
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- VisualStudio2022插件的安装及使用-编程手把手系列文章
- pprof-在现网场景怎么用
- C#实现的下拉多选框,下拉多选树,多级节点
- 【学习笔记】基础数据结构:猫树



 60
60
 4
4


经典的 RAG 架构以向量数据库(VectorDB)为核心来检索语义相似性上下文,让大语言模型(LLM)不需要重新训练就能够获取最新的知识,其工作流如下图所示:

这一架构目前广泛应用于各类 AI 业务场景中,例如问答机器人、智能客服、私域知识库检索等等。虽然 RAG 通过知识增强一定程度上缓解了 LLM 幻觉问题,但是依然面临准确度不高的问题,它受限于信息检索流程固有的限制(比如信息检索相关性、搜索算法效率、Embedding模型)以及大量对 LLM 能力依赖,使得在生成结果的过程中有了更多的不确定性.
下图来自 RAG 领域一篇著名的论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》 ,它总结了在使用 RAG 架构时经常会遇到的一些问题(红框部分,原作者称之为7个失败点).

它们包括:
以上问题目前都有一些优化方法来提升回答准确度,但依然离我们的预期有差距.
因此除了基于语义匹配文本块之外,业内也探索新的数据检索形式,比如在语义之上关注数据之间的关联性。这种关联性区别于关系模型中的逻辑性强依赖,而是带有一定的语义关联。比如人和手机是两个独立的实体,在向量数据库中的相似性一定非常差,但是结合实际生活场景,人和手机的关系是非常密切的,假如我搜索一个人的信息,我大可能性也关心他的周边,例如用什么型号的手机、喜欢拍照还是玩游戏等等.
基于这样的关系模型,从知识库检索出来的上下文在某些场景中可能更有效,例如“公司里面喜欢使用手机拍照的人有哪些”.
为了有效地描述知识库中的抽象数据关系,引入了知识图谱的概念,它不再使用二维表格来组织数据,而是用图结构来描述关系,这里面的关系没有固定的范式约束,类似下面这种人物关系图:

上图中有最重要的三个元素:对象(人物)、属性(身份)、关系,对于存储这样的数据有专门的数据库产品来支持,即图数据库.
图数据库是属于 NoSQL 的一种,它有着较为灵活的 schema 定义,可以简单高效表达真实世界中任意的关联关系。图数据库中的主要概念有:
以上概念可对应到前面的人物关系图.
具体到 schema 定义和数据操作层面,以流行的图数据库 NebulaGraph 为例:
# 创建图空间
CREATE SPACE IF NOT EXISTS test(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);
USE test;
# 创建节点和边
CREATE TAG IF NOT EXISTS entity(name string);
CREATE EDGE IF NOT EXISTS relationship(relationship string);
CREATE TAG INDEX IF NOT EXISTS entity_index ON entity(name(256));
# 写入数据
INSERT VERTEX entity (name) VALUES "1":("神州数码");
INSERT VERTEX entity (name) VALUES "2":("云基地");
INSERT EDGE relationship (relationship) VALUES "1"->"2":("建立了");
...
图数据库的查询语法遵循 Cypher 标准:
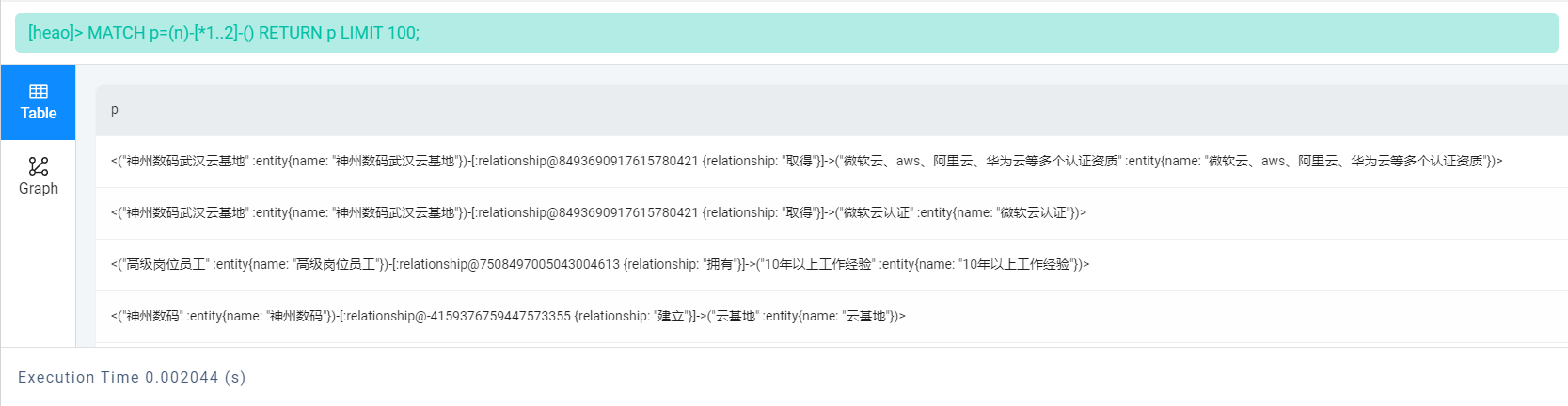
MATCH p=(n)-[*1..2]-() RETURN p LIMIT 100;
以上语句从 NebulaGraph 中找到最多100个从某个节点出发,通过1到2条边连接的路径,并返回这些路径.
如果用可视化图结构展示的话,它是这个样子:

如果借用 VectorRAG 的思想,通过图数据库来实现检索增强的话就演变出了 GraphRAG 架构,整体流程和 VectorRAG 并无差异,只是新知识的存储和检索都用知识图谱来实现,解决 VectorRAG 对抽象关系理解较弱的问题.
借助一些AI脚手架工具可以很容易地实现 GraphRAG,以下是用 LlamaIndex 和图数据库 NebulaGraph 实现的一个简易 GraphRAG 应用:
import os
from llama_index.core import KnowledgeGraphIndex, SimpleDirectoryReader
from llama_index.core import StorageContext
from llama_index.graph_stores.nebula import NebulaGraphStore
from llama_index.llms.openai import OpenAI
from pyvis.network import Network
from llama_index.core import (
Settings,
SimpleDirectoryReader,
KnowledgeGraphIndex,
)
# 参数准备
os.environ['OPENAI_API_KEY'] = "sk-proj-xxx"
os.environ["NEBULA_USER"] = "root"
os.environ["NEBULA_PASSWORD"] = "nebula"
os.environ["NEBULA_ADDRESS"] = "10.3.xx.xx:9669"
space_name = "heao"
edge_types, rel_prop_names = ["relationship"], ["relationship"]
tags = ["entity"]
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
Settings.llm = llm
Settings.chunk_size = 512
# 连接Nebula数据库实例
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
hosts=graph_store.query("SHOW HOSTS")
print(hosts)
# 抽取知识图谱写入数据库
documents = SimpleDirectoryReader(
"data"
).load_data()
kg_index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
max_triplets_per_chunk=2,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
max_knowledge_sequence=15,
)
# 信息检索生成答案
query_engine = kg_index.as_query_engine()
response = query_engine.query("神州数码云基地在哪里?")
print(response)
VectorRAG 擅长处理具有一定事实性的问题,对复杂关系理解较弱,而 GraphRAG 刚好弥补了这一点,如果把这两者进行结合,理论上能得到更优的结果.
我们可以把数据在 VectorDB 和 GraphDB 各放一份,分别通过向量化检索和图检索得到与问题相关结果后,我们将这些结果连接起来,形成统一的上下文,最后将组合的上下文传给大语言模型生成响应,这就形成了 HybridRAG 架构.
由英伟达团队Benika Hall等人在前段时间发表的论文《HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction》提出了这一设想,并使用金融服务行业中的数据集成、风险管理、预测分析等场景进行对比验证。在需要从相关文本文档中获取上下文以生成有意义且连贯的响应时 VectorRAG 表现出色,而 GraphRAG 能够从金融文件中提取的结构化信息生成更准确的且具有上下文感知的响应,但 GraphRAG 在抽象问答任务或问题中没有明确提及实体时通常表现不佳.
该论文最后给出了 VectorRAG、GraphRAG和 HybridRAG 的测试结果:

表格中F代表忠实度,用来衡量生成的答案在多大程度上可以从提供的上下文中推断出来。AR代表答案相关性,用来评估生成的答案在多大程度上解决了原始问题。CP代表上下文精度,CR代表上下文召回率.
以下示例用 Llama_index 作为应用框架,用 TiDB Vector 作为向量数据库,用 NebulaGraph 作为图数据库实现了简单的 HybridRAG 流程:
import os
from llama_index.core import KnowledgeGraphIndex, VectorStoreIndex,StorageContext,Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.graph_stores.nebula import NebulaGraphStore
from llama_index.llms.openai import OpenAI
from llama_index.vector_stores.tidbvector import TiDBVectorStore
TIDB_CONN_STR="mysql+pymysql://xx.root:xx@gateway01.eu-central-1.prod.aws.tidbcloud.com:4000/test?ssl_ca=isrgrootx1.pem&ssl_verify_cert=true&ssl_verify_identity=true"
os.environ["OPENAI_API_KEY"] = "sk-proj-xxx"
os.environ["NEBULA_USER"] = "root"
os.environ["NEBULA_PASSWORD"] = "nebula"
os.environ["NEBULA_ADDRESS"] = "10.3.xx.xx:9669"
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
Settings.llm = llm
Settings.chunk_size = 512
class HybridRAG:
def __init__(self):
# 初始化向量数据库
tidbvec = TiDBVectorStore(
connection_string=TIDB_CONN_STR,
table_name="semantic_embeddings",
distance_strategy="cosine",
vector_dimension=1536, # The dimension is decided by the model
drop_existing_table=False,
)
tidb_vec_index = VectorStoreIndex.from_vector_store(tidbvec)
self.vector_db = tidb_vec_index
# 初始化知识图谱
graph_store = NebulaGraphStore(
space_name="heao",
edge_types=["relationship"],
rel_prop_names=["relationship"],
tags=["entity"],
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
kg_index = KnowledgeGraphIndex.from_documents(
[],
storage_context=storage_context,
max_triplets_per_chunk=2,
max_knowledge_sequence=15,
)
self.kg = kg_index
# 初始化语言模型
self.llm = llm
# 初始化嵌入模型
self.embeddings = OpenAIEmbedding()
def vector_search(self, query):
# 在向量数据库中搜索相关文本
results = self.vector_db.as_retriever().retrieve(query)
print(results)
return [result.node for result in results]
def graph_search(self, query):
# 在知识图谱中搜索相关信息
results = self.kg.as_retriever().retrieve(query)
print(results)
return [result.node for result in results]
def generate_answer(self, query):
vector_context = self.vector_search(query)
graph_context = self.graph_search(query)
combined_context = "\n".join(vector_context) + "\n" + graph_context
prompt = f"Question: {query}\nContext: {combined_context}\nAnswer:"
return self.llm.generate(prompt)
# 使用示例
hybrid_rag = HybridRAG()
question = "TiDB从哪个版本开始支持资源管控特性?"
answer = hybrid_rag.generate_answer(question)
print(answer)
以上实现中只是简单的拼装了从向量数据库和图数据库中的检索结果,实际应用中可引入相关reranker模型进一步做精排提高上下文精准度。不管最终使用什么样的 RAG 架构,我们要达到的目的始终是保障传递给大语言模型的上下文是更完整更有效的,从而让大语言模型给出更准确的回答.
RAG 架构已经是提升大语言模型能力的有效方案,鉴于在不同的业务场景中正确率无法稳定保持,因此也衍生出了一系列变化后的 RAG 架构,如 Advanced RAG、GraphRAG、HybridRAG、RAG2.0 等等,它们之间有的是互补关系,有的是优化增强,也有另起炉灶的路线,可以看出在 LLM 应用优化上依然处于快速变化当中.
最后此篇关于更强的RAG:向量数据库和知识图谱的结合的文章就讲到这里了,如果你想了解更多关于更强的RAG:向量数据库和知识图谱的结合的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
60
4
 0
0
我有一个功能是转换 ADO Recordset 进入html: class function RecordsetToHtml(const rs: _Recordset): WideString; 该函
经过几天的研究和讨论,我想出了这种方法来收集访客的熵(你可以看到我的研究历史here) 当用户访问时,我运行此代码: $entropy=sha1(microtime().$pepper.$_SERVE
给定一个无序列表 List ,我需要查找是否存在 String与提供的字符串匹配。 所以,我循环 for (String k : keys) { if (Utils.keysM
我已经搜索过这个问题,但没有找到我正在寻找的答案。 基本上,我想将类构造函数包装在 try/except 子句中,以便它忽略构造函数内特定类型的错误(但无论如何都会记录并打印它们)。我发现做到这一点的
我有一组三个数字,我想将一组数字与另一组数字进行比较。即,第一组中的每个数字小于另一组中的至少一个数字。需要注意的是,第一组中的下一个数字必须小于第二组中的不同数字(即,{6,1,6} 对 {8,8,
关闭。这个问题是off-topic .它目前不接受答案。 想改进这个问题吗? Update the question所以它是on-topic用于堆栈溢出。 关闭 9 年前。 Improve this
首先介绍一下背景: 我正在开发一个带有 EJB 模块和应用程序客户端模块的企业应用程序 (ear)。我还使用 hibernate JPA 来实现持久性,并使用 swingx 来实现 GUI。这些是唯一
我正在尝试在我的上网本上运行 Eclipse 以便能够为 Android 进行开发。 您可能已经猜到了,Eclipse 非常慢,并且不容易有效地开发。 我正在使用 Linux Ubuntu 并且我还有
for row, instrument in enumerate(instruments): for col, value in enumerate(instrument):
return not a and not b ^ 我如何以更好的格式表达它 最佳答案 DeMorgan's Law , 也许? return not (a or b) 我认为在这一点上已经足够简单了
我正在尝试让 Font Awesome 图标看起来更 slim https://jsfiddle.net/cliffeee/7L6ehw9r/1/ . 我尝试使用“-webkit-text-strok
假设我有一个名为 vals 的数据框,如下所示: id…………日期…………min_date…… .........最大日期 1…………2016/01/01…………2017/01/01…………2018/
是否有更 Pythonic 的方式来做到这一点?: if self.name2info[name]['prereqs'] is None: se
我有一个函数可以将一些文本打印到它接收到的 ostream&。如果 ostream 以终端为目标,我想让它适应终端宽度,否则默认为某个值。 我现在做的是: 从 ostream 中获取一个 ofstre
这个问题在这里已经有了答案: Should a retrieval method return 'null' or throw an exception when it can't produce
我有这个 bc = 'off' if c.page == 'blog': bc = 'on' print(bc) 有没有更 Pythonic(和/或更短)的方式在 Python 中编写? 最佳
输入:一个包含 50,000 行的 CSV;每行包含 910 列值 0/1。 输出:运行我的 CNN 的数据框。 我编写了一个逐行读取 CSV 的代码。对于每一行,我将数据分成两部分,称为神经元(90
据我所知,with block 会在您退出 block 后自动调用 close(),并且它通常用于确保不会忘记关闭一个文件。 好像没有技术上的区别 with open(file, 'r+') as f
我有一个使用 Entity Framework V6.1.1 的 MVC 5 网站。 Entity Framework DbContext 类和模型最初都在网站项目中。这个项目有 3 个 DbCont
我是编程新手,在尝试通过将 tableView 和关联 View 的创建移动到单独的类并将委托(delegate)和数据源从 VC 移动到单独的类来精简我的 ViewController 时遇到了一些

我是一名优秀的程序员,十分优秀!