
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 25
25
 4
4


我正在尝试使用正则表达式模块编写一小段代码,该模块将从 .csv 文件中删除 URL 的一部分,并返回选定的 block 作为输出。如果该部分以 .com/go/结尾,我希望它在“go”之后返回内容。代码如下:
import csv
import re
with open('rtdata.csv', 'rb') as fhand:
reader = csv.reader(fhand)
for row in reader:
url=row[6].strip()
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
print url
print section
这是一些示例输入输出:
http://www.xxxxxxxxx.com/go/news/videos/新闻/视频http://www.xxxxxxxxx.com/new-cars/新车我在这里缺少什么?
最佳答案
尝试以下操作
s = re.search('http://www.xxxxxxxxx.com/(go/)?(.*)/', url)
section = s.group(2)
而不是
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
所用正则表达式的直观说明:
http://www.xxxxxxxxx.com/(go/)?(.*)/
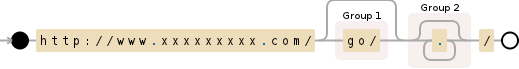
关于python - 简单的Python正则表达式问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/19552278/
25
4
 0
0
我正在处理一组标记为 160 个组的 173k 点。我想通过合并最接近的(到 9 或 10 个组)来减少组/集群的数量。我搜索过 sklearn 或类似的库,但没有成功。 我猜它只是通过 knn 聚类
我有一个扁平数字列表,这些数字逻辑上以 3 为一组,其中每个三元组是 (number, __ignored, flag[0 or 1]),例如: [7,56,1, 8,0,0, 2,0,0, 6,1,
我正在使用 pipenv 来管理我的包。我想编写一个 python 脚本来调用另一个使用不同虚拟环境(VE)的 python 脚本。 如何运行使用 VE1 的 python 脚本 1 并调用另一个 p
假设我有一个文件 script.py 位于 path = "foo/bar/script.py"。我正在寻找一种在 Python 中通过函数 execute_script() 从我的主要 Python
这听起来像是谜语或笑话,但实际上我还没有找到这个问题的答案。 问题到底是什么? 我想运行 2 个脚本。在第一个脚本中,我调用另一个脚本,但我希望它们继续并行,而不是在两个单独的线程中。主要是我不希望第
我有一个带有 python 2.5.5 的软件。我想发送一个命令,该命令将在 python 2.7.5 中启动一个脚本,然后继续执行该脚本。 我试过用 #!python2.7.5 和http://re
我在 python 命令行(使用 python 2.7)中,并尝试运行 Python 脚本。我的操作系统是 Windows 7。我已将我的目录设置为包含我所有脚本的文件夹,使用: os.chdir("
剧透:部分解决(见最后)。 以下是使用 Python 嵌入的代码示例: #include int main(int argc, char** argv) { Py_SetPythonHome
假设我有以下列表,对应于及时的股票价格: prices = [1, 3, 7, 10, 9, 8, 5, 3, 6, 8, 12, 9, 6, 10, 13, 8, 4, 11] 我想确定以下总体上最
所以我试图在选择某个单选按钮时更改此框架的背景。 我的框架位于一个类中,并且单选按钮的功能位于该类之外。 (这样我就可以在所有其他框架上调用它们。) 问题是每当我选择单选按钮时都会出现以下错误: co
我正在尝试将字符串与 python 中的正则表达式进行比较,如下所示, #!/usr/bin/env python3 import re str1 = "Expecting property name
考虑以下原型(prototype) Boost.Python 模块,该模块从单独的 C++ 头文件中引入类“D”。 /* file: a/b.cpp */ BOOST_PYTHON_MODULE(c)
如何编写一个程序来“识别函数调用的行号?” python 检查模块提供了定位行号的选项,但是, def di(): return inspect.currentframe().f_back.f_l
我已经使用 macports 安装了 Python 2.7,并且由于我的 $PATH 变量,这就是我输入 $ python 时得到的变量。然而,virtualenv 默认使用 Python 2.6,除
我只想问如何加快 python 上的 re.search 速度。 我有一个很长的字符串行,长度为 176861(即带有一些符号的字母数字字符),我使用此函数测试了该行以进行研究: def getExe
list1= [u'%app%%General%%Council%', u'%people%', u'%people%%Regional%%Council%%Mandate%', u'%ppp%%Ge
这个问题在这里已经有了答案: Is it Pythonic to use list comprehensions for just side effects? (7 个答案) 关闭 4 个月前。 告
我想用 Python 将两个列表组合成一个列表,方法如下: a = [1,1,1,2,2,2,3,3,3,3] b= ["Sun", "is", "bright", "June","and" ,"Ju
我正在运行带有最新 Boost 发行版 (1.55.0) 的 Mac OS X 10.8.4 (Darwin 12.4.0)。我正在按照说明 here构建包含在我的发行版中的教程 Boost-Pyth
学习 Python,我正在尝试制作一个没有任何第 3 方库的网络抓取工具,这样过程对我来说并没有简化,而且我知道我在做什么。我浏览了一些在线资源,但所有这些都让我对某些事情感到困惑。 html 看起来

我是一名优秀的程序员,十分优秀!