
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 57
57
 4
4


用户 flink 任务提交客户端侧抛出请求错误,经排查发现是客户端主动 cancle 的.接着排查 yarn app 日志,发现本质错误是 jm 退出了,接着看 jm 日志,jm 退出是由于失去了 leadership 导致的 。
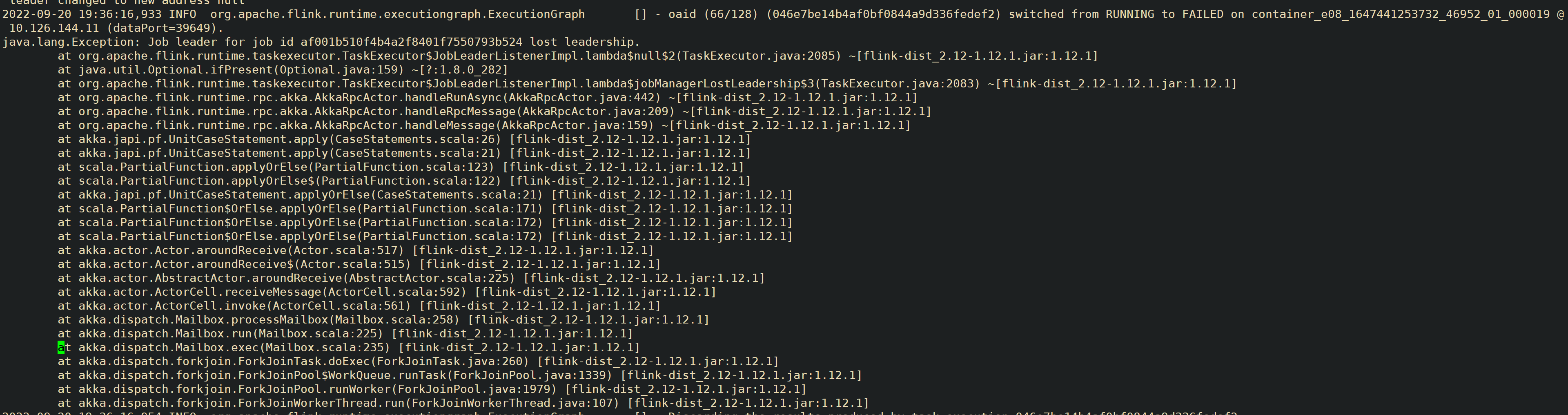
了解背景发现,用户有 flink ha任务,也有非 ha 任务, ha 使用的是基于 zookeeper 的实现 。
ha 任务是由于 jm 与选主的 zk 间的session 超时,导致jm 失去 leader 。
非 ha 任务是由于 jm 与 tm 间的心跳超时,jm 将 tm 置为 failed 状态,且没有配置 Restart Strategy 。
超时优化措施: 1.优化超时任务的 gc,通过 jstat 命令可以看到 tm jvm 的 old 分区占比 在 85 以上, 建议增大 flink 的 tm 内存参数 : -D taskmanager.memory.task.heap.size -D taskmanager.memory.managed.size -D taskmanager.memory.task.off-heap.size 在原来值的基础上增大 50% 2.优化超时任务的超时时间 增加 zk server ticktime (已经调整) 增加 jm 和 tm 的心跳超时时间 heartbeat.timeout = 180000 。
yarn.application-attempts: 1
yarn.application-attempt-failures-validity-interval: -1
ZooKeeper参数调优 - skyl夜 - 博客园 (cnblogs.com) Flink JobManager 高可用详解 - 白墨的博客 | Ink's Blog (baixin.ink) 。
最后此篇关于flinkjobmanager终止,任务失败问题的文章就讲到这里了,如果你想了解更多关于flinkjobmanager终止,任务失败问题的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
57
4
 0
0

我是一名优秀的程序员,十分优秀!