
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- c - 在位数组中找到第一个零
- linux - Unix 显示有关匹配两种模式之一的文件的信息
- 正则表达式替换多个文件
- linux - 隐藏来自 xtrace 的命令



 26
26
 4
4


我正在使用 GPU 版本的 keras 在预训练网络上应用迁移学习。我不明白如何定义参数 max_queue_size、workers 和 use_multiprocessing 。如果我更改这些参数(主要是为了加快学习速度),我不确定每个时期是否仍然可以看到所有数据。
max_queue_size:
用于“预缓存”来自生成器的样本的内部训练队列的最大大小
问题:这是指在 CPU 上准备了多少批处理?它与 workers 有什么关系?如何最佳定义?
worker :
并行生成批处理的线程数。批处理在 CPU 上并行计算,并即时传递到 GPU 以进行神经网络计算
问题:如何确定我的 CPU 可以/应该并行生成多少批处理?
use_multiprocessing:
是否使用基于进程的线程
问题:如果我更改 workers,是否必须将此参数设置为 true?跟CPU占用有关系吗?
相关问题可以在这里找到:
What is the parameter “max_q_size” used for in “model.fit_generator”?
A detailed example of how to use data generators with Keras .
我正在使用 fit_generator() 如下:
history = model.fit_generator(generator=trainGenerator,
steps_per_epoch=trainGenerator.samples//nBatches, # total number of steps (batches of samples)
epochs=nEpochs, # number of epochs to train the model
verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=callback, # keras.callbacks.Callback instances to apply during training
validation_data=valGenerator, # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch
validation_steps=
valGenerator.samples//nBatches, # number of steps (batches of samples) to yield from validation_data generator before stopping at the end of every epoch
class_weight=classWeights, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function
max_queue_size=10, # maximum size for the generator queue
workers=1, # maximum number of processes to spin up when using process-based threading
use_multiprocessing=False, # whether to use process-based threading
shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch
initial_epoch=0)
我的机器的规范是:
CPU : 2xXeon E5-2260 2.6 GHz
Cores: 10
Graphic card: Titan X, Maxwell, GM200
RAM: 128 GB
HDD: 4TB
SSD: 512 GB
最佳答案
Q_0:
Question: Does this refer to how many batches are prepared on CPU? How is it related to workers? How to define it optimally?
来自link你发布了,你可以了解到你的 CPU 一直在创建批处理,直到队列达到最大队列大小或到达停止点。您希望为您的 GPU 准备好批处理,以便 GPU 不必等待 CPU。队列大小的理想值是使其足够大,使您的 GPU 始终在最大值附近运行,而不必等待 CPU 准备新的批处理。
问题_1:
Question: How do I find out how many batches my CPU can/should generate in parallel?
如果您发现您的 GPU 处于空闲状态并等待批处理,请尝试增加 worker 数量,也可能增加队列大小。
问题_2:
Do I have to set this parameter to true if I change workers? Does it relate to CPU usage?
Here是对将其设置为 True 或 False 时发生的情况的实际分析。 Here建议将其设置为 False 以防止卡住(在我的设置中 True 可以正常工作而不会卡住)。也许其他人可以增加我们对该主题的理解。
尽量不要顺序设置,尽量让CPU给GPU提供足够的数据。 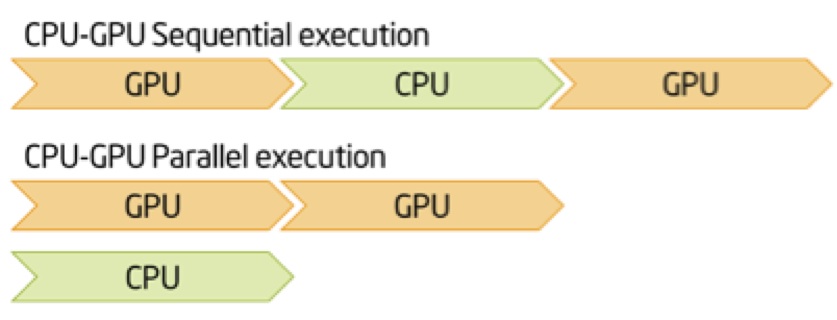
另外:下次您可以(应该?)提出几个问题,以便更容易回答它们。
关于python - 如何在 keras fit_generator() 中定义 max_queue_size、workers 和 use_multiprocessing?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55531427/
26
4
 0
0
我正在使用 GPU 版本的 keras 在预训练网络上应用迁移学习。我不明白如何定义参数 max_queue_size、workers 和 use_multiprocessing 。如果我更改这些参数
我对您如何使用 max_queue_size 感到困惑, workers和 use_multiprocessing在 Keras Documentation 有人可以举一个例子,如果你有的话,你会如何

我是一名优秀的程序员,十分优秀!