
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 56
56
 4
4


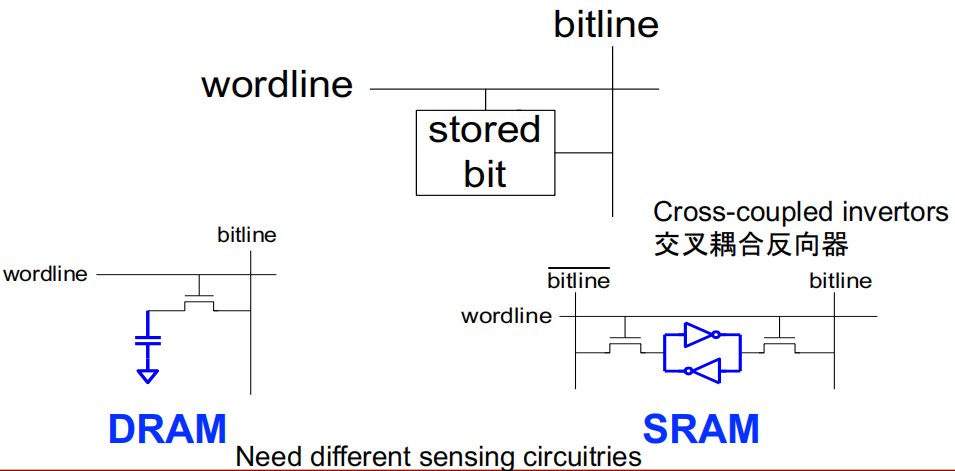
访问控制:
DRAM(Dynamic random access memory)的结构:
SRAM 的结构:
差异:
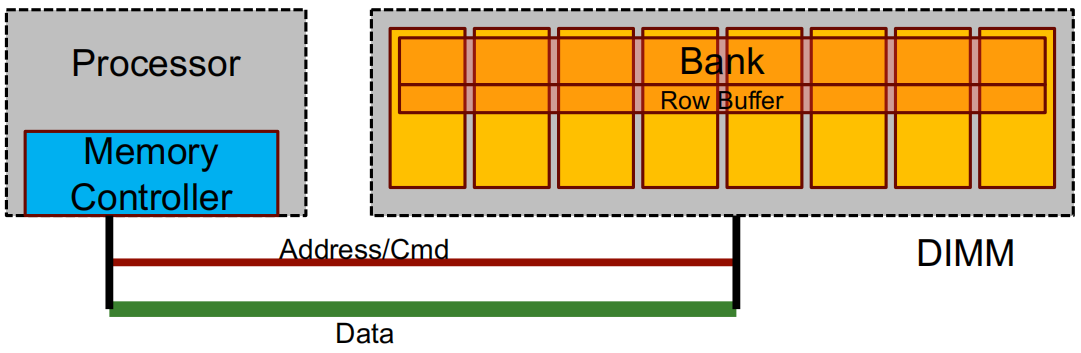
DIMM:背面和正面装有 DRAM 芯片的印刷电路板.
Rank:一组 DRAM 芯片,它们协同工作以响应请求并保持数据总线满载.
64位数据总线需要 8x8 DRAM 芯片或 4x16 DRAM 芯片... 。
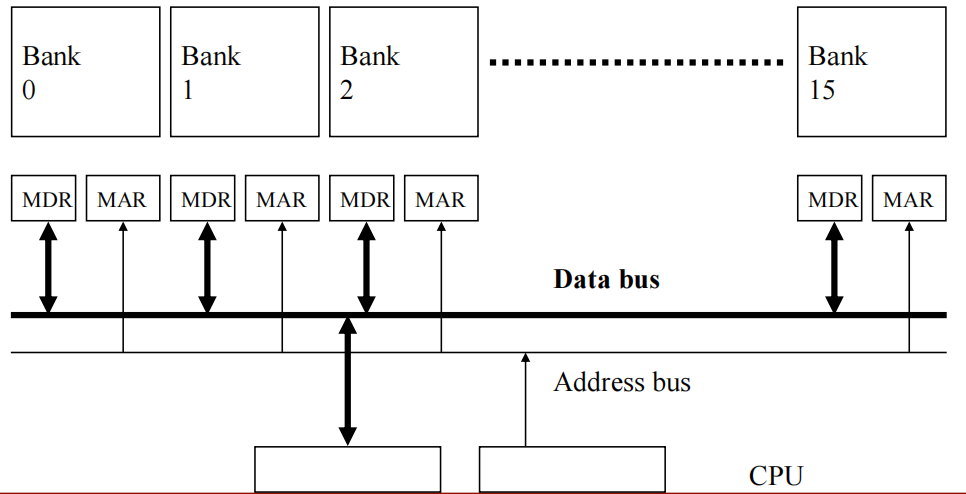
Bank:在一次请求期间忙碌的一个rank的子集.
行缓冲区(Row buffer):从组中读取的最后一行(如 8 KB),作用类似于缓存.
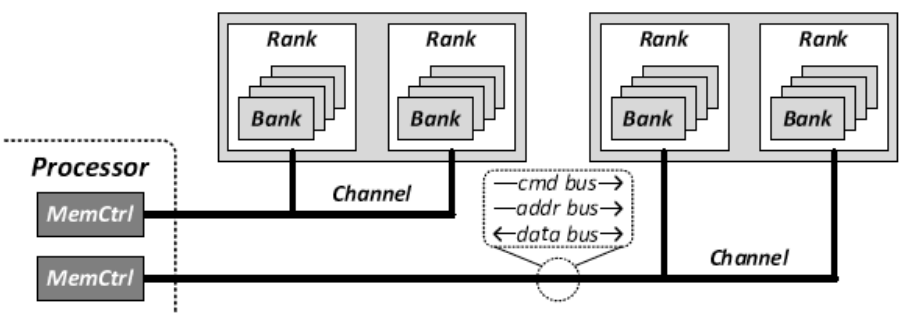
通道(Channel):每个通道通过命令总线(cmd bus)、地址总线(addr bus)和数据总线(data bus)与处理器相连,用于发送命令、地址和数据。这些总线允许处理器并行地与多个内存模块进行交互,从而提高系统的并行性.
内存控制器(MemCtrl):处理器通过内存控制器(MemCtrl)来管理对内存的访问。内存控制器负责内存请求的调度,并通过通道将数据发送到内存的特定区域.
Rank:在存储器模块中,每个通道包含一个或多个rank。rank是由多个bank组成的,它们在处理数据时可以同时访问.
Bank:每个rank包含多个bank,bank是rank的子集,每次访问期间只有一个bank处于繁忙状态。每个bank可以独立进行数据的存储和访问,使得系统能够在不同的bank之间并行处理数据,进一步提高内存的效率和带宽.
这种分层结构允许内存系统在不同的bank和rank之间进行并行访问,提高了内存带宽和数据处理效率。这种设计被广泛应用于DRAM中,以减少延迟并提高数据吞吐量.
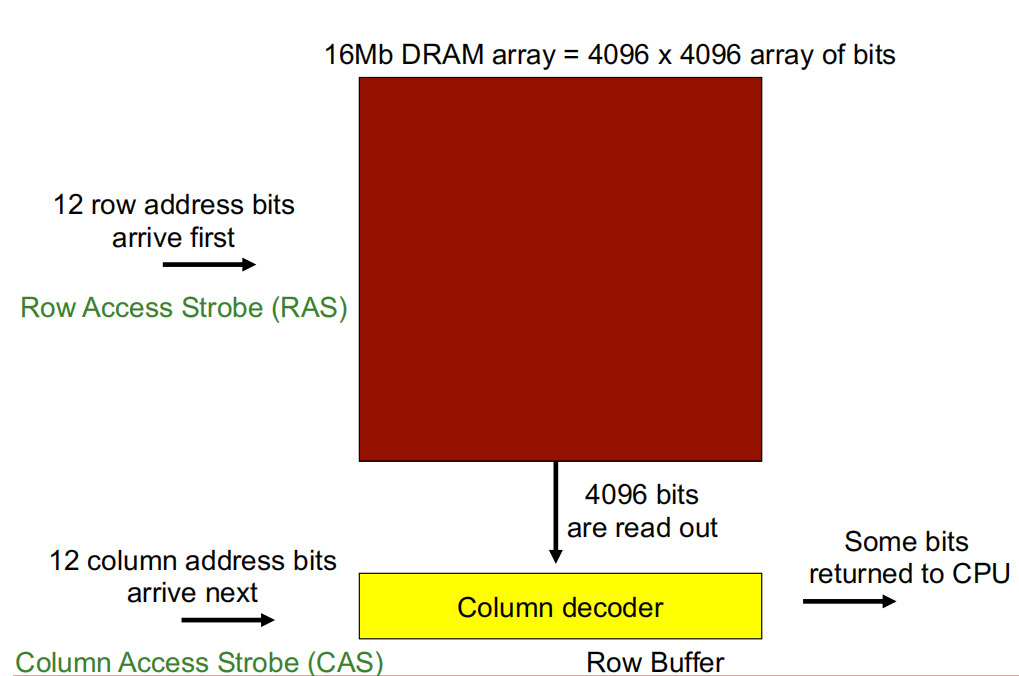
这是一个 \(16Mb\) 的DRAM阵列,即有 \(4096\times4096\) 阵列的bits.
行访问选通 (Row Access Strobe, RAS):由于该DRAM阵列有4096行,因此有\(log_{2}^{4096}=12 bits\)行地址,在访问数据时,12bits 行地址位最先到达.
列访问选通(Column Access Strobe,CAS):由于该DRAM阵列有4096列,因此有\(log_{2}^{4096}=12 bits\)列地址,在访问数据时,12bits 列地址位比行地址位后到达.
行访问选通到达后,DRAM读取一行数据(即4096bits)至行缓冲区(Row buffer),随后列访问选通到达,经过列解码器(Column decoder)从 Row buffer 读取数据返回 CPU.
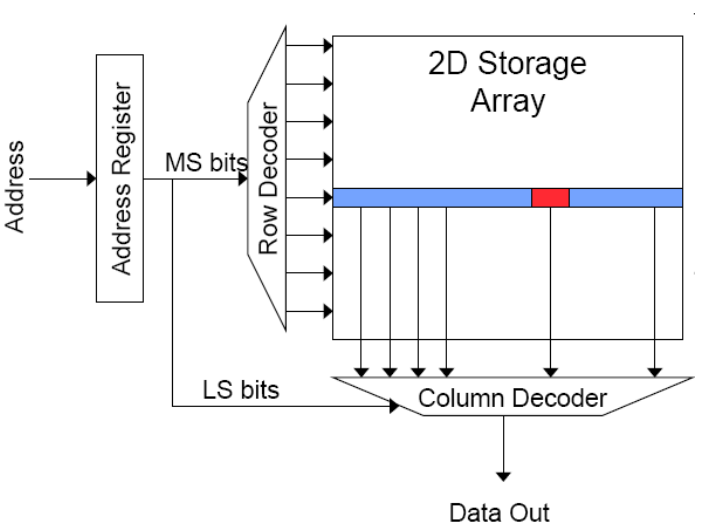
读取访问顺序:
主存储器存储在 DRAM 单元中,其存储密度要高得多 。
DRAM 单元会随着时间的推移而丢失状态 - 必须定期刷新,因此被称为动态存储器 。
DRAM 存取时间长,能源开销大 。
DRAM
SRAM
DIMM、rank、bank、array -> 在存储组织中形成一个层次结构 。
由于电气限制,总线上只能连接几个 DIMM 。
一个 DIMM 可有 1~4 ranks 。
为提高能效,应使用宽输出 DRAM 芯片 —— 每次请求只激活 \(4\times16bits\) 芯片比激活 \(16\times 4bits\) 芯片更好 。
为高容量,应使用窄输出 DRAM 芯片 —— 由于通道上的 rank 数有限,使用 \(16 \times 4bits\ 2Gb\) 芯片比使用 \(4 \times 16bits\ 2Gb\) 芯片可提高每个 rank 的容量 。
这种组织方式通过多个层次(ranks、banks、arrays)的划分,实现了高密度的存储,同时也通过并行访问多个banks和ranks,提升了内存系统的并行性和性能.
我们需要更大的存储阵列,但是大阵列意味着访问速度慢.
如何在保证存储器容量大的同时不使其变得非常慢?
Idea:将存储器划分为更小的阵列,并将这些阵列与输入/输出总线互连.
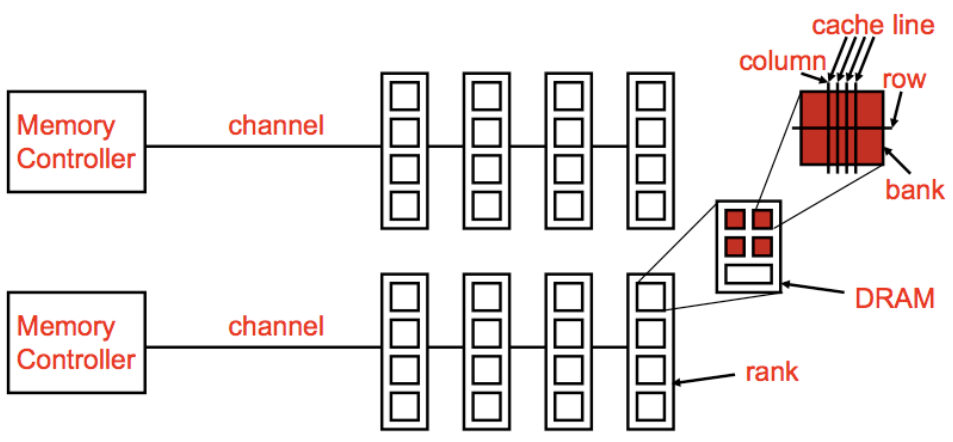
上图展示了一个通用的内存结构,主要包括以下组件:
交替访问(Interleaving)(banking 存储库) 。
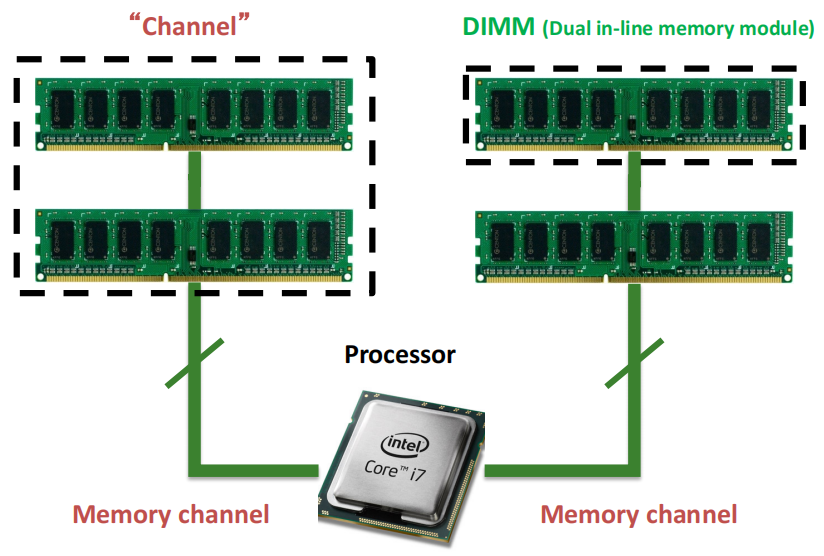
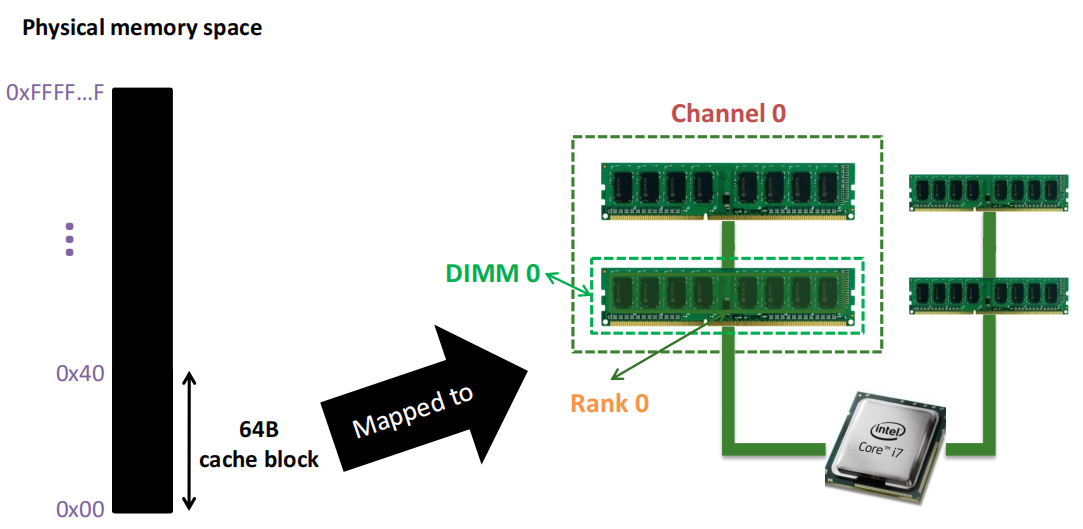
图中间的处理器通过两个独立的内存通道与内存模块相连,每个通道内可以插入多条内存条(DIMM,即双列直插内存模块),通道负责将数据传输到内存和处理器之间.
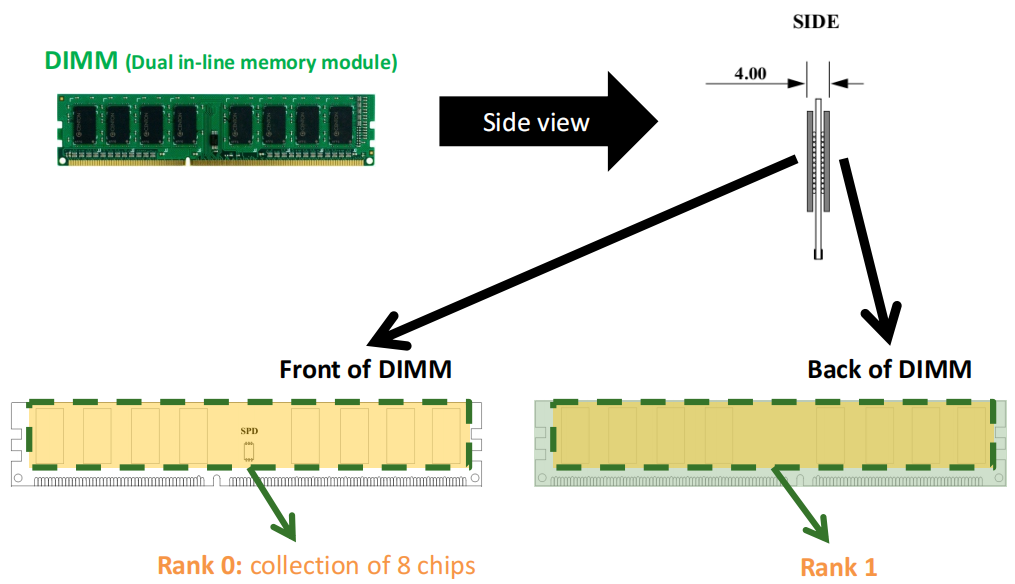
上图中展示了DIMM的正面和背面:
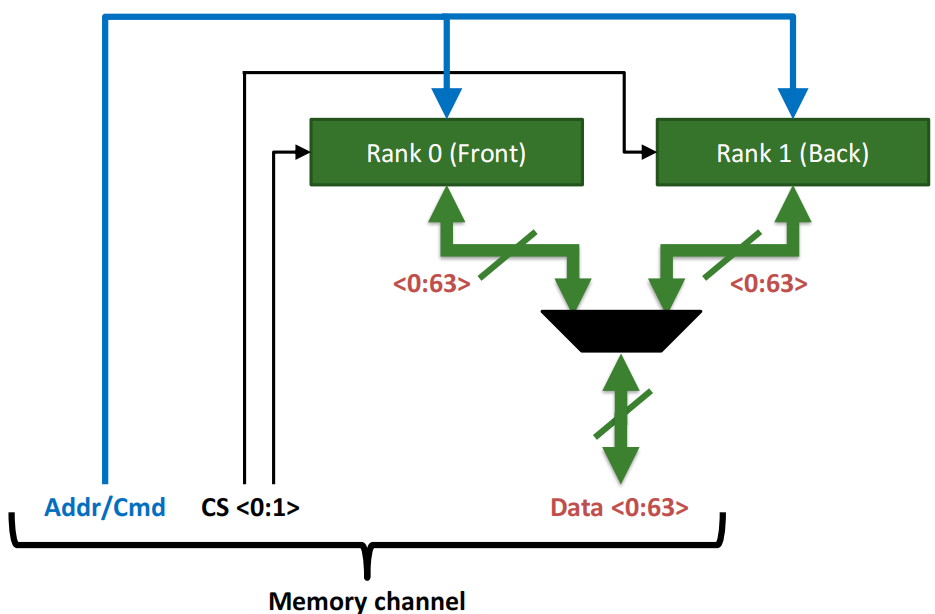
每个 Memory channel 包括:
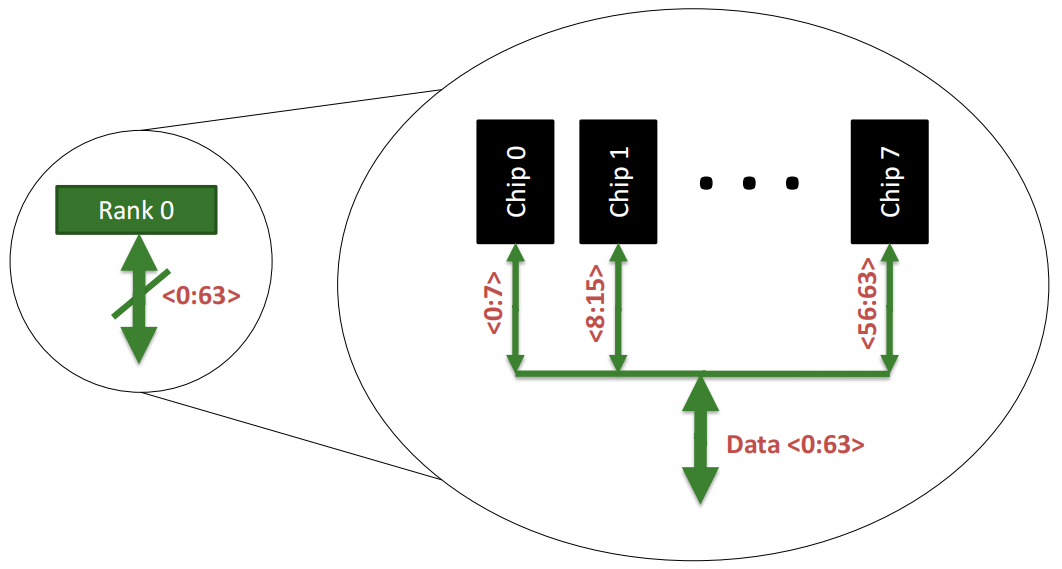
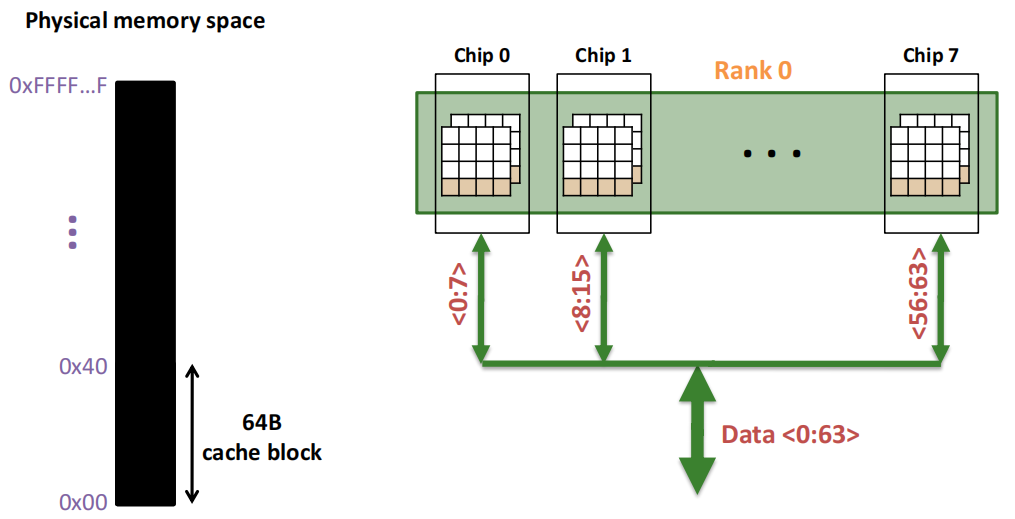
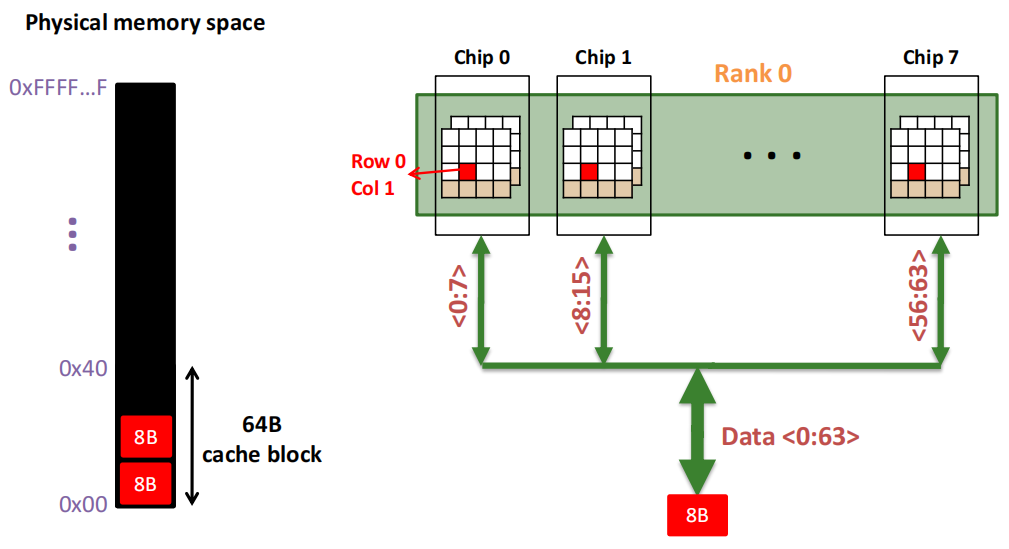
一个内存 Rank 内部是由多个芯片(Chip)构成的:
Rank 0被分解为多个芯片,从Chip 0到Chip 7。每个芯片负责部分数据位:
64位数据通道:所有芯片通过各自负责的8位数据位共同组成了64位的数据通道(Data <0:63>),从而实现并行数据的传输。这种设计允许Rank内多个芯片同时工作,提高了数据访问效率.
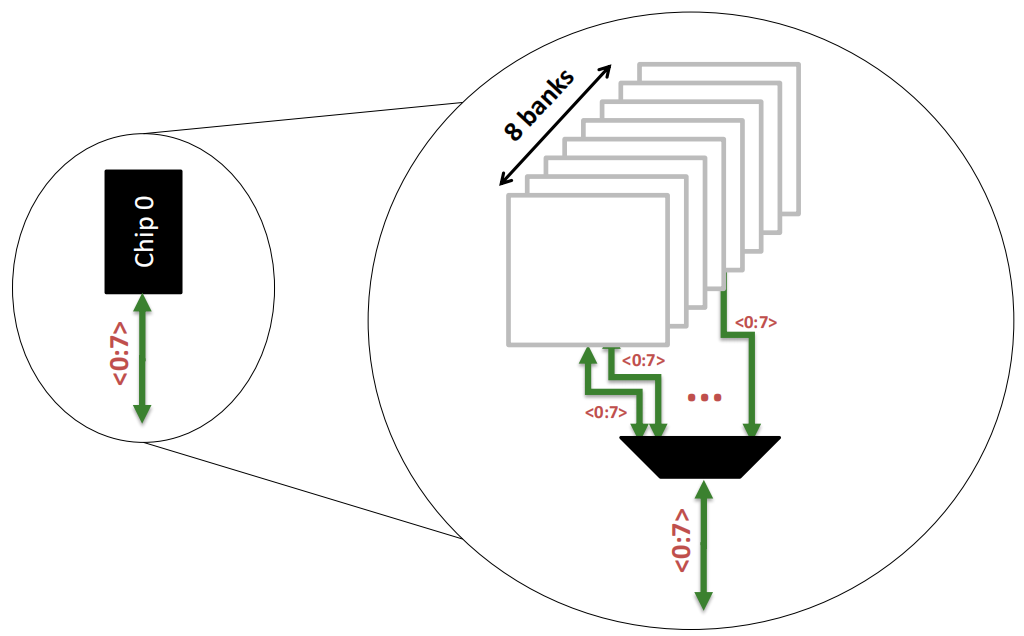
一个内存 Chip 内部是由多个存储库(Banks)构成的:
Chip 0:图的左侧的 Chip 0,它负责8位的数据通道(<0:7>),表示该芯片只传输数据的0到7位.
内部存储单元(Banks):在右侧的放大图中,Chip 0进一步被分解为8个独立的存储单元(称为“Banks”)。每个Bank都可以独立地存储和读取数据,允许芯片同时处理多个数据请求,提高数据传输的并行性.
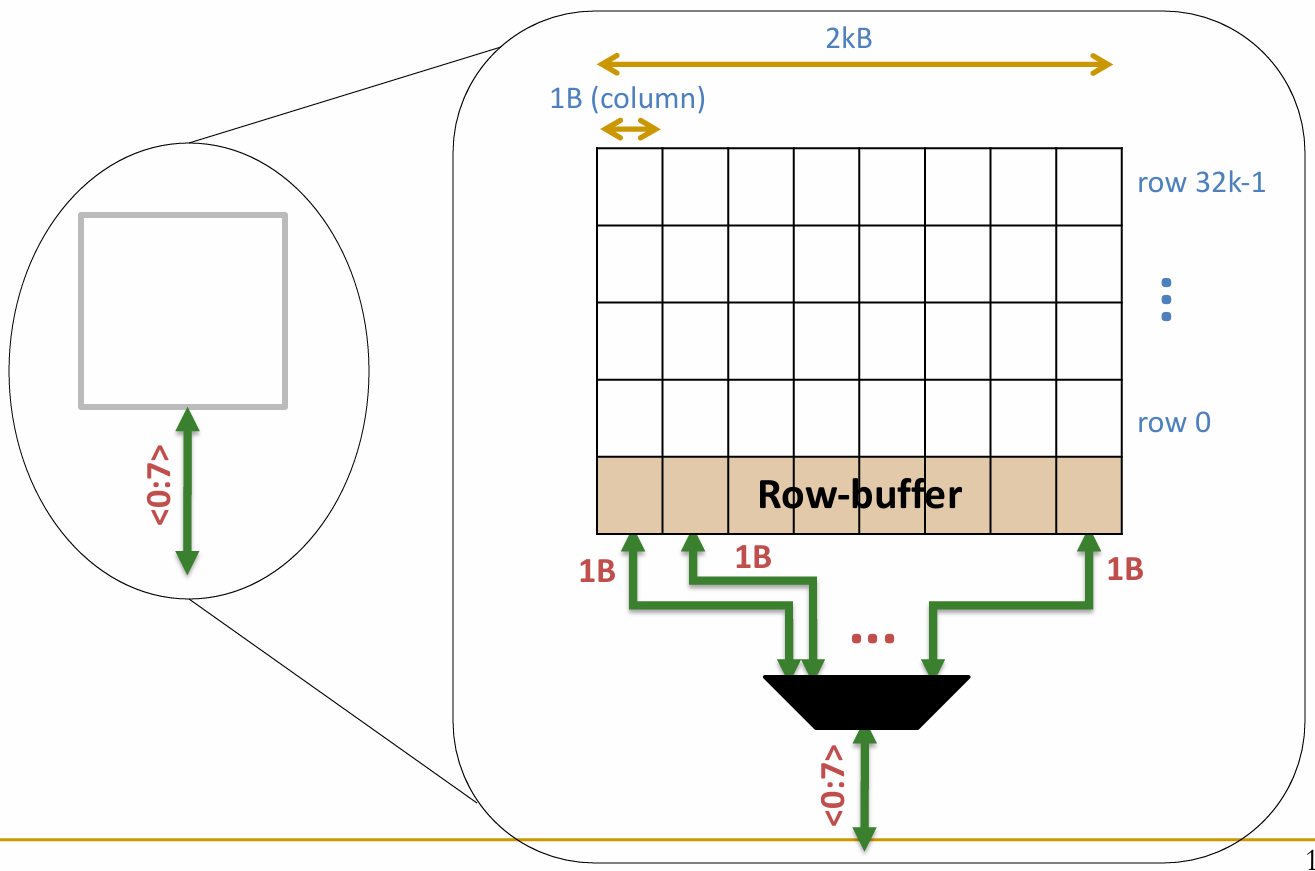
一个内存 Bank 内部是由多个大小为 1Byte 的 Arrays构成的:
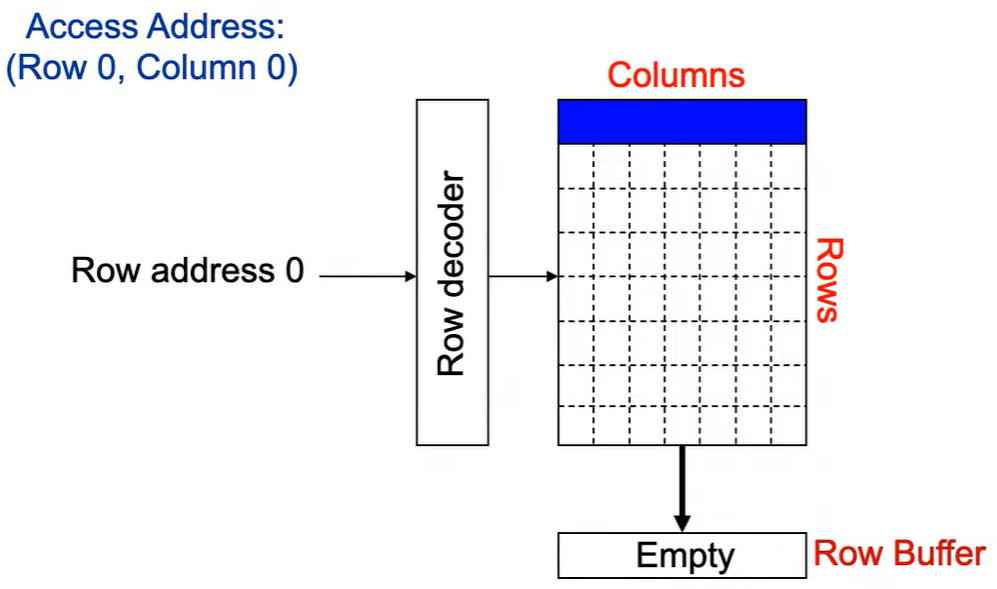
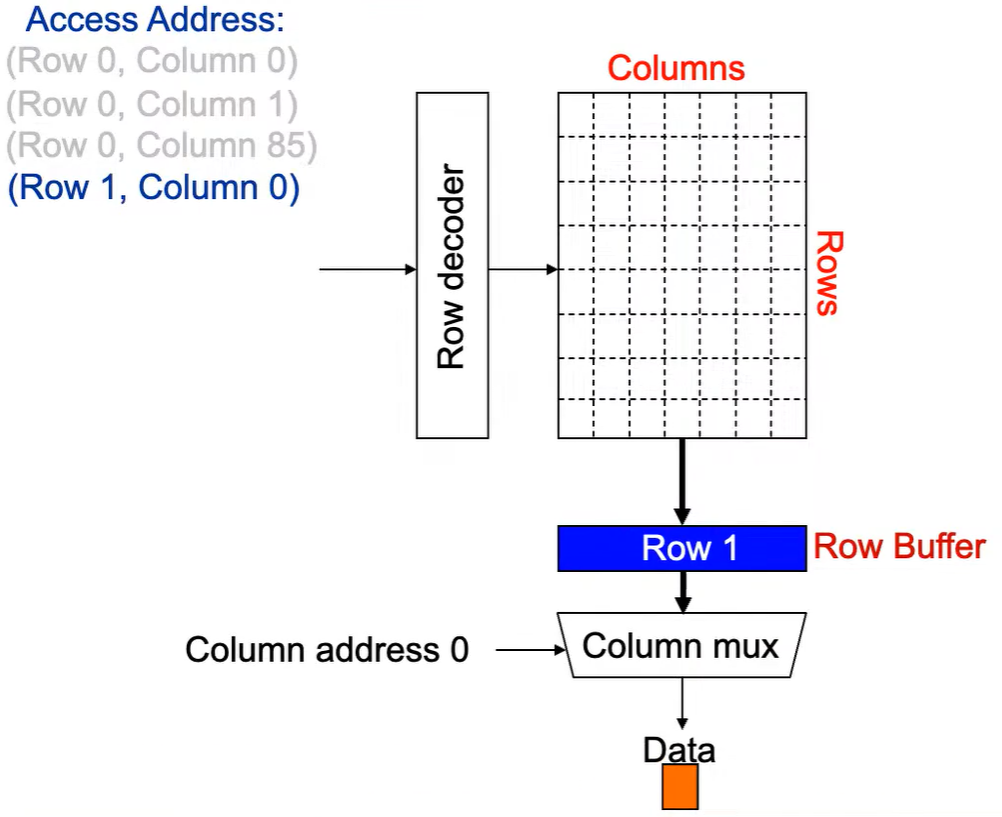
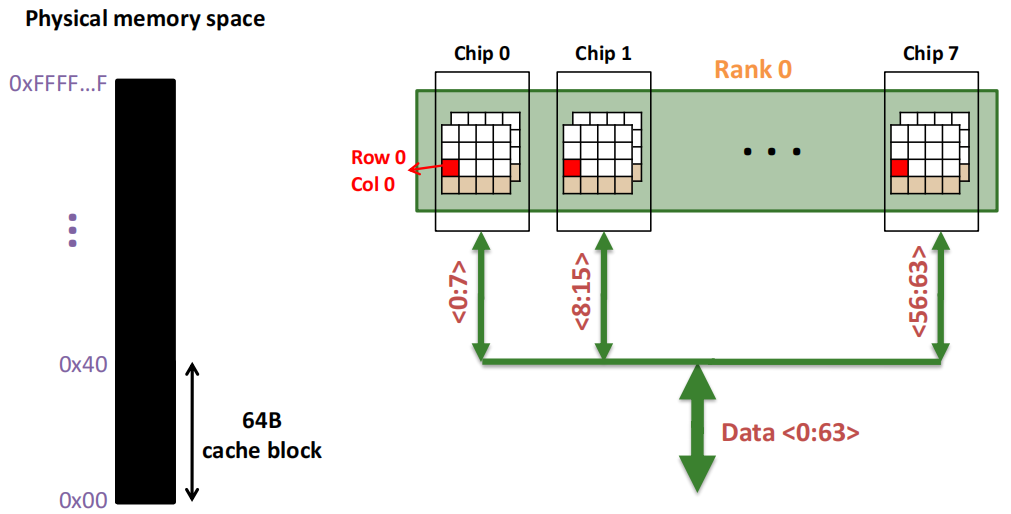
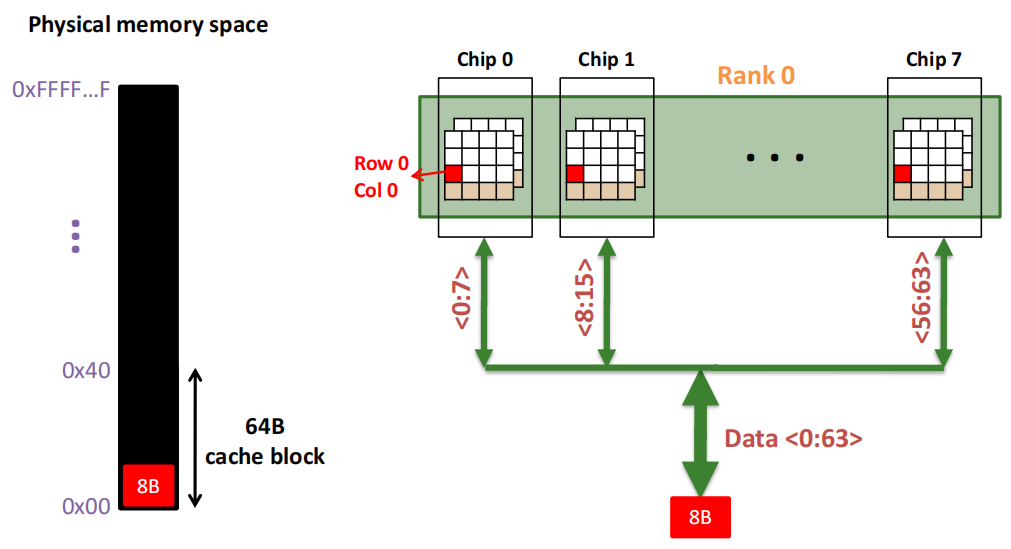
第1次访问(Row,Column 0):
Step 1: Row address 0到达,word-lines 被激活,bit-lines 被连接到感测放大器.
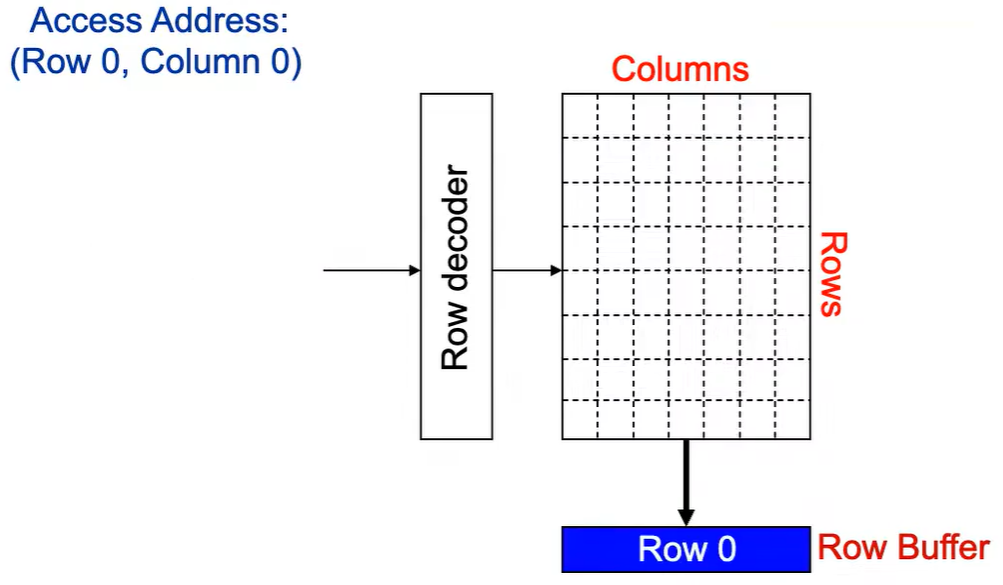
Step 2:感测放大器感知该行内容,捕捉数据放入 Row Buffer.
Step 3:Column address 0到达,选择列.
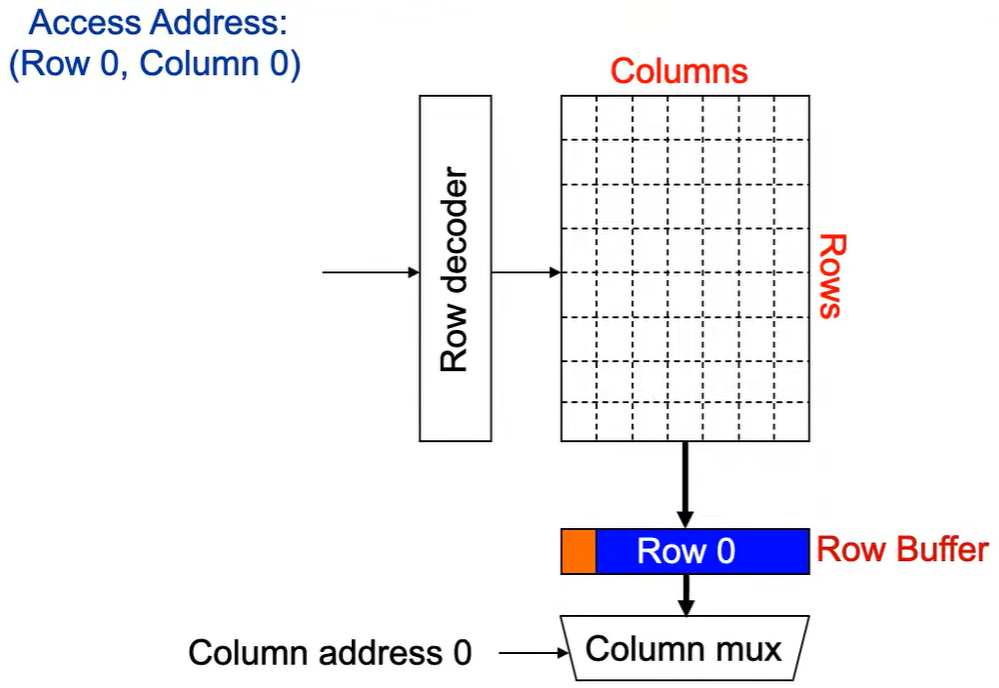
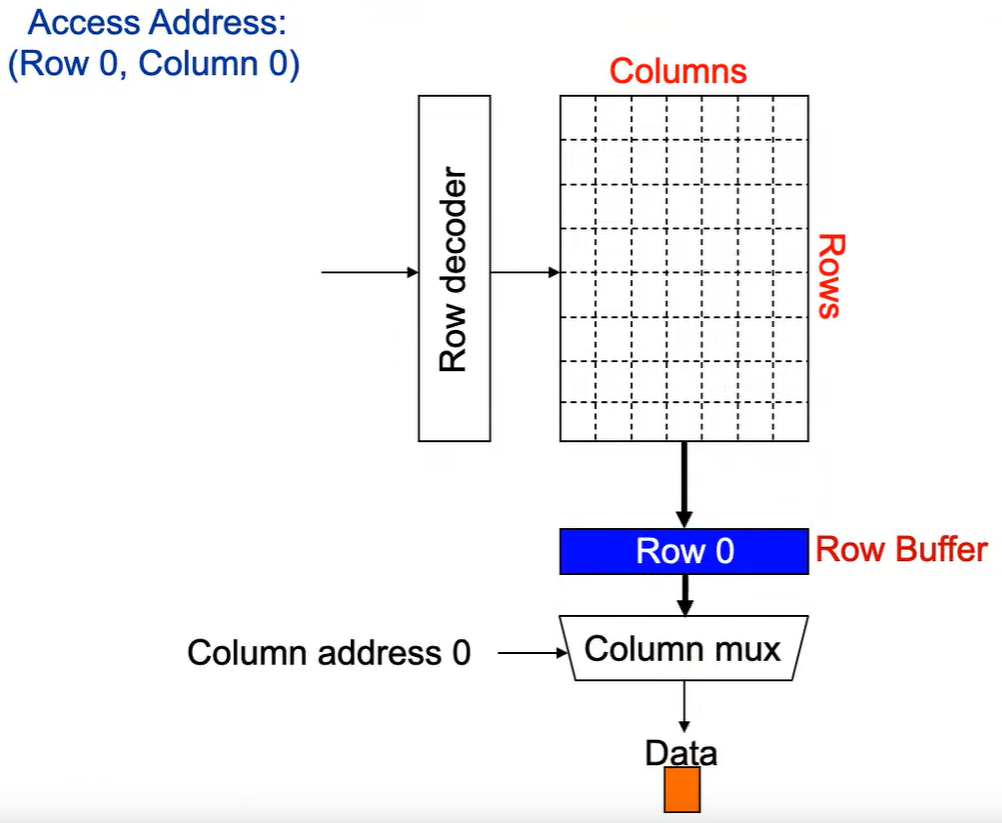
Step 4:最后数据被读出.
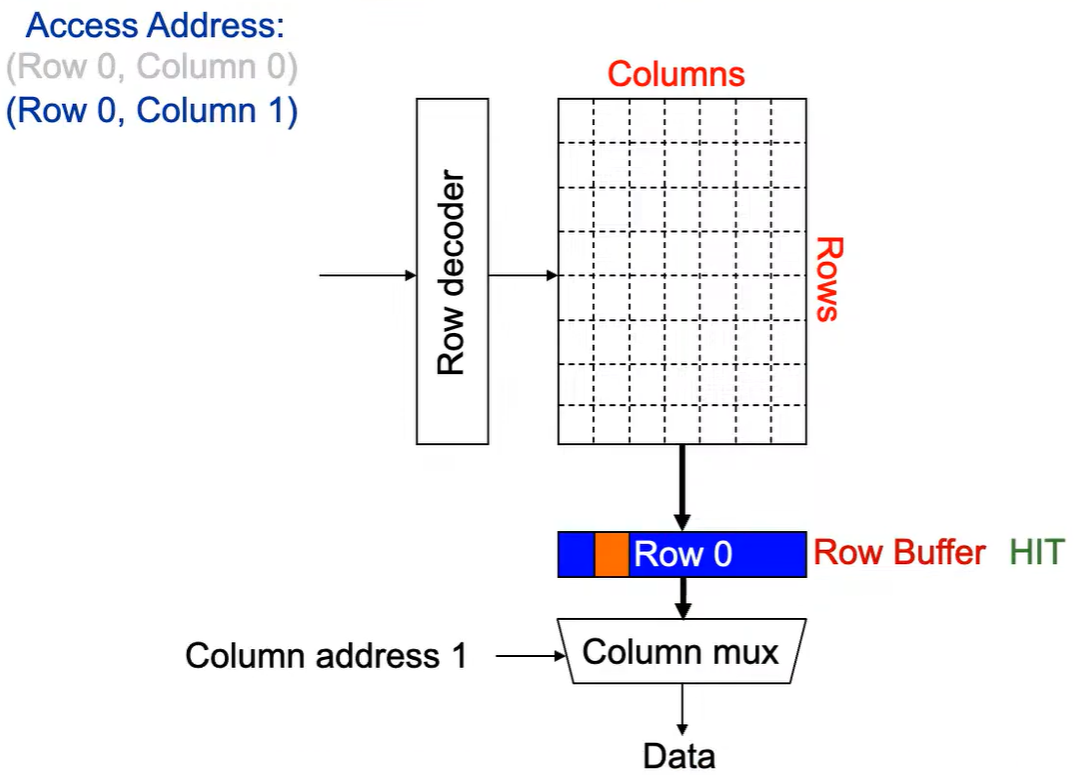
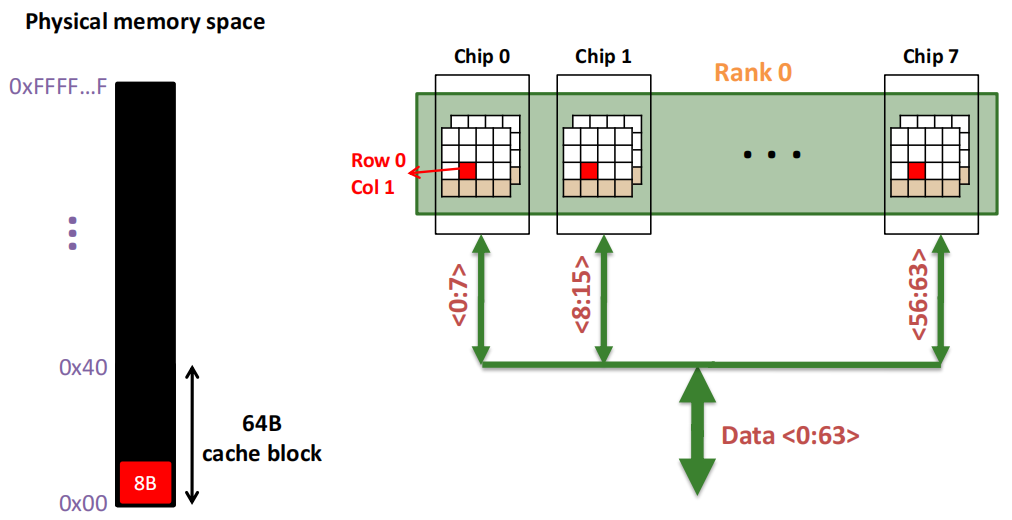
第2次访问(Row 0,Column 1):
由于 Row Buffer HIT,数据很快被读取出.
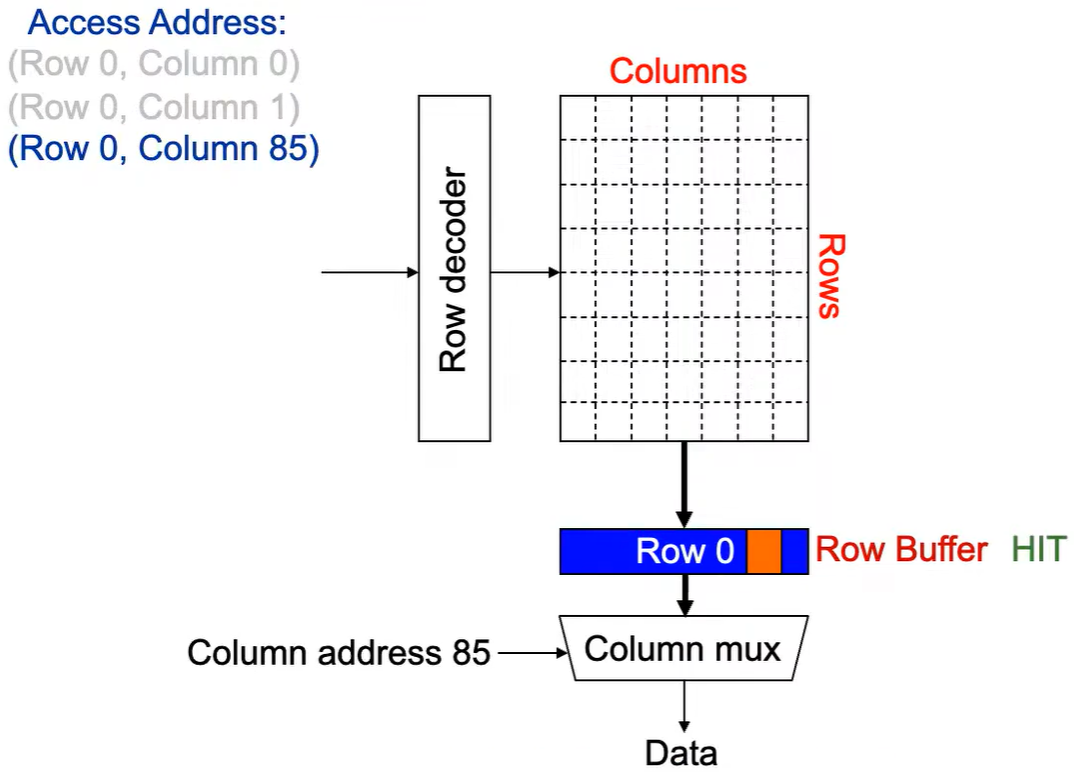
第3次访问(Row 0,Column 85):
同样由于 Row Buffer HIT,数据很快被读取出.
第4次访问(Row 1,Column 0):
出现 Row Buffer Conflict(冲突)! 。
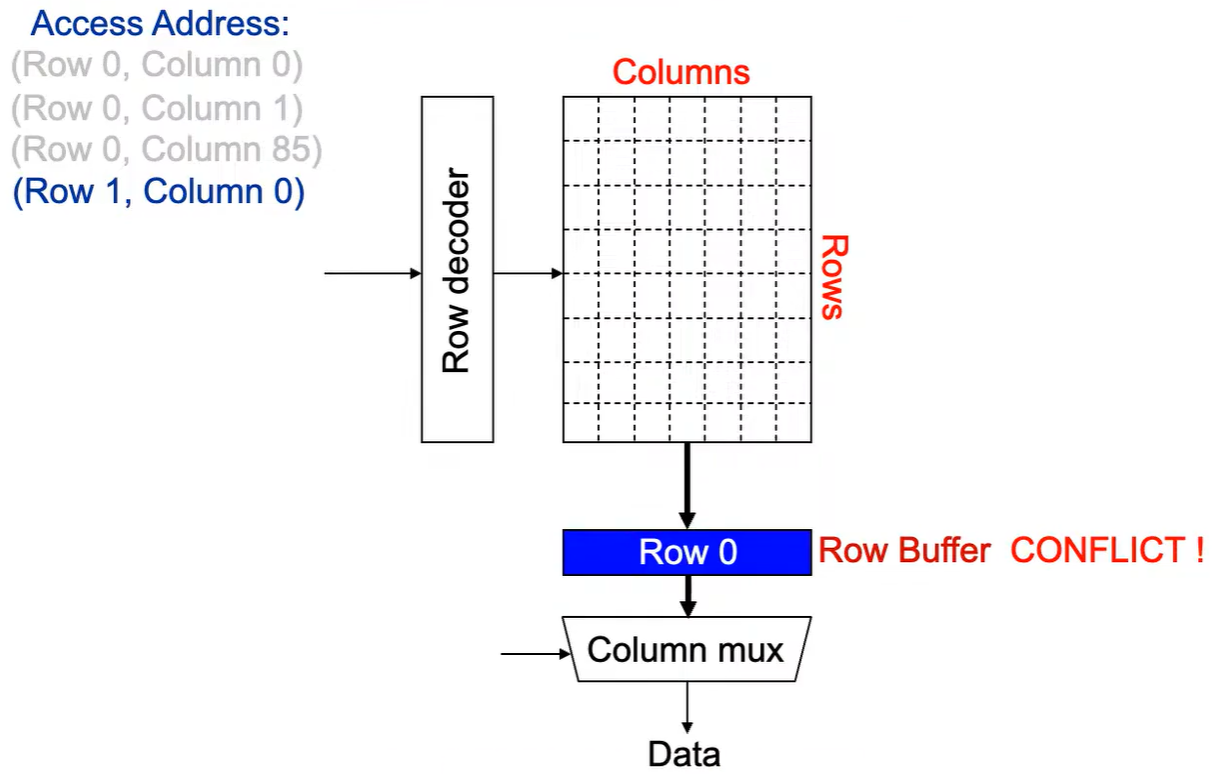
Step 1:将行写回,即预充电,使得下次访问的数据可靠,增加了延迟.
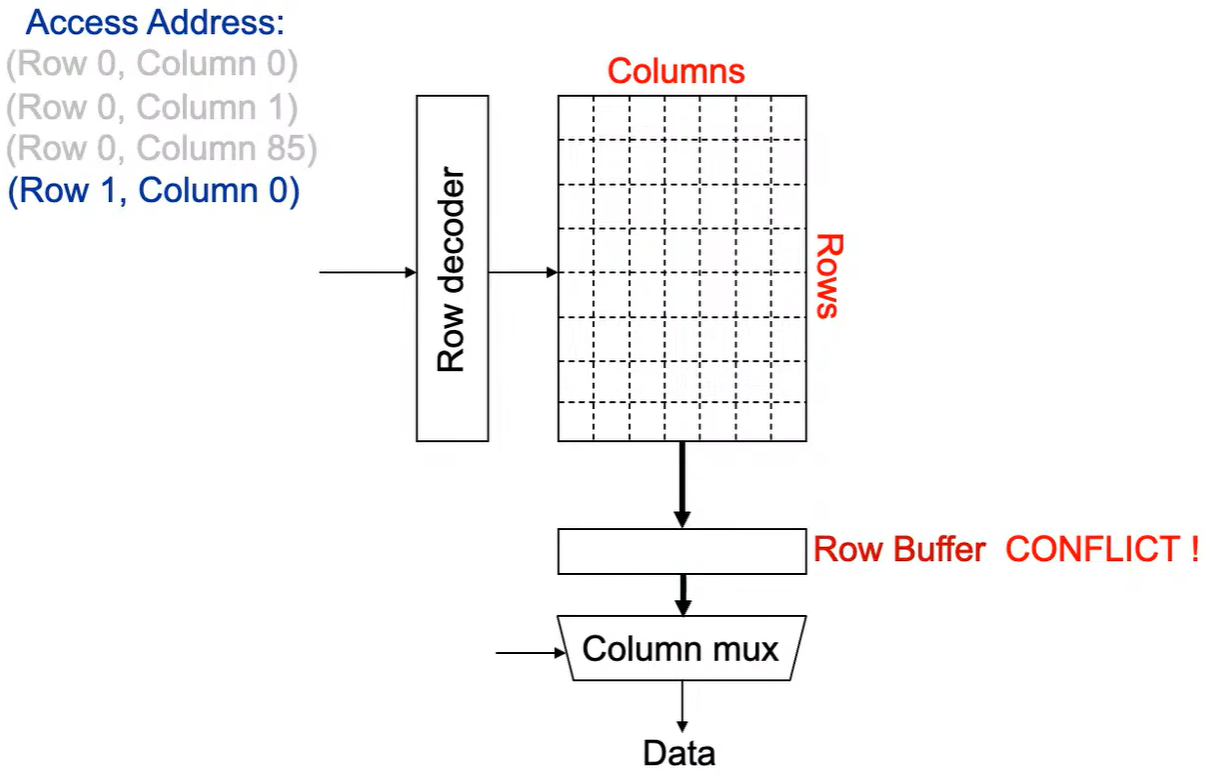
Step 2:Row address 1到达,word-lines 被激活,bit-lines 被连接到感测放大器.
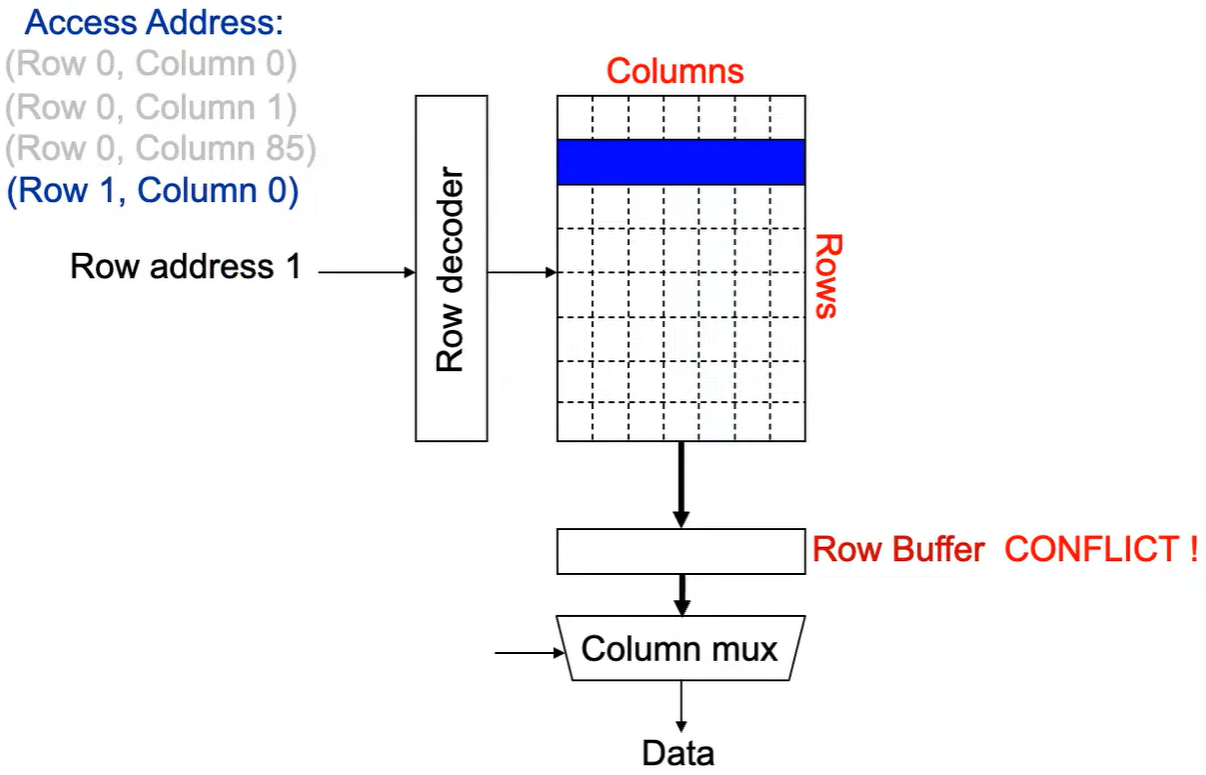
Step 3:感测放大器感知该行内容,捕捉数据放入 Row Buffer.
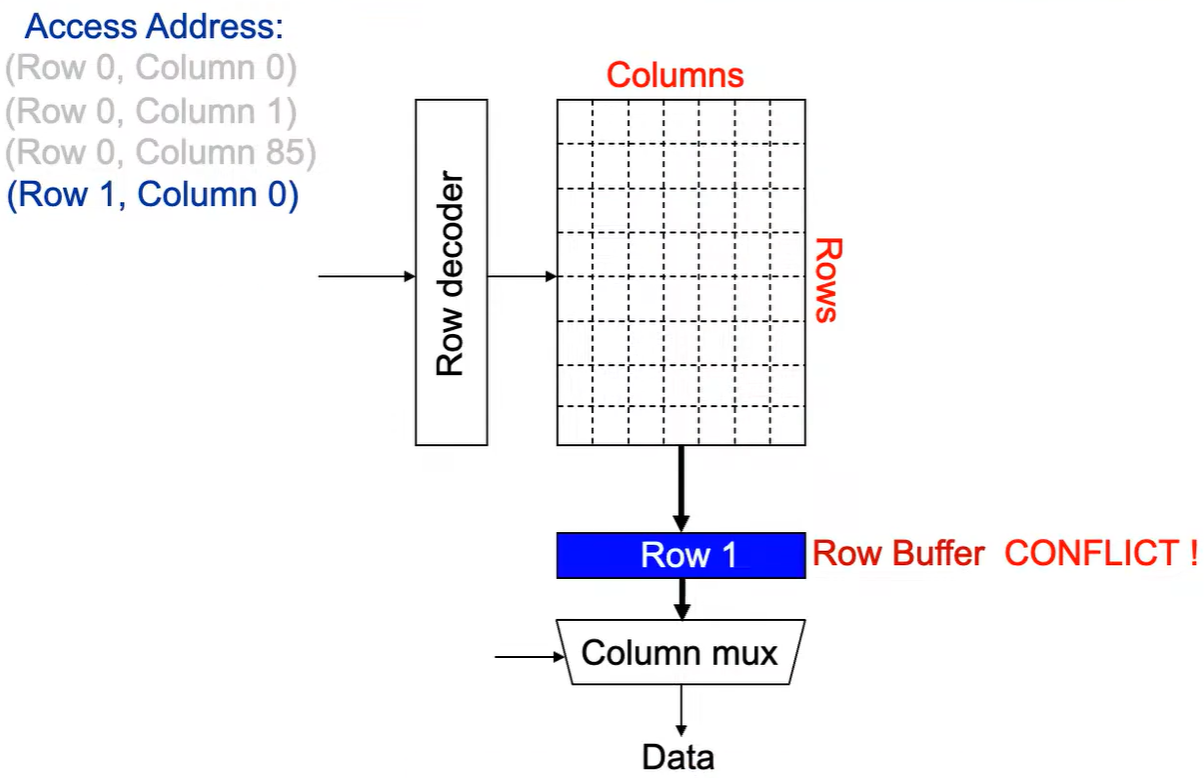
Step 4:Column address 0到达,选择列.
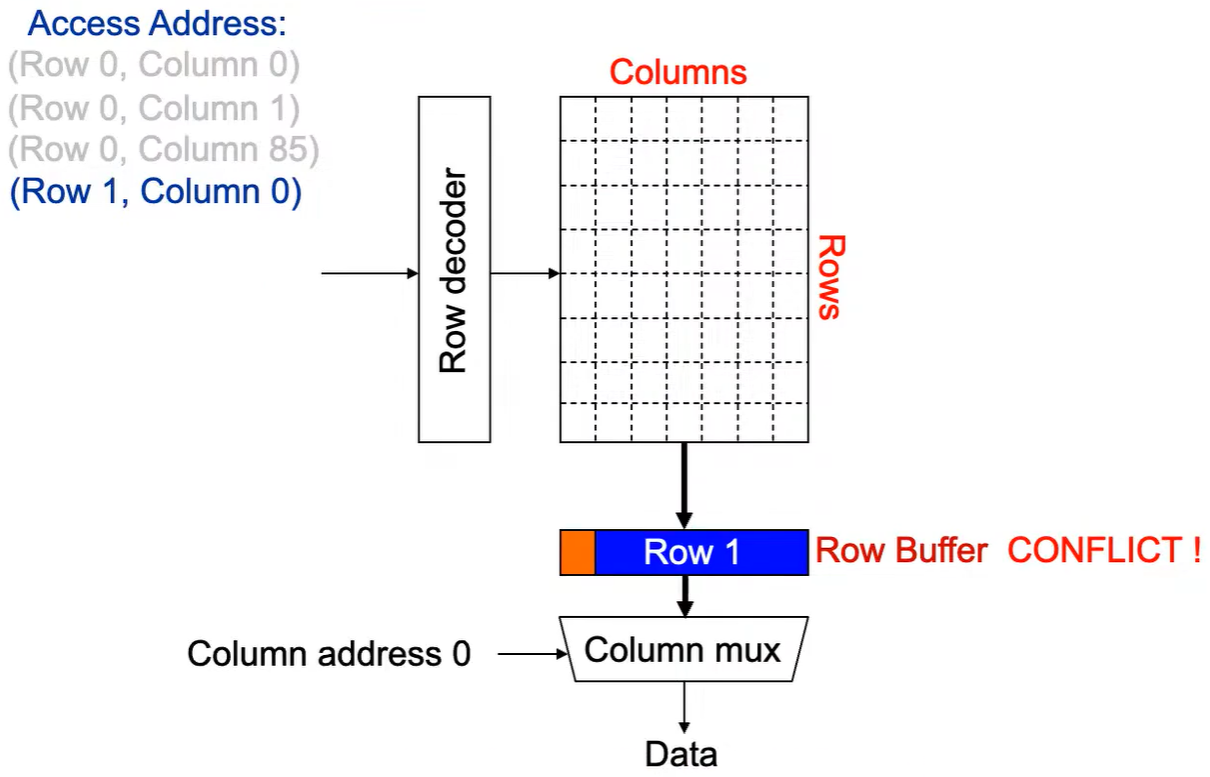
Step 5:最后数据被读出.
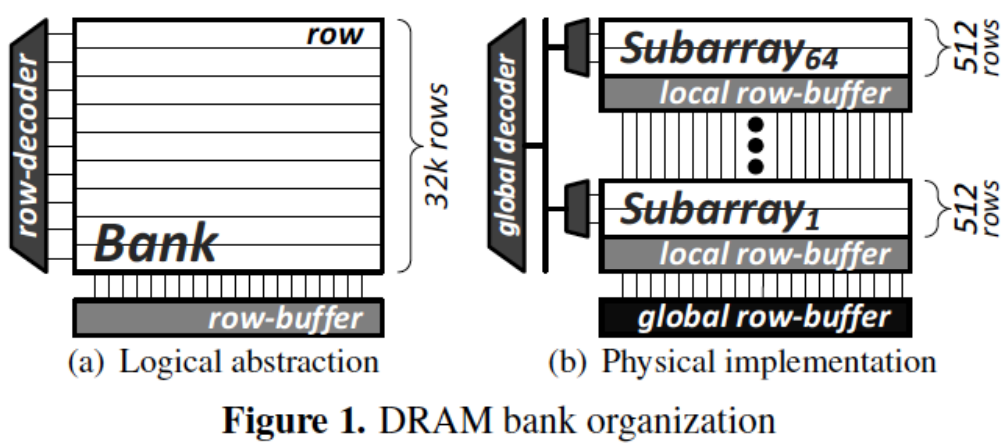
左图 (a) 是逻辑抽象图,展示了一个 DRAM bank 的传统表示法,其中包含行(row)、行解码器(row-decoder)和一个大的行缓冲区(row-buffer)。在逻辑抽象中,bank 似乎是一个整体,有着多达 32K 行的数据.
右图 (b) 是实际的物理实现。一个 DRAM bank 实际上被分割为多个子阵列 (Subarray),每个子阵列拥有自己的局部行缓冲区 (local row-buffer),并且每个子阵列由512行组成。这里显示了从第1个子阵列到第64个子阵列的结构。这些子阵列通过全局解码器 (global decoder) 连接到整个 bank 的全局行缓冲区 (global row-buffer).
这种设计通过将 bank 分为多个子阵列来增强访问速度和并行性,从而减少等待时间并提升DRAM性能.
Step 1:
Step 2:
Step 3:
Step 4:
读取和写入操作使用同一条总线.
在切换读取和写入操作时,必须反转总线方向;这需要时间,并导致总线空闲.
因此,写入操作通常以突发方式进行;写缓冲区会存储待处理的写入,直到达到高水位标记.
写入操作会一直进行,直到达到低水位标记.
高水位标记(High Water Mark):这是缓冲区中数据达到的一个预定的上限。当缓冲区中的数据量达到这个标记时,系统就会触发某些操作,例如开始写入数据(如在存储器中)或停止进一步的数据写入到缓冲区中,以避免缓冲区溢出.
低水位标记(Low Water Mark):这是缓冲区中的数据量达到的一个预定的下限。当缓冲区中的数据量减少到这个标记时,系统可以重新开启数据写入或进行其他操作,确保缓冲区不会因为数据不足而影响性能.
FCFS(先到先服务):处理队列中第一个可以执行的读或写请求.
First Ready - FCFS(优先行缓冲命中 - 先到先服务):优先处理行缓冲命中的请求,如果可能的话.
Stall Time Fair(等待时间公平):优先处理行缓冲命中的请求,除非其他线程被忽略了.
这个策略在优先行缓冲命中的基础上增加了公平性。如果多个线程在竞争内存访问,则该策略会在尽量优先行缓冲命中的同时,保证所有线程都能得到公平的访问机会,不让某些线程一直被延迟。这种方法有助于平衡多线程环境下的资源分配.
DRAM(动态随机存取存储器)中的每个存储单元都由电容存储电荷来表示数据。由于电容电荷会随时间逐渐泄漏,因此需要定期刷新来补充电荷,以确保数据不丢失.
刷新时间窗口:所有DRAM单元必须在64毫秒内刷新一次,防止数据因电荷泄漏而丢失.
自动刷新:当对某一行执行读或写操作时,该行会自动进行刷新,帮助延长数据保持时间.
刷新指令的影响:每次刷新指令会刷新一定数量的行。在刷新过程中,内存暂时不可用,这可能导致微小的延迟.
刷新频率:内存控制器通常会平均每7.8微秒发出一次刷新指令,以分散刷新负担,避免集中刷新带来的性能影响.
最后此篇关于DDCA——内存架构和子系统&内存控制器的文章就讲到这里了,如果你想了解更多关于DDCA——内存架构和子系统&内存控制器的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
56
4
 0
0
本文实例讲述了YII2框架中使用RBAC对模块,控制器,方法的权限控制及规则的使用。分享给大家供大家参考,具体如下: 在使用YII2中自带的RBAC时,需要先配置config/web.php:
添加路由 复制代码 代码如下: Route::get('artiles', 'ArticlesController@index'); 创建控制器
目录 一.系统环境 二.前言 三.StatefulSet简介 四.有状态应用和无状态应用区别 五.St
目录 一.系统环境 二.前言 三.Kubernetes 控制器 四.Deployment概览 五.创建
目录 一.系统环境 二.前言 三.DaemonSet 概览 四.创建DaemonSet 4
目录 一.系统环境 二.前言 三.ReplicationController概览 四.ReplicationCont
目录 一.系统环境 二.前言 三.ReplicaSet概览 四.ReplicaSet工作原理 五.Re
使用Yii2的时候,在某些场景和环境下需要获得Yii2目前所处于的module(模型)、Controller(控制器)、Action(方法),以及会调用控制器里面已经定义过的一些公共的方法等.对于这

我是一名优秀的程序员,十分优秀!