
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 25
25
 4
4


我对一些数据应用了一些机器学习算法,如线性回归、逻辑回归和朴素贝叶斯,但我试图避免使用 RDD 并开始使用 DataFrame,因为 RDDs are slower比pyspark下的Dataframes(见图1)。
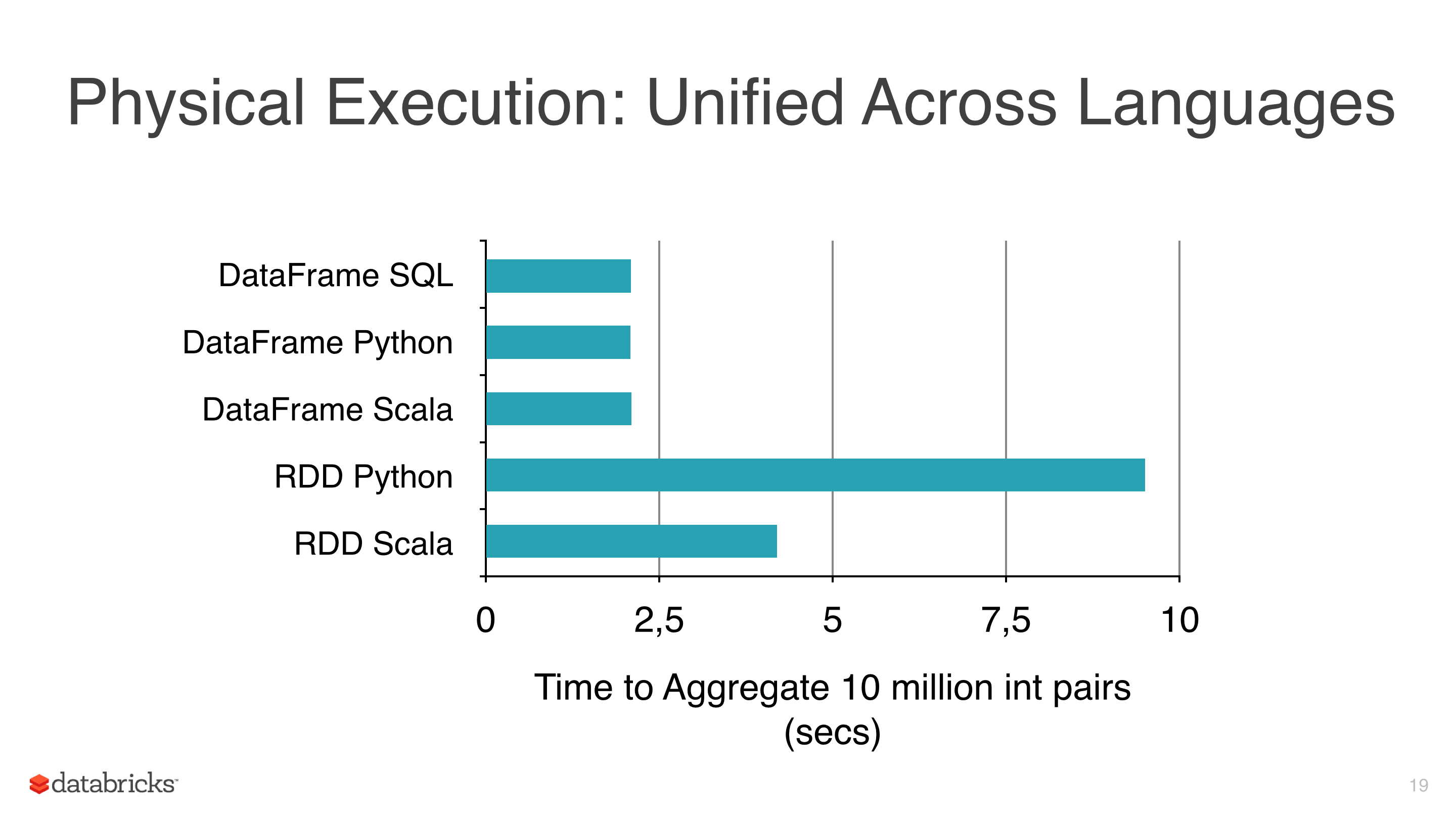
我使用 DataFrames 的另一个原因是 ml 库有一个类对调整模型非常有用,它是 CrossValidator。这个类拟合后返回一个模型,显然这个方法要测试几个场景,然后返回一个fitted model (具有最佳参数组合)。
我使用的集群不是很大,数据也很大,有些拟合需要几个小时,所以我想保存这些模型以便以后重用它们,但我还没有意识到如何,有什么我忽略的吗?
笔记:
最佳答案
Spark 2.0.0+
乍一看全部Transformers和 Estimators实现 MLWritable 使用以下界面:
def write: MLWriter
def save(path: String): Unit
MLReadable 具有以下界面
def read: MLReader[T]
def load(path: String): T
save将模型写入磁盘的方法,例如
import org.apache.spark.ml.PipelineModel
val model: PipelineModel
model.save("/path/to/model")
val reloadedModel: PipelineModel = PipelineModel.load("/path/to/model")
MLWritable /
JavaMLWritable 和
MLReadable /
JavaMLReadable 分别:
from pyspark.ml import Pipeline, PipelineModel
model = Pipeline(...).fit(df)
model.save("/path/to/model")
reloaded_model = PipelineModel.load("/path/to/model")
write.ml /
read.ml 功能,但截至今天,这些与其他支持的语言不兼容 -
SPARK-15572 .
PipelineStage 的类匹配。 .例如,如果您保存了
LogisticRegressionModel你应该使用
LogisticRegressionModel.load不是
LogisticRegression.load .
save 保存模型方法。因为几乎每个
model实现
MLWritable界面。例如,
LinearRegressionModel拥有它,因此可以使用它将模型保存到所需的路径。
DataFrames 的一些操作可以进行优化,与普通
RDDs 相比,它可以转化为更高的性能.
DataFrames提供高效的缓存,SQLish API 可以说比 RDD API 更容易理解。
DataFrames 上的简单操作喜欢 select或 withColumn显示与其 RDD 等效项类似的性能,例如 map , ml.classification.NaiveBayes are simply wrappers围绕其mllib API, MLLib算法,MLLib使用您选择的方法进行建模(Spark 模型或 PMML)关于apache-spark - 保存 ML 模型以供将来使用,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/33027767/
25
4
 0
0
如何将运算符传递给 ML 中的函数?例如,考虑这个伪代码: function (int a, int b, operator op) return a op b 这里,运算符可以是 op +
我尝试在 Google Cloud ML 上运行来自 github 的 word-RNN 模型。提交作业后,我在日志文件中收到错误。 这是我提交的训练内容 gcloud ml-engine jobs
在 a.ml 中定义了一个记录类型 t 并且也是透明地定义的 在 a.mli 中,即在 d 接口(interface)中,以便类型定义可用 到所有其他文件。 a.ml 还有一个函数 func,它返回一
关闭 ML.NET 模型生成器后,是否可以为创建的模型重新打开它? 我可以删除创建的模型并重新开始,但这并不理想。 最佳答案 不,不是真的。 AutoML/Model Builder 可以生成代码并将
我有一个关于训练可以预测名称是否为女性的 ML.NET 的问题。该模型可以使用这样的管道进行训练: var mlContext = new MLContext(); IDataView trainin
我在 ASP.NET Core 应用程序中使用 ML.NET,并在 Startup 中使用以下代码: var builder = services.AddPredictionEnginePool();
我使用 sklearn 创建了一个模型进行分类。当我调用函数 y_pred2 = clf.predict (features2) 时,它会返回一个包含我的预测的所有 id 的列表 y_pred2 =
我已向 cloud ml 提交了训练作业。但是,它找不到 csv 文件。它就在桶里。这是代码。 # Use scikit-learn to grid search the batch size and
我是 Azure Databricks 的新手,尽管我在 Databricks 方面有很好的经验,但仅限于 Data Engg 方面。我对 Databricks Runtime ML 和 ML Flo
为什么我尝试将经过训练的模型部署到 Google Cloud ML,却收到以下错误: Create Version failed.Model validation failed: Model meta
我是 Azure Databricks 的新手,尽管我在 Databricks 方面有很好的经验,但仅限于 Data Engg 方面。我对 Databricks Runtime ML 和 ML Flo
我是 Azure ML 新手。我有一些疑问。有人可以澄清下面列出的我的疑问吗? Azure ML 服务与 Azure ML 实验服务之间有什么区别。 Azure ML 工作台和 Azure ML St
我的 Cloud ML 训练作业已完成,输出如下: "consumedMLUnits": 43.24 我如何使用此信息来确定培训工作的成本?我无法在以下两个选项之间做出决定: 1)根据这个page ,
docs for setting up Google Cloud ML建议安装 Tensorflow 版本 r0.11。我观察到 r0.12 中新提供的 TensorFlow 函数在 Cloud ML
我正在关注一个来自 - https://spark.apache.org/docs/2.3.0/ml-classification-regression.html#multinomial-logist
我想使用 mosmlc 将我的 ML 程序编译成可执行二进制文件。但是,我找不到太多关于如何操作的信息。 我想编译的代码在这里http://people.pwf.cam.ac.uk/bt288/tic
假设我有两个 Azure ML 工作区: Workspace1 - 由一个团队(Team1)使用,该团队仅训练模型并将模型存储在 Workspace1 的模型注册表中 Workspace2 - 由另一
我尝试使用以下命令行在 Azure 上的 Linux(Ubuntu) 数据科学虚拟机上设置我的 Azure 机器学习环境: az ml 环境设置 但是,它显示错误为加载命令模块 ml 时出错。一直在谷
假设我有两个 Azure ML 工作区: Workspace1 - 由一个团队(Team1)使用,该团队仅训练模型并将模型存储在 Workspace1 的模型注册表中 Workspace2 - 由另一
我尝试使用以下命令行在 Azure 上的 Linux(Ubuntu) 数据科学虚拟机上设置我的 Azure 机器学习环境: az ml 环境设置 但是,它显示错误为加载命令模块 ml 时出错。一直在谷

我是一名优秀的程序员,十分优秀!