
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- android - 多次调用 OnPrimaryClipChangedListener
- android - 无法更新 RecyclerView 中的 TextView 字段
- android.database.CursorIndexOutOfBoundsException : Index 0 requested, 光标大小为 0
- android - 使用 AppCompat 时,我们是否需要明确指定其 UI 组件(Spinner、EditText)颜色



 25
25
 4
4


好的,我很感激这需要一点耐心,但请耐心等待。我正在分析一些拉曼光谱,并编写了一个程序的基础,以使用 Scipy curve_fit 将多个洛伦兹人拟合到我数据的峰值。诀窍是我有太多数据,我希望程序自动识别洛伦兹人的初始猜测,而不是手动执行。总的来说,该程序运行良好(并且可能对具有类似用例和更简单数据的其他人有用),但我对 Scipy 的了解还不足以优化 curve_fit 以使其在许多不同的情况下工作例子。
此处的代码库:https://github.com/btjones-me/raman_spectroscopy
它运行良好的示例如图 1 所示。
部分问题在于我的寻峰算法,该算法有时难以为每个洛伦兹函数找到合适的起始位置。您可以在图 2 中看到这一点。
下一个问题是,出于某种原因,curve_fit 偶尔会出现灾难性的分歧(我最好的猜测是由于舍入误差)。您可以在图 3 中看到此行为。
最后,虽然我通常会很好地猜测每个洛伦兹的高度和 x 位置,但我还没有找到预测宽度或曲线 FWHM 的好方法。预测这一点可能有助于 curve_fit。
如果有人能以任何方式帮助解决这些问题中的任何一个,我将不胜感激。我愿意接受任何其他方法或建议,包括其他第三方库,只要它们改进了当前的实现即可。非常感谢任何尝试这个的人!
这里它完全按照我的意图工作: 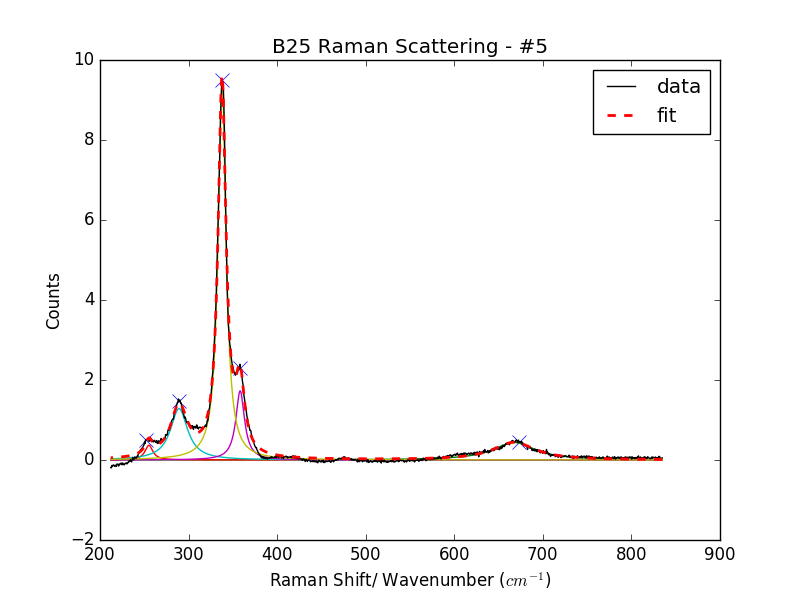
您可以在下面看到寻峰方法无法识别所有峰。有很多寻峰算法,但我使用的是 Scipy 的“find_peaks_cwt()”(通常不会这么糟糕,这是一种极端情况)。 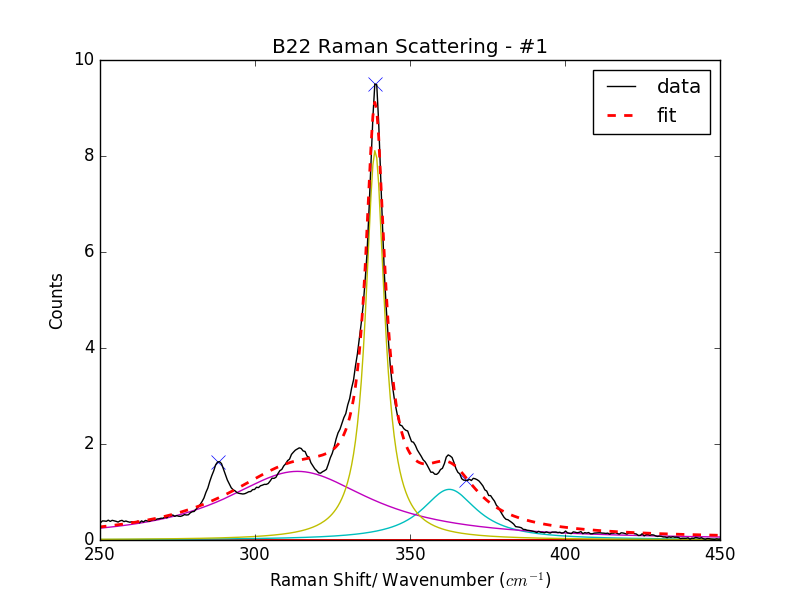
在这里它完全偏离了。这种情况经常发生,我真的不明白为什么,也不能阻止它发生。当我告诉它找到比光谱中可用的更多/更少的峰值时,它可能会发生,但这只是一个猜测。 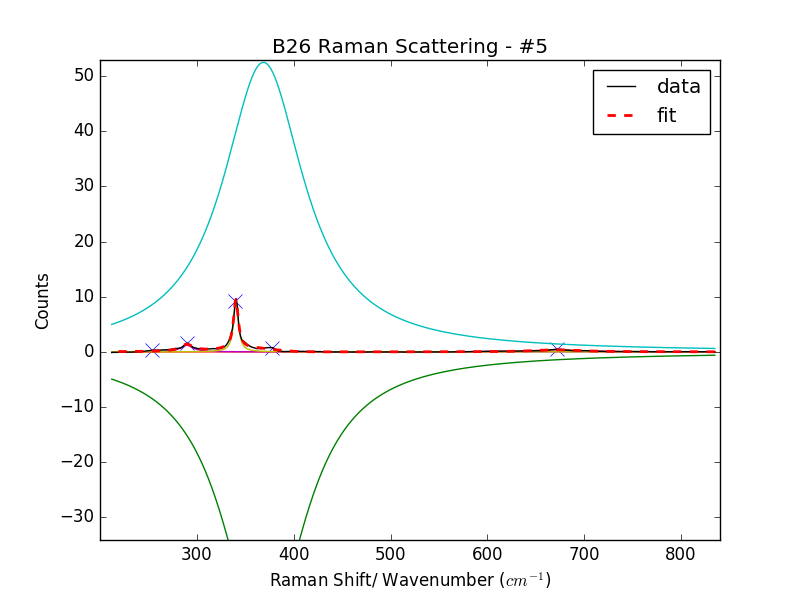
我已在 Python 3.5.2 中完成此操作。 PS 我知道我不会因代码布局而赢得任何奖牌,但一如既往地欢迎对代码风格和更好的做法发表评论。
最佳答案
我偶然发现了这个,因为我试图解决完全相同的问题,这是我的解决方案。对于每个峰,我只将我的洛伦兹分布在域 + 或 - 到下一个最近峰的距离的 1/2 处。这是我分解域的函数:
def get_local_indices(peak_indices):
#returns the array indices of the points closest to each peak (distance to next peak/2)
chunks = []
for i in range(len(peak_indices)):
peak_index = peak_indices[i]
if i>0 and i<len(peak_indices)-1:
distance = min(abs(peak_index-peak_indices[i+1]),abs(peak_indices[i-1]-peak_index))
elif i==0:
distance = abs(peak_index-peak_indices[i+1])
else:
distance = abs(peak_indices[i-1]-peak_index)
min_index = peak_index-int(distance/2)
max_index = peak_index+int(distance/2)
indices = np.arange(min_index,max_index)
chunks.append(indices)
return chunks
这是结果图的图片,虚线表示洛伦兹分布适合的区域: Lorentzian Fitting Plot
关于python - 在 Python3 中使用 scipy 将多个 Lorentzians 拟合到数据,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41687849/
25
4
 0
0
我在使用 cx_freeze 和 scipy 时无法编译 exe。特别是,我的脚本使用 from scipy.interpolate import griddata 构建过程似乎成功完成,但是当我尝试
是否可以通过函数在 scipy 中定义一个稀疏矩阵,而不是列出所有可能的值?在文档中,我看到可以通过以下方式创建稀疏矩阵 There are seven available sparse matrix
SciPy为非线性最小二乘问题提供了两种功能: optimize.leastsq()仅使用Levenberg-Marquardt算法。 optimize.least_squares()允许我们选择Le
SciPy 中的求解器能否处理复数值(即 x=x'+i*x")?我对使用 Nelder-Mead 类型的最小化函数特别感兴趣。我通常是 Matlab 用户,我知道 Matlab 没有复杂的求解器。如果
我有看起来像这样的数据集: position number_of_tag_at_this_position 3 4 8 6 13 25 23 12 我想对这个数据集应用三次样条插值来插值标签密度;为此
所以,我正在处理维基百科转储,以计算大约 5,700,000 个页面的页面排名。这些文件经过预处理,因此不是 XML 格式。 它们取自 http://haselgrove.id.au/wikipedi
Scipy 和 Numpy 返回归一化的特征向量。我正在尝试将这些向量用于物理应用程序,我需要它们不被标准化。 例如a = np.matrix('-3, 2; -1, 0') W,V = spl.ei
基于此处提供的解释 1 ,我正在尝试使用相同的想法来加速以下积分: import scipy.integrate as si from scipy.optimize import root, fsol
这很容易重新创建。 如果我的脚本 foo.py 是: import scipy 然后运行: python pyinstaller.py --onefile foo.py 当我启动 foo.exe 时,
我想在我的代码中使用 scipy.spatial.distance.cosine。如果我执行类似 import scipy.spatial 或 from scipy import spatial 的操
Numpy 有一个基本的 pxd,声明它的 c 接口(interface)到 cython。是否有用于 scipy 组件(尤其是 scipy.integrate.quadpack)的 pxd? 或者,
有人可以帮我处理 scipy.stats.chisquare 吗?我没有统计/数学背景,我正在使用来自 https://en.wikipedia.org/wiki/Chi-squared_test 的
我正在使用 scipy.odr 拟合数据与权重,但我不知道如何获得拟合优度或 R 平方的度量。有没有人对如何使用函数存储的输出获得此度量有建议? 最佳答案 res_var Output 的属性是所谓的
我刚刚下载了新的 python 3.8,我正在尝试使用以下方法安装 scipy 包: pip3.8 install scipy 但是构建失败并出现以下错误: **Failed to build sci
我有 my own triangulation algorithm它基于 Delaunay 条件和梯度创建三角剖分,使三角形与梯度对齐。 这是一个示例输出: 以上描述与问题无关,但对于上下文是必要的。
这是一个非常基本的问题,但我似乎找不到好的答案。 scipy 到底计算什么内容 scipy.stats.norm(50,10).pdf(45) 据我了解,平均值为 50、标准差为 10 的高斯中像 4
我正在使用 curve_fit 来拟合一阶动态系统的阶跃响应,以估计增益和时间常数。我使用两种方法。第一种方法是在时域中拟合从函数生成的曲线。 # define the first order dyn
让我们假设 x ~ Poisson(2.5);我想计算类似 E(x | x > 2) 的东西。 我认为这可以通过 .dist.expect 运算符来完成,即: D = stats.poisson(2.
我正在通过 OpenMDAO 使用 SLSQP 来解决优化问题。优化工作充分;最后的 SLSQP 输出如下: Optimization terminated successfully. (Exi
log( VA ) = gamma - (1/eta)log[alpha L ^(-eta) + 测试版 K ^(-eta)] 我试图用非线性最小二乘法估计上述函数。我为此使用了 3 个不同的包(Sc

我是一名优秀的程序员,十分优秀!