
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 38
38
 4
4


以OpenAI 的ChatGPT 所掀起的GenAI 快速创新浪潮,其中连接LLM 和 应用之间的桥梁的两大开源项目: LangChain [1]和 Semantic Kernel [2] ,在半年前写过一篇文章 LangChain vs Semantic Kernel [3],这半年以来Semantic kernel 有了显着改进,这篇文章反应了最新的更新.
Semantic Kernel (SK) 是一个开源的将大型语言模型(LLM)与流行的编程语言相结合的SDK,Microsoft将Semantic Kernel(简称SK)称为轻量级SDK,结合了OpenAI,Azure OpenAI和Hugging Face等AI LLM的集成。它使开发人员能够通过编排 AI 组件并将其与现有代码集成来创建 AI 应用。SDK 提供对 Java、Python 和 C# 的支持。它提供了用于添加内存和AI服务的连接器,为应用程序创建模拟的“大脑”。语义内核支持来自不同提供商的插件,为开发人员提供自己的 API,并简化 AI 服务的集成,使开发人员能够利用最新的 AI 进步并构建复杂和智能的管道。SK 大约 是在 2023 年 3 月下旬开源,大约开源6个多月,比 LangChain 晚开源了5个月.
SK Planner 与 LangChain Agents [8]非常相似。主要区别在于SK Planner 将从一开始就创建一个计划,而LangChain Agent将在每一步确定下一步的行动方案。LangChain的方法听起来更好,但代价是性能低和更高的Token 使用量。Planner 是SK的可扩展部分。这意味着我们有多个Planner 可供选择,如果您有特定需求,您可以创建自定义Planner。有关Planner 更多信息,请参阅 此处 [9].
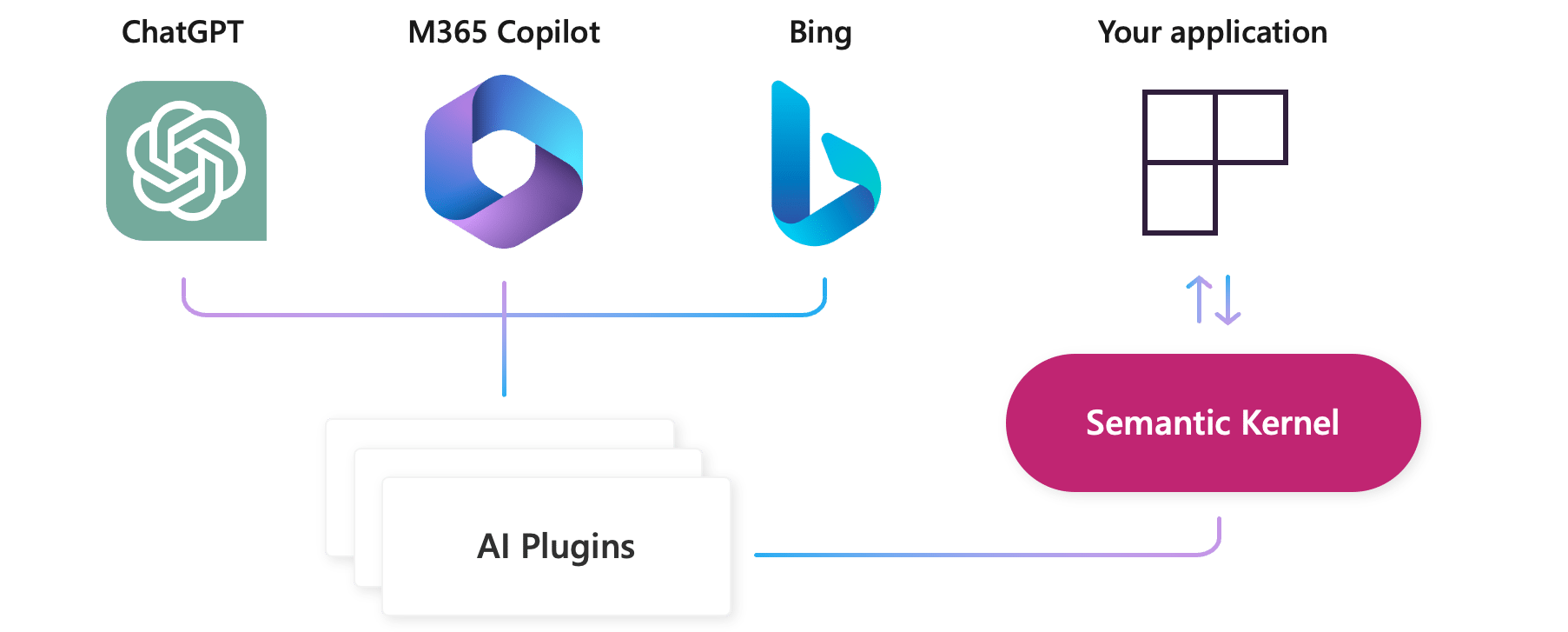
“Plugins” 只是SK用来表示一组 函数 的术语。为了推动整个行业的一致性,SK 采用了 OpenAI插件规范作为插件 [10]的标准。这将有助于创建一个可互操作的插件生态系统,可用于所有主要的AI应用程序和服务,如ChatGPT,Bing和Microsoft 365.
对于使用SK 的开发人员来说,这意味着您可以导出您构建的任何插件,以便它们可以在 ChatGPT、Bing 和 Microsoft 365 中使用。这使您无需重写代码即可扩大 AI 功能的范围。这也意味着为 ChatGPT、Bing 和 Microsoft 365 构建的插件可以无缝导入到SK中.
大多数“插件”将涉及与外部服务的集成,例如LLM,数据库,MS Teams,SAP等。但是绝对可以创建纯粹由函数组成的插件,而无需任何外部服务集成.
您可以使用 SK 插件 编写两种类型的函数, 语义 函数和 本机 函数.
IsValidEmail Respond with 1 or 0, is this a valid e-mail address format:"{email}" 。
or 。
LanguageTranslator Translate this text from {from} to {to}:"{input}" 。
我 非常喜欢 SK的是把这些提示是写在文件中的,或代码中 没有多行魔术字符串.
[SKFunction, Description("Take the square root of a number")]
public string Sqrt(string number)
{
return Math.Sqrt(Convert.ToDouble(number, CultureInfo.InvariantCulture)).ToString(CultureInfo.InvariantCulture);
}
LLM 通常只是自然语言处理方面的能手,比如通常数学不好,我们可以把 使用经过验证的数学库封装为本地函数,SK 通过语义函数和本地函数将传统的语法编程和语义编程结合起来构建强大的插件。插件之前叫做技能,将“ 插件 ”视为 “技能” 更容易理解。我猜测SK 之后使用术语“插件”来与OpenAI的术语保持一致.
Semantic Kernel与LangChain相比,SK目前拥有一组较小的开箱即用插件( LangChain 比SK开源时间早了 4个月)。以下是目前一些值得注意的差异:
Semantic Memory 是 “一个开源的 服务和 插件 ,专门用于数据集的有效索引( 来源在这里 [16])它是SK的有力搭档。 注入AI的应用程序的大多数实际用例都涉及处理数据,以便LLM可以使用数据。 分块 、 嵌入 、向量 存储 和 向量搜索 是该领域讨论的一些常见主题。有关详细信息,请参阅 文档 和 存储库 .
SK 没有内置功能将聊天记录存储在文件系统、Redis 缓存、MongoDB 或其他数据库等持久存储中,这部分功能的演示包含在 参考 应用程序 Chat Copilot [17].
正如反复提到的,SK是为 开发人员而构建 的。本节介绍一些这方面的工具:
SK Semantic Function最好使用 VS Code 编写,并使用官方 语义内核工具扩展 [18].

Prompt flow 。
提示流 [19]是一种开发工具,旨在简化LLM应用程序的创建。它通过提供简化原型设计,实验,迭代和部署LLM应用程序过程的工具来实现这一点。 最值得注意的是,提示流允许您编写本机和语义函数链,并将它们可视化为图形。这使你和团队的其他成员能够在 Azure ML Studio和本地使用 VS Code 轻松创建和测试 AI 支持的功能.

Prompt Playground 。
Prompt Playground [20] 是一个简易的 Semantic Kernel 语义技能调试工具,创建新的语义函数并对其进行测试,而无需编写任何代码 。

可观测性 。
正如反复提到的,SK是为开发人员而构建的,采用云原生的可观测性来建立有效的产品遥测, 产品遥测是指从软件应用程序收集和分析数据以深入了解以下内容的过程:
使用Semantic Kernel记录和计量请求有几个主要好处:
Chat Copilot 应用程序 。
SK发布了 一个 Chat Copilot [17]参考 应用程序。与 许多 ChatGPT 存储库 [21]不同,此示例应用程序充分展示SK 的上述各项特性:
除了Chat Copilot 参考应用程序之外,还有其他 示例应用 。这些应用展示:
Semantic Kernel 是一个强大的SDK,用于为您的 Copilot Stack 构建AI编排器。 在这篇文章中,我向你介绍了如何使用SK完成各种任务的学习总结,例如创建和执行计划,编写语义和本机函数等等。我还向您展示了一些使用 SK 进行开发的实用资源,例如 VS Code 扩展、Chat Copilot 应用程序和其他示例应用程序。虽然目前的SK版本已经相当强大,马上就要发布1.0 版本了,但它正在不断创新 。如果您想了解有关SK的更多信息并加入SK社区。我在Github上为你准备好了开始探索SK的资源列表: https://github.com/geffzhang/awesome-semantickernel[25 ] 。

相关链接:
最后此篇关于使用SemanticKernel进行智能应用开发(2023-10更新)的文章就讲到这里了,如果你想了解更多关于使用SemanticKernel进行智能应用开发(2023-10更新)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
38
4
 0
0
我查看了网站上的一些问题,但还没有完全弄清楚我做错了什么。我有一些这样的代码: var mongoose = require('mongoose'), db = mongoose.connect('m
基本上,根据 this bl.ocks,我试图在开始新序列之前让所有 block 都变为 0。我认为我需要的是以下顺序: 更新为0 退出到0 更新随机数 输入新号码 我尝试通过添加以下代码块来遵循上述
我试图通过使用随机数在循环中设置 JSlider 位置来模拟“赛马”的投注结果。我的问题是,当然,我无法在线程执行时更新 GUI,因此我的 JSlider 似乎没有在竞赛,它们从头到尾都在运行。我尝试
该功能非常简单: 变量:$table是正在更新的表$fields 是表中的字段,$values 从帖子生成并放入 $values 数组中而$where是表的索引字段的id值$indxfldnm 是索引
让我们想象一个环境:有一个数据库客户端和一个数据库服务器。数据库客户端可以是 Java 程序或其他程序等;数据库服务器可以是mysql、oracle等。 需求是在数据库服务器上的一个表中插入大量记录。
在我当前的应用程序中,我正在制作一个菜单结构,它可以递归地创建自己的子菜单。然而,由于这个原因,我发现很难也允许某种重新排序方法。大多数应用程序可能只是通过“排序”列进行排序,但是在这种情况下,尽管这
Provisioning Profile 有 key , key 链依赖于它。我想知道 key 什么时候会改变。 Key will change after renew Provisioning Pr
截至目前,我在\server\publications.js 中有我的 MongoDB“选择”,例如: Meteor.publish("jobLocations", function () { r
我读到 UI 应该始终在主线程上更新。但是,当谈到实现这些更新的首选方法时,我有点困惑。 我有各种函数可以执行一些条件检查,然后使用结果来确定如何更新 UI。我的问题是整个函数应该在主线程上运行吗?应
我在代理后面,我无法构建 Docker 镜像。 我试过 FROM ubuntu , FROM centos和 FROM alpine ,但是 apt-get update/yum update/apk
我构建了一个 Java 应用程序,它向外部授权客户端公开网络服务。 Web 服务使用带有证书身份验证的 WS-security。基本上我们充当自定义证书颁发机构 - 我们在我们的服务器上维护一个 ja
因此,我有时会在上传新版本时使用 app_offline.htm 使应用程序离线。 但是,当我上传较大的 dll 时,我收到黄色错误屏幕,指出无法加载 dll。 这似乎与我对 app_offline.
我刚刚下载了 VS Apache Cordova Tools Update 5,但遇到了 Node 和 NPM 的问题。我使用默认的空白 cordova 项目进行测试。 版本 如果我在 VS 项目中对
所以我有一个使用传单库实例化的 map 对象。 map 实例在单独的模板中创建并以这种方式路由:- var app = angular.module('myApp', ['ui', 'ngResour
我使用较早的 Java 6 u 3 获得的帧速率是新版本的两倍。很奇怪。谁能解释一下? 在 Core 2 Duo 1.83ghz 上,集成视频(仅使用一个内核)- 1500(较旧的 java)与 70
我正在使用 angular 1.2 ng-repeat 创建的 div 也包含 ng-click 点击时 ng-click 更新 $scope $scope 中的变化反射(reflect)在使用 $a
这些方法有什么区别 public final void moveCamera(CameraUpdate更新)和public final void animateCamera (CameraUpdate
我尝试了另一篇文章中某人评论中关于如何将树更改为列表的建议。但是,我在某处(或某物)有未声明的变量,所以我列表中的值是 [_G667, _G673, _G679],而不是 [5, 2, 6],这是正确
实现以下场景的最佳方法是什么? 我需要从java应用程序调用/查询包含数百万条记录的数据库表。然后,对于表中的每条记录,我的应用程序应该调用第三方 API 并获取状态字段作为响应。然后我的应用程序应该
只是在编写一些与 java 图形相关的代码,这是我今天的讲座中的非常简单的示例。不管怎样,互联网似乎说更新不会被系统触发器调用,例如调整框架大小等。在这个例子中,更新是由这样的触发器调用的(因此当我只

我是一名优秀的程序员,十分优秀!