
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 65
65
 4
4


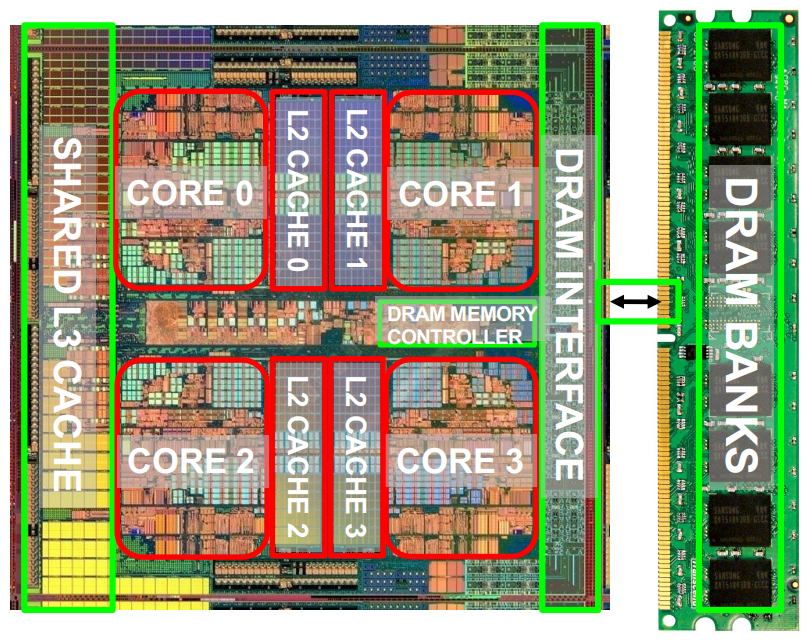

L3一般是共享的.
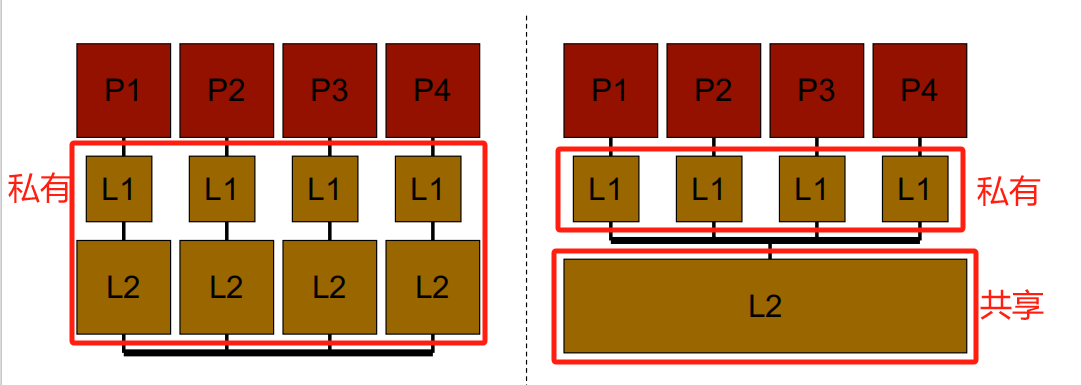
Idea:与其将一个硬件资源专门分配给一个上下游的硬件,不如让多个上下游的硬件共享使用它.
优点:
资源共享导致资源争夺 。
有时会降低每个或某些线程的性能 。
消除性能隔离,即运行时性能不一致 。
无控制(自由共享)共享会降低QoS 。
因此,需要高效、公平地利用共享资源.
优点:
缺点:
Example:
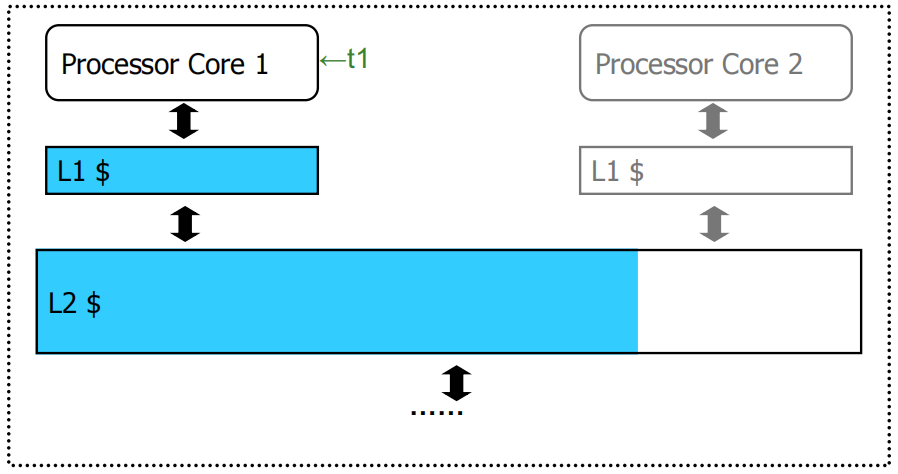
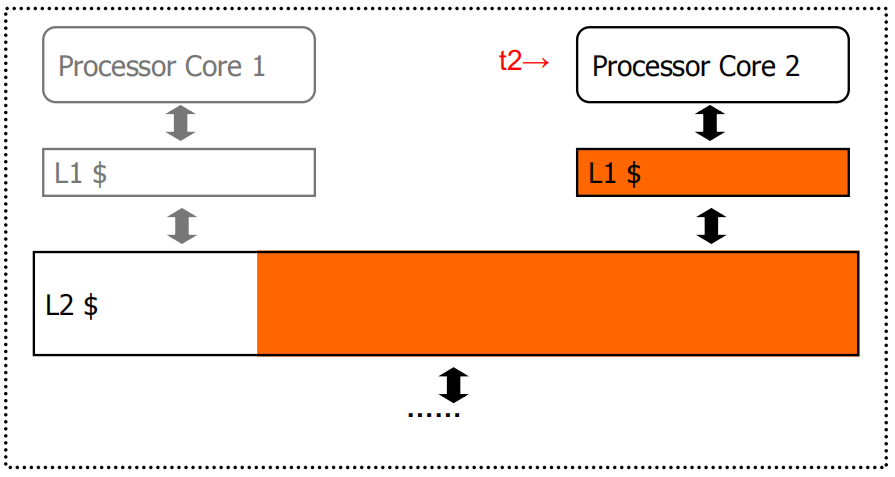
Core 1单独运行 t1 时需要共享缓存L2中蓝色区域大小的空间,Core 2 单独运行 t2 时需要共享缓存L2中橙色区域大小的空间,当这两个 Core 同时运行时,由于不公平的缓存共享,t2 的吞吐量会大幅降低.
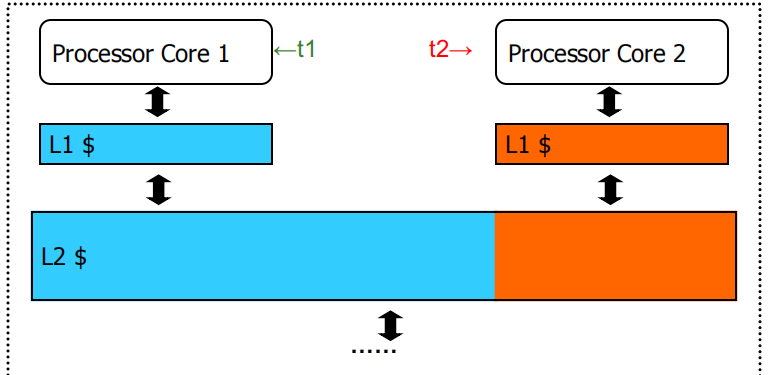
目前,小尺寸缓存都是统一缓存访问(Uniform Cache Access, UCA):即无论数据在哪里被找到,访问延迟都是一个恒定的值.
对于大型的多兆字节缓存,按最坏情况的延迟来限制访问时间代价太高,因此引入了非均匀缓存架构(Non-Uniform Cache Architecture).
在 NUCA 架构中,CPU与多个缓存单元相连接,每个缓存单元可能有不同的访问延迟,这与传统的统一缓存访问架构不同。由于缓存较大,无法保证所有缓存单元的访问延迟相同,因此引入了NUCA架构来解决这个问题.

NUCA架构中需要解决的几个关键问题:
Mapping(映射):如何将内存地址映射到不同的缓存单元,以便高效地存取数据.
Migration(迁移):如何在不同缓存单元之间移动数据,以尽量减少访问延迟。例如,频繁使用的数据可以迁移到更接近CPU的缓存单元中.
Search(查找):如何高效地搜索缓存中的数据,确保找到目标数据所在的缓存单元.
Replication(复制):如何在不同缓存单元中复制数据,以提高访问速度并减少通信延迟.
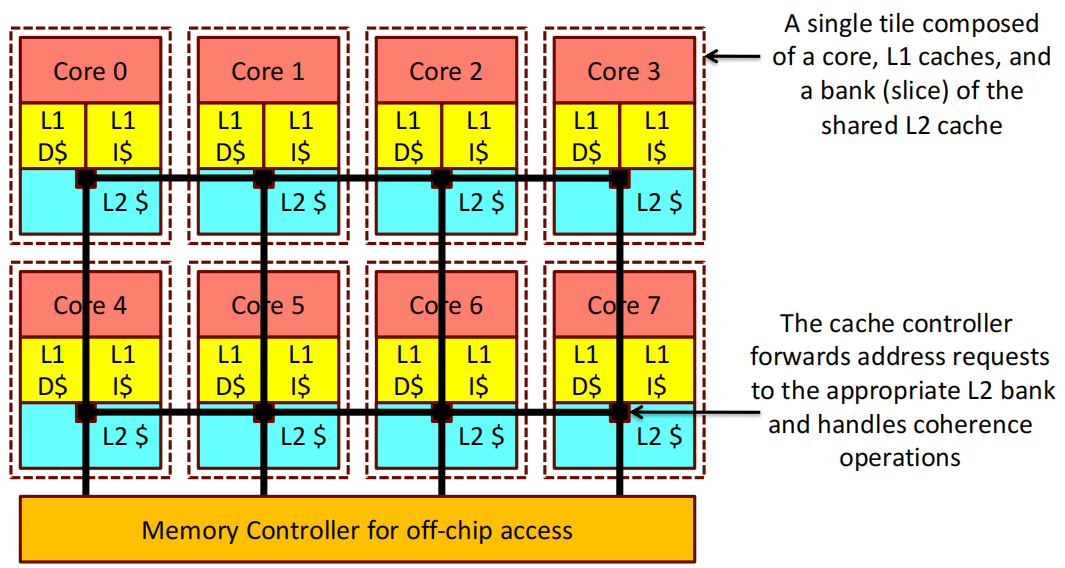
这张图片展示了一个多核处理器的结构,其中每个 Core 都有自己的L1缓存(L1 D 和 L1 I)以及共享的L2缓存切片。并且每个 Core 的L1缓存和L2缓存切片组合在一起,构成了一个独立的单元(Tile).
程序员看到的是虚拟内存 。
事实上,物理内存大小比程序员假设的小得多 。
系统(系统软件+硬件,相互配合)将虚拟内存地址映射到物理内存 。
优点:程序员不需要知道内存的物理大小,也不需要对其进行管理 。
缺点:更复杂的系统软件和架构 。
程序员不处理物理地址 。
每个进程都有自己的虚拟地址与物理地址的映射关系 。
Enables 。
Examples
CPU 的加载或存储地址直接用于访问内存.

该系统存在的问题:
程序员需要管理物理内存空间 。
难以支持代码和数据的重分配 。
难以支持多个进程 。
难以支持跨进程的数据/代码共享 。
Idea:让程序员产生地址空间大而物理内存小的错觉 。
程序员可以假设拥有“无限”的物理内存 。
硬件和软件协同自动管理物理内存空间,以提供这种假象 。
寻址中的不定向 。
程序中每条指令生成的地址是一个“虚拟地址” 。
地址翻译机制将虚拟地址映射到物理地址 。
在x86架构中称为“实际地址(real address)” 。
地址翻译机制可以通过硬件和软件共同实现.
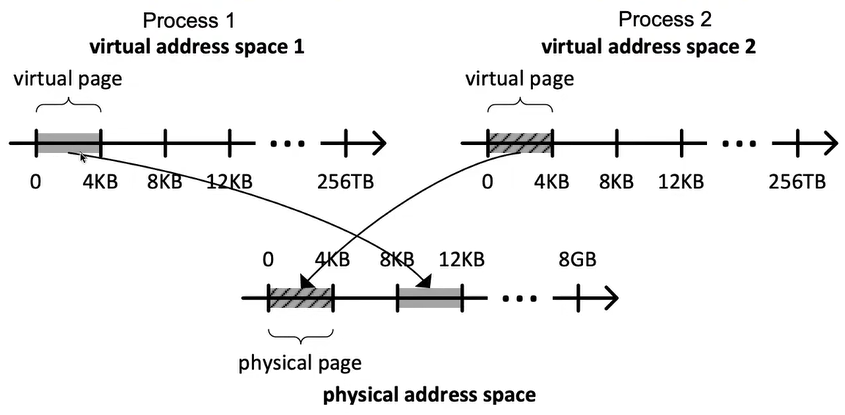
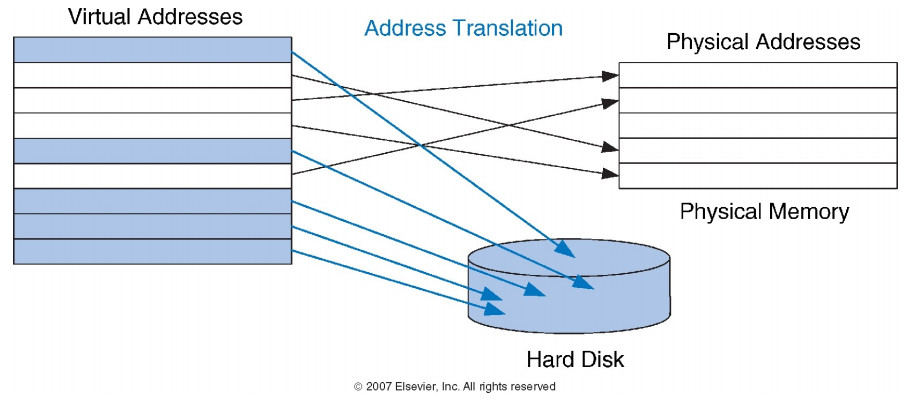
虚拟地址空间:
每个进程都有自己的虚拟地址空间,分别标为“virtual address space 1”和“virtual address space 2” 。
每个虚拟地址空间大小可以达到 256TB 。
虚拟地址空间被分成虚拟页面(virtual page),每个虚拟页面为4KB 。
物理地址空间:
地址映射:
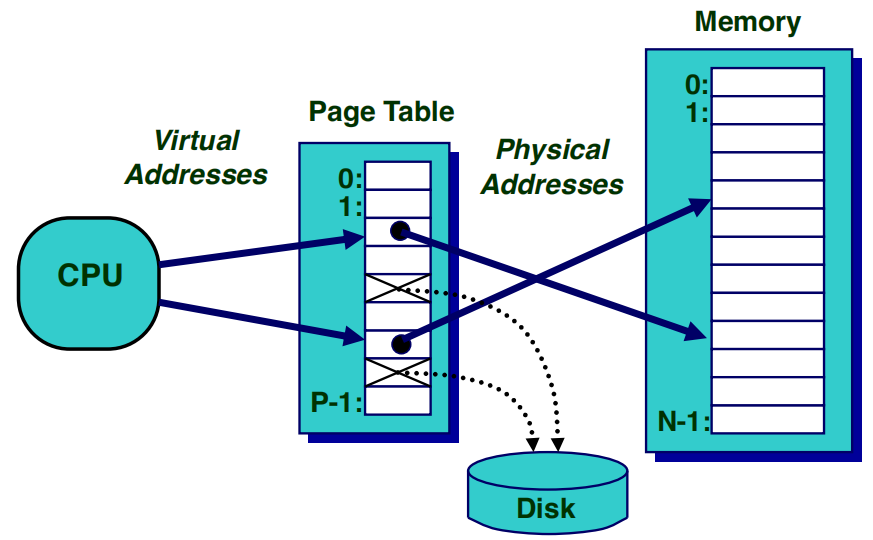
这张图片展示了基于分页机制的虚拟内存系统的工作原理,解释了虚拟地址如何通过页表转换为物理地址.
换句话说,物理内存是用于存储在磁盘上的页面的缓存.
事实上,在现代系统中,它是一个全关联缓存(虚拟页面可以映射到任何物理帧) 。
与我们之前讨论的缓存问题类似,这里也有类似的问题:
很多概念都可以进行类比:
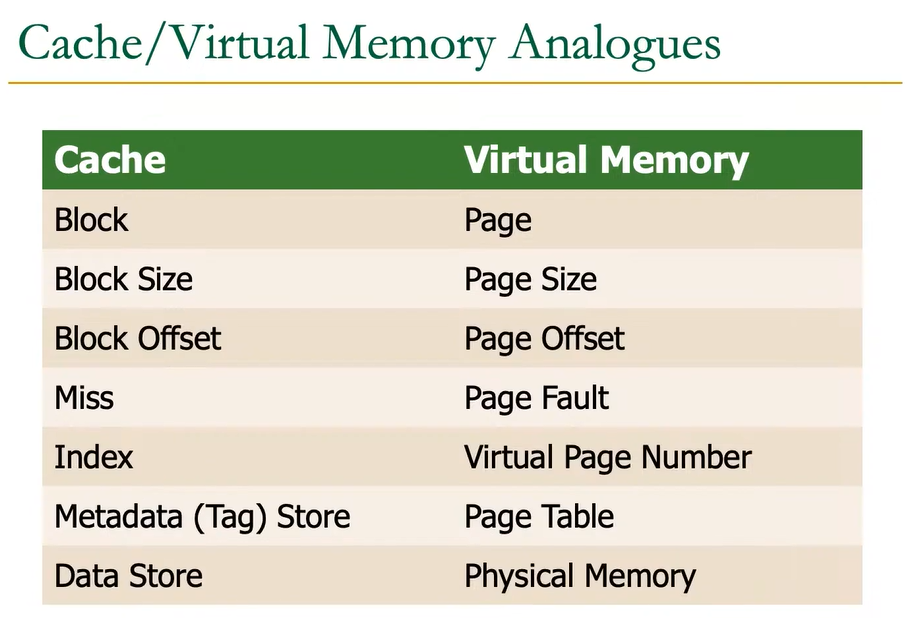
大多数访问都在物理内存中进行 。
但程序看到的虚拟内存容量很大 。
Example:
虚拟页面映射到物理页面的灵活性使得物理内存可以作为一个缓存,存储当前活跃的页面,同时支持地址空间隔离和更大的虚拟地址空间.
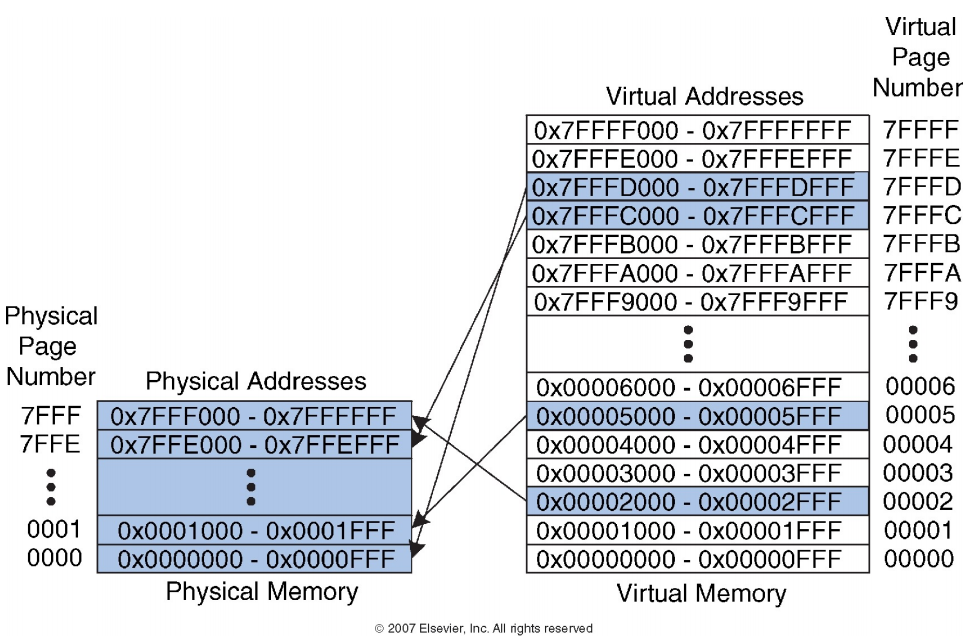
如上图所示,虚拟内存和物理内存都被划分为页(pages),每页大小为8KB.
虚拟地址(Virtual Address)分为两部分:
虚拟页号(Virtual Page Number):用于定位虚拟内存中的具体页.
页内偏移(Page Offset):13位偏移量,用于指定该页内的具体位置.
物理地址(Physical Address)分为两部分:

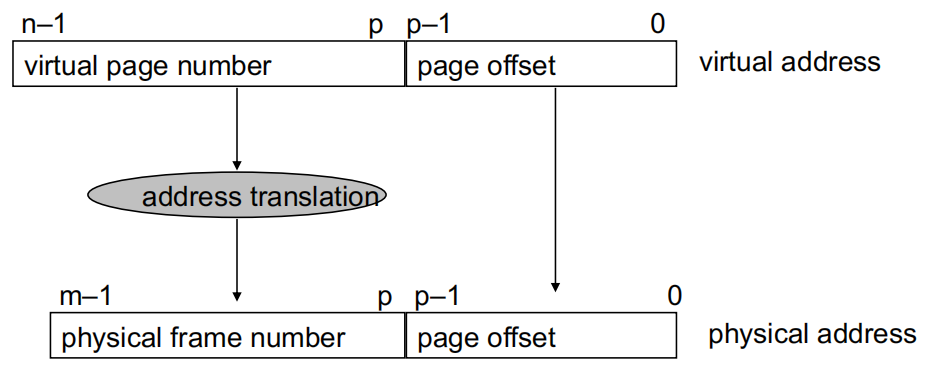
参数定义:
\(P=2^p\):页面大小,以字节为单位.
\(N=2^n\):虚拟地址空间大小.
\(M=2^m\):物理地址空间大小.
页偏移位在转换过程中不会改变.
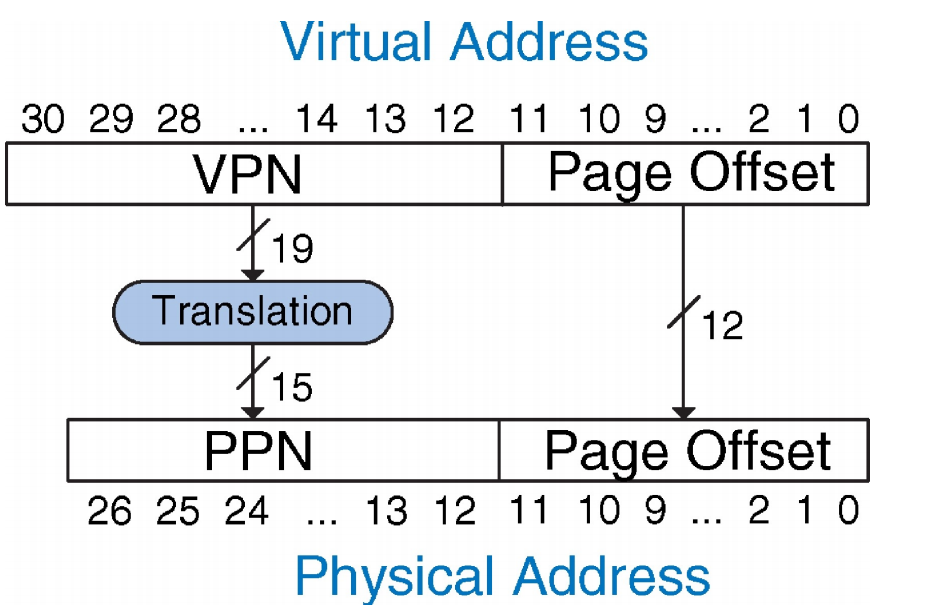
如上图所示:
系统配置:
虚拟内存大小:\(2\ GB = 2^{31}\ bytes\) 。
物理内存大小:\(128\ MB = 2^{27}\ bytes\) 。
页大小:\(4\ KB = 2^{12}\ bytes\) 。
组织结构:
虚拟地址:31 位 。
物理地址:27 位 。
页偏移:12 位 。
虚拟页数量 = \(2^{31} / 2^{12} = 2^{19}\)(虚拟页号占 19 位) 。
物理页数量 = \(2^{27} / 2^{12} = 2^{15}\)(物理页号占 15 位) 。
页表(Page Table) 。
每个页表条目都有:
我们如何访问页表?
页表基址寄存器(Page Table Base Register, PTBR)(x86 中为 CR3) 。
页表限制寄存器(Page Table Limit Register, PTLR) 。
如果虚拟页号 (VPN) 超出范围(超过 PTLR),则表示该进程未分配此虚拟页 -> 产生异常 。
页表基址寄存器是进程上下文的一部分 。
就像程序计数器 (PC)、状态寄存器和通用寄存器一样 。
当进程进行上下文切换时需要加载 。
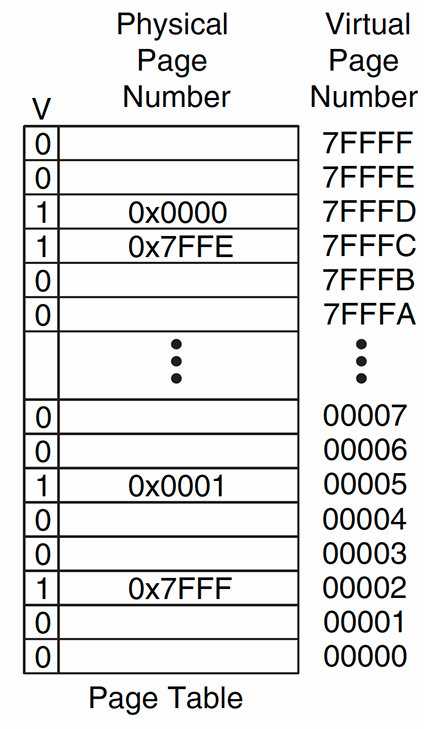
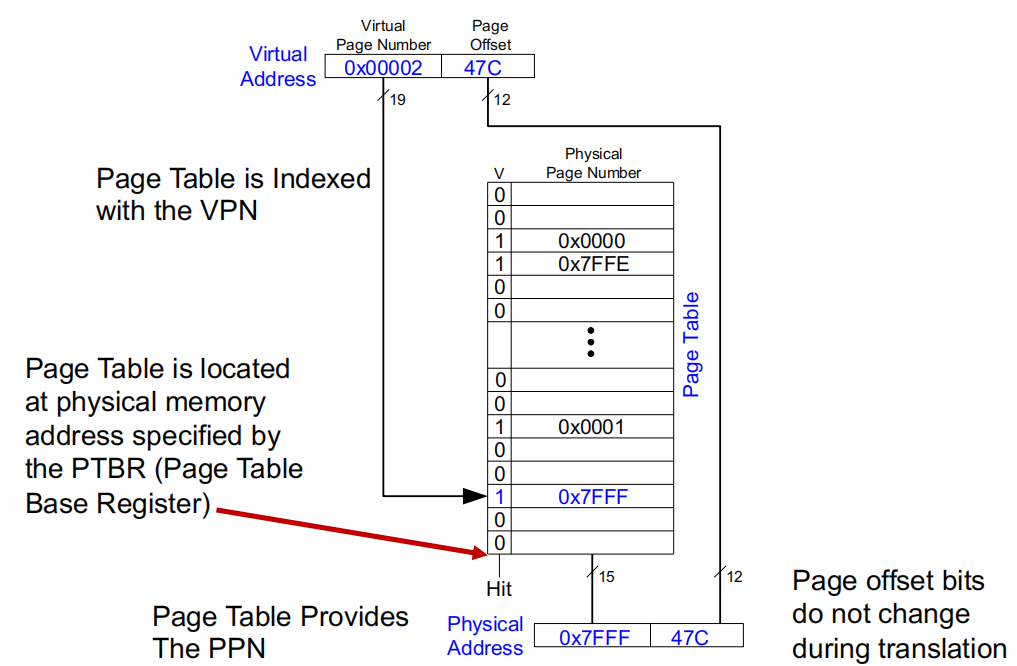
虚拟地址结构:虚拟地址由虚拟页号 (VPN) 和页偏移组成。在上图中,虚拟地址的虚拟页号为 0x00002,页偏移为 47C.
页表的索引:页表使用 VPN 作为索引,用于查找对应的物理页号 (PPN)。在图片中,页表中每一行代表一个页面映射条目,其中“V”位表示该条目是否有效.
页表基址寄存器 (PTBR):页表位于物理内存中,通过页表基址寄存器 (PTBR) 指定其起始地址。PTBR 提供了访问页表的入口.
页表提供 PPN:页表条目中包含物理页号 (PPN)。对于 VPN 为 0x00002 的条目,页表给出了相应的物理页号 0x7FFF.
地址转换:最终的物理地址由 PPN 和页偏移组合而成。在这个例子中,转换得到的物理地址是 0x7FFF47C.
页偏移不变:在地址转换过程中,页偏移部分不发生变化,直接从虚拟地址传递到物理地址.
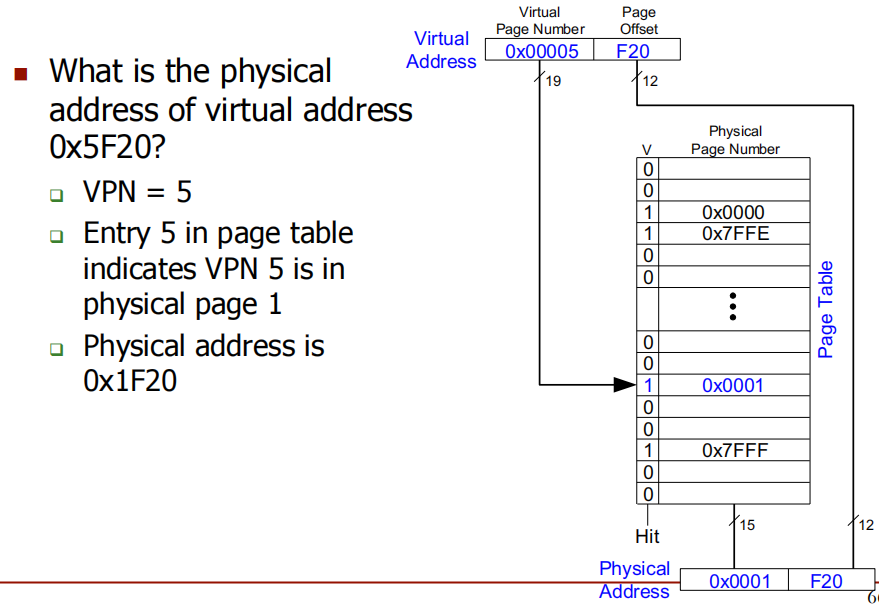
PTBR + VPN * PTE-size 处查找 PTE。Problem:虚拟地址 0x5F20 的物理地址是什么?
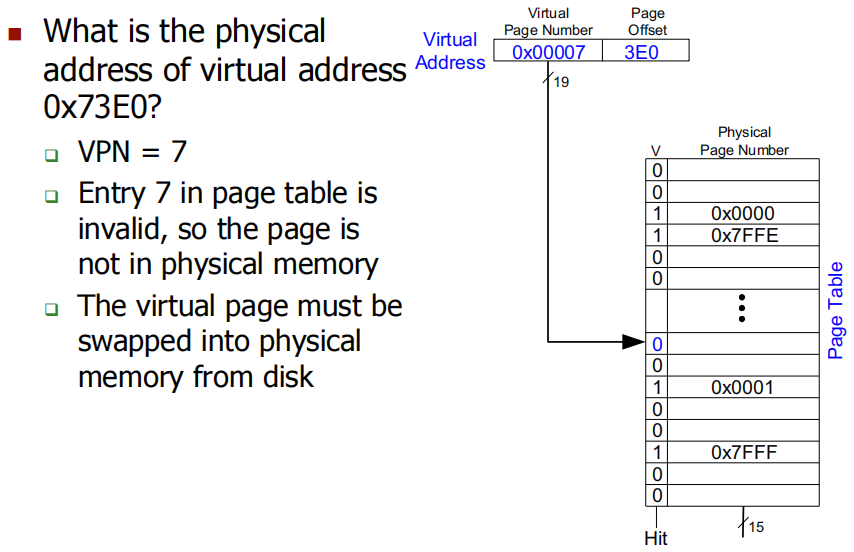
Problem:虚拟地址 0x73E0 的物理地址是什么?invalid,需要去Disk找 。
虚拟内存页可以放置在物理内存中的任意位置(全相联).
替换通常使用 LRU 策略(因为缺页的代价很大,所以我们可以投入一些努力来减少缺页).
使用页表(按虚拟页号索引)将虚拟页号转换为物理页号.
内存-磁盘层次结构可以是包含式或排除式,写策略为写回(write-back).
Challenge 1: Page table is large 页表很大 。
Challenge 2:每个指令获取或数据访存至少两次内存访问:
Challenge 3:我们什么时候进行与缓存访问相关的转换?

64 位虚拟地址(VA)被分成两部分,前52位是虚拟页号(VPN),后12位是页偏移(Page Offset),经过地址转换后变为 40 位物理地址(PA).
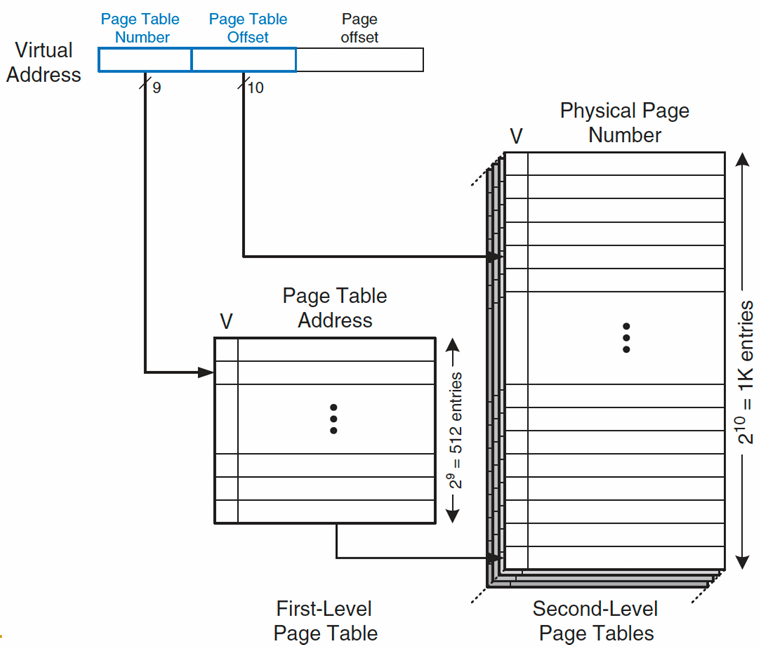
解决方法:多级页表 。
将页表组织成层次结构,这样只有一小部分的第一级页表需要位于物理内存中.
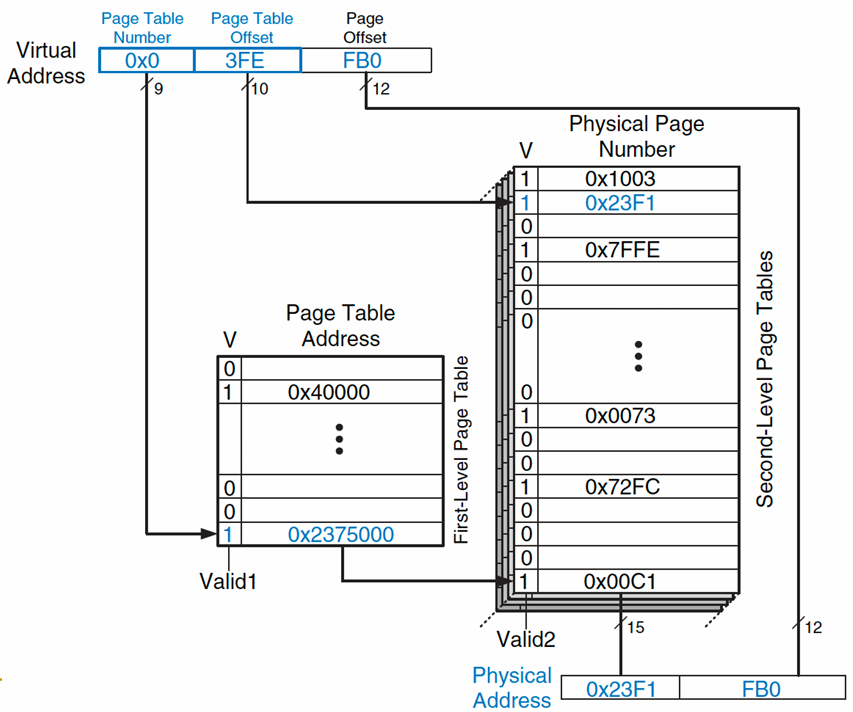
x86 架构示例:
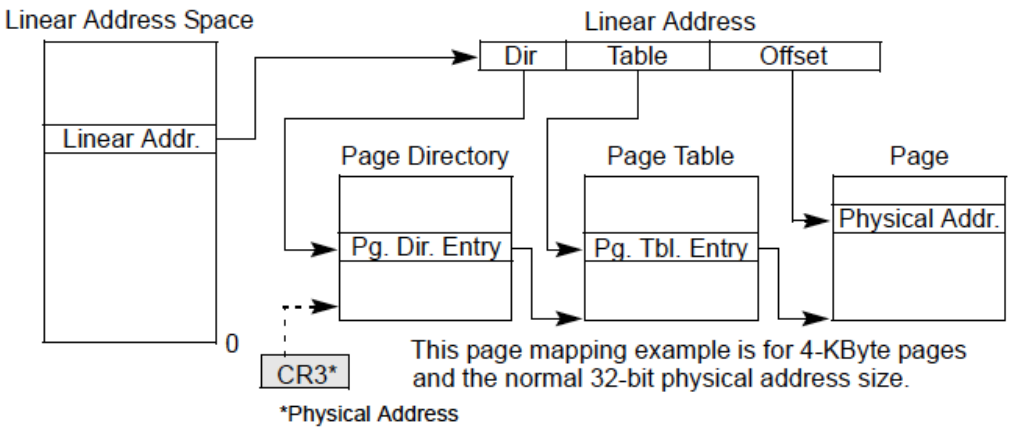
上图展示了线性地址到物理地址的映射过程,采用了两级页表的地址转换机制。这是一个基于 4KB 页表大小、32位物理地址空间的例子.
线性地址空间:线性地址由“目录”(Dir)、“表项”(Table)和“偏移”(Offset)三部分组成。这些字段用于索引分页结构以找到对应的物理地址.
页目录和页表:
页目录(Page Directory):线性地址的“目录”部分用于索引页目录,从而找到对应的页目录项(Pg. Dir. Entry).
页表(Page Table):页目录项指向页表的位置。线性地址的“表项”部分用于索引页表,找到对应的页表项(Pg. Tbl. Entry) 。
物理地址:
CR3寄存器:CR3寄存器保存页目录的物理地址,在地址转换时用于定位页目录.
优点:这种方法在不需要用到所有虚拟地址空间时特别有效,因为每一级的页表只有在需要时才会分配,从而减少了内存的浪费.
x84-64的4级页表:
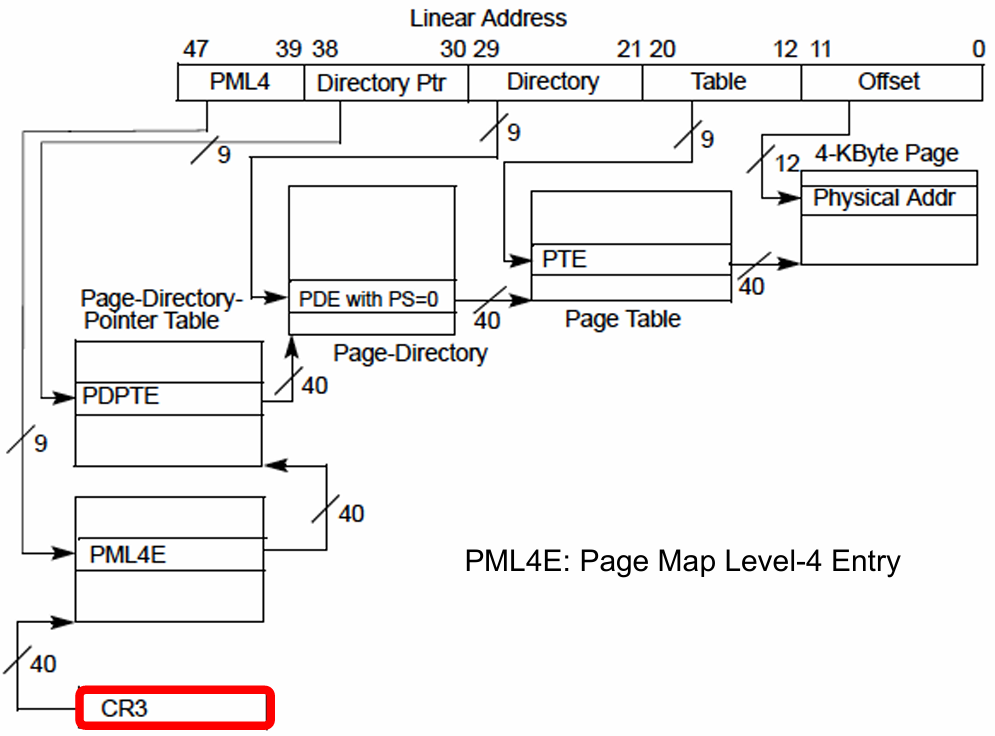
Idea:将页表条目(PTE)缓存在处理器的硬件结构中,以加快地址转换 。
Translation lookaside buffer(TLB):
缓存最近使用的 PTE 。
将大多数指令获取和数据访存所需的内存访问次数减少到只有一个 。
页表访问具有很大的时间局部性 。
TLB 。
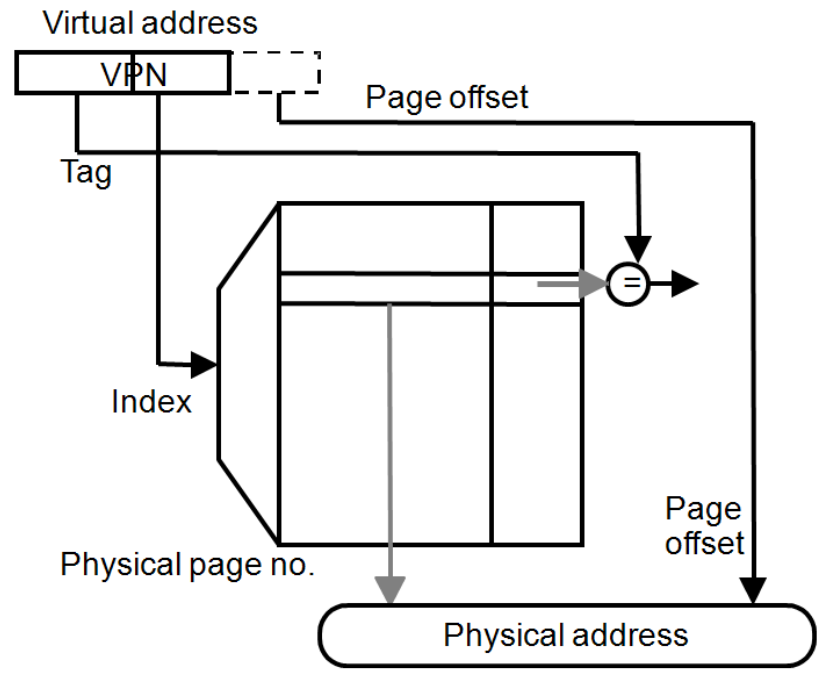
Index:使用虚拟页号(VPN)的低位作为索引,用于快速查找对应的条目.
Tag:使用 VPN 的未使用位和进程 ID 组成标签,用于确保唯一识别虚拟页.
Data:存储页表项(PTE)的内容,即物理页号(PPN).
Status:记录状态信息,如条目的有效性(valid)和是否被修改(dirty).
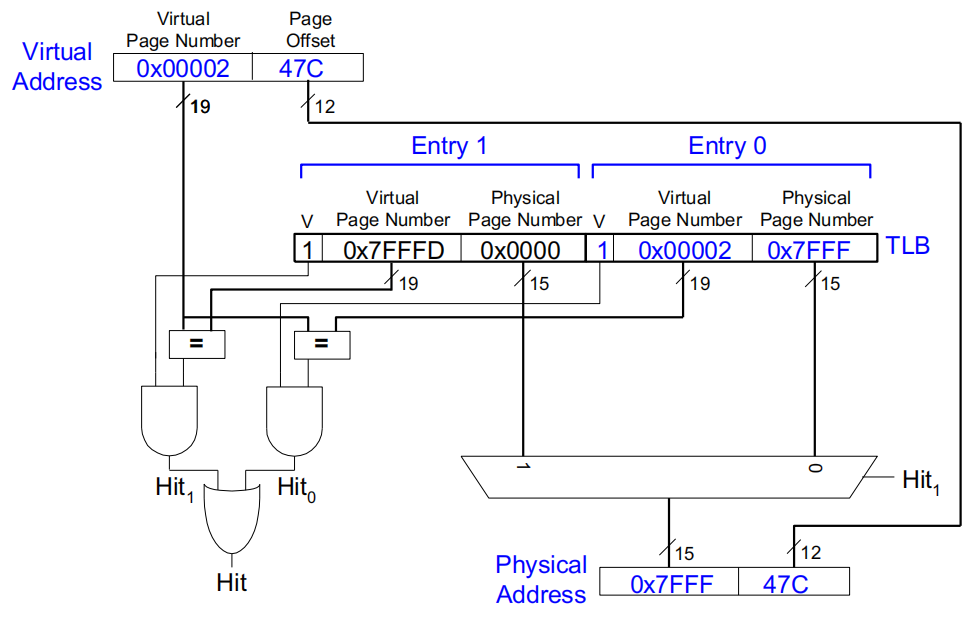
流程:
输入的虚拟地址由 VPN 和页偏移(Page offset)组成.
使用 VPN 与 TLB 的索引匹配,通过标签验证条目是否有效.
如果找到有效条目,将物理页号与页偏移组合得到物理地址.
如果没有找到有效条目(TLB 缺失),则需要查找页表.
方法 1. 硬件管理(如 x86) 。
方法 2. 软件管理(如 MIPS) 。
虚拟内存需要硬件和软件的支持:
硬件组件称为 MMU(memory management unit 内存管理单元):
软件的职责是利用 MMU 来:
页大小由 ISA(指令集架构)指定 。
每个虚拟页都有一个页表项(PTE) 。
页表是物理内存数据存储的“Tag Store”:
页表项(PTE)是内存中虚拟页的“Tag Store Entry”:
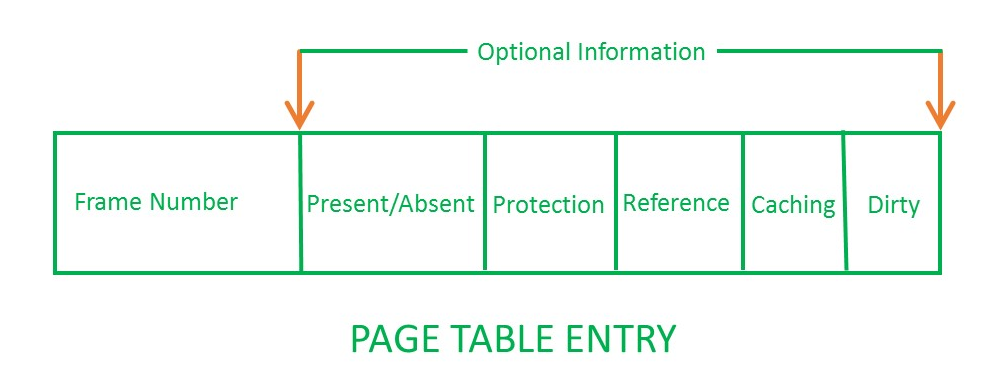
如果页面不在物理内存中而在磁盘中:
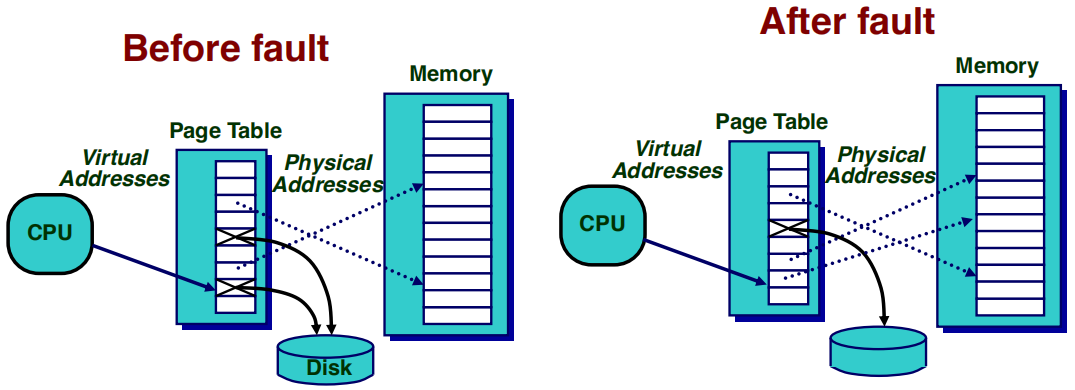
Before Fault(发生页面错误之前):
After Fault(页面错误处理完成后):
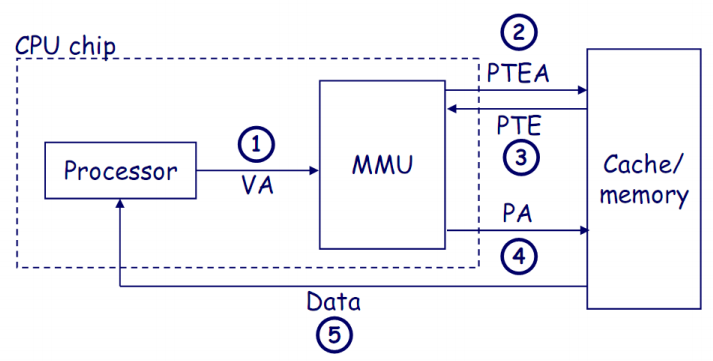
上图展示了处理器通过MMU(内存管理单元)将虚拟地址转换为物理地址,并从缓存或内存中获取数据的过程.
2-3. MMU从内存中的页表获取PTE(页表项):MMU使用虚拟地址查找页表项(PTE),以获取虚拟地址和物理地址之间的映射关系。如果页表项不在TLB中,MMU会从内存中获取相应的PTE.
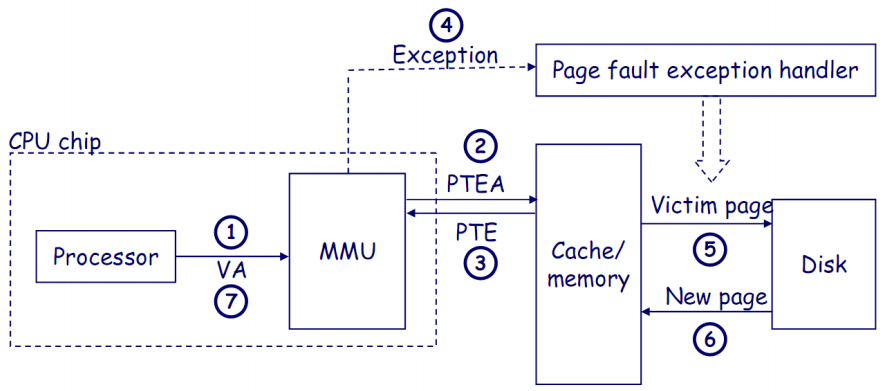
上图展示了在地址转换过程中发生缺页异常(Page Fault)的处理过程.
处理器发送虚拟地址(VA)到MMU:处理器生成一个虚拟地址并将其发送给MMU,MMU负责将虚拟地址转换为物理地址.
MMU从页表中获取页表项地址(PTEA):MMU通过虚拟地址查找对应的页表项地址(PTEA)以获取页表项(PTE).
MMU从页表中获取页表项(PTE):MMU访问内存中的页表项(PTE),以确定虚拟地址是否在物理内存中.
有效位(valid bit)为0,MMU触发缺页异常:如果页表项中的有效位为0,表示该页面不在物理内存中,MMU触发缺页异常(Page Fault Exception),将控制权交给缺页异常处理程序.
异常处理程序识别替换页面,如果页面是脏页,则写回磁盘:异常处理程序选择一个页面作为“牺牲页”(Victim Page),如果该页面是脏页,则将其内容写回磁盘,以便腾出空间.
异常处理程序从磁盘加载新页面,并更新内存中的页表项(PTE):异常处理程序从磁盘加载所需的页面到物理内存中,并更新页表项,使得虚拟地址可以正确映射到新的物理地址.
处理程序返回原进程,重新执行引发缺页的指令:在页面加载完成后,处理器重新执行引发缺页的指令,使用正确的物理地址完成操作.
物理内存(DRAM)是 Disk 的缓存 。
页面替换与缓存替换类似 。
页表是物理内存数据存储的 "tag store" 。
区别是什么?
如果物理内存已满(即可用物理页列表为空),则在错页时要替换哪个物理页?
使用 True LRU 是否可行?
现代系统使用 LRU 的近似算法 。
以及考虑到使用 "频率 "的更复杂算法 。
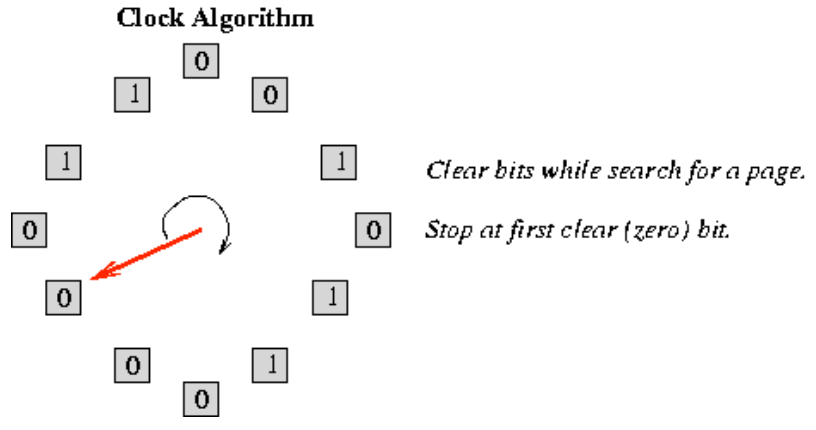
上图为 时钟页面替换算法 的工作原理。该算法用于决定在内存不足时需要将哪个页面置换出去,以便为新页面腾出空间。具体内容如下:
CLOCK 算法的优势:
最后此篇关于DDCA——大缓存、虚拟内存:多核缓存、NUCA缓存、页表等的文章就讲到这里了,如果你想了解更多关于DDCA——大缓存、虚拟内存:多核缓存、NUCA缓存、页表等的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
65
4
 0
0
有WHERE 1=1有什么作用如果您在脚本(伪代码)中编写此请求: sql = "SELECT f1,f2,f3 FROM t WHERE 1=1" ++ restOfTheClause
这个问题已经有答案了: R: Convert delimited string into variables (3 个回答) 已关闭 5 年前。 我有一个包含电影数据的表,在最后一列中,它包含电影所属
假设我有一个基类: struct A{ virtual void foo() = 0; }; 然后假设我有一个这样的派生类: struct B : public virtual A{ voi
我有一个小问题,我的 << 运算符没有被正确调用。 这是我的: class SomeInterface { friend std::ostream& operator<<(std::ostrea
首先,我来自 Java 社区,并且仍然是 C++ 的学习者。 请看下面的类 第二张图片显示了类“GameObject”的子类。它还有一个 Display() 方法。 GameObject类有5个子类,
我这里遇到了一些问题。我试图让我的代码像 java 中的接口(interface)一样工作。这个类被其他 2 个继承,因为它们导致了一些问题。而且我还想知道我是否做对了,以及改进我的代码的方法。我是新
在 C++ 中,我有一个基类 A,一个子类 B。两者都有虚方法 Visit。我想在 B 中重新定义“访问”,但 B 需要访问每个 A(以及所有子类)的“访问”功能。 我有类似的东西,但它告诉我 B 无
我有一个抽象类,它是类层次结构的根。该根类有一个带有一些简单实现的方法,似乎没有必要随时随地更改该实现。 使该方法成为非虚方法很好,但是某些子类可能会意外地重新实现它。在这种情况下,虚拟 final方
在 MSDN 上,我发现在抽象方法声明中使用“virtual”修饰符是错误的。我的一位同事应该是非常有经验的开发人员,但他在他的代码中使用了这个: public abstract class Busi
C++ 虚函数表是仅用于确定调用虚函数时应该执行哪一段代码,还是在运行时有其他用途? 在维基百科上,它列出了“动态调度”作为一个原因,但没有深入了解 C++ 的更多细节...... 最佳答案 一些实现
页面大小是否恒定?更具体地说,getconf PAGE_SIZE 给出 4096,这很公平。但这可以通过程序的运行时间改变吗?或者它在整个操作系统进程生成过程中是否保持不变。 IE。 , 进程是否可能
析构函数(当然还有构造函数)和其他成员函数之间的区别在于,如果常规成员函数在派生类中具有主体,则仅执行派生类中的版本。而在析构函数的情况下,派生版本和基类版本都会被执行? 很高兴知道在析构函数(可能是
如果一个函数被定义为虚函数并且与纯虚函数相同,这究竟意味着什么? 最佳答案 来自 Wikipedia's Virtual function... In object-oriented programm
我有一个在 Jetty 下运行的应用程序,我希望该应用程序返回自引用绝对 URL(生成 RSS 提要时,因此客户端必须能够在没有“当前 URL”上下文的情况下工作)。 问题是我事先不知道应用程序将部署
如何在两个virtualtreeview之间复制以复制所有列,而不仅仅是第一列? 复制前: 复制后: 最佳答案 树控件不保存任何数据。它不包含要显示的列数据,因此无法复制它。而是,当树控件想要显示任何
我已将 ShowHint 设置为 true 并将 HintMode 设置为 hmToolTip,但是当我将光标悬停在控件上时,我的 OnGetHint() 事件处理程序甚至没有断点。 知道我做错了什么
我的 friend 正在 Delphi 中使用 VirtualTreeView 工作,并且遇到了下一个问题:他有两列,第一列的每一行都有数据和子项。是否可以不更改第一列宽度来设置最大子列宽度? 图例:
我在我的 Virtual TreeView Component 中使用 TVirtualStringTree ( Delphi project 的一部分)我想创建一个 View ,其中 2 列可以有可
我想遍历 VirtualTreeView 的所有根并将其删除。 我不想清除它。 我收到此代码的访问冲突: var Node : PVirtualNode; begin if VirtualStri
我有一个可以输出表单的 PHP 文件。我想在服务器端调用这个 PHP 文件(当前使用“include”),填写并提交。 这样更好,因此我不必干预实际的 PHP 表单,只需处理表示层,以便数据可以被它自

我是一名优秀的程序员,十分优秀!