
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 25
25
 4
4


我正在使用 Verilog 设计类似 MIPS 的 CPU,现在正在处理数据危险。我有这些说明:
Ins[0] = LW r1 r0(100)
Ins[1] = LW r2 r0(101)
Ins[2] = ADD r3 r2 r1
我正在使用管道,我的数据路径是这样的: 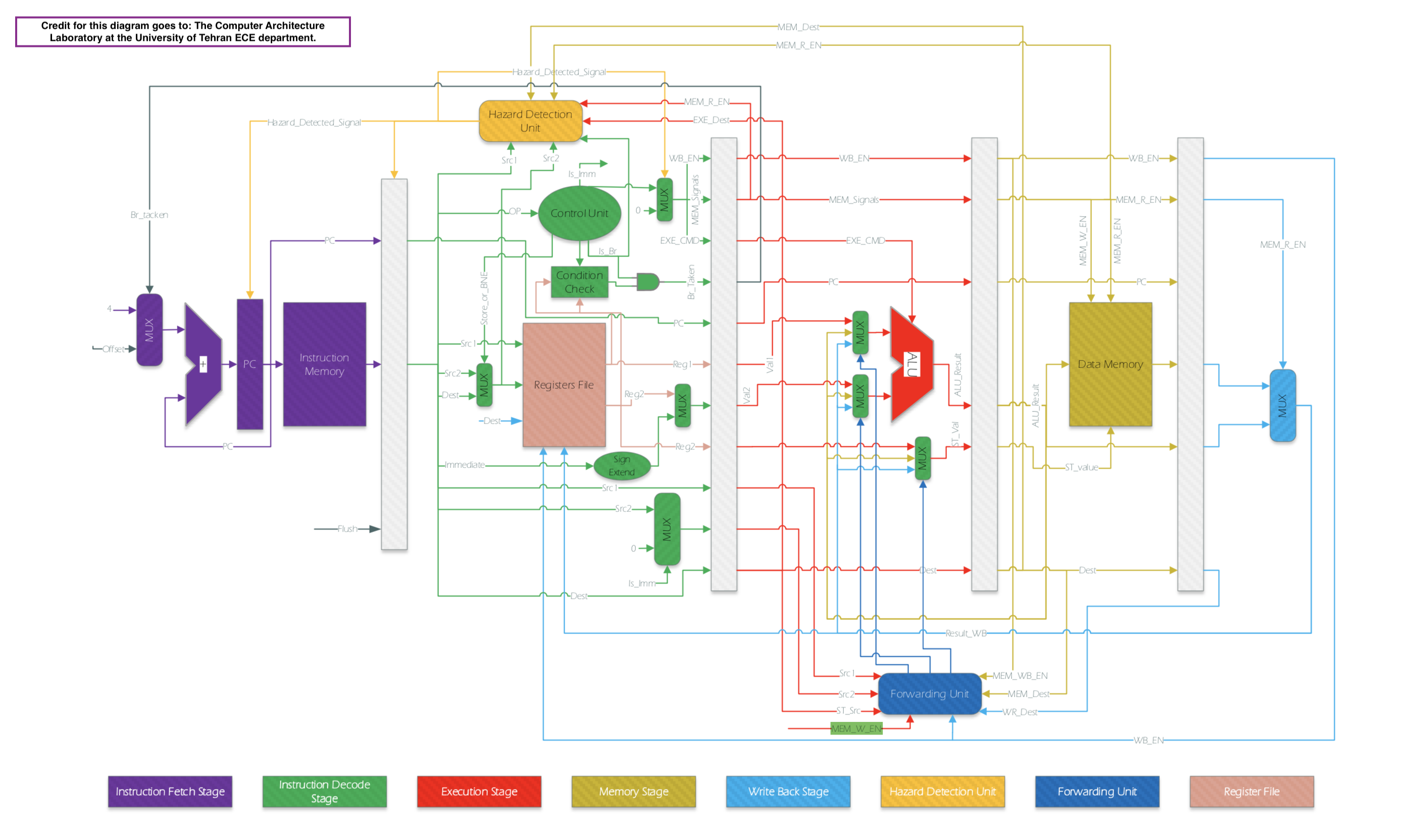 我有 5 个阶段,有 4 个锁存缓冲区将它们分开。
我有 5 个阶段,有 4 个锁存缓冲区将它们分开。
问题是,当ADD指令到达阶段3(ALU应该计算r1 + r2)时,指令1(第二个LW)处于阶段4并且尚未读取内存的r0 + 101地址,因此我应该停止一个周期,然后 Ins1 到达最后阶段。
在这种情况下,第一个 LW 已完成其工作,并且 r1 的新值不在 dataPath 中的任何位置,但我需要将此值传递给 ALU 的输入 B。
(这称为数据转发,因为当第三条指令处于第 2 阶段时,r1 的值尚未准备好,我应该从后面的阶段转发它(从最后一个 MUX 出来并进入 ALU MUX 的蓝色电线) ,但是由于第二个LW的停顿,我还没有r1的值。
感谢您的帮助。
最佳答案
我犯了一个错误。我的错误是,当 LDM 指令后面跟着 RType 时,当 Rtype 处于 stage3 并且 LDM 处于 stage4 时,我会停止处理器。相反,当 RType 处于 stage2(解码)且 LDM 处于 stage3(执行)时,我应该在此之前一个时钟检测依赖性。
在这种情况下,我应该停止管道。
因此,当 Rtype 处于阶段 2、第二个 LDM 处于阶段 3、第一个 LDM 处于阶段 4 时,我检测到依赖性并停止管道一个周期。
因此在下一个时钟中,Rtype 仍处于 stage2,第二个 LDM 处于 stage4,第一个 LDM 正在写回寄存器,因此由于 RType 仍处于 stage2,因此它可以读取写入寄存器文件的数据。 (写回在时钟的负边完成。在posege中,RType的第一个参数已准备好。)
关于assembly - 数据危险的特定情况(当 R 类型指令出现在两个连续的 LW 之后时),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/50722307/
25
4
 0
0
我正在从 Stata 迁移到 R(plm 包),以便进行面板模型计量经济学。在 Stata 中,面板模型(例如随机效应)通常报告组内、组间和整体 R 平方。 I have found plm 随机效应
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 想改进这个问题?将问题更新为 on-topic对于堆栈溢出。 6年前关闭。 Improve this qu
我想要求用户输入整数值列表。用户可以输入单个值或一组多个值,如 1 2 3(spcae 或逗号分隔)然后使用输入的数据进行进一步计算。 我正在使用下面的代码 EXP <- as.integer(rea
当 R 使用分类变量执行回归时,它实际上是虚拟编码。也就是说,省略了一个级别作为基础或引用,并且回归公式包括所有其他级别的虚拟变量。但是,R 选择了哪一个作为引用,以及我如何影响这个选择? 具有四个级
这个问题基本上是我之前问过的问题的延伸:How to only print (adjusted) R-squared of regression model? 我想建立一个线性回归模型来预测具有 15
我在一台安装了多个软件包的 Linux 计算机上安装了 R。现在我正在另一台 Linux 计算机上设置 R。从他们的存储库安装 R 很容易,但我将不得不使用 安装许多包 install.package
我正在阅读 Hadley 的高级 R 编程,当它讨论字符的内存大小时,它说: R has a global string pool. This means that each unique strin
我们可以将 Shiny 代码写在两个单独的文件中,"ui.R"和 "server.R" , 或者我们可以将两个模块写入一个文件 "app.R"并调用函数shinyApp() 这两种方法中的任何一种在性
我正在使用 R 通过 RGP 包进行遗传编程。环境创造了解决问题的功能。我想将这些函数保存在它们自己的 .R 源文件中。我这辈子都想不通怎么办。我尝试过的一种方法是: bf_str = print(b
假设我创建了一个函数“function.r”,在编辑该函数后我必须通过 source('function.r') 重新加载到我的全局环境中。无论如何,每次我进行编辑时,我是否可以避免将其重新加载到我的
例如,test.R 是一个单行文件: $ cat test.R # print('Hello, world!') 我们可以通过Rscript test.R 或R CMD BATCH test.R 来
我知道我可以使用 Rmd 来构建包插图,但想知道是否可以更具体地使用 R Notebooks 来制作包插图。如果是这样,我需要将 R Notebooks 编写为包小插图有什么不同吗?我正在使用最新版本
我正在考虑使用 R 包的共享库进行 R 的站点安装。 多台计算机将访问该库,以便每个人共享相同的设置。 问题是我注意到有时您无法更新包,因为另一个 R 实例正在锁定库。我不能要求每个人都关闭它的 R
我知道如何从命令行启动 R 并执行表达式(例如, R -e 'print("hello")' )或从文件中获取输入(例如, R -f filename.r )。但是,在这两种情况下,R 都会运行文件中
我正在尝试使我当前的项目可重现,因此我正在创建一个主文档(最终是一个 .rmd 文件),用于调用和执行其他几个文档。这样我自己和其他调查员只需要打开和运行一个文件。 当前设置分为三层:主文件、2 个读
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 想改进这个问题?将问题更新为 on-topic对于堆栈溢出。 5年前关闭。 Improve this qu
我的 R 包中有以下描述文件 Package: blah Title: What the Package Does (one line, title case) Version: 0.0.0.9000
有没有办法更有效地编写以下语句?accel 是一个数据框。 accel[[2]]<- accel[[2]]-weighted.mean(accel[[2]]) accel[[3]]<- accel[[
例如,在尝试安装 R 包时 curl作为 usethis 的依赖项: * installing *source* package ‘curl’ ... ** package ‘curl’ succes
我想将一些软件作为一个包共享,但我的一些脚本似乎并不能很自然地作为函数运行。例如,考虑以下代码块,其中“raw.df”是一个包含离散和连续类型变量的数据框。函数“count.unique”和“squa

我是一名优秀的程序员,十分优秀!