
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 56
56
 4
4


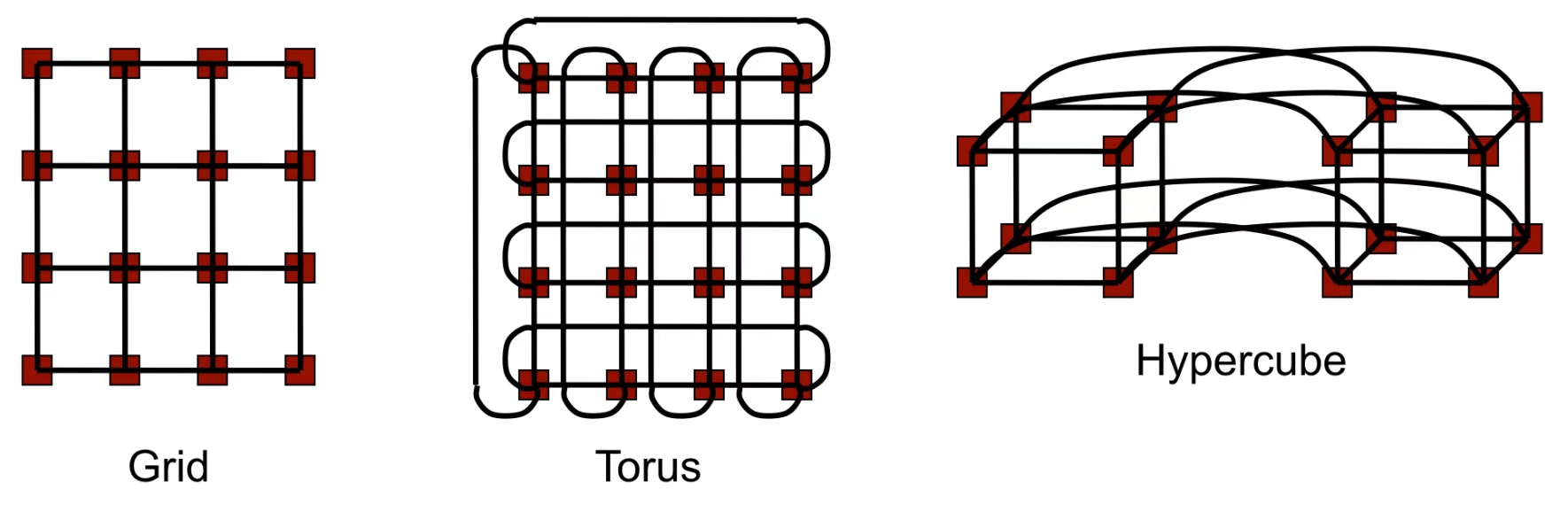
Grid(网格) 。
网络拓扑通常是一个二维矩阵形式,每个节点(处理器)与其上下左右相邻的节点相连.
如果节点在边缘,某些方向上可能没有相邻节点(边界节点).
Torus(环形网格) 。
Torus是网格的改进版本,通过将网格的边界节点相连,形成一个环状结构.
每个节点都与上下左右相邻的节点连接,同时网格边缘节点环绕连接,形成闭合路径.
Hypercube(超立方体) 。
超立方体是一种高维网络拓扑,具有\(d\)-维结构,其中节点数 \(P=2^d\).
每个节点通过 \(d\) 条链接与其他节点相连,节点的编号之间的 Hamming 距离为 1.
例如,三维超立方体有 8 个节点,四维超立方体有 16 个节点.
确定性路由(Deterministic Routing):给定源节点和目标节点时,存在唯一的一条路由路径.
自适应路由(Adaptive Routing):交换节点可以根据意外事件(例如故障、拥塞)动态调整路由路径。这种方式会增加路由器的复杂性,但可能提升网络性能。!!!仍可能造成死锁!!! 。
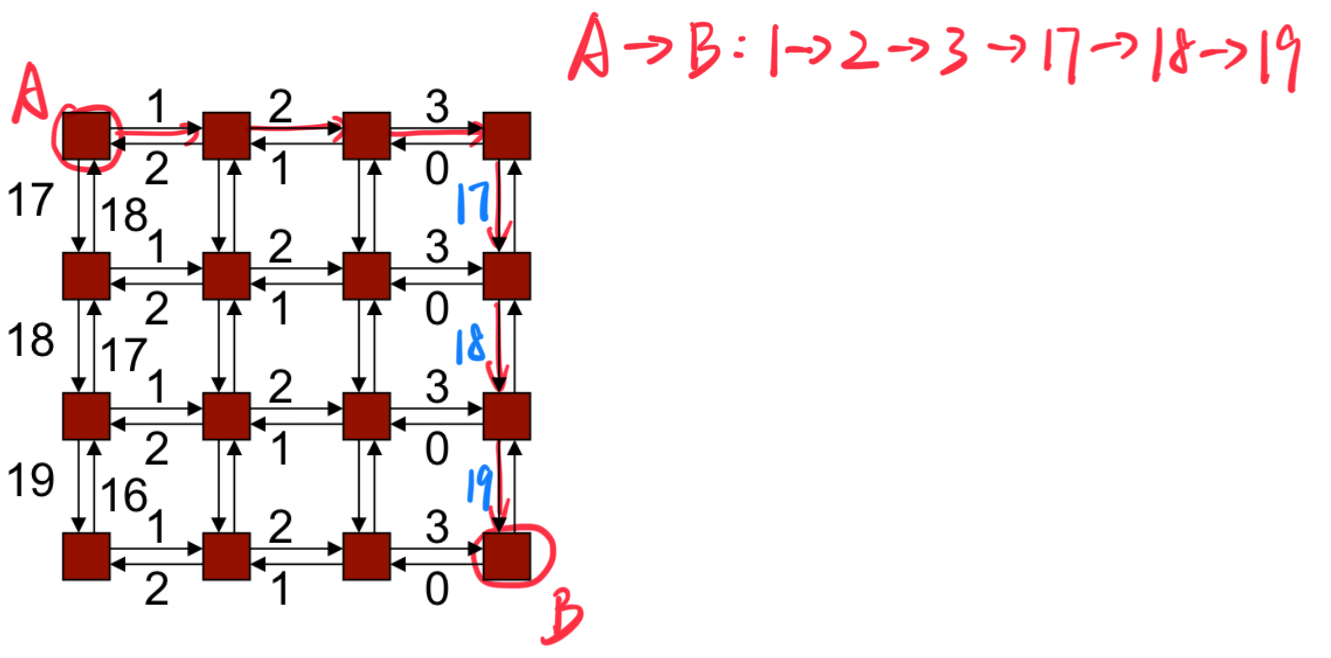
确定性路由示例:维度顺序路由(Dimension Order Routing):数据包沿着第一维度发送,直到到达目标在该维度上的坐标,然后继续在下一维度上发送,以此类推,直到数据包到达目标节点.
死锁发生在资源依赖形成循环的情况下:一个进程占有某个资源(A)并试图获取另一个资源(B),而资源 A 不会被释放,直到获取到资源 B.


如上图所示,每个 message packets 试图进行左转操作,从而造成死锁.
给边编号,并证明所有路由将按递增(或递减)顺序遍历边 。
示例:k-ary二维数组(k-ary 2-d array)使用维度路由 。
考虑二维网格中的 8 种可能的转弯(注意:转弯会导致循环) 。
通过阻止两个特定的转弯,可以消除循环 。
维度顺序路由(Dimension Order Routing)禁止四种转弯 。
如下图所示,维度顺序路由对于从左边或从右边跳转的 Packets,只允许进行两个方向的转弯,从而避免死锁的产生.
即使在自适应路由中也可以避免死锁 。
下方图示展示了几种常见的死锁避免策略:

West-First(西优先) 。
数据包不能先向东转弯,只能先向西移动.

North-Last(北最后) 。
数据包一开始不能向北走,最后才向北走.

Negative-First(负向优先) 。
数据包的移动方向被分为两类:
数据包必须先移动负方向(例如 X 轴负方向或 Y 轴负方向),直到不能再移动为止,然后才能开始移动正方向.

会造成死锁(Deadlock) 。

一条消息会被拆分成多个数据包(packets)(每个数据包都包含头部信息,允许接收端重新构建原始消息).

一个数据包本身可以进一步被拆分成流控单元(Flits)——流控单元不包含额外的头部信息.
两个数据包可以沿着不同的路径到达目的地;而流控单元始终是有序的,并且沿着相同的路径传输.

这种架构允许使用较大的数据包(从而减少头部开销),同时可以基于流控单元(Flits)实现细粒度的资源分配.
消息(Message)的路由(route)需要分配多种资源:
无缓冲流控(Bufferless):
如果发生链路争用,数据单元(flits)会被丢弃.
系统会发送否定确认(NACK),通知原始发送方.
发送方需要重新传输该数据包.
偏转路由:

电路交换(Circuit Switching):
发送方首先发送一个请求(探测 message)来预留信道.
如果中间路由器的信道暂时不可用,请求会被阻塞(因此不是真正的无缓冲机制).
一旦信道预留完成,会发送确认消息(ACK).
随后的数据包或数据单元(flits)能够以较小的开销进行传输(适合大规模数据传输).

两个信道之间的缓冲区可以使每个信道的资源分配相互解耦.

数据包缓冲流控(Packet-buffer flow control):数据包缓冲流控是将资源(如信道和缓冲区)按数据包的单位进行分配 。

存储-转发(Store-and-forward):
切割传输(Cut-through):
虫洞路由(Wormhole Routing):
虫洞路由是切割传输的一种优化,它的特点是缓冲区按数据单元(flit)进行分配,而不是按整个数据包.
虫洞路由(Wormhole Routing)和切割传输(Cut-through)的区别:
切割传输从路由 1 跳转到路由 2 时,它需要在路由 2 分配整个数据包的缓存空间.
虫洞路由从路由 1 跳转到路由 2 时,它只需要在路由 2 分配一个 flit 的缓存空间.
传统信道的局限性:
传统情况下,数据包(packet)占用一个物理信道进行传输.
数据包被拆分为多个 flits(流控制单元),这些 flits 按顺序通过信道传输.
问题:

虚拟信道(Virtual Channel)的解决方案:
多缓冲区设计: 每个物理信道被虚拟化为 N 个逻辑虚拟信道,每个虚拟信道都有自己的缓冲区.
多路复用: 允许多个数据包共享同一个物理信道(Physical Channel),但逻辑上各自独立.
虚拟信道 ID: 数据包中的 flits 携带一个 虚拟信道 ID,用于标识其所属的虚拟信道.
优势:

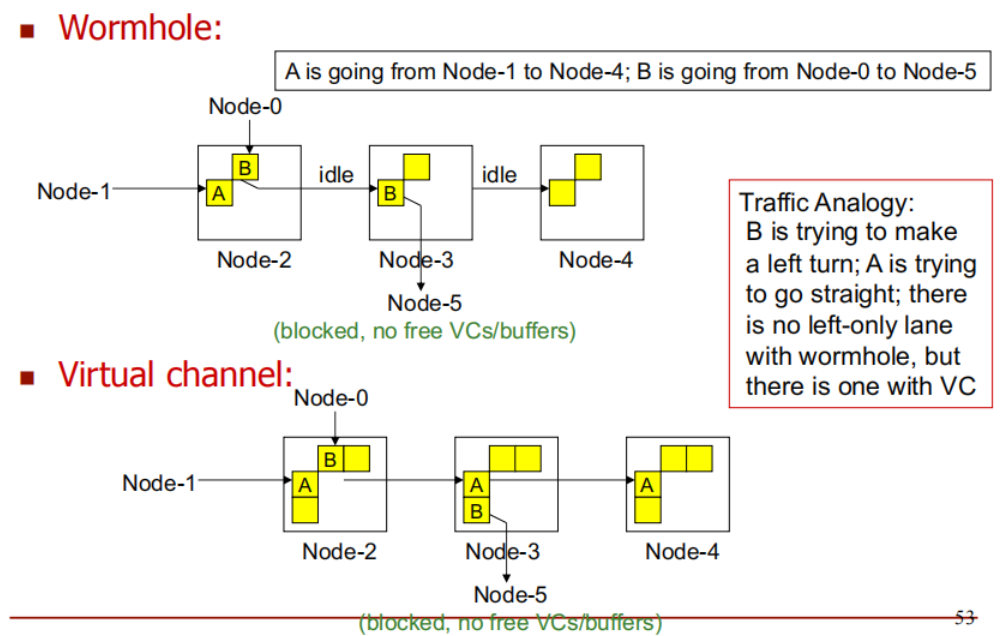
流量类比(Traffic Analogy):
A 和 B 分别代表两种不同的数据流,它们在网络中传输,想要到达不同的目的地.
数据包 B 需要转弯才能到达目的地,而数据包 A 需要直行.
在虫洞路由中,没有左转专用车道。这意味着,尽管数据包 B 需要转弯,它仍然会在传输过程中与直行的数据包 A 分享同一个物理信道。这可能导致冲突或阻塞,类似于左转的车辆与直行的车辆在同一车道上发生干扰.
在虚拟信道机制下,有左转专用车道。这意味着,数据包 B 可以通过专门的信道(虚拟信道)来完成左转,而不会干扰到数据包 A 的直行。虚拟信道为不同的数据流提供了独立的缓冲区,使得即使数据流的路径有所不同,它们也不会发生冲突.
传入的 flit 和缓冲区:
三个资源的竞争:为了将 flit 从当前路由器传输到下一个路由器,需要竞争以下三个资源:
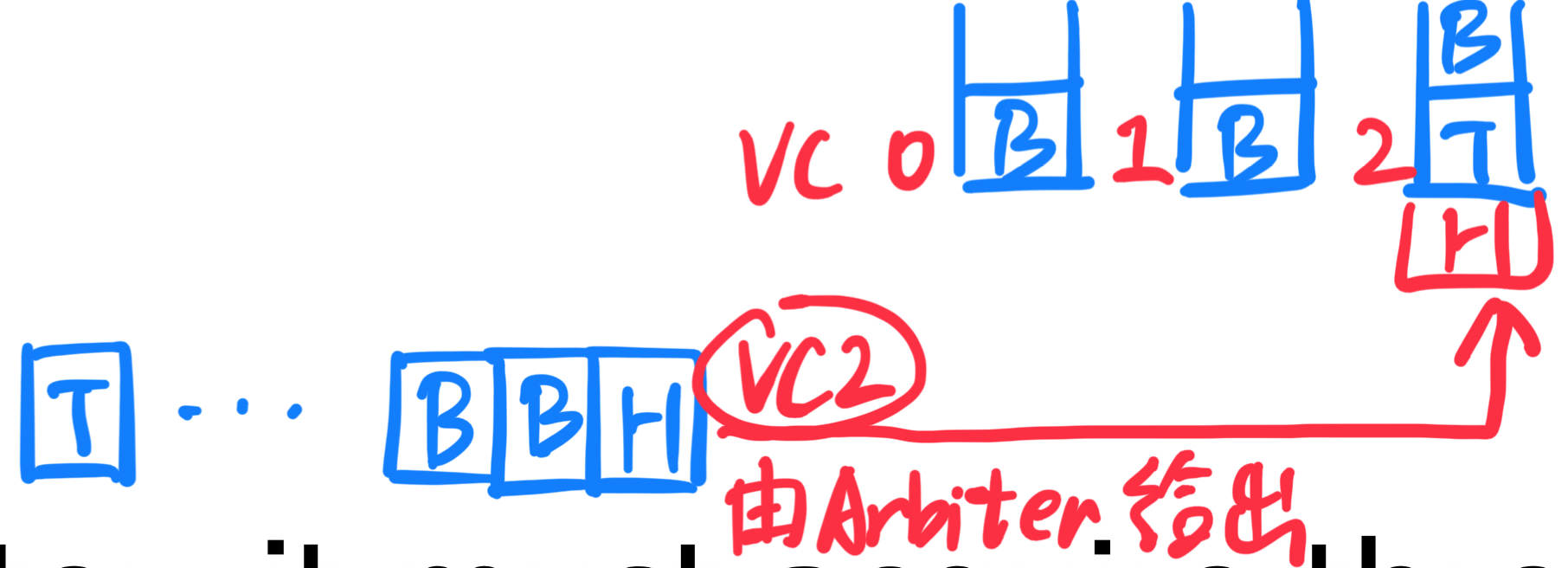
基于信用的缓冲区管理(Credit-based) 。
原理:在这种模式下,下游节点(即接收端)会持续追踪它的空闲缓冲区数量,并将该数量的信息反馈给上游节点(即发送端).
过程:
优点:

开/关缓冲区管理(On/Off) 。
基于虚拟信道的递增链路编号法 。
原理:
作用:通过链路编号的单调递增特性,保证了数据流动不会陷入死锁状态.

双平面(Two-Plane)路由法 。
路由器功能模块:
交叉开关(Crossbar):负责数据在输入端口和输出端口之间的交换,是数据传输的核心组件.
缓冲器(Buffer):用于存储临时数据(flits),防止数据包因通道繁忙而丢失.
仲裁器(Arbiter):当多个数据流争用同一个输出端口或资源时,仲裁器决定哪个数据流优先传输.
虚拟信道状态与分配(VC State and Allocation):管理虚拟信道(VC)的状态,分配虚拟信道资源,确保多个数据流共享物理通道时不会混淆.
缓冲管理(Buffer Management):控制缓冲区的使用,确保数据流在缓冲区中高效存储与传输.
算术逻辑单元(ALUs):处理与数据传输有关的计算逻辑(例如计数、状态更新等).
控制逻辑(Control Logic):负责整个路由器的协调与控制,确保各模块协同工作.
路由(Routing):计算数据包的下一跳路径,决定数据传输的方向.

片上网络的能耗:
网络延迟:
功耗分布:
每部分都占30%,这说明优化任何一个组件的功耗,都可以对片上网络的整体能效产生显著影响.
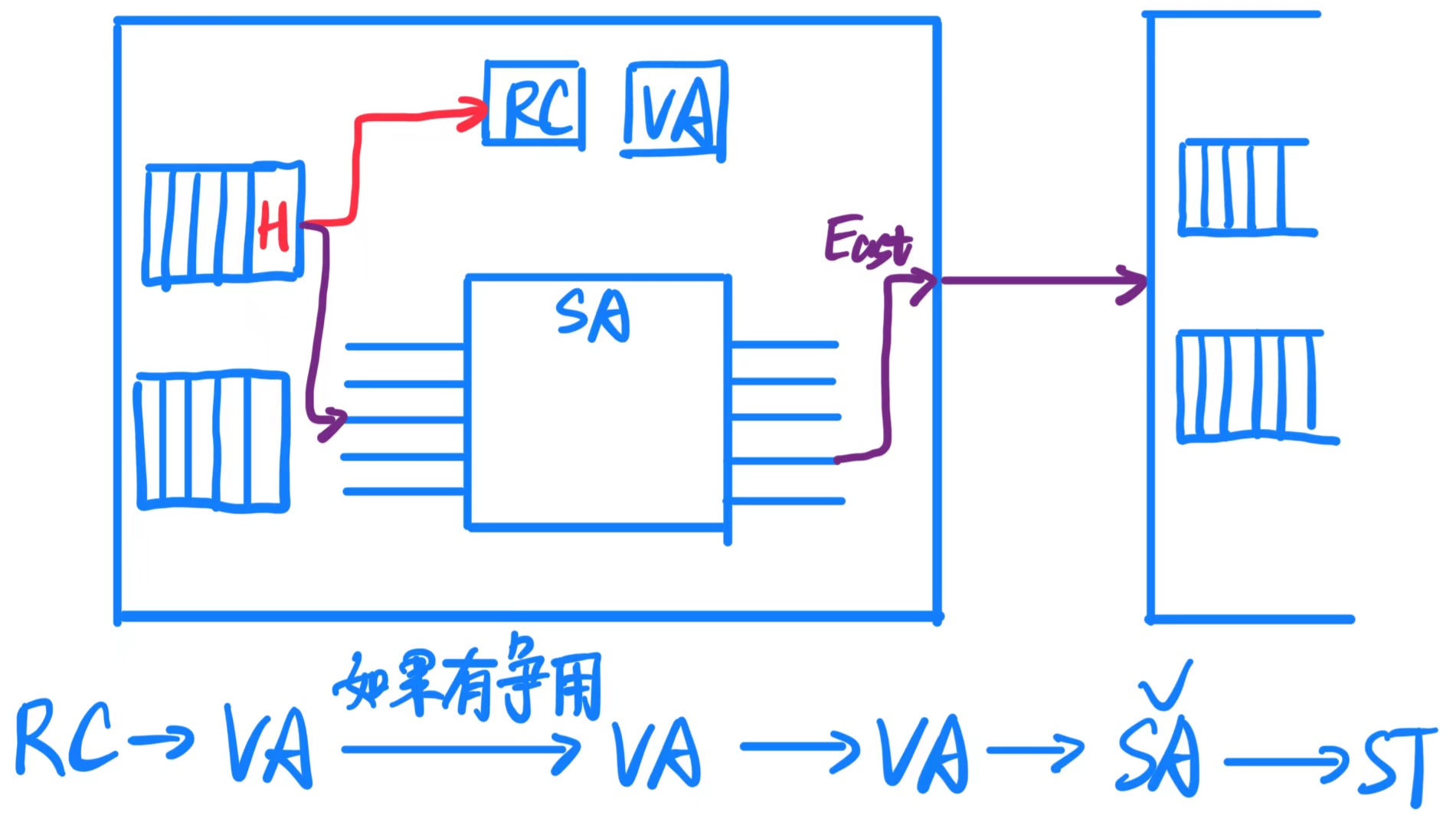
路由器流水线 是网络中路由器处理数据传输时采用的一种高效方法。它将数据包(packet)处理分为四个典型阶段,确保高吞吐量和低延迟。下面详细解释各个阶段:
流水线规则:

推测性流水线是一种优化路由器性能的方法,通过同时尝试多个步骤,来减少流水线延迟,提高吞吐量.
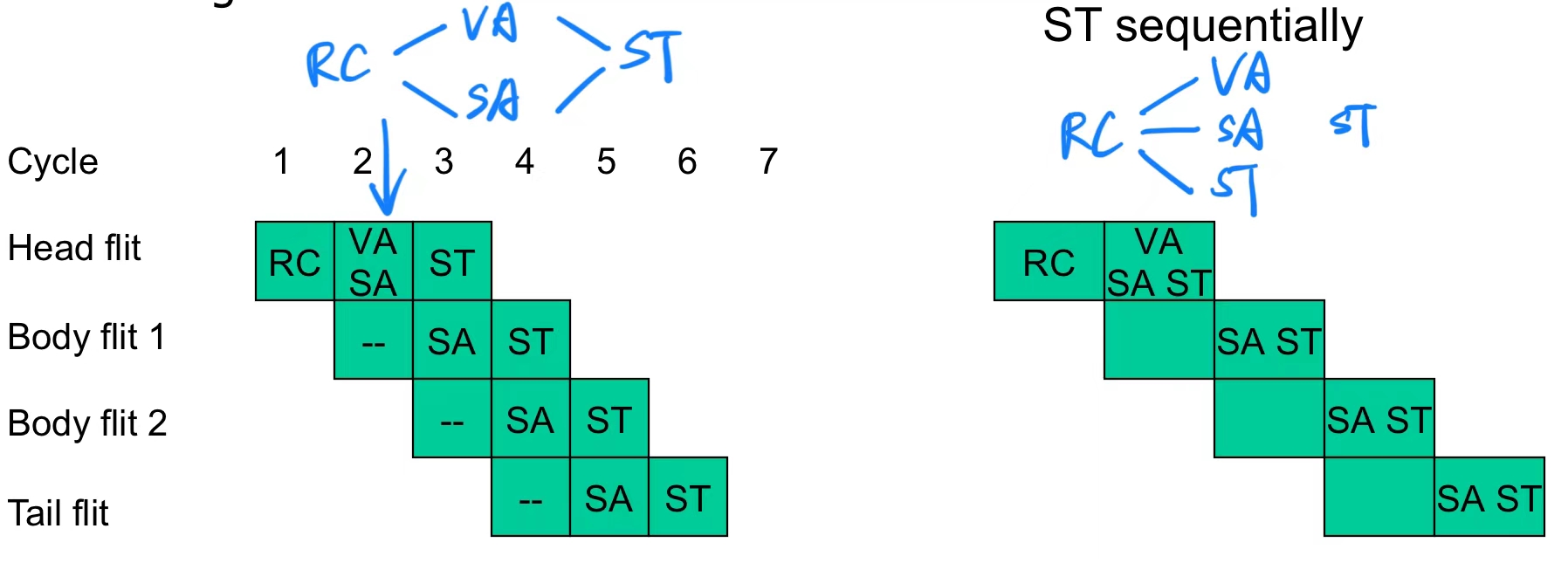
理想情况下,推测性策略可以使整个路由器的流水线缩短为单阶段,将 RC、VA、SA 和 ST 合并在一起.
但实际上,由于冲突和硬件限制,完全单阶段流水线很难实现,只在一些特定网络结构和负载下可行.

越来越关注消除路由器缓冲区带来的面积/功耗开销;由于流量水平相对较低,基于虚拟通道的有缓冲路由网络可能显得过于复杂.
Option 1:对于短距离通信(如 16 个核心),可以使用总线;对于长距离通信,采用分层总线结构.
Option 2:采用热土豆路由(hot-potato routing)或无缓冲路由(bufferless routing).
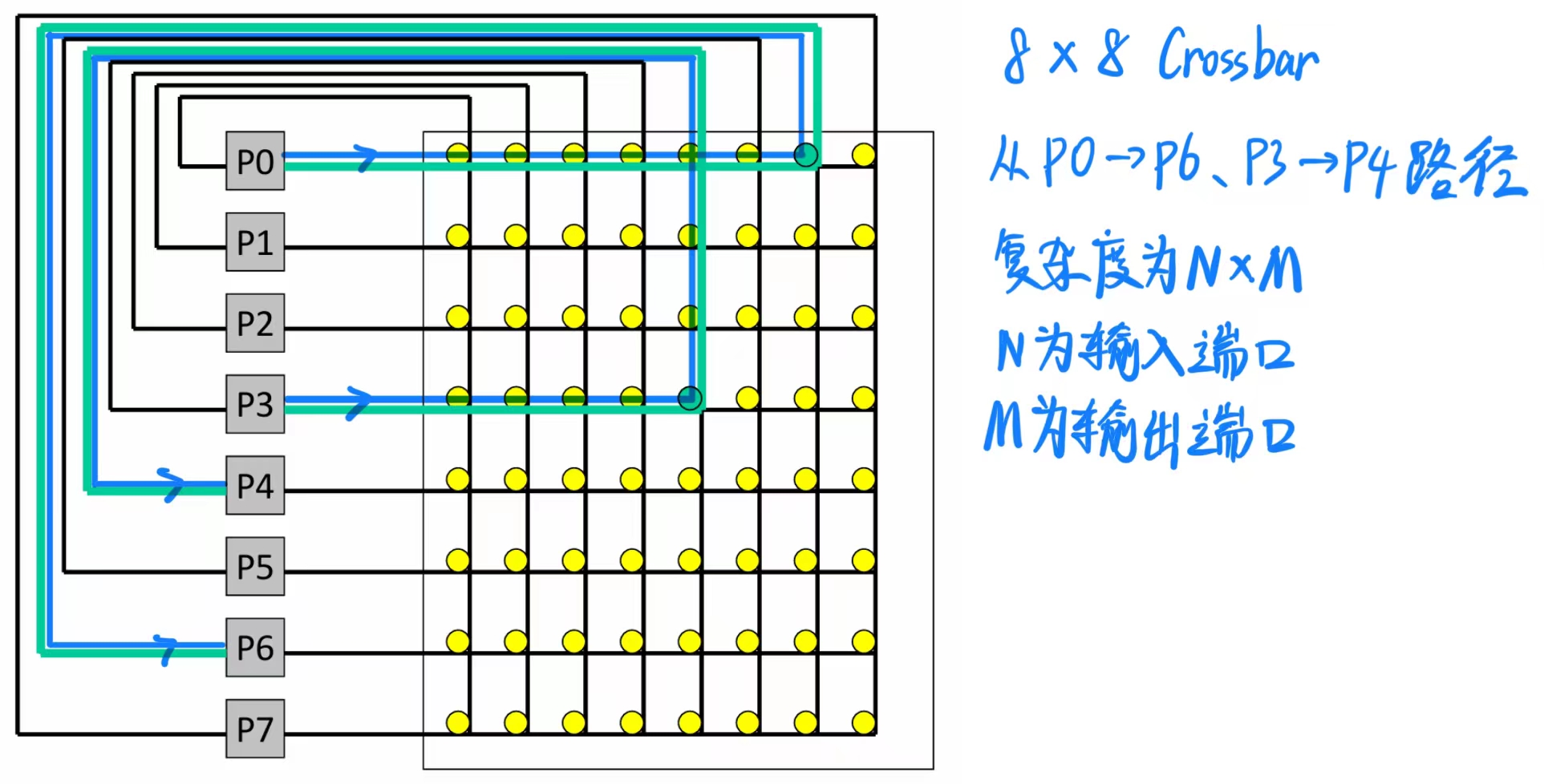
假设每个节点有一个输入端口和一个输出端口,交叉开关可以提供最大带宽:只要有 N 个唯一的源节点和 N 个唯一的目标节点,可以同时发送 N 条消息.
最大开销:交叉开关内部需要 WN² 个开关,其中 W 是数据宽度,N 是节点数量.
为了减少开销,可以使用较小的开关作为构建模块——这样会用更低的开销换取较低的有效带宽.
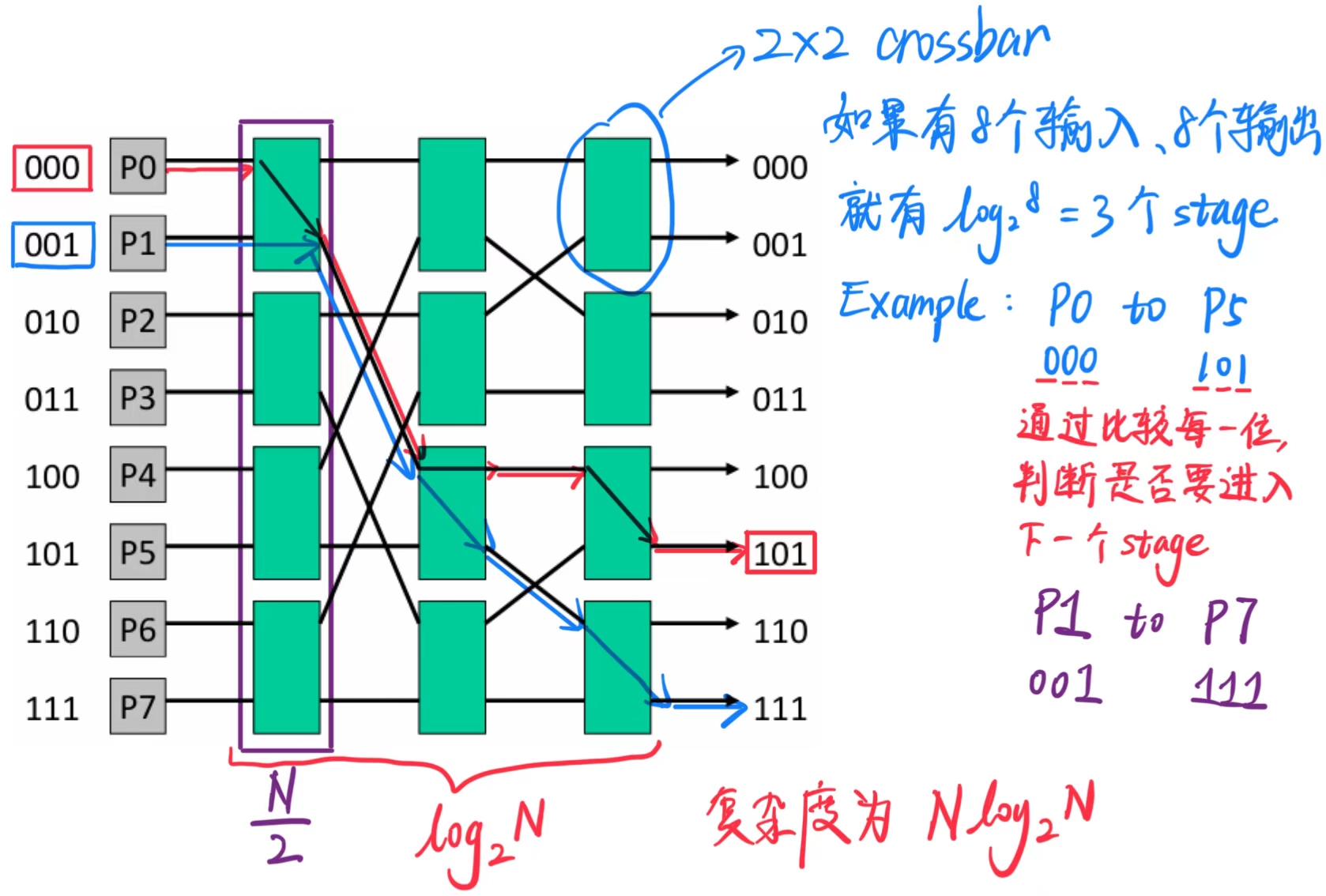
交换机的复杂度现在是 O(N log N).
争用增加:P0 - P5 和 P1 - P7 无法同时发生(在交叉开关中是可能的).
为了应对争用,可以增加网络的层数(冗余路径):通过镜像网络,我们可以通过 N 个中间节点从 P0 路由到 P5,同时将复杂度增加一个 2 倍.
复杂度为 O(N).
在与邻近节点通信时可以实现低延迟.
通过增加多个输入和输出链接可以构建胖树(Fat Tree).

双向带宽的定义 。

双向带宽是评估网络结构性能的重要指标之一。它衡量了网络在最糟糕的情况下,两个部分之间的数据传输能力.
最后此篇关于DDCA——片上网络互联的文章就讲到这里了,如果你想了解更多关于DDCA——片上网络互联的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
56
4
 0
0
1. SIMD 处理:利用常规(数据) 并行性 1.1 数据级并行的兴起与SIMD的优势 动机(Data Level Parallelism,DLP): 应用需求和技术发展推动着体系结构的
1. 路由 1.1 网络拓扑示例 Grid(网格) 网络拓扑通常是一个二维矩阵形式,每个节点(处理器)与其上下左右相邻的节点相连。 如果节点在边缘,某些方向上可能没有相邻节点(边界节点
1. 同步(Synchronization) 1.1 构造锁(Locks) 原子(atomic)执行:应用程序的某些部分必须独占执行(原子性),这意味着在这些部分执行期间,其他并行进程无法访
1. 内存架构和子系统 1.1 如何控制访问? 访问控制: 存储单元的访问是通过 访问晶体管(access transistors) 进行控制的。访问晶体管像开关一样,可以连接或断开存
1. 存储器层次(The Memory Hierarchy) 1.1 现代系统中的存储器 其中包括L1、L2、L3和DRAM 1.2 存储器的局限 理想存储器的需求如下: 零延迟
1. 缓存中的多核问题 1.1 多核系统中的缓存 Intel Montecito缓存 两个 core,每个都有一个私有的12 MB的L3缓存和一个1 MB的L2缓存,图中

我是一名优秀的程序员,十分优秀!