
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- c - 在位数组中找到第一个零
- linux - Unix 显示有关匹配两种模式之一的文件的信息
- 正则表达式替换多个文件
- linux - 隐藏来自 xtrace 的命令



 29
29
 4
4


在 Markdown 中有两种放置链接的方法,一种是直接输入原始链接,例如:<a href="http://example.com" rel="noreferrer noopener nofollow">http://example.com</a> , 另一个是使用 ()[]语法:(Stack Overflow)[<a href="http://example.com" rel="noreferrer noopener nofollow">http://example.com</a> ] .
我正在尝试编写一个可以匹配这两个的正则表达式,并且,如果它是第二个匹配项,则还捕获显示字符串。
到目前为止我有这个:
(?P<href>http://(?:www\.)?\S+.com)|(?<=\((.*)\)\[)((?P=href))(?=\])
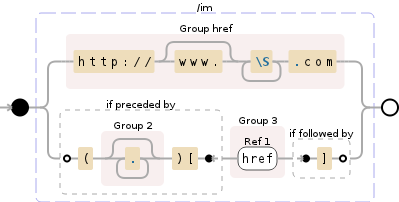
但这似乎与我在 Debuggex 中的两个测试用例都不匹配:
http://example.com
(Example)[http://example.com]
真的不确定为什么第一个至少不匹配,这与我使用命名组有关吗?如果可能的话,我想继续使用它,因为这是一个匹配链接的简化表达式,在实际示例中,它太长了,我无法以相同的模式在两个不同的地方复制它。
我做错了什么?或者这根本不可行?
编辑:我在 Python 中执行此操作,因此将使用他们的正则表达式引擎。
最佳答案
您的模式不起作用的原因在这里:(?<=\((.*)\)\[)因为 Python 的 re 模块不允许可变长度后视。
您可以使用 the new regex module of Python 以更方便的方式获得您想要的东西(因为相比之下 re 模块的功能很少)。
示例:(?|(?<txt>(?<url>(?:ht|f)tps?://\S+(?<=\P{P})))|\(([^)]+)\)\[(\g<url>)\])
图案细节:
(?| # open a branch reset group
# first case there is only the url
(?<txt> # in this case, the text and the url
(?<url> # are the same
(?:ht|f)tps?://\S+(?<=\P{P})
)
)
| # OR
# the (text)[url] format
\( ([^)]+) \) # this group will be named "txt" too
\[ (\g<url>) \] # this one "url"
)
此模式使用分支重置功能 (?|...|...|...)这允许在交替中保留捕获组名称(或数字)。在模式中,由于 ?<txt>分组首先在交替的第一个成员中打开,第二个成员中的第一个组将自动具有相同的名称。 ?<url> 相同组。
\g<url>是对命名子模式的引用 ?<url> (就像一个别名,这样,就不需要在第二个成员中重写了。)
(?<=\P{P})检查 url 的最后一个字符是否不是标点符号(例如有助于避免结束方括号)。 (我不确定语法,可能是 \P{Punct} )
关于python - 如何使用正则表达式查找所有 Markdown 链接?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/25109307/
29
4
 0
0
我有一个加号/减号按钮,希望用户不能选择超过 20 个但不知道如何让它工作。我尝试使用 min="1"max="5 属性,但它们不起作用。这是我的代码和一个 fiddle 链接。https://jsf
我正在尝试复制顶部底部图,如示例 here但它没有正确渲染(紫色系列有 +ve 和 -ve 值,绿色为负值)留下杂乱的人工制品。我也在努力创建一个玩具示例来复制这个问题,所以我希望尽管我缺乏数据,但有
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 这个问题似乎与 help center 中定义的范围内的编程无关。 . 已关闭 6 年前。 社区去年审查了是
这个问题在这里已经有了答案: Adding two positive integers gives negative answer.Why? (4 个答案) 关闭 5 年前。 我遇到了一个奇怪的问题
有谁知道如何将字符串值类型 -4,5 或 5,4 转换为 double -4.5 或 5.4? 最佳答案 只需使用 Double.parseDouble(Locale, String); 糟糕,我很困
我正在尝试根据 TextBlob 分类插入一个仅包含“正”或“负”字符串的新数据框列:对于我的 df 的第一行,结果是 ( pos , 0.75, 0.2499999999999997)我想要' 正
我对 VBA 非常陌生,无法理解如何在一个循环中完成 2 个任务。我非常感谢您的帮助。 我已经能够根据第 3 列中的数据更改第 2 列中的数值,但我不明白如何将负值的字体更改为红色。 表格的大小每月都
欢迎, 我正在使用 jquery 通过 POST 发送表单。 这就是我获得值(value)的方式。 var mytext = $("#textareaid").val(); var dataStrin
double d = 0; // random decimal value with it's integral part within the range of Int32 and always p
我有这个字符串: var a='abc123#xyz123'; 我想构建 2 个正则表达式替换函数: 1) 用 '*' 替换所有确实有 future '#'的字符(不包括'#') 所以结果应该是这样的
我正在使用 DialogFragment。当用户从 Gmail 平板电脑应用程序的屏幕与下面示例图片中的编辑文本进行交互时,我希望正面和负面按钮保持在键盘上方。 在我的尝试中不起作用,这是我的 Dia
从组装艺术一书中,我复制了这句话: In the two’s complement system, the H.O. bit of a number is a sign bit. If the H.O
是否有更好更优雅的方法来实现下面的简单代码(diffYear、A 和 B 是数字): diffYear = yearA - yearB; if (diffYear == 0) { A = B
我正在设计一种语言,并尝试确定 true 应该是 0x01 还是 0xFF。显然,所有非零值都将转换为 true,但我正在尝试确定确切的内部表示。 每种选择的优点和缺点是什么? 最佳答案 没关系,只要
在我的 dialogfragment 类的 OnCreateDialog 中,我正在这样做: AlertDialog.Builder builder = new AlertDialog.Builder
这个问题在这里已经有了答案: Resolving ambiguous overload on function pointer and std::function for a lambda usin
我偶然发现了一个奇怪的 NSDecimalNumber 行为:对于某些值,调用 integerValue、longValue、longLongValue 等,返回意想不到的值(value)。示例: l
这个问题在这里已经有了答案: Resolving ambiguous overload on function pointer and std::function for a lambda using
我有这个正则表达式来测试用户输入是否有效: value.length === 0 || value === '-' || (!isNaN(parseFloat(value)) && /^-?\d+\.
我想用高斯混合模型拟合数据集,数据集包含大约 120k 个样本,每个样本有大约 130 个维度。当我使用 matlab 执行此操作时,我运行脚本(簇号为 1000): gm = fitgmdist(d

我是一名优秀的程序员,十分优秀!