
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- html - 出于某种原因,IE8 对我的 Sass 文件中继承的 html5 CSS 不友好?
- JMeter 在响应断言中使用 span 标签的问题
- html - 在 :hover and :active? 上具有不同效果的 CSS 动画
- html - 相对于居中的 html 内容固定的 CSS 重复背景?



 25
25
 4
4


我试图找到所有看起来像 abc_rty 或 abc_45 或 abc09_23k 或 abc09-K34 或 4535。标记不应以 _ 或 - 或数字开头。
我没有取得任何进步,甚至失去了我取得的进步。这就是我现在拥有的:
r'(?<!0-9)[(a-zA-Z)+]_(?=a-zA-Z0-9)|(?<!0-9)[(a-zA-Z)+]-(?=a-zA-Z0-9)\w+'
为了使问题更清楚这里是一个例子:如果我有一个字符串如下:
D923-44 43 uou 08*) %%5 89ANB -iopu9 _M89 _97N hi_hello
然后它将接受
D923-44 and 43 and uou and hi_hello
应该忽略
08*) %%5 89ANB -iopu9 _M89 _97N
我可能遗漏了一些案例,但我认为文字就足够了。如果不是,请道歉
最佳答案
^(\d+|[A-Za-z][\w_-]*)$
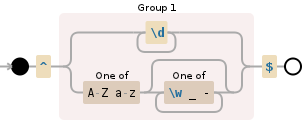
用空格分隔符分隔行,然后通过该行运行此 REGEX 以进行过滤。
^ 是行的开始\d 表示数字[0-9]+表示一个或多个| 表示或[A-Za-z]第一个字符必须是字母[\w_-]* 后面可以有任何字母数字 _ + 字符,也可以什么都没有。 $表示行尾REGEX 的流程显示在我提供的图表中,这在一定程度上解释了它是如何发生的。
但是,我无法解释,基本上它会检查它是否全是数字,或者它是否以字母(大写/小写)开头,然后在该字母之后检查任何字母数字 _ + 字符,直到行尾。
关于用于提取标记的 Python 正则表达式,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/18750680/
25
4
 0
0
我有一个加号/减号按钮,希望用户不能选择超过 20 个但不知道如何让它工作。我尝试使用 min="1"max="5 属性,但它们不起作用。这是我的代码和一个 fiddle 链接。https://jsf
我正在尝试复制顶部底部图,如示例 here但它没有正确渲染(紫色系列有 +ve 和 -ve 值,绿色为负值)留下杂乱的人工制品。我也在努力创建一个玩具示例来复制这个问题,所以我希望尽管我缺乏数据,但有
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 这个问题似乎与 help center 中定义的范围内的编程无关。 . 已关闭 6 年前。 社区去年审查了是
这个问题在这里已经有了答案: Adding two positive integers gives negative answer.Why? (4 个答案) 关闭 5 年前。 我遇到了一个奇怪的问题
有谁知道如何将字符串值类型 -4,5 或 5,4 转换为 double -4.5 或 5.4? 最佳答案 只需使用 Double.parseDouble(Locale, String); 糟糕,我很困
我正在尝试根据 TextBlob 分类插入一个仅包含“正”或“负”字符串的新数据框列:对于我的 df 的第一行,结果是 ( pos , 0.75, 0.2499999999999997)我想要' 正
我对 VBA 非常陌生,无法理解如何在一个循环中完成 2 个任务。我非常感谢您的帮助。 我已经能够根据第 3 列中的数据更改第 2 列中的数值,但我不明白如何将负值的字体更改为红色。 表格的大小每月都
欢迎, 我正在使用 jquery 通过 POST 发送表单。 这就是我获得值(value)的方式。 var mytext = $("#textareaid").val(); var dataStrin
double d = 0; // random decimal value with it's integral part within the range of Int32 and always p
我有这个字符串: var a='abc123#xyz123'; 我想构建 2 个正则表达式替换函数: 1) 用 '*' 替换所有确实有 future '#'的字符(不包括'#') 所以结果应该是这样的
我正在使用 DialogFragment。当用户从 Gmail 平板电脑应用程序的屏幕与下面示例图片中的编辑文本进行交互时,我希望正面和负面按钮保持在键盘上方。 在我的尝试中不起作用,这是我的 Dia
从组装艺术一书中,我复制了这句话: In the two’s complement system, the H.O. bit of a number is a sign bit. If the H.O
是否有更好更优雅的方法来实现下面的简单代码(diffYear、A 和 B 是数字): diffYear = yearA - yearB; if (diffYear == 0) { A = B
我正在设计一种语言,并尝试确定 true 应该是 0x01 还是 0xFF。显然,所有非零值都将转换为 true,但我正在尝试确定确切的内部表示。 每种选择的优点和缺点是什么? 最佳答案 没关系,只要
在我的 dialogfragment 类的 OnCreateDialog 中,我正在这样做: AlertDialog.Builder builder = new AlertDialog.Builder
这个问题在这里已经有了答案: Resolving ambiguous overload on function pointer and std::function for a lambda usin
我偶然发现了一个奇怪的 NSDecimalNumber 行为:对于某些值,调用 integerValue、longValue、longLongValue 等,返回意想不到的值(value)。示例: l
这个问题在这里已经有了答案: Resolving ambiguous overload on function pointer and std::function for a lambda using
我有这个正则表达式来测试用户输入是否有效: value.length === 0 || value === '-' || (!isNaN(parseFloat(value)) && /^-?\d+\.
我想用高斯混合模型拟合数据集,数据集包含大约 120k 个样本,每个样本有大约 130 个维度。当我使用 matlab 执行此操作时,我运行脚本(簇号为 1000): gm = fitgmdist(d

我是一名优秀的程序员,十分优秀!