
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 36
36
 4
4


本文已收录至GitHub,推荐阅读 👉 Java随想录 。
微信公众号:Java随想录 。
原创不易,注重版权。转载请注明原作者和原文链接 。
在日常的应用开发中,我们经常会遇到需要使用多种不同类型的数据库管理系统来满足各种业务需求。其中最典型的就是Redis和MySQL的组合使用.
这两者拥有各自的优点,例如Redis为高性能的内存数据库提供了极快的读写速度,而MySQL则是非常强大的关系型数据库,支持事务处理,并且提供了很好的数据一致性.
然而,在实际应用过程中,如何保证Redis和MySQL双写时的数据一致性问题成为了开发者们面临的重要挑战。本文即将针对这个问题进行深入探讨,希望能为广大开发者们提供一些有价值的思路和解决方案.
双写一致性问题主要是指当我们同时向Redis和MySQL写数据时,由于网络延迟、服务器故障等原因,可能导致数据在两个系统之间产生不一致.
例如,你可能已经更新了MySQL中的数据,但是Redis中的数据还未来得及更新,或者反过来。这样的结果就可能导致用户读到的是旧的、不正确的数据.
比如在现实生活中的购物网站场景:假设用户A在购买一件库存仅剩1件的商品,系统在接收到请求后,先将MySQL中的库存减少1,然后出现了网络延迟或系统故障,Redis中的库存没有减少。此时,用户B看到的是还有1件商品,也发起了购买请求,如果系统又首先更改了MySQL,那么就会出现超卖的情况,即实际库存已经没有,但因为缓存中的信息不准确,导致系统销售了更多的商品.
严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以对于缓存架构我们追求的目标是最终一致性.
实际上,缓存就是通过牺牲强一致性来提高性能的。这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP.
解决这种问题的常见策略就是“缓存读写策略”。这个策略用于处理先更新数据库还是先更新缓存等场景.
接下来,我们将探讨三种缓存读写策略。这些策略各有优劣,没有绝对的最佳选择。请根据具体的应用场景选择最合适的策略.
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。旁路缓存模式中服务端需要同时维护 DB 和 Cache ,并且是以 DB 的结果为准。 读 :从缓存读取数据,读到直接返回。如果读取不到的话,从数据库加载,写入缓存后,再返回响应.
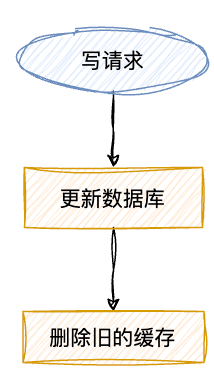
写 :更新的时候,先「 更新数据库,然后再删除缓存 」.
Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责.
因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入DB的功能,所以使用并不多.

读 :从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应.
从流程图中可以看出,读写穿透模式和旁路缓存模式的读取流程几乎相同。不过,在旁路缓存模式中,客户端需要负责将数据写入 cache 。而在读写穿透模式中, cache 服务自行写入缓存,对客户端来说,这个过程是透明的.
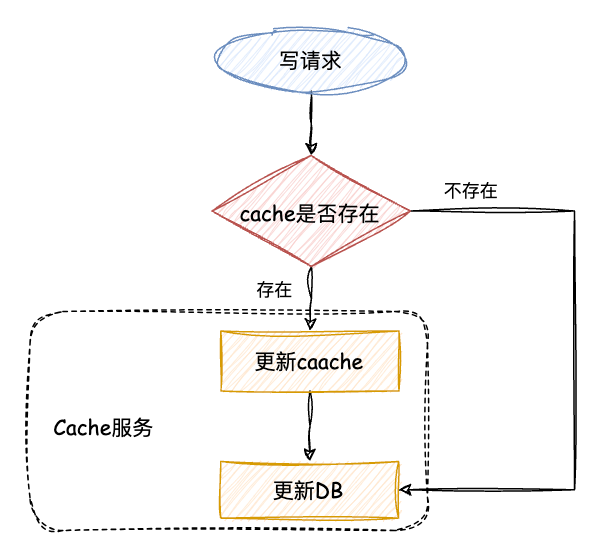
写 :先查 cache,cache 中不存在,直接更新 DB。cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB( 同步更新 cache和DB ).
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写.
但是,两个又有很大的不同: Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB .
很明显,这种方式对数据一致性带来了更大的挑战,比如cache数据可能还没异步更新DB的话,cache服务可能就挂掉了,反而会带来更大的灾难.
这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 InnoDB Buffer Pool 机制都用到了这种策略.
Write Behind Pattern 下 DB 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量等.
旁路缓存模式是我们平时中使用最多的,根据该模式,我们可能会有以下几个疑问.
为什么写操作是删除缓存,而不是更新缓存 。
答 :假设线程A先发起一个写操作,第一步先更新数据库。线程B再发起一个写操作,紧接着也更新了数据库。由于网络等原因,线程B比线程A先更新了缓存,然后线程A更新缓存.
这时候,缓存保存的是A的数据(老数据),而数据库保存的是B的数据(新数据),数据就不一致了,脏数据出现啦。如果是「 删除缓存取代更新缓存 」则不会出现这个脏数据问题.
实际上要写操作的时候更新缓存也是可以的,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题.
在写数据的过程中,为什么要先更新DB再删除缓存 。
答 :假设请求1 是写操作,要是先删除缓存A,这时候来了请求2,请求2是读操作,先读缓存A,发现缓存被删除了(被请求1删除了),然后去读数据库,但是此时请求1还没来得及把数据及时更新,那么请求2读的就是旧数据,并且请求2还会把读到的旧数据放到缓存中,造成了数据的不一致.
其实要先删缓存,再更新数据库也是可以,如采用「 延时双删策略 」.
休眠一段时间,再次淘汰缓存。这么做,可以将这段时间内所造成的缓存脏数据,再次删除.
注意sleep休眠的时间不能小于修改数据库数据的时间小,基本上1秒就够了.
在写数据的过程中,先更新DB,后删除cache就没有问题了么?
答: 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小.
假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生:
然而,发生这种情况的概率并不高 。
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5).
可是,仔细想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现.
还有其他造成不一致的原因么?
答: 如果删除缓存过程中失败了就会造成不一致问题。可以使用Canal去订阅数据库的binlog,获得需要操作的数据。另起一个程序,获得这个订阅程序传来的信息,进行删除缓存操作.
Cache Aside Pattern是一种常见的缓存更新策略,主要在读取数据时用于处理缓存的失效和更新。尽管它有很多优点,但也存在一些缺陷:
缺陷1:首次请求数据一定不在 cache 的问题 。
解决办法:可以将热点数据提前放入cache 中.
缺陷2:写操作比较频繁的话导致cache中的数据会被频繁被删除,这样会影响缓存命中率 .
Redis的延时双删策略主要用于解决分布式系统当中的缓存与数据库数据一致性问题。以下是其基本步骤:
该策略的理念是:如果有其他线程在步骤1和步骤2之间查询到旧的数据并写入了缓存,那么步骤3可以保证这部分旧的数据被清除,从而尽可能维持数据库和缓存之间的数据一致性.
以下是使用Java实现的样例代码:
import redis.clients.jedis.Jedis;
public class RedisDoubleDelStrategy {
private Jedis jedis;
private static final long DELAY_MILLIS = 1000L; // 设置为你需要的延时时间
public RedisDoubleDelStrategy(String host, int port) {
this.jedis = new Jedis(host, port);
}
public void updateDBAndCache(String key, String value) {
// Step 1: 删除缓存
jedis.del(key);
// Step 2: 更新数据库,此处以打印输出代替
System.out.println("Update DB with: " + value);
// 延迟任务来完成第二次删除
new Thread(() -> {
try {
Thread.sleep(DELAY_MILLIS);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Step 3: 延时后再次删除缓存
jedis.del(key);
}).start();
}
}
这段代码实现了延时双删策略,但请注意它仍然不能完全保证数据库和缓存之间的一致性.
在某些情况下(比如大量并发情况下),可能仍然会出现不一致的问题。例如,在步骤3之后,如果还有其他线程查询到了旧数据并写入了缓存,那么数据库和缓存的数据就会不一致。因此,在使用该策略时,需要根据你的系统特性和一致性需求来进行权衡.
本篇文章到这就结束了,在探讨Redis与MySQL双写问题的过程中,我们分析了各种可能的场景和解决方案。双写系统不仅考验我们对数据库原理的理解,也展示了协同工作的复杂性。最终,解决这个问题的关键是理解你的用例并根据实际需求选择适当的策略和工具.
而在实际应用中,再完美的方案也可能会遇到挑战和困难。因此,持续监控,频繁测试和及时调整策略都至关重要。希望本文能为你在处理Redis与MySQL双写问题上提供一些思路和灵感,同时,我们也期待在未来看到更多精妙的解决方案诞生.
感谢阅读,如果本篇文章有任何错误和建议,欢迎给我留言指正.
老铁们,关注我的微信公众号「Java 随想录」,专注分享Java技术干货,文章持续更新,可以关注公众号第一时间阅读.
一起交流学习,期待与你共同进步! 。
最后此篇关于探索Redis与MySQL的双写问题的文章就讲到这里了,如果你想了解更多关于探索Redis与MySQL的双写问题的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
36
4
 0
0
接上篇 通过一个示例形象地理解C# async await 非并行异步、并行异步、并行异步的并发量控制 前些天写了两篇关于C# async await异步的博客, 第一篇博客看的人多,点
前言 在 SwiftUI 中,我们可以通过添加不同的交互来使我们的应用程序更具交互性,这些交互可以响应我们的点击,点击和滑动。 今天,我们将回顾SwiftUI基本手势:
今年我一直在想,2022年我想做些什么,做哪方面的改变,这周末在家终于想到了! 2021 轻描淡写 年底就一直想对2021年写一篇总结的,起码不得写个千八百字,可是思来想去不知道怎么写,直到最后都没想
已关闭。此问题不符合Stack Overflow guidelines 。目前不接受答案。 要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于 Stack Overflow 来说是偏离主题的,因为
在 Eclipse 中使用 Java 进行开发时,它非常方便:您可以像自己一样附加源代码并探索核心 Java 代码。在 Visual Studio 中,我知道只有在调试时才能查看 .net 源代码(我
我正在尝试创建自己的字符串数据类型,谁能告诉我 typedef 和初始化做错了什么。 #include #include typedef char string[10]; int main(){
我期待开发一些东西来分析在服务器上运行的应用程序的 JVM 线程,要求如下: 访问在单独应用程序中运行的所有线程 打印线程栈 了解事件的详细信息 - 记录执行时间和方法详细信息(在特定线程中执行) 我
是否可以探索 Android 内部存储?我需要这个用于调试目的,以帮助我的开发工作。 最佳答案 您可以在模拟器上,或在 Root设备上。只是 adb shell 连接设备,然后从那里导航。 关于and
我有一个使用大量外键的 innoDB 表,但我们只想从中查找一些基本信息。 我做了一些研究,但还是迷路了。 如何判断我的主机是否有 Sphinx已经安装了吗?我没看到作为表格存储的选项方法(即 inn
我有一个创建列表的 GWT 代码(作为结果的网格),我将样式设置为 CSS 类,如 .test tr { height: 26px; } 现在...如果在渲染未完成或网格没有元素时我需要从代码
我需要使用 Javascript 和 HTML 为 Rally 敏捷工具开发一个 View 。我没有处理过在我作为开发人员的新职业中经常使用的网络语言。 我只是在探索他们的 API,但不知道如何探索他
我想了解 Hadoop 而不是一个黑盒子。我想探索 Hadoop 代码本身。我怎样才能不从主干下载 bundle ,我应该从哪里开始?任何帮助都会很有帮助谢谢舒佳特 最佳答案 Hadoop 代码在 S
想象一下这样的情况。您获得了一些遗留代码或获得了一些新框架。您需要尽快调查并了解如何使用此代码。没有机会向以前的开发人员寻求帮助。什么是最佳实践/方法/方式/步骤/工具(首选 .NET Framewo
我注意到我的 git 存储库中的某些 makefile 缺少变量定义的问题,我想搜索所有提交历史以查找我的变量 TESTDIR 在变更集中出现的位置 我该怎么做? 干杯 最佳答案 你可以使用 git
有什么方法可以探索 GO 包吗? 在 java 中,我使用“javap java.lang.String”命令来查看类内部的方法。像这样,有没有命令是他们用 GO 语言写的? 我在谷歌中搜索了相同的内
我注意到 docker 我需要了解容器内发生了什么或其中存在哪些文件。一个示例是从 docker 索引下载图像 - 您不知道图像包含什么,因此无法启动应用程序。 理想的情况是能够通过 ss
近日,华为 分析服务 6.9.0版本发布,正式上线 探索能力 。开发者可自由定义与配置分析模型,支持报告实时预览,数据洞察体验更加灵活与便捷. 新上线的探索能力中,有漏斗分析、事件归因、会话路径分析
我有一个 4 列的 excel 2010 电子表格。 A 列:我销售的产品的 UPC 代码列表。大约300行。 B 列:公式(稍后会详细介绍) C 列:另一个 UPC 代码列表。这些 UPC 代码大约
我有 3 个表格如下: CREATE TABLE USER_STATUS ("UID" varchar2(7), "STAT_ID" varchar2(11)) ; INSERT ALL IN
有什么方法可以探索 java 脚本对象(如 telerik 菜单或任何其他第 3 方对象)的属性和/或功能?我可以通过调试和破坏然后在 watch 中添加对象或在 VS 中使用智能感知来实现。 我使用

我是一名优秀的程序员,十分优秀!