
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- c - 在位数组中找到第一个零
- linux - Unix 显示有关匹配两种模式之一的文件的信息
- 正则表达式替换多个文件
- linux - 隐藏来自 xtrace 的命令



 39
39
 4
4


SciPy 和 Numpy 都内置了奇异值分解 (SVD) 函数。命令基本上是 scipy.linalg.svd 和 numpy.linalg.svd。这两者有什么区别?它们中的任何一个都比另一个更好吗?
最佳答案
来自FAQ page ,它说 scipy.linalg 子模块为 Fortran LAPACK 库提供了一个更完整的包装器,而 numpy.linalg 试图能够独立于 LAPACK 进行构建。
我做了一些 benchmarks对于 svd 函数的不同实现,发现 scipy.linalg.svd 比对应的 numpy 更快:
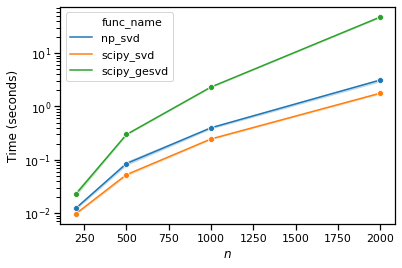
然而,jax包裹的 numpy,又名 jax.numpy.linalg.svd 甚至更快:
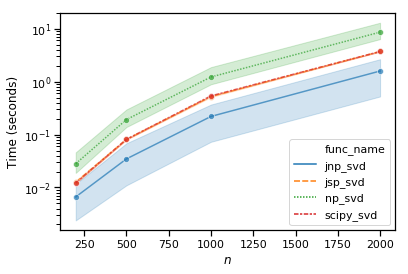
基准测试的完整笔记本可用here .
关于python - SciPy SVD 与 Numpy SVD,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/32569188/
39
4
 0
0
作为脚本的输出,我有 numpy masked array和标准numpy array .如何在运行脚本时轻松检查数组是否为掩码(具有 data 、 mask 属性)? 最佳答案 您可以通过 isin
我的问题 假设我有 a = np.array([ np.array([1,2]), np.array([3,4]), np.array([5,6]), np.array([7,8]), np.arra
numpy 是否有用于矩阵模幂运算的内置实现? (正如 user2357112 所指出的,我实际上是在寻找元素明智的模块化减少) 对常规数字进行模幂运算的一种方法是使用平方求幂 (https://en
我已经在 Numpy 中实现了这个梯度下降: def gradientDescent(X, y, theta, alpha, iterations): m = len(y) for i
我有一个使用 Numpy 在 CentOS7 上运行的项目。 问题是安装此依赖项需要花费大量时间。 因此,我尝试 yum install pip install 之前的 numpy 库它。 所以我跑:
处理我想要旋转的数据。请注意,我仅限于 numpy,无法使用 pandas。原始数据如下所示: data = [ [ 1, a, [, ] ], [ 1, b, [, ] ], [ 2,
numpy.random.seed(7) 在不同的机器学习和数据分析教程中,我看到这个种子集有不同的数字。选择特定的种子编号真的有区别吗?或者任何数字都可以吗?选择种子数的目标是相同实验的可重复性。
我需要读取存储在内存映射文件中的巨大 numpy 数组的部分内容,处理数据并对数组的另一部分重复。整个 numpy 数组占用大约 50 GB,我的机器有 8 GB RAM。 我最初使用 numpy.m
处理我想要旋转的数据。请注意,我仅限于 numpy,无法使用 pandas。原始数据如下所示: data = [ [ 1, a, [, ] ], [ 1, b, [, ] ], [ 2,
似乎 numpy.empty() 可以做的任何事情都可以使用 numpy.ndarray() 轻松完成,例如: >>> np.empty(shape=(2, 2), dtype=np.dtype('d
我在大型 numpy 数组中有许多不同的形式,我想使用 numpy 和 scipy 计算它们之间的边到边欧氏距离。 注意:我进行了搜索,这与堆栈中之前的其他问题不同,因为我想获得数组中标记 block
我有一个大小为 (2x3) 的 numpy 对象数组。我们称之为M1。在M1中有6个numpy数组。M1 给定行中的数组形状相同,但与 M1 任何其他行中的数组形状不同。 也就是说, M1 = [ [
如何使用爱因斯坦表示法编写以下点积? import numpy as np LHS = np.ones((5,20,2)) RHS = np.ones((20,2)) np.sum([ np.
假设我有 np.array of a = [0, 1, 1, 0, 0, 1] 和 b = [1, 1, 0, 0, 0, 1] 我想要一个新矩阵 c 使得如果 a[i] = 0 和 b[i] = 0
我有一个形状为 (32,5) 的 numpy 数组 batch。批处理的每个元素都包含一个 numpy 数组 batch_elem = [s,_,_,_,_] 其中 s = [img,val1,val
尝试为基于文本的多标签分类问题训练单层神经网络。 model= Sequential() model.add(Dense(20, input_dim=400, kernel_initializer='
首先是一个简单的例子 import numpy as np a = np.ones((2,2)) b = 2*np.ones((2,2)) c = 3*np.ones((2,2)) d = 4*np.
我正在尝试平均二维 numpy 数组。所以,我使用了 numpy.mean 但结果是空数组。 import numpy as np ws1 = np.array(ws1) ws1_I8 = np.ar
import numpy as np x = np.array([[1,2 ,3], [9,8,7]]) y = np.array([[2,1 ,0], [1,0,2]]) x[y] 预期输出: ar
我有两个数组 A (4000,4000),其中只有对角线填充了数据,而 B (4000,5) 填充了数据。有没有比 numpy.dot(a,b) 函数更快的方法来乘(点)这些数组? 到目前为止,我发现

我是一名优秀的程序员,十分优秀!