
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 28
28
 4
4


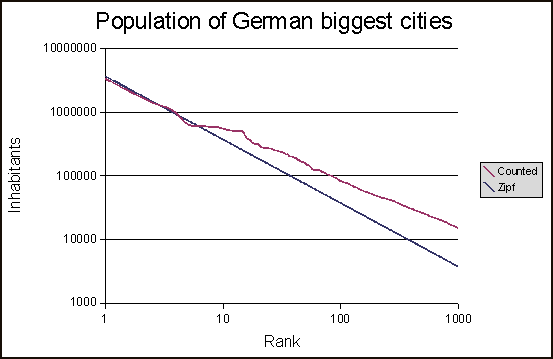
对于家庭作业,我必须绘制文本的词频并将其与最佳 zipf 分布进行比较。
根据对数对数图中的排名绘制文本的词频计数似乎效果很好。
但是我在计算最佳 zipf 分布时遇到了麻烦。结果应该如下所示:
我不明白计算 zipf 直线的方程是什么样的。
在zipf定律的德语维基百科页面上,我发现了一个似乎有效的方程式

但没有引用来源,所以我不明白 1.78 常数来自哪里。
#tokenizes the file
tokens = word_tokenize(raw)
tokensNLTK = Text(tokens)
#calculates the FreqDist of all words - all words in lower case
freq_list = FreqDist([w.lower() for w in tokensNLTK]).most_common()
#Data for X- and Y-Axis plot
values=[]
for item in (freq_list):
value = (list(item)[1]) / len([w.lower() for w in tokensNLTK])
values.append(value)
#graph of counted frequencies gets plotted
plt.yscale('log')
plt.xscale('log')
plt.plot(np.array(list(range(1, (len(values)+1)))), np.array(values))
#graph of optimal zipf distribution is plotted
optimal_zipf = 1/(np.array(list(range(1, (len(values)+1))))* np.log(1.78*len(values)))###1.78
plt.plot(np.array(list(range(1, (len(values)+1)))), optimal_zipf)
plt.show()
我使用此脚本的结果如下所示:

但我只是不确定最佳 zipf 分布是否计算正确。如果是这样,最佳 zipf 分布不应该在某一点穿过 X 轴吗?
编辑:如果有帮助的话,我的文本有 2440400 个标记和 27491 个类型
最佳答案
看看这个 research paper by Andrew William Chisholm.特别是第 #22 页。
H(N) ≈ ln(N) + γ
Where γ is the Euler-Mascheroni constant with approximate value 0.57721. Noting that exp(γ) ≈ 1.78, equation <...> can be re-written to become for large N (N must be greater than 1,000 for this to be accurate to one part in a thousand).
pr ≈ 1 / [r*ln(1.78*N)]
关于python - 如何计算文本中词频的最佳 zipf 分布,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55518957/
28
4
 0
0
我有两个项目。一个项目正在运行,没有任何问题。它是从 gitlab 下载的。另一个项目是从 github 下载的。 github项目有这个问题。我想使用默认的 gradle 分布。我想知道我做错了什么
我正在通过我学习的大学提供的 VNC 软件(远程访问)使用 IBM bigInsights,但我无法通过该桌面访问 Internet。为了使用互联网上的一些数据样本,我决定安装 Hadoop 在我的笔
所以,这非常简单,我有一个包含嵌套列表的列表,如下所示: List( *list1* List(List("n1", "n3"), List("n1", "n4"), List("n3", "n4")
我有以下示例。 prefix = ['blue ','brown '] suffix = [('dog','shoes','bike'), ('tree','cat','car')] 我想获得一个如下
我创建了一项调查并将其发送出去。该调查要求用户提供电子邮件,然后要求他们从包含 8 个不同选项的下拉菜单中选择要吃哪顿饭。有些人使用同一封电子邮件多次填写调查,但食物选择不同。 我有一个如下所示的 M
我在 Python 中使用 plotly 来创建由某些分类变量着色的美国县的等值线。由于县非常小,因此图像中的边界线占主导地位。我怎样才能摆脱它们(或将它们的宽度设置为零)? 到目前为止的代码和输出(
我们有qgamma在 R 和 gamm.inv在 excel 中,我无法使用 invgamma 获得相同的结果python中的函数。例如在excel中GAMMA.INV(0.99,35,0.08)=4
过去几年我经常使用 Docker,但对于 Kubernetes 来说我还是个新手。我从今天开始,与我以前使用 Docker swarm 的方式相比,我正在努力思考 Pod 概念的实用性。 假设我有一个
我有一个 UIStackView然而,subViews的第一个 View 是 UILabel它没有相应地调整它的大小。 我的代码如下; private let stackView: UIStackVi
我想绘制自由度为 1、2、5 和 10 的 Student t 分布;所有在一个图中,并为图中的每个分布使用不同的颜色。此外,在 Canvas 的左上角创建一个图例,并增加 df = 1 的曲线线宽。
我对 Python 很陌生,我在互联网上浏览过,但找不到任何可以帮助我解决问题的逻辑。 我在图中有降水值,现在我需要根据图中的这些值拟合 GEV 分布。每个值等于从 1974 年到 2017 年的一年
我正在尝试复制此图 https://wind-data.ch/tools/weibull.php 我编写的代码是 import matplotlib.pyplot as plt import nump
对于家庭作业,我必须绘制文本的词频并将其与最佳 zipf 分布进行比较。 根据对数对数图中的排名绘制文本的词频计数似乎效果很好。 但是我在计算最佳 zipf 分布时遇到了麻烦。结果应该如下所示: 我不
Mathematica 具有四参数广义逆 Gamma 分布: http://reference.wolfram.com/mathematica/ref/InverseGammaDistribution
正在用 C 语言开发一个学校项目,使用 Pthreads 将一维数组分解为 tRows 和 tCols 的子矩阵。整个数组的大小为 wRows 和 wCols。假设 wCols = 4、wRows =
有没有办法得到制服int32_t没有警告的分发?我用这个uniform_int_distribution在我的代码中,但我收到警告: 54988961.cpp: In function ‘int ma
在花了相当多的时间试图了解如何在 postgresql 数据库服务器之间实现负载平衡(分配数据库处理负载)之后,我来到这里。 我有一个 postgresql 系统,每秒吸引大约 100 笔交易,而且这
所以标题已经说明了一切。我们正在开发一个开始获得大量依赖项的项目。到目前为止,我们一直在使用 setuptools,但越来越多的依赖项要么不容易安装(例如 wxPython),要么在某些使用 easy
我有以下代码: #include #include #include using namespace boost::numeric; using namespace interval_lib;
我有一个对象列表,我想以随机顺序连续访问这些对象。 我想知道是否有一种方法可以确保随机值并不总是相似。 例子。 我的列表是队列列表,我试图交错这些值以生成用于测试的真实场景。 我并不是特别想要队列 1

我是一名优秀的程序员,十分优秀!