
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 28
28
 4
4


我对整个领域有点陌生,因此决定研究 MNIST 数据集。我几乎改编了 https://github.com/pytorch/examples/blob/master/mnist/main.py 中的整个代码,只有一个重大变化:数据加载。我不想使用 Torchvision 中预加载的数据集。所以我用了MNIST in CSV .
我通过继承 Dataset 并创建一个新的数据加载器来加载 CSV 文件中的数据。相关代码如下:
mean = 33.318421449829934
sd = 78.56749081851163
# mean = 0.1307
# sd = 0.3081
import numpy as np
from torch.utils.data import Dataset, DataLoader
class dataset(Dataset):
def __init__(self, csv, transform=None):
data = pd.read_csv(csv, header=None)
self.X = np.array(data.iloc[:, 1:]).reshape(-1, 28, 28, 1).astype('float32')
self.Y = np.array(data.iloc[:, 0])
del data
self.transform = transform
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
item = self.X[idx]
label = self.Y[idx]
if self.transform:
item = self.transform(item)
return (item, label)
import torchvision.transforms as transforms
trainData = dataset('mnist_train.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
testData = dataset('mnist_test.csv', transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,), (sd,))
]))
train_loader = DataLoader(dataset=trainData,
batch_size=10,
shuffle=True,
)
test_loader = DataLoader(dataset=testData,
batch_size=10,
shuffle=True,
)
然而,这段代码给了我你在图片中看到的绝对奇怪的训练错误图,以及 11% 的最终验证错误,因为它将所有内容分类为“7”。 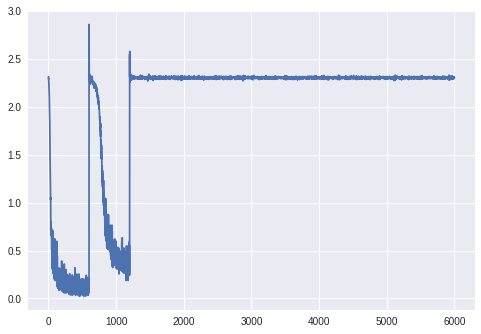
我设法将问题追溯到如何标准化数据,如果我使用示例代码中给出的值(0.1307和0.3081)进行变换。标准化,同时将数据读取为“uint8”类型,它就可以工作完美。请注意,这两种情况下提供的数据差异极小。对 0 到 1 的值按 0.1307 和 0.3081 进行归一化与对 0 到 255 的值按 33.31 和 78.56 进行归一化具有相同的效果。这些值甚至基本相同(黑色像素在第一种情况下对应于 -0.4241,在第一种情况下对应于 -0.4242)在第二个)。
如果您想查看可以清楚地看到此问题的 IPython Notebook,请查看 https://colab.research.google.com/drive/1W1qx7IADpnn5e5w97IcxVvmZAaMK9vL3
我无法理解是什么导致了这两种略有不同的数据加载方式的行为存在如此巨大的差异。任何帮助将不胜感激。
最佳答案
长话短说:你需要改变item = self.X[idx]至item = self.X[idx].copy() .
长话短说:T.ToTensor()运行 torch.from_numpy ,它返回一个张量,该张量为 numpy 数组的内存设置别名 dataset.X 。和T.Normalize() works inplace ,因此每次抽取样本时都有 mean减去并除以 std ,导致数据集降级。
编辑:关于为什么它在原始 MNIST 加载器中工作,兔子洞甚至更深。 MNIST中的关键行是图像是 transformed进入PIL.Image实例。该操作声称仅在缓冲区不连续的情况下进行复制(在我们的例子中),但在 hood 下。它会检查它是否被跨步了(确实如此),然后复制它。因此,幸运的是,默认的 torchvision 管道涉及 T.Normalize() 的复制,从而就地操作。不会损坏内存 self.data我们的MNIST实例。
关于python - MNIST Pytorch 中的验证错误意外增加,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/53652015/
28
4
 0
0
我正在处理一组标记为 160 个组的 173k 点。我想通过合并最接近的(到 9 或 10 个组)来减少组/集群的数量。我搜索过 sklearn 或类似的库,但没有成功。 我猜它只是通过 knn 聚类
我有一个扁平数字列表,这些数字逻辑上以 3 为一组,其中每个三元组是 (number, __ignored, flag[0 or 1]),例如: [7,56,1, 8,0,0, 2,0,0, 6,1,
我正在使用 pipenv 来管理我的包。我想编写一个 python 脚本来调用另一个使用不同虚拟环境(VE)的 python 脚本。 如何运行使用 VE1 的 python 脚本 1 并调用另一个 p
假设我有一个文件 script.py 位于 path = "foo/bar/script.py"。我正在寻找一种在 Python 中通过函数 execute_script() 从我的主要 Python
这听起来像是谜语或笑话,但实际上我还没有找到这个问题的答案。 问题到底是什么? 我想运行 2 个脚本。在第一个脚本中,我调用另一个脚本,但我希望它们继续并行,而不是在两个单独的线程中。主要是我不希望第
我有一个带有 python 2.5.5 的软件。我想发送一个命令,该命令将在 python 2.7.5 中启动一个脚本,然后继续执行该脚本。 我试过用 #!python2.7.5 和http://re
我在 python 命令行(使用 python 2.7)中,并尝试运行 Python 脚本。我的操作系统是 Windows 7。我已将我的目录设置为包含我所有脚本的文件夹,使用: os.chdir("
剧透:部分解决(见最后)。 以下是使用 Python 嵌入的代码示例: #include int main(int argc, char** argv) { Py_SetPythonHome
假设我有以下列表,对应于及时的股票价格: prices = [1, 3, 7, 10, 9, 8, 5, 3, 6, 8, 12, 9, 6, 10, 13, 8, 4, 11] 我想确定以下总体上最
所以我试图在选择某个单选按钮时更改此框架的背景。 我的框架位于一个类中,并且单选按钮的功能位于该类之外。 (这样我就可以在所有其他框架上调用它们。) 问题是每当我选择单选按钮时都会出现以下错误: co
我正在尝试将字符串与 python 中的正则表达式进行比较,如下所示, #!/usr/bin/env python3 import re str1 = "Expecting property name
考虑以下原型(prototype) Boost.Python 模块,该模块从单独的 C++ 头文件中引入类“D”。 /* file: a/b.cpp */ BOOST_PYTHON_MODULE(c)
如何编写一个程序来“识别函数调用的行号?” python 检查模块提供了定位行号的选项,但是, def di(): return inspect.currentframe().f_back.f_l
我已经使用 macports 安装了 Python 2.7,并且由于我的 $PATH 变量,这就是我输入 $ python 时得到的变量。然而,virtualenv 默认使用 Python 2.6,除
我只想问如何加快 python 上的 re.search 速度。 我有一个很长的字符串行,长度为 176861(即带有一些符号的字母数字字符),我使用此函数测试了该行以进行研究: def getExe
list1= [u'%app%%General%%Council%', u'%people%', u'%people%%Regional%%Council%%Mandate%', u'%ppp%%Ge
这个问题在这里已经有了答案: Is it Pythonic to use list comprehensions for just side effects? (7 个答案) 关闭 4 个月前。 告
我想用 Python 将两个列表组合成一个列表,方法如下: a = [1,1,1,2,2,2,3,3,3,3] b= ["Sun", "is", "bright", "June","and" ,"Ju
我正在运行带有最新 Boost 发行版 (1.55.0) 的 Mac OS X 10.8.4 (Darwin 12.4.0)。我正在按照说明 here构建包含在我的发行版中的教程 Boost-Pyth
学习 Python,我正在尝试制作一个没有任何第 3 方库的网络抓取工具,这样过程对我来说并没有简化,而且我知道我在做什么。我浏览了一些在线资源,但所有这些都让我对某些事情感到困惑。 html 看起来

我是一名优秀的程序员,十分优秀!