
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- c - 在位数组中找到第一个零
- linux - Unix 显示有关匹配两种模式之一的文件的信息
- 正则表达式替换多个文件
- linux - 隐藏来自 xtrace 的命令



 25
25
 4
4


对于我的一个类(class)项目,我开始使用 C 实现“朴素贝叶斯分类器”。我的项目是使用大量训练数据实现文档分类器应用程序(尤其是垃圾邮件)。
现在由于 C 的数据类型的限制,我在实现算法时遇到了问题。
(这里给出了我使用的算法,http://en.wikipedia.org/wiki/Bayesian_spam_filtering)
问题陈述:该算法涉及获取文档中的每个词并计算它是垃圾词的概率。如果 p1, p2 p3 .... pn 是单词 1, 2, 3 ... n 的概率。 doc 是垃圾邮件的概率是使用
计算的 
这里,概率值可以很容易地在 0.01 左右。因此,即使我使用数据类型“double”,我的计算也会被折腾。为了证实这一点,我编写了下面给出的示例代码。
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
我尝试了 Float、double 甚至 long double 数据类型,但仍然存在同样的问题。
因此,假设在我正在分析的 100K 字的文档中,如果只有 162 个词具有 1% 的垃圾邮件概率,而其余 99838 个明显是垃圾邮件词,那么我的应用程序仍然会因为精度错误而将其说成“非垃圾邮件文档”(如分子很容易变为零)!!!。
这是我第一次遇到这样的问题。那么究竟应该如何解决这个问题呢?
最佳答案
这在机器学习中经常发生。 AFAIK,对于精度损失您无能为力。因此,为了绕过这一点,我们使用 log 函数并将除法和乘法分别转换为减法和加法。
所以我决定算一下,
原方程为:

我稍微修改了一下:
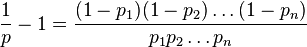
两边取日志:

让,

替换,

因此计算组合概率的替代公式:
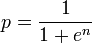
如果您需要我对此进行扩展,请发表评论。
关于c - C中的精密浮点运算问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/2691021/
25
4
 0
0
为什么 (defun boolimplies (a b) (or (not a) b)) if called as(boolimplies 'a 'b) 返回 B? 即使我不使用任何 boolean
这个问题已经有答案了: Are there builtin functions for elementwise boolean operators over boolean lists? (5 个回答
我正在寻求帮助以使以下功能看起来更清晰。我觉得我可以通过使用更少的代码行来实现同样的目标。 标题看起来一定很困惑,所以让我详细说明一下。我创建了一个函数,它接受用户输入(即 72+5),将字符串拆分为
我正在学习 C++ 并尝试为矩阵编写一个 C++ 类,我在其中将矩阵存储为一维 C 数组。为此,我定义了一个 element成员函数根据矩阵元素在数组中的位置访问矩阵元素。然后我重载了 class
我正在学习 C++ 并尝试为矩阵编写一个 C++ 类,我在其中将矩阵存储为一维 C 数组。为此,我定义了一个 element成员函数根据矩阵元素在数组中的位置访问矩阵元素。然后我重载了 class
伙计们,以下内容不起作用 函数返回 true,变量返回 false,但它不会进入 when 子句。我尝试像这样放大括号 但是当我将变量的值设置为 true 并将上面的代码更改为 它进入w
关闭。此题需要details or clarity 。目前不接受答案。 想要改进这个问题吗?通过 editing this post 添加详细信息并澄清问题. 已关闭 9 年前。 Improve th
我是原生 C 语言的新手,但我没有看到错误。 我尝试在这种情况下使用 if 操作: #define PAGE_A 0 #define PAGE_B 1 int pageID = 0; if (page
我正在从事一个项目,让用户鼠标滚轮移动并知道它向上或向下滚动。在我的代码中,我可以上下移动。但我想将 Action 保存到一个字符串中。例如,如果用户向上向上向下滚动'mhmh' 显示返回“UUD”但
我有一个 MySQL 表 payment我在其中存储客户的所有付款相关数据。表字段为:fileNo , clientName , billNo , billAmount , status 。我想构建一
我的表架构如下: +------+-------+-------+
我有这个(顺便说一句,我刚刚开始学习): #include #include using namespace std; int main() { string mystr; cout << "We
我正在用 bash 构建一个用于 Linux (SLES 11SP3) 的脚本。我想通过使用以下语法查找它的 pid 来检查某个进程是否存在: pid="$(ps -ef | grep -v grep
我有一个包含两列的表格; CREATE TABLE IF NOT EXISTS `QUESTION_CATEGORY_RELATION` ( `question_id` int(16) NOT N
我对 Python 如何计算 bool 语句感到困惑。 例如 False and 2 or 3 返回 3 这是如何评估的?我认为 Python 首先会查看“False and 2”,甚至不查看“or
这个问题在这里已经有了答案: 12 年前关闭。 这可能是非常基本的......但我似乎不明白: 如何 (2 & 1) = 0 (3 & 1) = 1 (4 & 1) = 0 等等.. 上面的这种模式似
无论如何在Haskell中定义如下函数? or True True = True or True undefined = True or True False
如您所知,TCL 有一些数学函数,例如 罪 , 因 , 和 假设 在 中调用的expr 带有 的命令() 大括号如下: puts [expr sin(1.57)] 现在如何使用 TCL 添加功能 li
让我们考虑两个数组列表。 ArrayList list1 = new ArrayList(); list1.add(1); list1.add(2); list1.add(3); ArrayList
我想包含和排除使用AND和OR的专业知识,包括与AND和OR操作正常工作。但是,当将排除专家与AND和OR一起使用时,返回与3相同的结果计数。我使用的是1.4版 Elasticsearch 。帮助我解

我是一名优秀的程序员,十分优秀!