
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 26
26
 4
4


在匹配字符串中的空格时,我遇到了 Mysql 中正则表达式语法的问题。
我有一个邮政编码数据库,格式为:1111 AA CITYNAME 或 1111 CITYNAME。
由此,我想提取邮政编码和城市名称,我使用了以下代码:
DROP FUNCTION IF EXISTS GET_POSTALCODE;
CREATE FUNCTION GET_POSTALCODE(input VARCHAR(255))
RETURNS VARCHAR(255)
BEGIN
DECLARE output VARCHAR(255) DEFAULT '';
IF input LIKE '^[1-9][0-9]{3}[[:blank:]][A-Z]{2}[[:blank:]]%'
THEN
SET output = SUBSTRING(input, 1, 7);
ELSE
SET output = SUBSTRING(input, 1, 4);
END IF;
RETURN output;
END
我希望将 9741 NE Groningen 的输入字符串的结果拆分为 9741 NE 和 Groningen。
但我得到的是 9741 和 NE Groningen。
我已经尝试了各种方法来匹配空白,我认为这是问题所在。我试过了:
[[:blank:]][:blank:][[:space:]][:space:]\s方法[:space:] 应该匹配所有空格,但结果还是一样。
我尝试的任何方法似乎都不起作用,您能否为我指明正确的方向?
谢谢!
最佳答案
如果使用 this library,您可以启用 PCRE
^([0-9]{4}(?:[[:blank:]]+[a-z]{2}(?=[[:blank:]]))?)[[:blank:]](.*$)
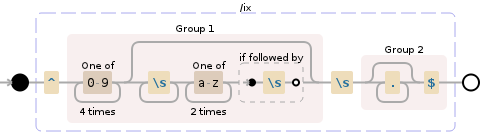
此正则表达式将执行以下操作:
现场演示
https://regex101.com/r/sE3xN7/4
示例文本
请注意,您的示例只有 4 位代码,所以我冒昧地添加了一个额外的数字
1111 AA CITYNAME1
2222 CITYNAME2
3333 Las Vegas
4444 BB Las Vegas
9741 NE Groningen
样本匹配
MATCH 1
1. [0-7] `1111 AA`
2. [8-17] `CITYNAME1`
MATCH 2
1. [18-22] `2222`
2. [23-32] `CITYNAME2`
MATCH 3
1. [33-37] `3333`
2. [38-47] `Las Vegas`
MATCH 4
1. [48-55] `4444 BB`
2. [56-65] `Las Vegas`
MATCH 5
1. [66-73] `9741 NE`
2. [74-83] `Groningen`
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[0-9]{4} any character of: '0' to '9' (4 times)
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
[[:blank:]]+ whitespace (\n, \r, \t, \f, and " ")
(1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
[a-z]{2} any character of: 'a' to 'z' (2 times)
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
[[:blank:]] whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
[[:blank:]] whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
( group and capture to \2:
----------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
----------------------------------------------------------------------
$ before an optional \n, and the end of a
"line"
----------------------------------------------------------------------
) end of \2
----------------------------------------------------------------------
关于正则表达式中的MySQL匹配空格,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/37602211/
26
4
 0
0
我正在用 yacc/bison 编写一个简单的计算器。 表达式的语法看起来有点像这样: expr : NUM | expr '+' expr { $$ = $1 + $3; } | expr '-'
我开始学习 lambda 表达式,并在以下情况下遇到了以下语句: interface MyNumber { double getValue(); } MyNumber number; nu
这两个 Linq 查询有什么区别: var result = ResultLists().Where( c=> c.code == "abc").FirstOrDefault(); // vs. va
如果我们查看 draft C++ standard 5.1.2 Lambda 表达式 段 2 说(强调我的 future ): The evaluation of a lambda-expressio
我使用的是 Mule 4.2.2 运行时、studio 7.5.1 和 Oracle JDK 1.8.0_251。 我在 java 代码中使用 Lambda 表达式,该表达式由 java Invoke
我是 XPath 的新手。我有网页的html源 http://london.craigslist.co.uk/com/1233708939.html 现在我想从上面的页面中提取以下数据 完整日期 电子
已关闭。这个问题是 off-topic 。目前不接受答案。 想要改进这个问题吗? Update the question所以它是on-topic用于堆栈溢出。 已关闭10 年前。 Improve th
我将如何编写一个 Cron 表达式以在每天上午 8 点和下午 3:30 触发?我了解如何创建每天触发一次的表达式,而不是在多个设定时间触发。提前致谢 最佳答案 你应该只使用两行。 0 8 * * *
这个问题已经有答案了: What do 3 dots next to a parameter type mean in Java? (9 个回答) varargs and the '...' argu
我是 python 新手,在阅读 BeautifulSoup 教程时,我不明白这个表达式“[x for x in titles if x.findChildren()][:-1]”我不明白?你能解释一
(?:) 这是一个有效的 ruby 正则表达式,谁能告诉我它是什么意思? 谢谢 最佳答案 正如其他人所说,它被用作正则表达式的非捕获语法,但是,它也是正则表达式之外的有效 ruby 语法。 在
这个问题在这里已经有了答案: Why does ++[[]][+[]]+[+[]] return the string "10"? (10 个答案) 关闭 8 年前。 谁能帮我处理这个 JavaSc
这个问题在这里已经有了答案: What is the "-->" operator in C++? (29 个答案) Java: Prefix/postfix of increment/decrem
这个问题在这里已经有了答案: List comprehension vs. lambda + filter (16 个答案) 关闭 10 个月前。 我不确定我是否需要 lambda 或其他东西。但是,
C 中的 assert() 函数工作原理对我来说就像一片黑暗的森林。根据这里的答案https://stackoverflow.com/a/1571360 ,您可以使用以下构造将自定义消息输出到您的断言
在this页,John Barnes 写道: If the conditional expression is the argument of a type conversion then effec
我必须创建一个调度程序,它必须每周从第一天上午 9 点到第二天晚上 11 点 59 分运行 2 天(星期四和星期五)。为此,我需要提供一个 cron 表达式。 0-0 0-0 9-23 ? * THU
我正在尝试编写一个 Linq 表达式来检查派生类中的属性,但该列表由来自基类的成员组成。下面的示例代码。以“var list”开头的 Process 方法的第二行无法编译,但我不确定应该使用什么语法来
此 sed 表达式将输入字符串转换为两行输出字符串。两条输出行中的每一行都由输入的子串组成。第一行需要转换成大写: s:random_stuff\(choice1\|choice2\){\([^}]*
我正在使用 Quartz.Net 在我的应用程序中安排我的工作。我只是想知道是否可以为以下场景构建 CRON 表达式: Every second between 2:15AM and 5:20AM 最

我是一名优秀的程序员,十分优秀!