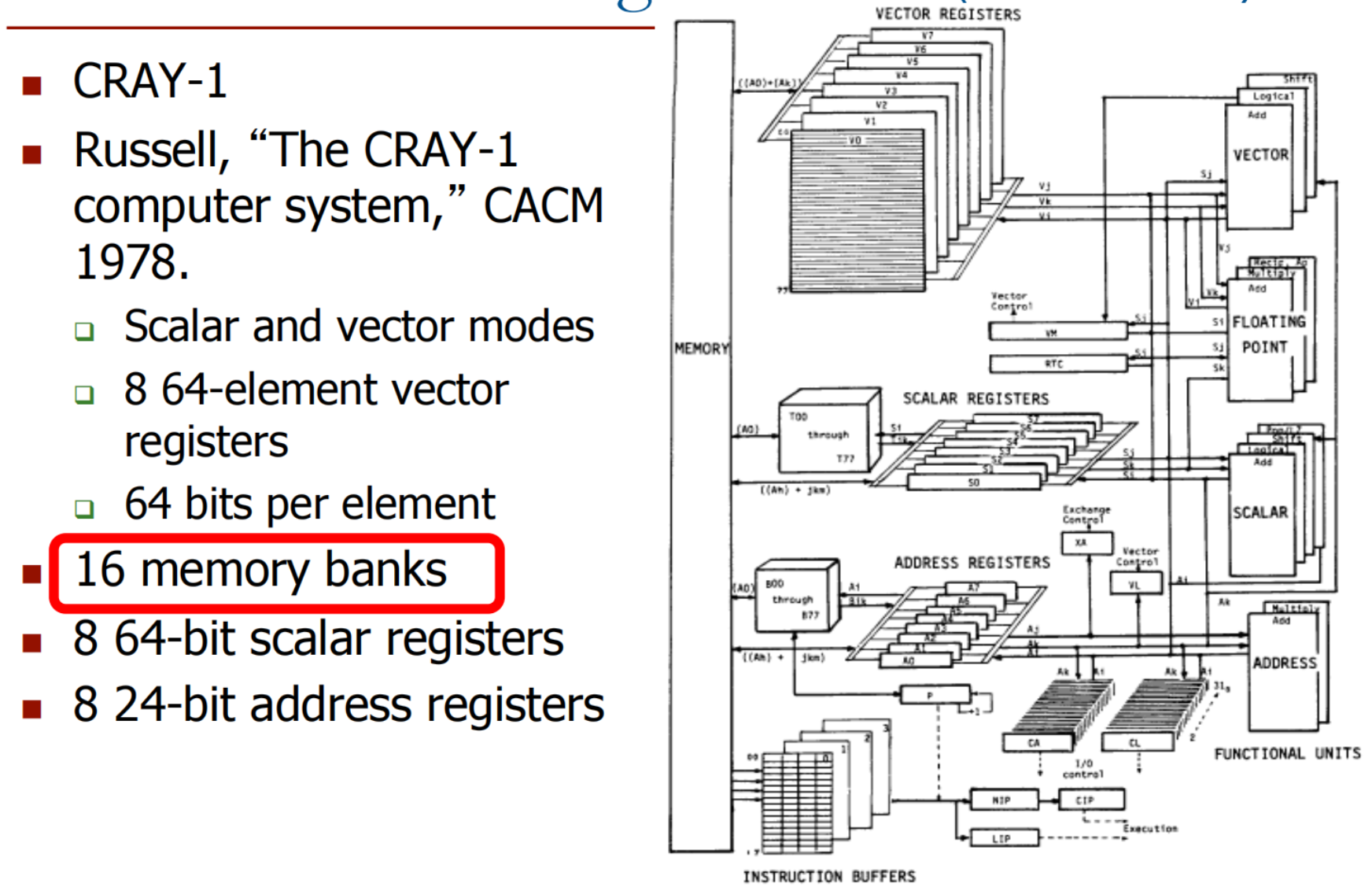
内存被划分为多个独立的 bank;各 bank 共享地址总线和数据总线(以减少内存芯片的引脚数量) 。
每个周期可以启动并完成一个 bank 的访问 。
如果所有访问都指向不同的 bank,则可以持续进行 N 次并发访问 。
下一个地址 = 上一个地址 + 步幅(Stride) 。
如果(步幅 == 1)且(连续元素跨 memory bank 交错存储)且(memory bank 数量 ≥ memory bank 延迟),则:
for i = 0 to 49
C[i] = (A[i] + B[i])/2
标量代码(指令及其在时钟周期中的延迟):
MOVI R0 = 50 ; 1 cycle
MOVA R1 = A ; 1 cycle
MOVA R2 = B ; 1 cycle
MOVA R3 = C ; 1 cycle
X: LD R4 = MEM[R1++] ; 11 cycle
LD R5 = MEM[R2++] ; 11 cycle
ADD R6 = R4 + R5 ; 4 cycle
SHFR R7 = R6 >> 1 ; 1 cycle
ST MEM[R3++] = R7 ; 11 cycle
DECBNZ R0, X ; 2 cycle
该程序会执行 \(4 + 6 \times 50 = 300\) 条动态指令.
标量代码执行时间 (按顺序):
在一个单存储体(bank)的顺序执行处理器上的标量执行时间 。
在一个具有两个存储端口(两个不同的内存访问可以同时进行服务)的单存储体顺序执行处理器上的标量执行时间,或者具有两个存储体(其中数组A和B存储在不同的存储体中) 。
可向量化的循环:
for i = 0 to 49
C[i] = (A[i] + B[i])/2
向量化后的循环(每个指令及其延迟):
MOVI VLEN = 50 ; 1
MOVI VSTR = 1 ; 1
VLD V0 = A ; 11 + VLEN - 1
VLD V1 = B ; 11 + VLEN - 1
VADD V2 = V0 + V1 ; 4 + VLEN - 1
VSHFR V3 = V2 >> 1 ; 1 + VLEN - 1
VST C = V3 ; 11 + VLEN - 1
该程序会执行 7 条动态指令.
基本向量代码执行性能:

向量链接:向量链接是指数据从一个向量功能单元转发到另一个单元的过程.
链接过程:
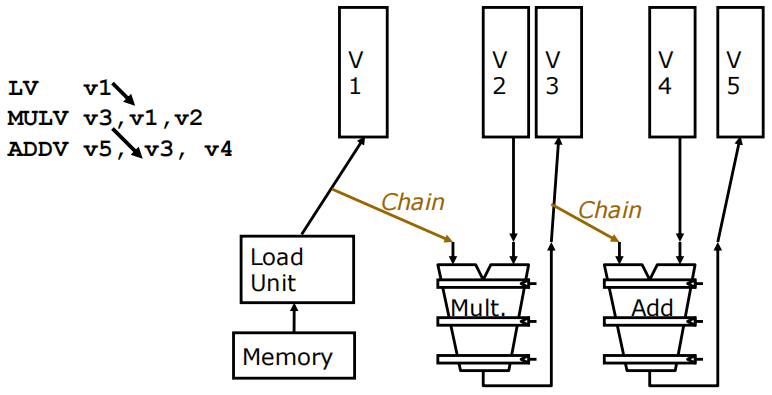
对于 2.4.2节 的向量化程序:

如果每个 memory bank 有 2 个加载端口和 1 个存储端口.
VLD V0=A 和 VLD V1=B:由于有两个加载端口,这两个加载操作可以并行进行,从而加速内存访问。VADD 和 VSHFR:向量加法(VADD)和向量右移(VSHFR)通过链式处理快速传递数据,进一步减少了执行时间。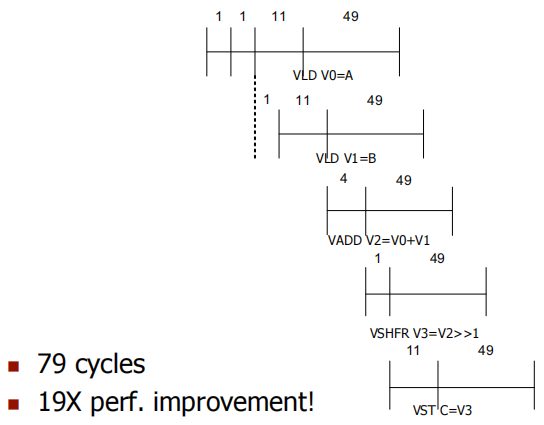
如果数据元素数 > 向量寄存器中的元素数怎么办?
如果向量数据在内存中不是以固定步长存储的呢?(即不规则内存访问) 。
向量化具有间接访问的循环,如:
for (i=0; i<N; i++)
A[i] = B[i] + C[D[i]]
索引加载指令(聚集):
LV vD, rD ; 加载D向量的索引
LVI vC, rC, vD ; 从rC基址间接加载到vC中
LV vB, rB ; 加载B向量
ADDV.D vA, vB, vC ; 执行加法操作
SV vA, rA ; 存储结果
聚集操作用于从非连续内存地址收集数据。这里,通过LVI指令,使用向量D中的索引来间接访问C向量,即从C的不同位置加载数据.
聚集/散射操作通常在硬件中实现,以处理稀疏向量(矩阵)或间接索引.
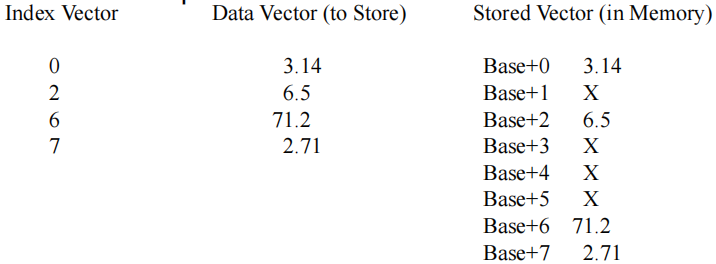
向量加载和存储使用一个索引向量,通过将其加到基址寄存器来生成地址.
散射示例:
索引向量包含位置索引 {0, 2, 6, 7}.
数据向量包含要存储的数据 {3.14, 6.5, 71.2, 2.71}.
在存储操作中,3.14 被存储在 基址+0 的位置,6.5 在 基址+2 的位置,71.2 在 基址+6 的位置,2.71 在 基址+7 的位置.
其他位置保留为X,表示这些位置没有被当前操作修改.
如果某些操作不应在向量上执行怎么办?(基于动态确定的条件) 。
for (i=0; i<N; i++)
if (a[i] != 0)
b[i] = a[i] * b[i];
在这个循环中,只有当a[i]不为零时,才执行乘法操作.
想法:掩码操作(Masked Operations):
VLD V0 = A:将向量A加载到寄存器V0。VLD V1 = B:将向量B加载到寄存器V1。VMASK = (V0 != 0):创建一个掩码,V0中不为零的元素对应的掩码位置为1。VMUL V1 = V0 * V1:对V0和V1中的元素进行乘法操作,但仅对掩码为1的索引执行。VST B = V1:将结果存储回向量B中。举例:
循环逻辑:这个循环的目标是将a[i]或b[i]中较大的值存储到c[i].
for (i = 0; i < 64; ++i)
if (a[i] >= b[i])
c[i] = a[i]
else
c[i] = b[i]
执行步骤:
VMASK:比较A和B的元素,生成一个位掩码VMASK。如果a[i] >= b[i],则VMASK[i]为1,否则为0。VMASK,把满足条件(a[i] >= b[i])的元素从A存储到C。VMASK,使得之前为0的位变为1,反之亦然。VMASK,把不满足条件(a[i] < b[i])的元素从B存储到C。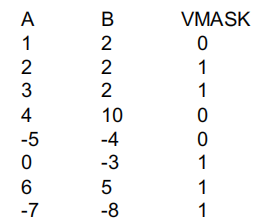
掩码向量指令用于在向量处理器中根据掩码位决定哪些操作结果需要被写回。根据掩码的不同状态,可以优化执行效率和资源使用.
方法: 执行所有 N 个操作,根据掩码决定是否写回结果.
示例:
A[i]和B[i],计算结果C[i]。M[i] = 1,则结果被写入C[i];如果M[i] = 0,则结果不被写回。特性: 所有运算都执行,但根据掩码来控制哪些结果被写入存储.
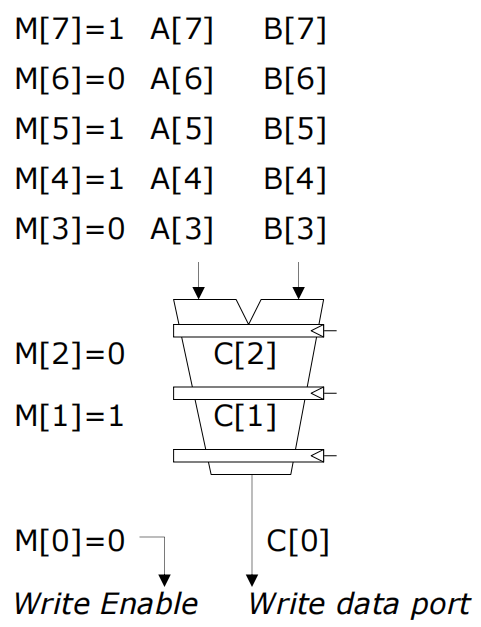
M[i] = 1的元素进行计算和写回。M[7]=1,则仅计算A[7]和B[7],并将结果写回C[5]。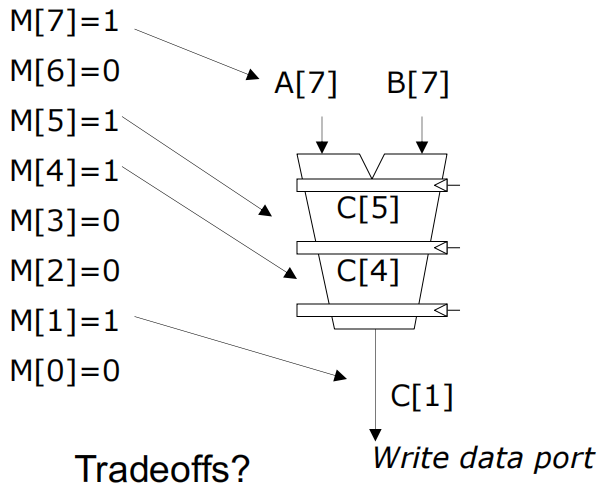
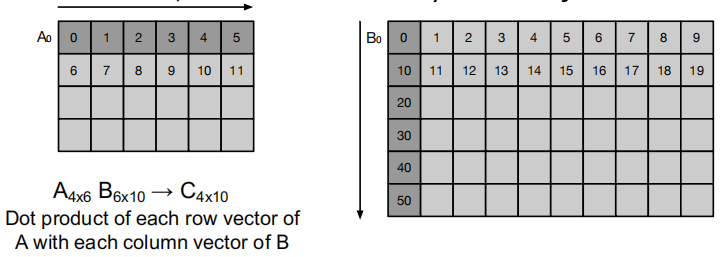
矩阵 A 和 B 都以行优先顺序存储在内存中.
加载A的第0行到向量寄存器V1:
加载B的第0列到向量寄存器V2:
不同步长导致的冲突:
如何最小化冲突?
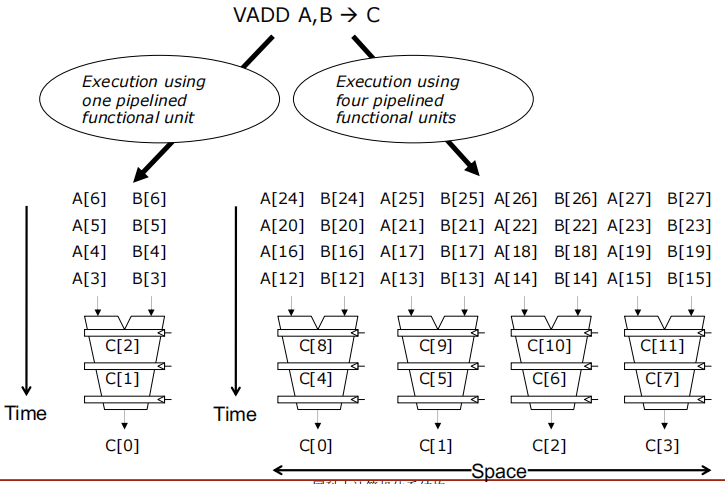
使用一个流水线功能单元(Execution using one pipelined functional unit):
使用四个流水线功能单元(Execution using four pipelined functional units):
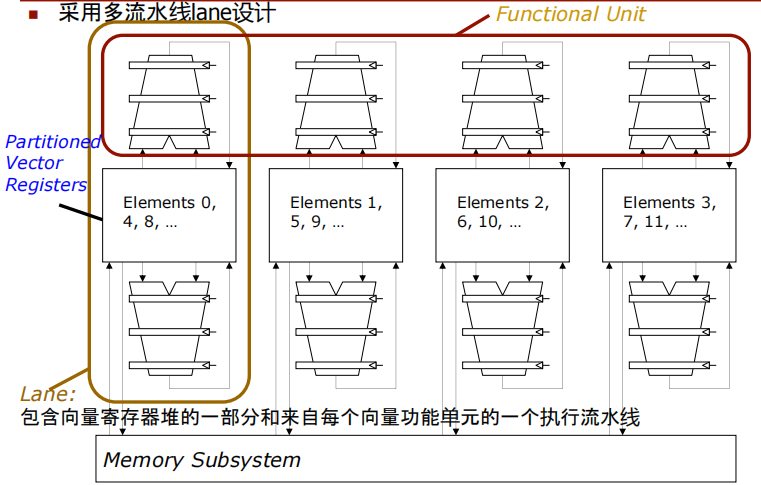
采用多流水线(lane)设计:
每个lane包含一部分向量寄存器堆和一个来自每个向量功能单元的执行流水线。这样可以在同一时间并行处理多个数据元素,提高计算效率.
划分的向量寄存器(Partitioned Vector Registers):向量寄存器被分割成多个部分,每部分与一个lane相关联,这样可以在多个lane之间分配和管理数据.
元素分配:各个lane处理不同索引的元素,例如,第一个lane处理元素0、4、8等,第二个lane处理元素1、5、9等.
内存子系统(Memory Subsystem):与多个lane连接,用于提供数据存取支持.
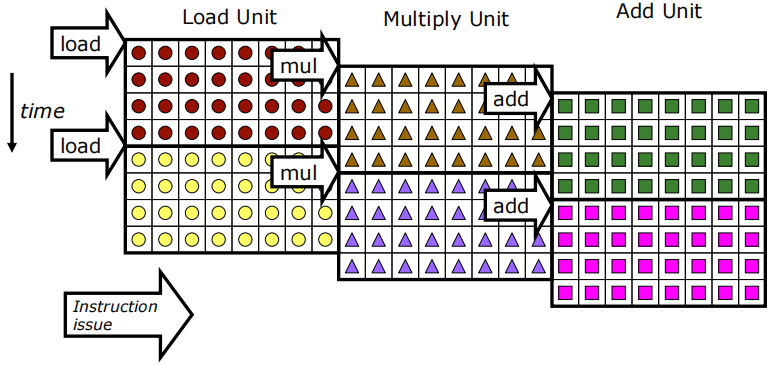
可以重叠多个向量指令的执行:
示例机器配置:
每个向量寄存器有32个元素.
共有8条流水线(lanes).
在稳定状态下,每个周期可以完成24个操作,同时每个周期发出1条向量指令.
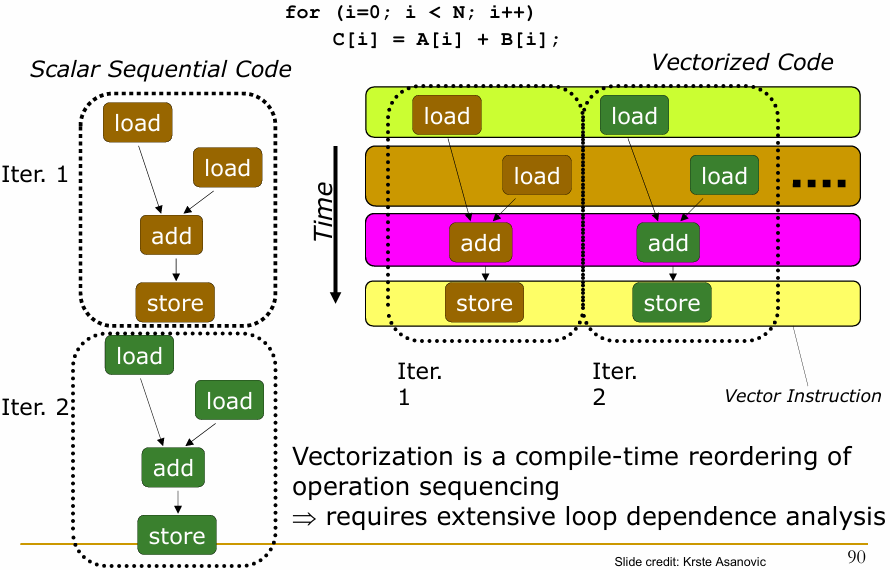
for (i = 0; i < N; i++)
C[i] = A[i] + B[i]
Iter. 1 和 Iter. 2):每次迭代,程序依次执行加载、加法和存储操作.
这种线性执行方式在处理大量数据时可能效率低下,因为每个操作需要等待前一个操作完成.
向量化是一种在编译时对操作顺序进行重排的过程.
需要对循环依赖进行广泛分析,以确保操作可以安全地并行执行而不破坏数据的正确性.
最后此篇关于DDCA——SIMD结构和向量处理器的文章就讲到这里了,如果你想了解更多关于DDCA——SIMD结构和向量处理器的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
57
4
 0
0
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 想改进这个问题?将问题更新为 on-topic对于堆栈溢出。 7年前关闭。 Improve this qu
我有一个代码库,我可以在我的 mac 上编译和运行,但不能在我的远程 linux 机器上编译和运行,我不确定为什么。 编译时出现错误 fatal error: simd/simd.h: No such
我需要了解如何编写一些可并行化问题的 C++ 跨平台实现,以便在可用的情况下利用 SIMD(SSE、SPU 等)。以及我希望能够在运行时在 SIMD 和非 SIMD 之间切换。 您建议我如何解决这个问
我正在使用 AVX 内在 _mm256_extract_epi32() . 不过,我不完全确定我是否正确使用它,因为 gcc 不喜欢我的代码,而 clang 编译它并运行它没有问题。 我根据整数变量的
当我可以使用 SSE3 或 AVX 时,SSE2 或 MMX 等较旧的 SSE 版本是否可用 - 还是我还需要单独检查它们? 最佳答案 一般来说,这些都是附加的,但请记住,多年来英特尔和 AMD 对这
在 godbolt.org 使用 gcc 7.2 我可以看到以下内容 code在汇编程序中翻译得非常好。我看到 1 次加载、1 次添加和 1 次存储。 #include __attribute__(
假设我们有一个函数将两个数组相乘,每个数组有 1000000 个 double 值。在 C/C++ 中,该函数如下所示: void mul_c(double* a, double* b) {
我有一个 A = a1 a2 a3 a4 b1 b2 b3 b4 c1 c2 c3 c4 d1 d2 d3 d4 我有两排, float32x2_t a = a1 a2 flo
我正在考虑编写一个 SIMD vector 数学库,因此作为一个快速基准,我编写了一个程序,该程序执行 1 亿(4 个 float ) vector 元素乘法并将它们加到累积总数中。对于我的经典非 S
我正在开发带有英特尔编译器 OpenMP 4.0 的英特尔 E5(6 核、12 线程) 为什么这段代码 SIMD 编译比并行 SIMD 编译更快? for (int suppv = 0; suppv
OpenMP 4.0 引入了 SIMD 结构以利用 CPU 的 SIMD 指令。根据规范http://www.openmp.org/mp-documents/OpenMP4.0.0.pdf ,有两种结
英特尔编译器允许我们通过以下方式对循环进行矢量化 #pragma simd for ( ... ) 但是,您也可以选择使用 OpenMP 4 的指令执行此操作: #pragma omp simd fo
关注我的 x86 question ,我想知道如何在 Arm-v8 上有效地矢量化以下代码: static inline uint64_t Compress8x7bit(uint64_t x) {
Intel 提供了几个 SIMD 命令,它们似乎都对 128 位数据执行按位异或: _mm_xor_pd(__m128d, __m128d) _mm_xor_ps(__m128, __m128) _m
可以使用“位打包”技术压缩无符号整数:在一个无符号整数 block 中,只存储有效位,当一个 block 中的所有整数都“小”时,会导致数据压缩。该方法称为 FOR (引用框架)。 有SIMD lib
SSE 寄存器是否在逻辑处理器(超线程)之间共享或复制? 对于 SSE 繁重的程序,我能否期望从并行化中获得与普通程序相同的加速(英特尔声称具有超线程的处理器为 30%)? 最佳答案 从英特尔的文档中
我正在编写一个使用 SSE 指令来乘法和相加整数值的程序。我用浮点数做了同样的程序,但我的整数版本缺少一个指令。 使用浮点数,在完成所有操作后,我将 de 值返回到常规浮点数数组,执行以下操作: _m
我正在开发基于Intel指令集(AVX,FMA等)的高性能算法。当数据按顺序存储时,我的算法(内核)运行良好。但是,现在我面临一个大问题,但没有找到解决方法或解决方案: see 2D Matrix i
大家好 :) 我正在尝试了解有关浮点、SIMD/数学内在函数和 gcc 的快速数学标志的一些概念。更具体地说,我在 x86 cpu 上使用 MinGW 和 gcc v4.5.0。 我已经搜索了一段时间
根据https://sourceware.org/glibc/wiki/libmvec GCC 具有数学函数的向量实现。它们可以被编译器用于优化,可以在这个例子中看到:https://godbolt.

我是一名优秀的程序员,十分优秀!