
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 32
32
 4
4


在DBS-集群列表-更多-连接查询-死锁中,看到9月22日有数据库死锁日志,后排查发现是因为mysql的优化-index merge(索引合并)导致数据库死锁.
index merge(索引合并):该数据库查询优化的一种技术,在mysql 5.1之后进行引入,它可以在多个索引上进行查询,并将结果合并返回.
在排查问题之前,首先讲一下mysql数据库的锁机制:
1 加锁的基本单位是 next-key lock(记录锁+间隙锁),当记录锁或者间隙锁能够解决幻读的问题,就会退化为记录锁(行锁),间隙锁.
2 加锁是将锁加在了索引之上,而不是数据之上.
3 对于当前读,索引进行加锁,当前读语句包括了(select ... from. ... for update,select...from ..... lock in share mode,update...,delete....).
4 加锁根据唯一性索引、非唯一性索引进行了区分,根据查询条件分为了等值查询、范围查询,根据是否能够查到数据又分为了记录存在和不存在的情况.
本次死锁问题使用的索引是非唯一性索引的等值查询中记录存在的情况,因此本文仅仅详细介绍这种情况,其它情况可以查看最下面的参考文档1:
加锁情况是:会依次扫描,首先扫描到条件匹配的数据,加一个next-key lock,然后接下来扫描到第一个记录不匹配的数据,增加一个间隙锁,最后对查到记录的主键增加一个记录锁, 。
针对以上情况加了三种锁,加锁的目的是为了防止幻读的发生.
针对二级索引的锁进行分析:
表结构:
CREATE TABLE `jdi_roster_apply_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`apply_id` varchar(100) NOT NULL COMMENT '申请单号',
`status` tinyint(10) NOT NULL COMMENT '状态',
PRIMARY KEY (`id`),
KEY `idx_status` (`status`),
KEY `idx_apply_id` (`apply_id`)
) ENGINE=InnoDB AUTO_INCREMENT=984483 DEFAULT CHARSET=utf8 COMMENT='黑白名单申请单明细'
表数据:
| id | apply_id | status |
|---|---|---|
| 959651 | 1695369220522068998 | 1 |
| 960738 | 1695369227576173690 | 1 |
| 961319 | 1695373047673903326 | 1 |
| 961365 | 1695373122447865228 | 1 |
通过 idx_apply_id建立的b+树:
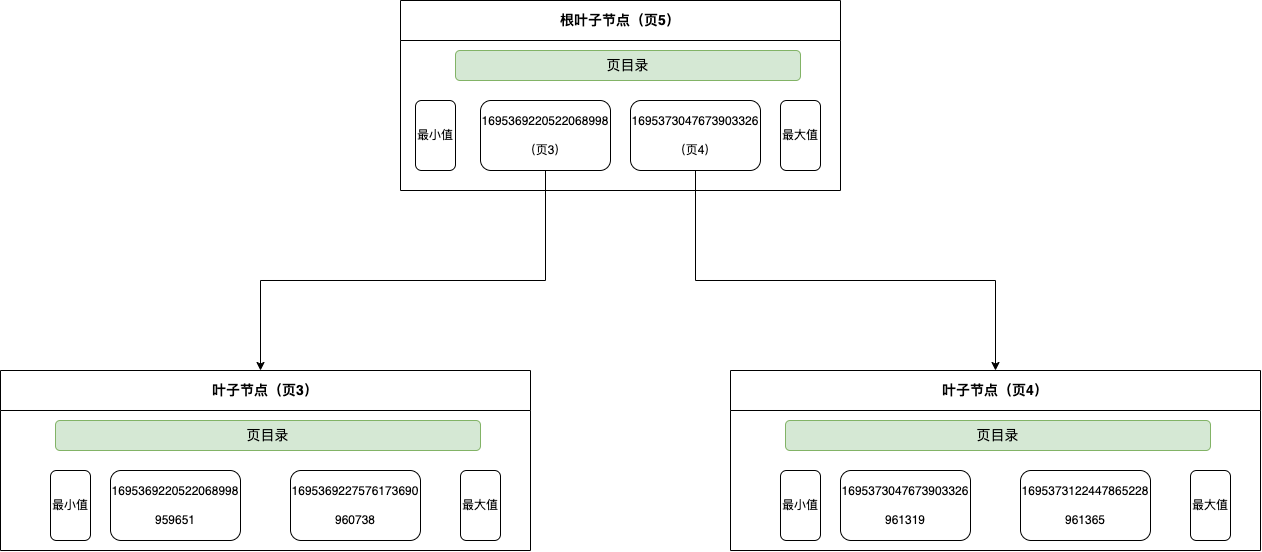
因为索引是二级索引,所以叶子节点存储的数据是主键值.
执行sql
select * from jdi_roster_apply_detail where apply_id='1695369227576173690' for update
执行数据扫描过程 。
1 查到符合条件的记录,增加next-key 锁,因此锁是(1695369220522068998,1695369227576173690] 。
2 找到第一个不符合记录的数据增加间隙锁,因此锁是 (1695369227576173690,1695373047673903326) 。
3 对符合条件的主键索引增加记录锁,因此对 id=960738,增加记录锁.
针对三种锁解决的幻读:
1 如果没有第一条的next-key锁, 另一个事务增加一个apply_id=1695369227576173690, id<960738 时,该事务在进行查询时,会多一条记录,因此会造成幻读.
2 如果没有第二条的 间隙锁,另一个事务增加一个apply_id=1695369227576173690, id>960738是,该事务在进行查询时,会多一条记录,因此会造成幻读.
3 如果没有第三条的记录锁,另一条事务删除一条 id=960738的记录,该事务进行查询时,会少一条数据,因此会造成幻读.
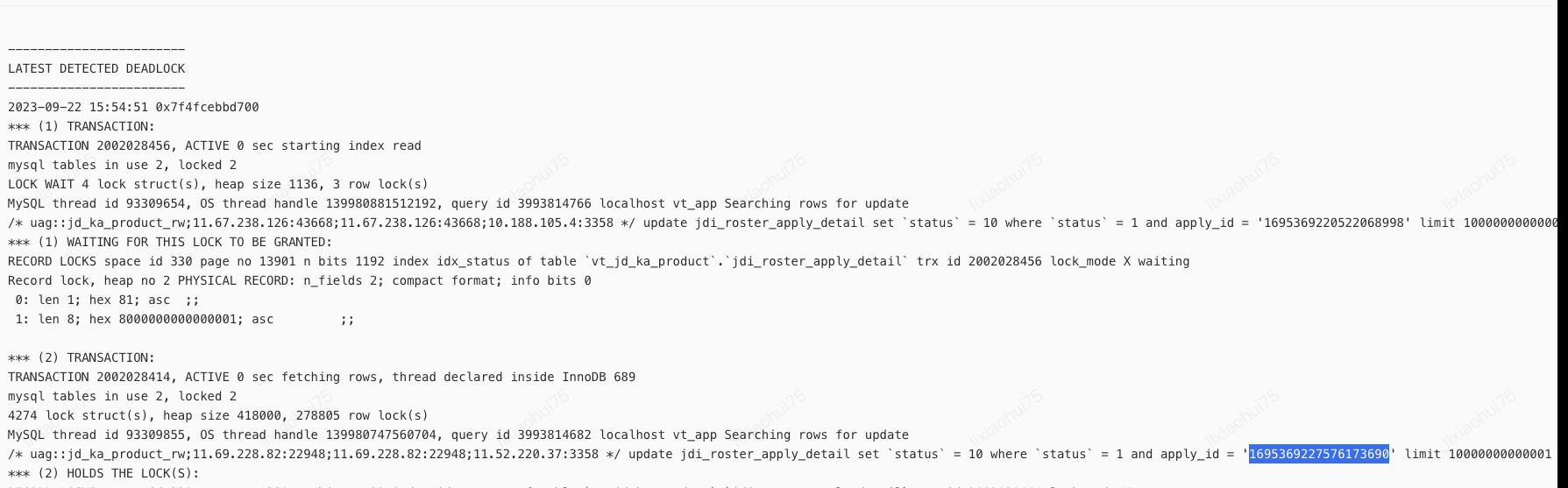
以上日志两个事务分别执行了update语句:
#事务1
update jdi_roster_apply_detail set `status` = 10 where `status` = 1 and apply_id = '1695369220522068998'
#事务2
update jdi_roster_apply_detail set `status` = 10 where `status` = 1 and apply_id = '1695369227576173690'
这个sql是用于将某个申请单id待审批的数据改为已审批.
因为在泰山里不能执行update语句 ,因此执行了select语句查看用的索引情况:
explain select * from jdi_roster_apply_detail where `status` = 1 and apply_id = '1695369220522068998'
执行的结果:

通过结果可以看出两个update语句都使用了两个索引,分别是idx_status,idx_apply_id,然后将查到的结果进行合并,因此在模拟的过程中,可以将其拆成两个查询语句.
| 事务1 | 事务2 | 锁的范围 |
|---|---|---|
| begin | begin | |
| select * from jdi_roster_apply_detail where apply_id = '1695369220522068998' for update | idx_apply_id所以锁住了(-∞,1695369220522068998],(1695369220522068998,1695369227576173690) 主键id索引锁住了 id=959651 | |
| select * from jdi_roster_apply_detail where apply_id = '1695369227576173690' for update | idx_apply_id所以锁住了(1695369220522068998,1695369227576173690],(1695369227576173690,1695373047673903326) 主键id索引锁住了 id=960738 | |
| select * from jdi_roster_apply_detail where status = 1 for update | 会对idx_status上加next-key锁和间隙锁,但是在对主键959651,960738,961319,961365进行加记录锁时,其中事务2 对960738已经加了记录锁,所以该事务1进行了阻塞。 | |
| select * from jdi_roster_apply_detail where status = 1 for update | 会对idx_status上加next-key锁和间隙锁,但是在对主键959651,960738,961319,961365进行加记录锁时,其中事务1对959651已经加了记录锁,所以该事务2进行了阻塞。 | |
| deadlock |
两个事务分别想要两个主键id的记录锁,造成相互等待,形成了死锁.
以上是先执行idx_apply_id的索引查询再执行idx_status索引查询,如果先执行idx_status索引查询,再执行idx_apply_id的索引查询,也会因为主键的记录锁造成死锁.
1 利用force index(idx_apply_id)强制走某个索引,这样InnoDB就会忽略index merge,避免多个索引同时加锁的情况.
2 禁用Index Merge,用命令禁用Index Merge:SET GLOBAL optimizer_switch='index_merge=off,index_merge_union=off,index_merge_sort_union=off,index_merge_intersection=off',
3 Index Merge同时使用了2个独立索引,因此新建一个包含这两个索引所有字段的联合索引,这样InnoDB就只会走这个单独的联合索引.
第三种方案相较于第一种查询性能更好,相对于第二种仅仅作用于该表,影响范围小,因此本次也是采用了该方案.
该死锁问题是因为优化器使用了合并索引问题导致的,最终通过新建一个联合索引来解决这个问题.
参考文档:
1 https://www.xiaolincoding.com/mysql/lock/how_to_lock.html 。
作者:京东工业 李小辉 。
来源:京东云开发者社区 转载请注明来源 。
最后此篇关于MySQL的indexmerge(索引合并)导致数据库死锁分析与解决方案的文章就讲到这里了,如果你想了解更多关于MySQL的indexmerge(索引合并)导致数据库死锁分析与解决方案的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
32
4
 0
0
我的问题是如何在 python 中创建一个简单的数据库。我的例子是: User = { 'Name' : {'Firstname', 'Lastname'}, 'Address' : {'Street
我需要创建一个与远程数据库链接的应用程序! mysql 是最好的解决方案吗? Sqlite 是唯一的本地解决方案吗? 我使用下面的方法,我想知道它是否是最好的方法! NSString *evento
给定两台 MySQL 服务器,一台本地,一台远程。两者都有一个包含表 bohica 的数据库 foobar。本地服务器定义了用户 'myadmin'@'%' 和 'myadmin'@'localhos
我有以下灵活的搜索查询 Select {vt:code},{vt:productcode},{vw:code},{vw:productcode} from {abcd AS vt JOIN wxyz
好吧,我的电脑开始运行有点缓慢,所以我重置了 Windows,保留了我的文件。因为我的大脑还没有打开,所以我忘记事先备份我的 MySQL 数据库。我仍然拥有所有原始文件,因此我实际上仍然拥有数据库,但
如何将我的 Access 数据库 (.accdb) 转换为 SQLite 数据库 (.sqlite)? 请,任何帮助将不胜感激。 最佳答案 1)如果要转换 db 的结构,则应使用任何 DB 建模工具:
系统检查发现了一些问题: 警告:?:(mysql.W002)未为数据库连接“默认”设置 MySQL 严格模式 提示:MySQL 的严格模式通过将警告升级为错误来修复 MySQL 中的许多数据完整性问题
系统检查发现了一些问题: 警告:?:(mysql.W002)未为数据库连接“默认”设置 MySQL 严格模式 提示:MySQL 的严格模式通过将警告升级为错误来修复 MySQL 中的许多数据完整性问题
我想在相同的 phonegap 应用程序中使用 android 数据库。 更多说明: 我创建了 phonegap 应用程序,但 phonegap 应用程序不支持服务,所以我们已经在 java 中为 a
Time Tracker function clock() { var mytime = new Date(); var seconds
我需要在现有项目上实现一些事件的显示。我无法更改数据库结构。 在我的 Controller 中,我(从 ajax 请求)传递了一个时间戳,并且我需要显示之前的 8 个事件。因此,如果时间戳是(转换后)
我有一个可以收集和显示各种测量值的产品(不会详细介绍)。正如人们所期望的那样,显示部分是一个数据库+建立在其之上的网站(使用 Symfony)。 但是,我们可能还会创建一个 API 来向第三方公开数据
我们将 SQL Server 从 Azure VM 迁移到 Azure SQL 数据库。 Azure VM 为 DS2_V2、2 核、7GB RAM、最大 6400 IOPS Azure SQL 数据
我正在开发一个使用 MongoDB 数据库的程序,但我想问在通过 Java 执行 SQL 时是否可以使用内部数据库进行测试,例如 H2? 最佳答案 你可以尝试使用Testcontainers Test
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 已关闭 9 年前。 此问题似乎与 a specific programming problem, a sof
我正在尝试使用 MSI 身份验证(无需用户名和密码)从 Azure 机器学习服务连接 Azure SQL 数据库。 我正在尝试在 Azure 机器学习服务上建立机器学习模型,目的是我需要数据,这就是我
我在我的 MySQL 数据库中使用这个查询来查找 my_column 不为空的所有行: SELECT * FROM my_table WHERE my_column != ""; 不幸的是,许多行在
我有那个基地:http://sqlfiddle.com/#!2/e5a24/2这是 WordPress 默认模式的简写。我已经删除了该示例不需要的字段。 如您所见,我的结果是“类别 1”的两倍。我喜欢
我有一张这样的 table : mysql> select * from users; +--------+----------+------------+-----------+ | userid
我有表: CREATE TABLE IF NOT EXISTS `category` ( `id` int(11) NOT NULL, `name` varchar(255) NOT NULL

我是一名优秀的程序员,十分优秀!