
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java 双重比较
- java - 比较器与 Apache BeanComparator
- Objective-C 完成 block 导致额外的方法调用?
- database - RESTful URI 是否应该公开数据库主键?



 24
24
 4
4


我正在尝试使用我目前正在处理的正则表达式从 html 字符串中获取:
extension String {
func regex (pattern: String) -> [String] {
do {
let regex = try NSRegularExpression(pattern: pattern, options: NSRegularExpressionOptions(rawValue: 0))
let nsstr = self as NSString
let all = NSRange(location: 0, length: nsstr.length)
var matches : [String] = [String]()
regex.enumerateMatchesInString(self, options: NSMatchingOptions(rawValue: 0), range: all) {
(result : NSTextCheckingResult?, _, _) in
if let r = result {
let result = nsstr.substringWithRange(r.range) as String
matches.append(result)
}
}
return matches
} catch {
return [String]()
}
}
模式是:<img[^>]+src\\s*=\\s*['\']([^'\"]+)['\"][^>]*>
我仍然无法从中获取图像 url,这意味着它返回空数组。实际上我的 html 字符串包含一个图像。我不想使用 UIWebView因为UITableView调整大小问题。所以,我需要从 html 中获取图像 url,并使用 AlamofireImage 在 UIImageView 中显示它。
有什么帮助吗?这只是我需要获取的一个 url。
这是我的标签:
<img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
收件人:
https://en.wikipedia.org/wiki/File:BH_LMC.png
最佳答案
<img\b(?=\s)(?=(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*?\ssrc=['"]([^"]*)['"]?)(?:[^>=]|='[^']*'|="[^"]*"|=[^'"\s]*)*"\s?\/?>
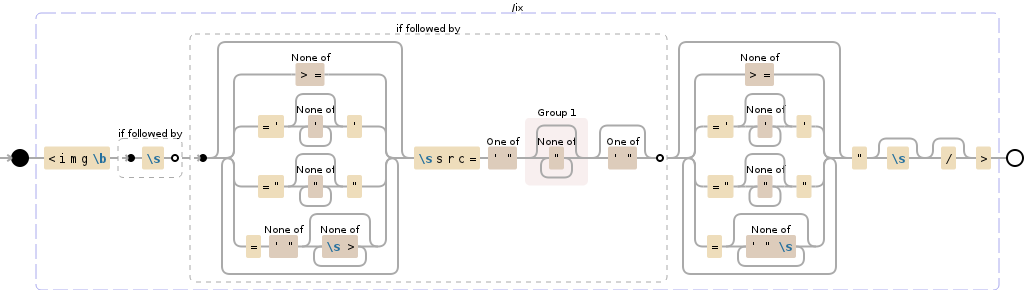
此正则表达式将执行以下操作:
现场演示
https://regex101.com/r/qW9nG8/1
示例文本
请注意我们正在寻找特定机器人的第一行中的困难边缘情况。
<img onmouseover=' if ( 6 > 3 { funSwap(" src="NotTheDroidYourLookingFor.jpg", 6 > 3 ) } ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
some text
<img src="http://website/someurl.jpeg" onload="img_onload(this);" />
more text
<img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
样本匹配
[0][0] = <img onmouseover=' funSwap(" src='NotTheDroidYourLookingFor.jpg", data-pid) ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
[0][1] = http://website/ThisIsTheDroidYourLookingFor.jpeg
[1][0] = <img src="http://website/someurl.jpeg" onload="img_onload(this);" />
[1][1] = http://website/someurl.jpeg
[2][0] = <img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
[2][1] = https://en.wikipedia.org/wiki/File:BH_LMC.png
NODE EXPLANATION
----------------------------------------------------------------------
<img '<img'
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the least amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)*? end of grouping
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
src= 'src='
----------------------------------------------------------------------
['"] any character of: ''', '"'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
['"]? any character of: ''', '"' (optional
(matching the most amount possible))
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"\s]* any character except: ''', '"',
whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\/? '/' (optional (matching the most amount
possible))
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
关于html - 如何使用正则表达式从 html 字符串中获取图像 url,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/37645945/
24
4
 0
0
我正在尝试学习 Knockout 并尝试创建一个照片 uploader 。我已成功将一些图像存储在数组中。现在我想回帖。在我的 knockout 码(Javascript)中,我这样做: 我在 Jav
我正在使用 php 编写脚本。我的典型问题是如何在 mysql 中添加一个有很多替代文本和图像的问题。想象一下有机化学中具有苯结构的描述。 最有效的方法是什么?据我所知,如果我有一个图像,我可以在数据
我在两个图像之间有一个按钮,我想将按钮居中到图像高度。有人可以帮帮我吗? Entrar
下面的代码示例可以在这里查看 - http://dev.touch-akl.com/celebtrations/ 我一直在尝试做的是在 Canvas 上绘制 2 个图像(发光,然后耀斑。这些图像的链接
请检查此https://jsfiddle.net/rhbwpn19/4/ 图像预览对于第一篇帖子工作正常,但对于其他帖子则不然。 我应该在这里改变什么? function readURL(input)
我对 Canvas 有疑问。我可以用单个图像绘制 Canvas ,但我不能用单独的图像绘制每个 Canvas 。- 如果数据只有一个图像,它工作正常,但数据有多个图像,它不工作你能帮帮我吗? va
我的问题很简单。如何获取 UIImage 的扩展类型?我只能将图像作为 UIImage 而不是它的名称。图像可以是静态的,也可以从手机图库甚至文件路径中获取。如果有人可以为此提供一点帮助,将不胜感激。
我有一个包含 67 个独立路径的 SVG 图像。 是否有任何库/教程可以为每个路径创建单独的光栅图像(例如 PNG),并可能根据路径 ID 命名它们? 最佳答案 谢谢大家。我最终使用了两个答案的组合。
我想将鼠标悬停在一张图片(音乐专辑)上,然后播放一张唱片,所以我希望它向右移动并旋转一点,当它悬停时我希望它恢复正常动画片。它已经可以向右移动,但我无法让它随之旋转。我喜欢让它尽可能简单,因为我不是编
Retina iOS 设备不显示@2X 图像,它显示 1X 图像。 我正在使用 Xcode 4.2.1 Build 4D502,该应用程序的目标是 iOS 5。 我创建了一个测试应用(主/细节)并添加
我正在尝试从头开始以 Angular 实现图像 slider ,并尝试复制 w3school基于图像 slider 。 下面我尝试用 Angular 实现,谁能指导我如何使用 Angular 实现?
我正在尝试获取图像的图像数据,其中 w= 图像宽度,h = 图像高度 for (int i = x; i imageData[pos]>0) //Taking data (here is the pr
我的网页最初通过在 javascript 中动态创建图像填充了大约 1000 个缩略图。由于权限问题,我迁移到 suPHP。现在不用标准 标签本身 我正在通过这个 php 脚本进行检索 $file
我正在尝试将 python opencv 图像转换为 QPixmap。 我按照指示显示Page Link我的代码附在下面 img = cv2.imread('test.png')[:,:,::1]/2
我试图在这个 Repository 中找出语义分割数据集的 NYU-v2 . 我很难理解图像标签是如何存储的。 例如,给定以下图像: 对应的标签图片为: 现在,如果我在 OpenCV 中打开标签图像,
import java.util.Random; class svg{ public static void main(String[] args){ String f="\"
我有一张 8x8 的图片。 (位图 - 可以更改) 我想做的是能够绘制一个形状,给定一个 Path 和 Paint 对象到我的 SurfaceView 上。 目前我所能做的就是用纯色填充形状。我怎样才
要在页面上显示图像,你需要使用源属性(src)。src 指 source 。源属性的值是图像的 URL 地址。 定义图像的语法是: 在浏览器无法载入图像时,替换文本属性告诉读者她们失去的信息。此
**MMEditing是基于PyTorch的图像&视频编辑开源工具箱,支持图像和视频超分辨率(super-resolution)、图像修复(inpainting)、图像抠图(matting)、
我正在尝试通过资源文件将图像插入到我的程序中,如下所示: green.png other files 当我尝试使用 QImage 或 QPixm

我是一名优秀的程序员,十分优秀!