
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 59
59
 4
4


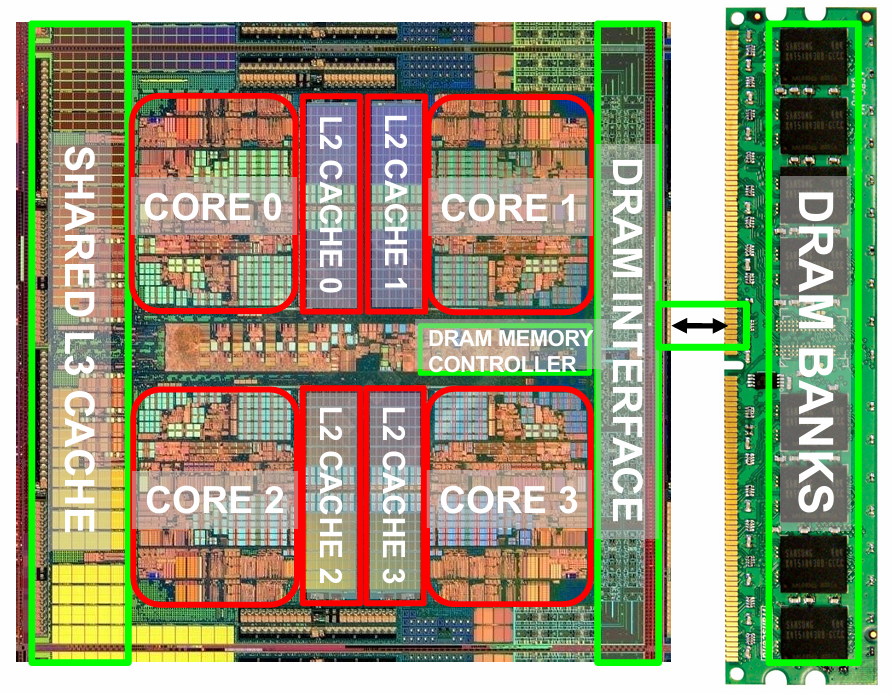
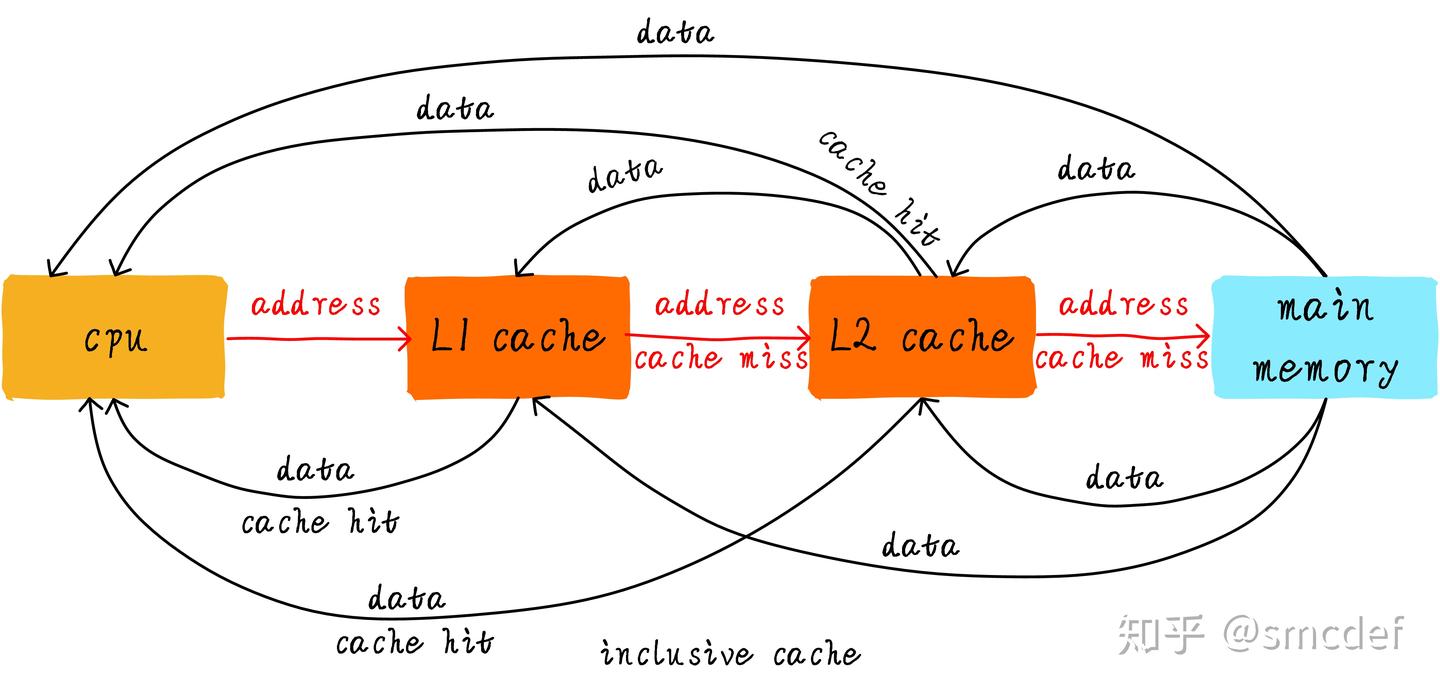
其中包括L1、L2、L3和DRAM 。
理想存储器的需求如下:
但理想存储器的需求彼此冲突:
我们想要存储器又快,容量又大,这并不能通过单层存储器实现.
Idea:多层次存储(离处理器越远的存储器容量越大,速度越慢)并且确保处理器所需的大部分数据能够保持在较快的层次中.
Memory System:
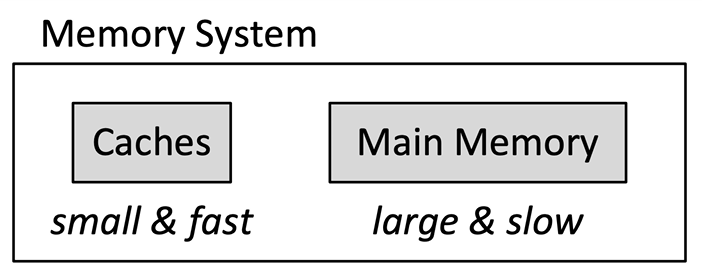
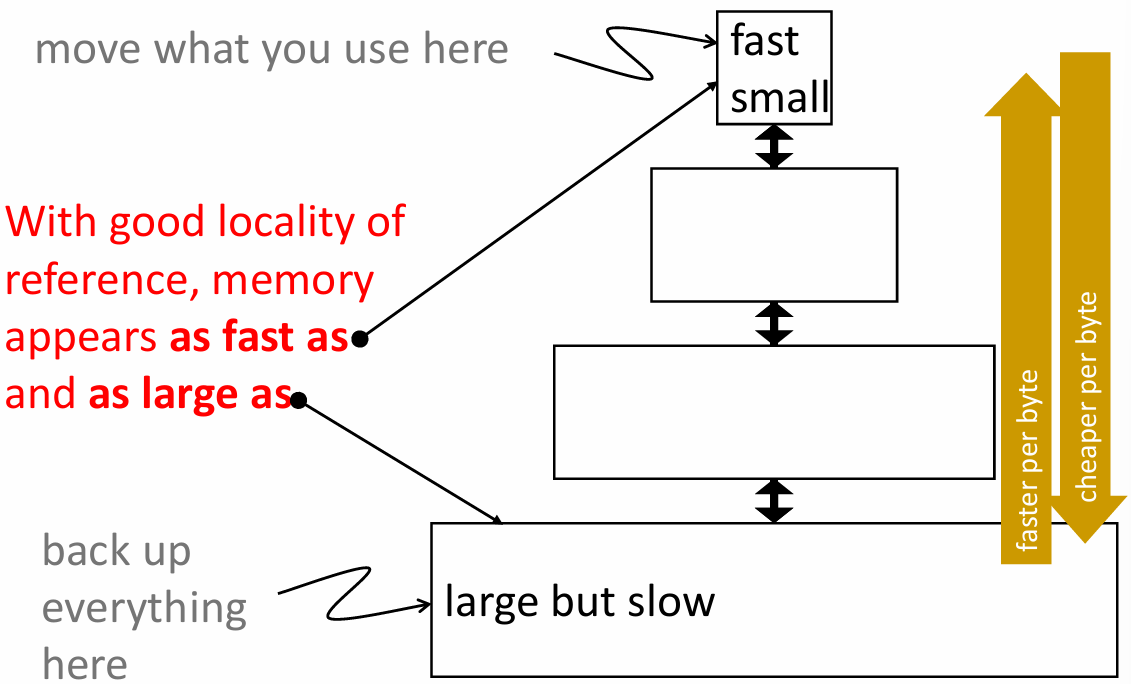
只要拥有良好的引用局部性,存储器层次结构可以使得存储器又快,容量又大.
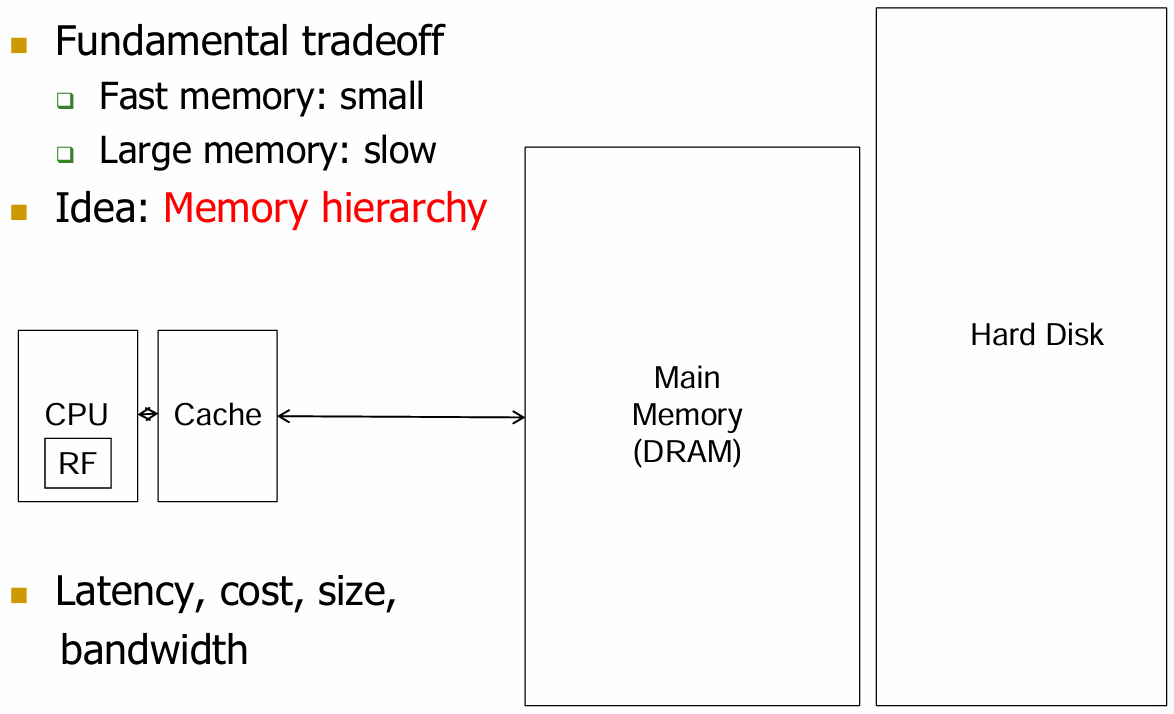
从小到大,从快到慢依次包括:寄存器(Register File)、缓存(Cache)、主存储器(Main Memory)和硬盘(Hard Disk).
通过一个人不久的过去能够预测其不远的将来 。
时间局部性(Temporal Locality):如果你刚好干了某事,那么你极有可能很快再干同样的事情.
空间局部性(Spatial Locality):如果你做了某件事情,你很可能会做类似/相关的事情(在空间上).
loop 组成的程序缓存需要与流水线紧密集成 。
然而高频流水线 → 不能让 cache 太大 。
Idea:缓存层次结构 。
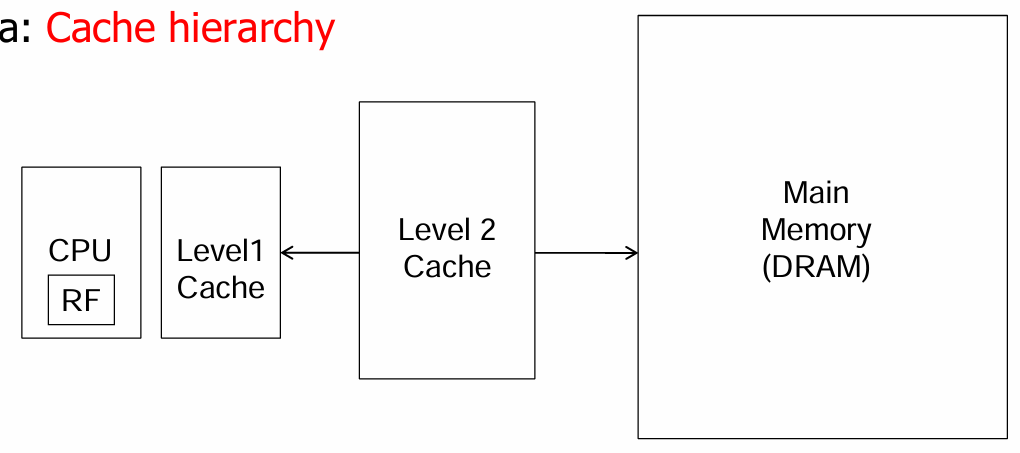
其中,一级缓存(L1)设计决策主要由处理器的频率决定,并且L1非常小;二级缓存(L2)比L1大,但访问速度也比L1慢.
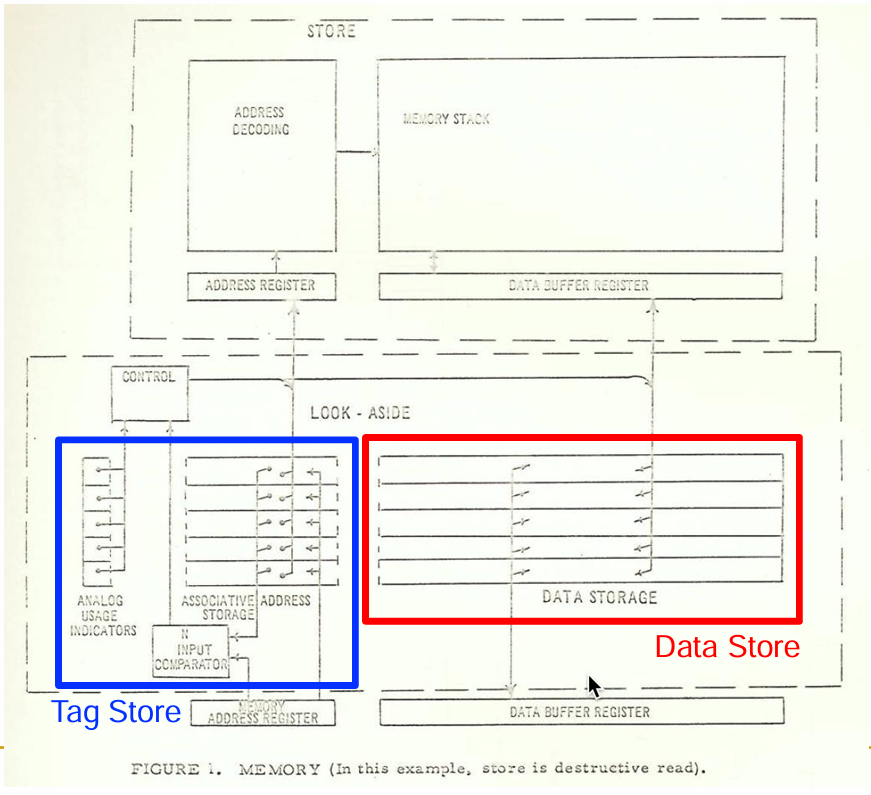
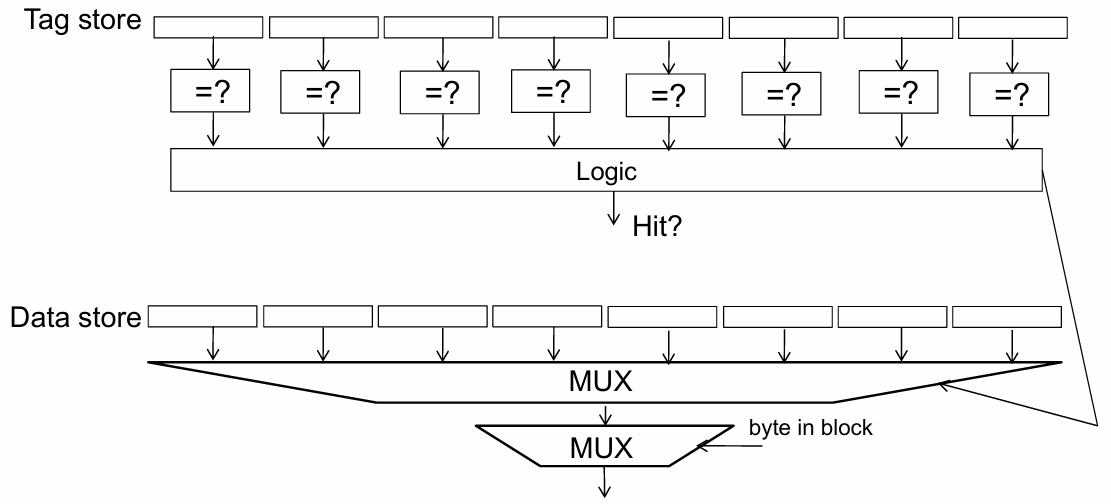
其中包括一个标签存储(Tag Store)和一个数据存储(Data Store).
当处理器需要查询缓存时,它需要向Tag Store发送一个地址.
如果Tag Store显示该地址存在缓存中,那么你可以从Data Store中获取数据.
如果Tag Store显示该地址不在缓存中,那么你必须去主内存取数据.
程序查询该层,会得到访问数据命中或未命中(Hit/Miss),这意味着数据在该层或不在.
假设给定的存储器分层结构第 \(i\) 层具有固有访问时间(technology-intrinsic access time)\(t_i\).
但实际的感知访问时间(perceived access time)\(T_i\) 要比 \(t_i\) 长.
除了最外层的层次结构外,在查找给定地址时,有以下几种情况 。
因此 \(T_i = h_i \cdot t_i + m_i \cdot (t_i + T_{i+1})\),即 \(T_i = t_i + m_i \cdot T_{i+1}\).
递归延迟方程 。
目标:在允许的成本范围内实现所需的 \(T_1\) 。
希望 \(T_i \approx t_i\),虽然这是不可能的 。
降低未命中率 \(m_i\):
降低下一层级的感知访问时间 \(T_{i+1}\):
\(T_i = t_i + m_i\cdot T_{i+1}\) 。
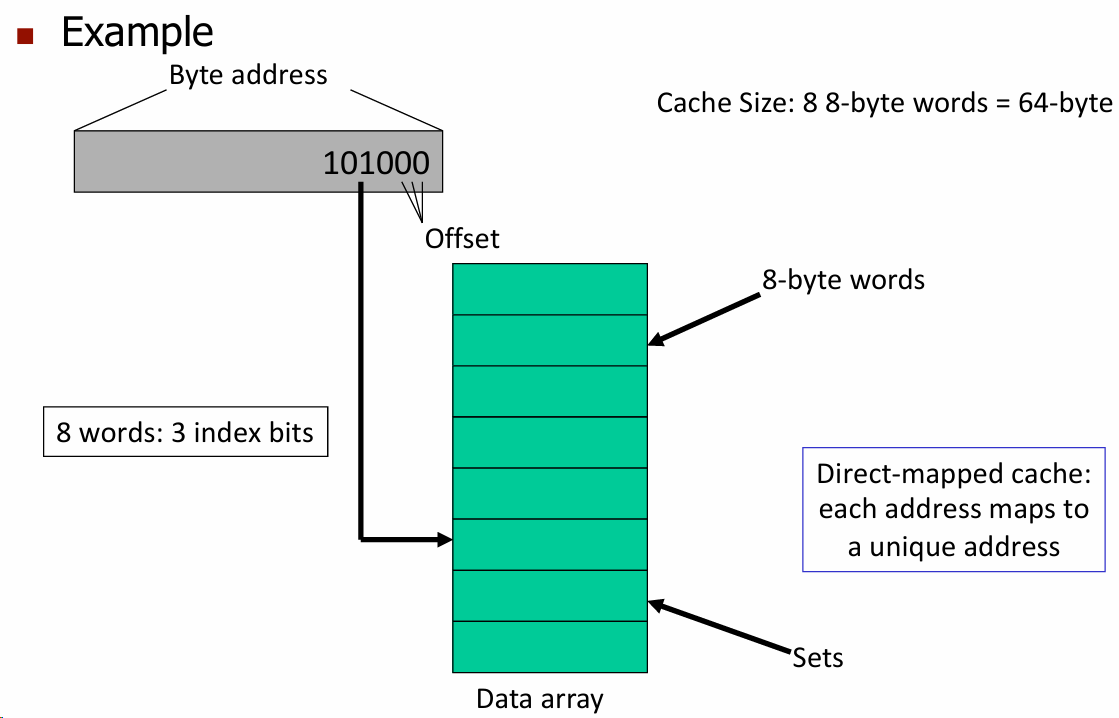
缓存大小:缓存的总大小是64字节,由8个8字节的存储单元(8-byte words)组成,每个存储单元可以存储8个字节的数据.
字节地址(Byte Address):后3位表示字节的Offset,由于每个存储单元为8-byte.
索引位(Index Bits):有3位index bits,由于有8个缓存行(\(2^3 = 8\)),每行可以存储一个8字节的数据块.
直接映射缓存(Direct-mapped Cache):每个主存地址直接映射到缓存中的唯一位置。地址中的索引位决定数据在缓存中的位置,所以每个地址都会对应到一个唯一的缓存行.
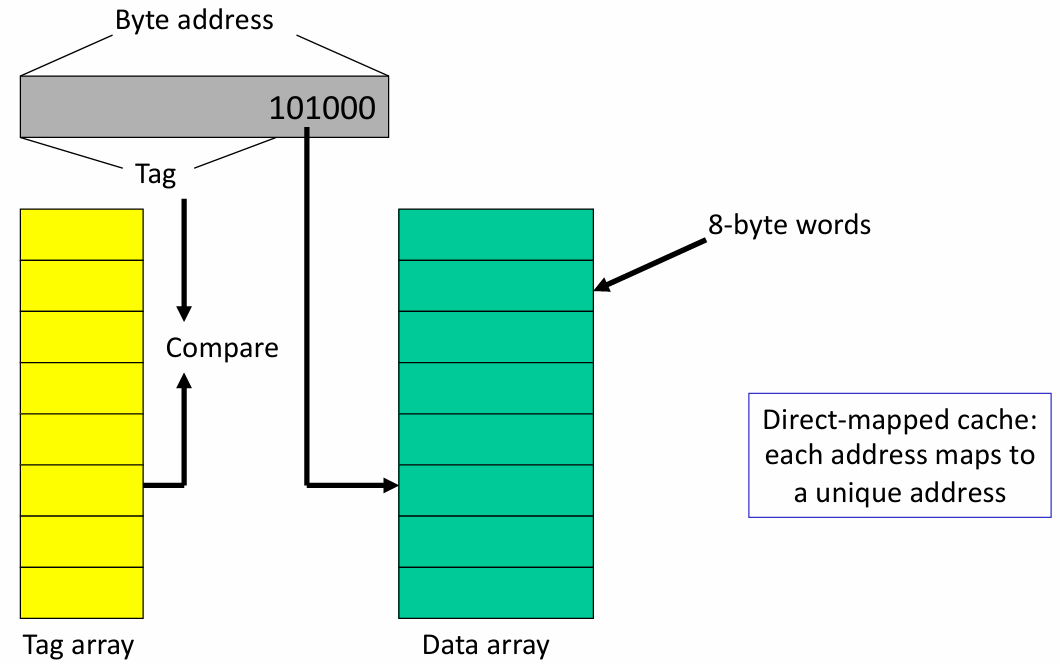
当主存地址映射到某一缓存行时,系统会将该地址的Tag值与标记数组中的Tag值进行比较,以判断数据是否在缓存中。如果Tag值匹配,说明数据已在缓存中(命中);如果不匹配,则说明需要从主存中加载该数据(未命中).
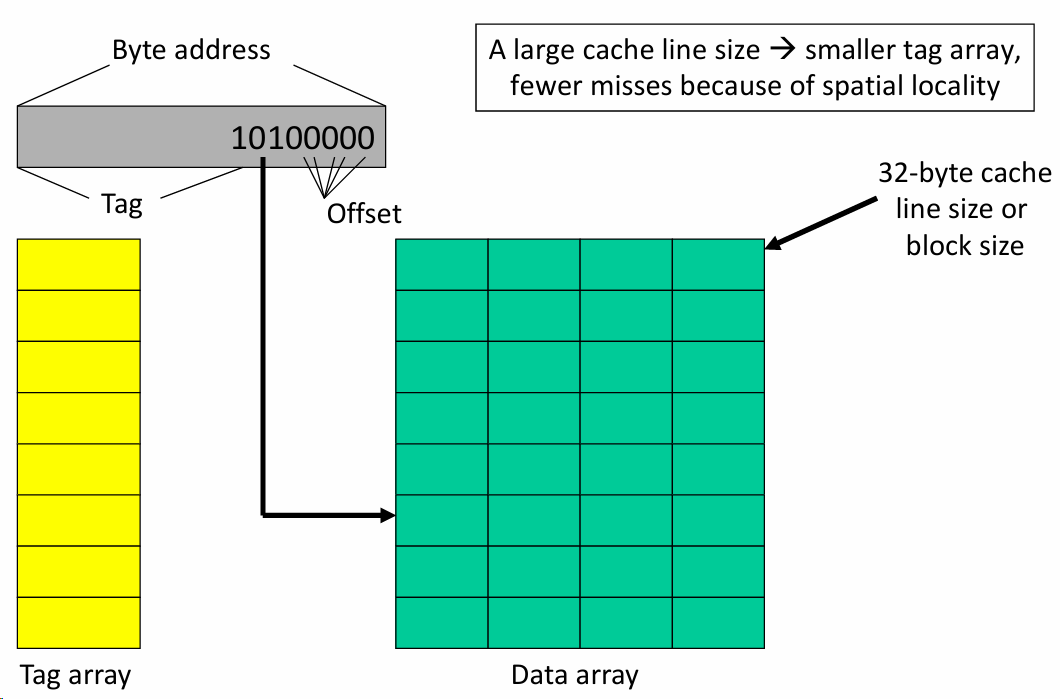
从每行存储8-byte数据变为每行存储32-byte数据:
缓存大小:缓存的总大小是256字节,由8个32字节的存储单元(32-byte words)组成,每个存储单元可以存储32个字节的数据.
字节地址(Byte Address):后5位表示字节的Offset,由于每个存储单元为32-byte.
索引位(Index Bits):有3位index bits,由于有8个缓存行(\(2^3 = 8\)),每行可以存储一个32字节的数据块.
更大的缓存行的影响:
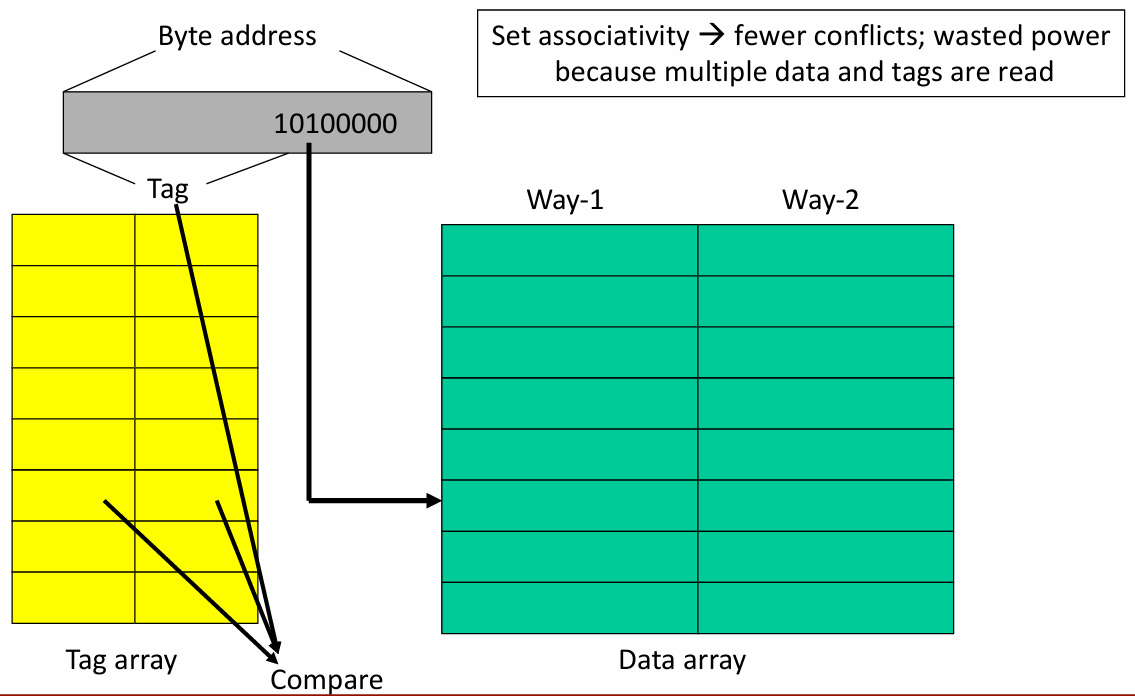
两路组相联缓存(2-way set associative cache)的结构:
组相联的优势与劣势:
32 KB 4 路组关联缓存阵列,行大小为 32 字节,假设地址为 40 位 。
How many sets?
\(32KB / (32Byte\times4)=32KB/128Byte=256set\) 。
How many index bits, offset bits, tag bits?
index bits(8): \(2^8=256set\) 。
offset bits(5): \(2^{5}=32Byte\) 。
tag bits(27): \(40-5-8=27bits\) 。
How large is the tag array?
\(27bit \times 256 \times 4=27Kb\) 。
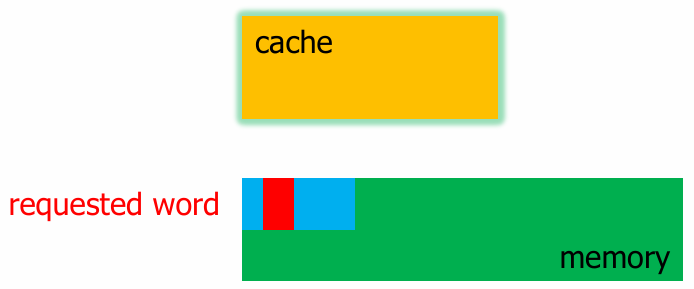
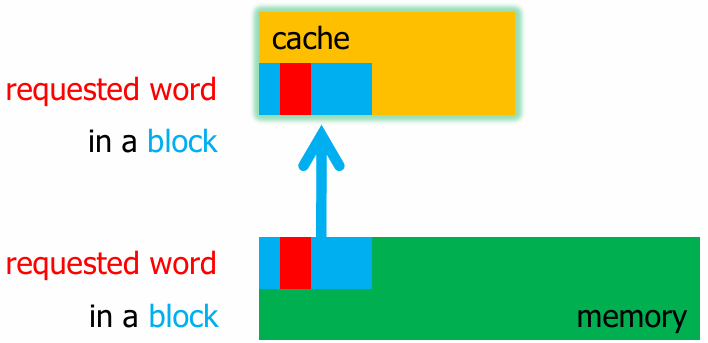
对于引用:
一些重要的缓存设计决策 。
附注:全关联缓存的未命中次数会比相同大小的直接映射缓存多吗?会,增加了冲突未命中 。
增加缓存块大小:增大缓存块的大小可以减少强制性未命中(即数据首次被访问时的未命中),并且在存在空间局部性时,可以降低未命中的惩罚(因为可以一次性预取更多相关数据)。但增大块大小也带来一些负面影响,比如:
不同缓存层之间的流量增加 。
可能导致空间浪费(当只需访问其中一小部分数据时) 。
可能增加冲突未命中(因为较大的块会占用更多缓存空间,导致其他数据无法缓存) 。
增大缓存容量:更大的缓存可以减少容量未命中和冲突未命中,因为可以存储更多的数据。然而,增大缓存容量会带来访问时间的惩罚(较大的缓存通常访问速度会稍慢).
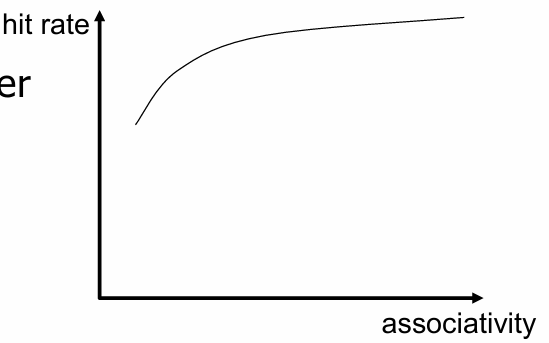
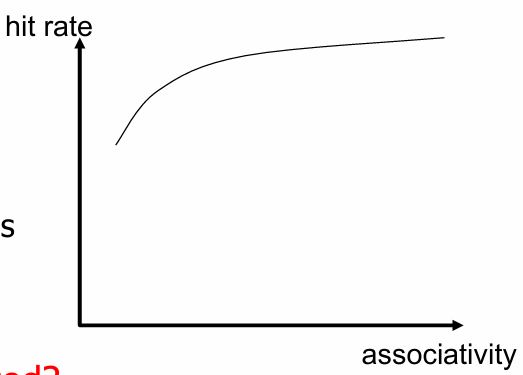
高关联度:增加缓存的相联度(如从1路变为2路或更高)可以减少冲突未命中,因为多个数据块可以存储在同一缓存组中,减少了因为地址冲突而导致的数据丢失.
L1缓存分为指令缓存和数据缓存,而L2和L3是统一缓存:在一级缓存(L1)中,将指令和数据分别存储在不同的缓存中,以提高访问效率;而在L2和L3级别,指令和数据共享同一个缓存空间,即为统一缓存.
L1/L2缓存层次结构可以是包容性、排他性或非包容性:
包容性:L2缓存包含所有L1缓存中的数据内容,这样如果L2有数据,L1肯定也有。这种结构便于管理,但会占用更多L2空间.
排他性:L2缓存中的数据不在L1中,两个缓存不会重复存储相同数据,这种结构可以更有效地利用总的缓存空间.
非包容性:L1和L2之间没有严格的包容关系,数据可以在L1或L2中单独存在.
写操作时可以选择写分配或不写分配:
写分配(Write-Allocate):在写入缓存时,如果数据不在缓存中,会将其加载到缓存中后再写入.
不写分配(Write-No-Allocate):如果数据不在缓存中,直接写到下一级缓存或主存,而不加载到缓存中.
写操作时可以选择回写(Write-Back)或直写(Write-Through):
回写(Write-Back):写入时只更新缓存中的数据,而不立即写回内存,只有当缓存行被替换时才写回内存,减少了内存总线的流量.
直写(Write-Through):每次写入缓存时,同时更新内存,这样简化了数据一致性管理,但增加了内存访问流量.
读操作优先于写操作,且写操作通常会进行缓冲:为了保证数据的快速读取,读操作通常具有更高优先级,而写操作会被缓冲,等待合适的时机再写入,避免影响读操作的效率.
L1缓存并行进行标签和数据访问,L2/L3缓存串行进行标签和数据访问:
在L1缓存中,标签(Tag)和数据的访问是并行的,以减少访问时间.
在L2和L3缓存中,标签和数据访问是串行的,先检查标签是否命中,再决定是否读取数据,这种设计减少了电路的复杂性.
在处理缓存未命中(cache miss)时,如何通过一些策略来减少等待带来的性能损失:
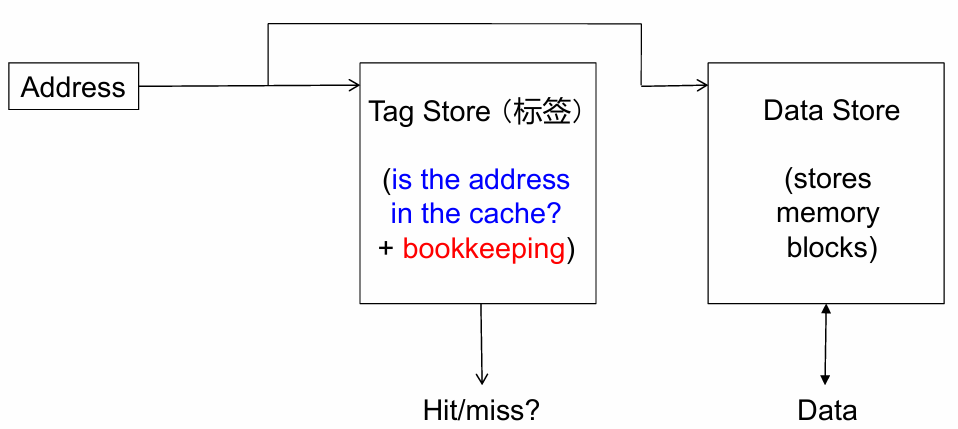
给一个地址来索引数据存储,tag store 回答寻找的地址是否在缓存中,它会发出信号Hit/miss,如果Hit,Data store会给出Data.
Cache hit rate = (# hits) / (# hits + # misses) = (# hits) / (# accesses)Average memory access time (AMAT) = ( hit-rate * hit-latency ) + ( miss-rate * miss-latency )(include hit latency)
假设字节可寻址内存:256bytes,8-byte blocks -> 32 blocks 。
假设缓存: 64 bytes,8 blocks 。
具有相同 index 的地址争夺相同位置 。
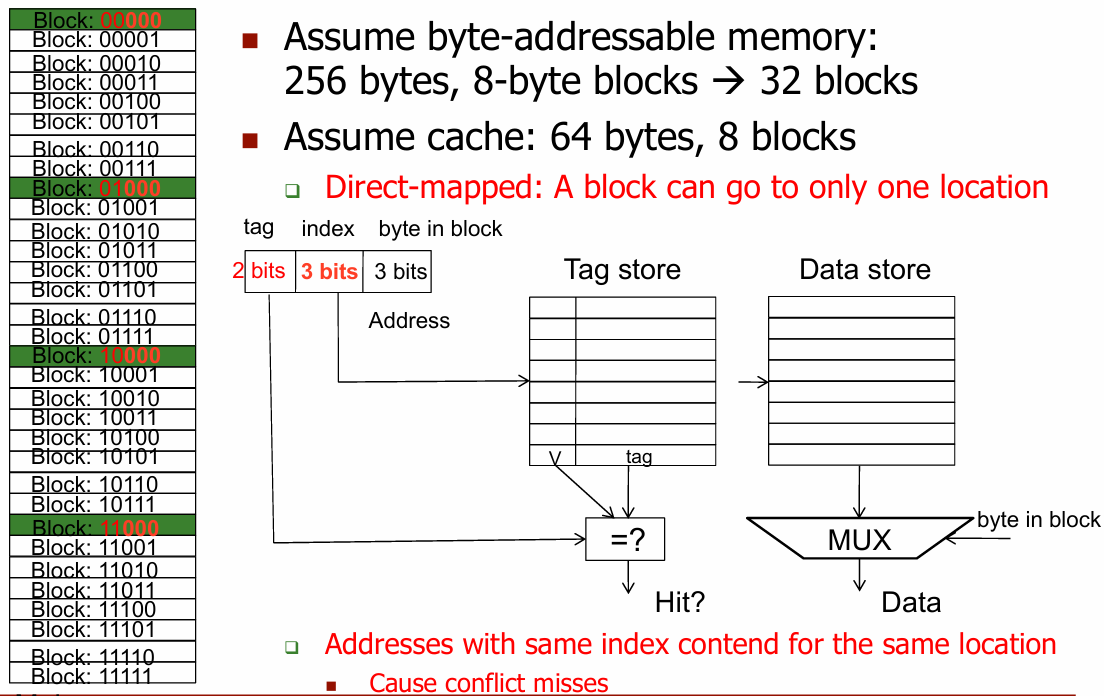
直接映射缓存:内存中映射到高速缓存中相同 index 的两个块不能同时出现在缓存中 。
如果以交错方式访问的多个 block 映射到同一索引,则可能导致 0% 的命中率 。


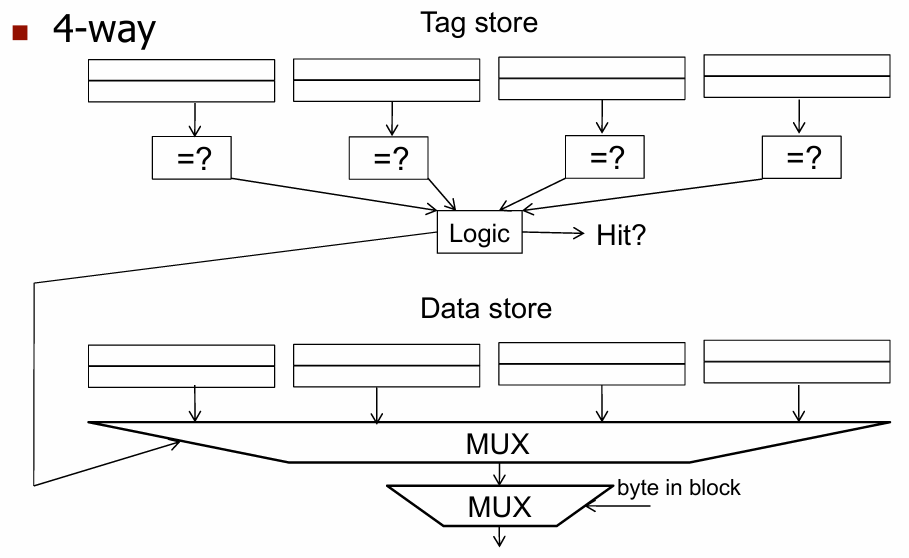
关联性程度:有多少 block 可以映射到同一个 index(或数据集)?
更高的关联性 。
高关联度带来的收益递减 。
Idea:驱逐最近访问次数最少的区块 。
Problem:需要跟踪 block 的访问顺序 。
问题:2路组关联缓存 。
问题:4路组关联缓存 。
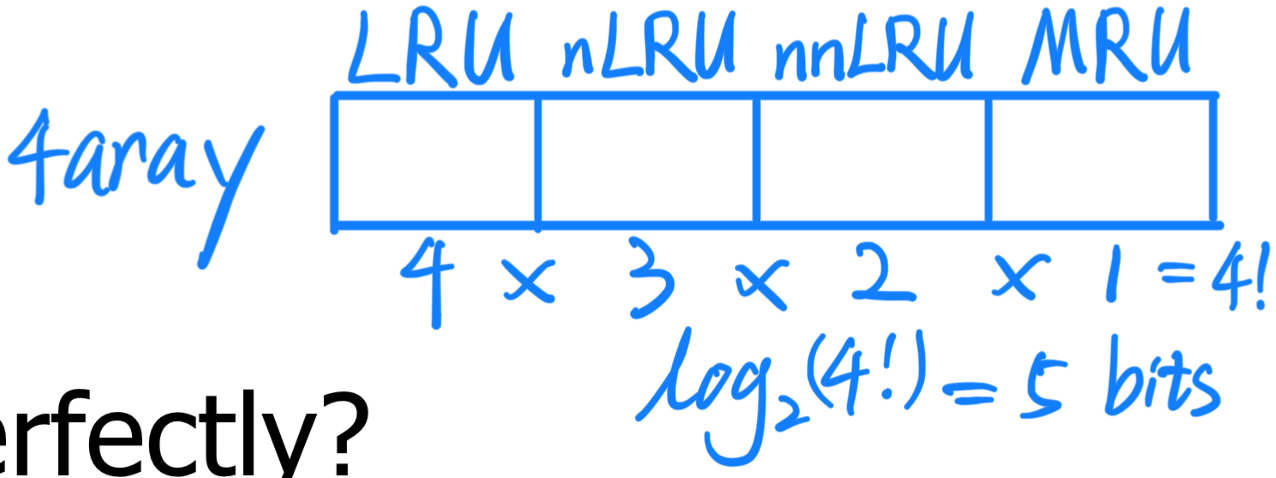
大多数现代处理器都没有在高关联缓存中实现 "真正的 LRU"(也称为 "完美的 LRU").
Example:
NRU:集合中的每个 block 都有一个 bit;block 被访问时,该 bit 变为 0;如果所有 bit 都为 0,则将所有位变为 1;将 bit 设置为 1 的 block 驱逐出去 。
DRRIP:使用多个 NRU 位(3 位),将进入的 block 设置为高位,使其接近被驱逐;类似于将进入的 block 置于 LRU 列表的头部而非尾部附近 。
Tag的组成可以有以下几部分:
我们何时将缓存中修改过的数据写入下一级?
Write-back(写回模式):更新缓存时,并不同步更新memory 。
Write-through(写直达模式):CPU向cache写入数据时,同时向memory写 。
如果处理器在较短时间内写入整个数据块怎么办?是否有必要首先将数据块从内存带入缓存?
为什么我们不能只写入数据块的一部分,即子数据块?
Idea:将一个 block 划分为子区块 subblocks(or 扇区sectors) 。

优点:
缺点:
要分开(Separate)管理还是统一(Unified)管理 。
Unified的优缺点:
动态共享缓存空间:不会出现静态分区(即独立的 Instruction 和 Data 缓存)可能出现的超额配置情况 。
指令和数据会互相驱逐(即两者都没有充足的空间 。
Instruction 和 Data 在流水线的不同位置被访问。 我们应该把统一缓存放在哪里才能实现快速访问? 这是大多数处理器使用单独(Separate)缓存的主要原因 。
一级缓存几乎总是被拆分 。
高级缓存几乎总是统一的 。
缓存参数与失误/命中率的关系 。
缓存大小:数据(不包括 tag)总容量 。
过大的缓存会对命中和未命中延迟产生不利影响 。
缓存太小 。
工作集(working set)点:应用程序所引用的全部数据集可能存在于缓存中 。
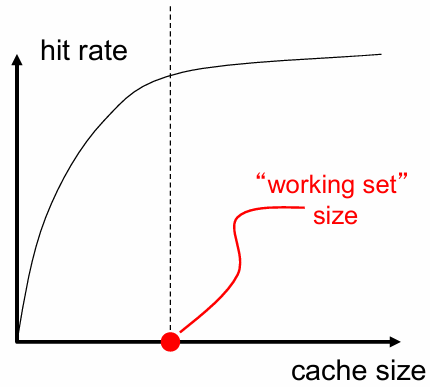
Block 大小是与地址 tag 关联的数据 。
Block 太小 。
block 太大 。
大型缓存块可能需要很长时间才能填入缓存 。
大型缓存块会浪费总线带宽 。
同一索引(即组)中可以出现多少个block?
最后此篇关于DDCA——缓存(Cache):缓存体系结构、缓存操作的文章就讲到这里了,如果你想了解更多关于DDCA——缓存(Cache):缓存体系结构、缓存操作的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
59
4
 0
0
我正在努力做到这一点 在我的操作中从数据库获取对象列表(确定) 在 JSP 上打印(确定) 此列表作为 JSP 中的可编辑表出现。我想修改然后将其提交回同一操作以将其保存在我的数据库中(失败。当我使用
我有以下形式的 Linq to Entities 查询: var x = from a in SomeData where ... some conditions ... select
我有以下查询。 var query = Repository.Query() .Where(p => !p.IsDeleted && p.Article.ArticleSections.Cou
我正在编写一个应用程序包,其中包含一个主类,其中主方法与GUI类分开,GUI类包含一个带有jtabbedpane的jframe,它有两个选项卡,第一个选项卡包含一个jtable,称为jtable1,第
以下代码产生错误 The nested query is not supported. Operation1='Case' Operation2='Collect' 问题是我做错了什么?我该如何解决?
我已经为 HA redis 集群(2 个副本、1 个主节点、3 个哨兵)设置了本地 docker 环境。只有哨兵暴露端口(10021、10022、10023)。 我使用的是 stackexchange
我正在 Desk.com 中构建一个“集成 URL”,它使用 Shopify Liquid 模板过滤器语法。对于开始日期为 7 天前而结束日期为现在的查询,此 URL 需要包含“开始日期”和“结束日期
你一定想过。然而情况却不理想,python中只能使用类似于 i++/i--等操作。 python中的自增操作 下面代码几乎是所有程序员在python中进行自增(减)操作的常用
我需要在每个使用 github 操作的手动构建中显示分支。例如:https://gyazo.com/2131bf83b0df1e2157480e5be842d4fb 我应该显示分支而不是一个。 最佳答
我有一个关于 Perl qr 运算符的问题: #!/usr/bin/perl -w &mysplit("a:b:c", /:/); sub mysplit { my($str, $patt
我已经使用 ArgoUML 创建了一个 ERD(实体关系图),我希望在一个类中创建两个操作,它们都具有 void 返回类型。但是,我只能创建一个返回 void 类型的操作。 例如: 我能够将 book
Github 操作仍处于测试阶段并且很新,但我希望有人可以提供帮助。我认为可以在主分支和拉取请求上运行 github 操作,如下所示: on: pull_request push: b
我正在尝试创建一个 Twilio 工作流来调用电话并记录用户所说的内容。为此,我正在使用 Record,但我不确定要在 action 参数中放置什么。 尽管我知道 Twilio 会发送有关调用该 UR
我不确定这是否可行,但值得一试。我正在使用模板缓冲区来减少使用此算法的延迟渲染器中光体积的过度绘制(当相机位于体积之外时): 使用廉价的着色器,将深度测试设置为 LEQUAL 绘制背面,将它们标记在模
有没有聪明的方法来复制 和 重命名 文件通过 GitHub 操作? 我想将一些自述文件复制到 /docs文件夹(:= 同一个 repo,不是远程的!),它们将根据它们的 frontmatter 重命名
我有一个 .csv 文件,其中第一列包含用户名。它们采用 FirstName LastName 的形式。我想获取 FirstName 并将 LastName 的第一个字符添加到它上面,然后删除空格。然
Sitecore 根据 Sitecore 树中定义的项目名称生成 URL, http://samplewebsite/Pages/Sample Page 但我们的客户有兴趣降低所有 URL(页面/示例
我正在尝试进行一些计算,但是一旦我输入金额,它就会完成。我只是希望通过单击按钮而不是自动发生这种情况。 到目前为止我做了什么: Angular JS - programming-fr
我的公司创建了一种在环境之间移动文件的复杂方法,现在我们希望将某些构建的 JS 文件(已转换和缩小)从一个 github 存储库移动到另一个。使用 github 操作可以实现这一点吗? 最佳答案 最简
在我的代码中,我创建了一个 JSONArray 对象。并向 JSONArray 对象添加了两个 JSONObject。我使用的是 json-simple-1.1.jar。我的代码是 package j

我是一名优秀的程序员,十分优秀!