
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 35
35
 4
4


博客地址: https://www.cnblogs.com/zylyehuo/ 。
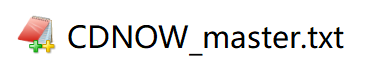
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
import matplotlib.pyplot as plt
df = pd.read_csv('./data/CDNOW_master.txt',header=None,sep='\s+',names=['user_id','order_dt','order_product','order_amount'])
df
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69659 non-null int64
1 order_dt 69659 non-null int64
2 order_product 69659 non-null int64
3 order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB
df['order_dt'] = pd.to_datetime(df['order_dt'],format='%Y%m%d')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69659 non-null int64
1 order_dt 69659 non-null datetime64[ns]
2 order_product 69659 non-null int64
3 order_amount 69659 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2)
memory usage: 2.1 MB
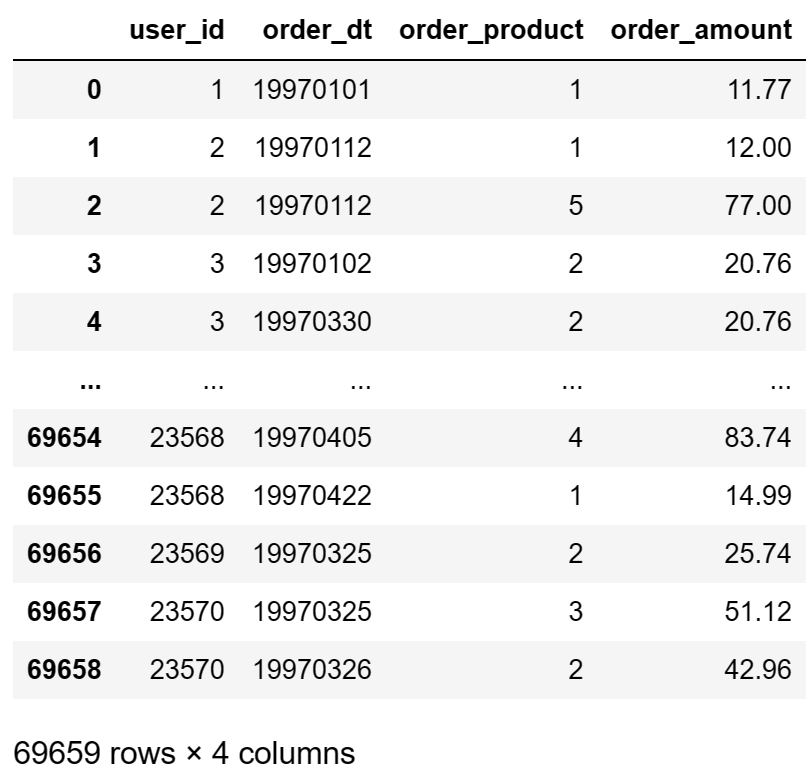
df.describe()
# 基于order_dt取出其中的月份
# astype('datetime64[M]') 将类型更换成 datetime64[M],仅仅表示月份
df['order_dt'].astype('datetime64[M]')
0 1997-01-01
1 1997-01-01
2 1997-01-01
3 1997-01-01
4 1997-03-01
...
69654 1997-04-01
69655 1997-04-01
69656 1997-03-01
69657 1997-03-01
69658 1997-03-01
Name: order_dt, Length: 69659, dtype: datetime64[ns]
df['month'] = df['order_dt'].astype('datetime64[M]')
df.head()
df.groupby(by='month')['order_amount'].sum()
month
1997-01-01 299060.17
1997-02-01 379590.03
1997-03-01 393155.27
1997-04-01 142824.49
1997-05-01 107933.30
1997-06-01 108395.87
1997-07-01 122078.88
1997-08-01 88367.69
1997-09-01 81948.80
1997-10-01 89780.77
1997-11-01 115448.64
1997-12-01 95577.35
1998-01-01 76756.78
1998-02-01 77096.96
1998-03-01 108970.15
1998-04-01 66231.52
1998-05-01 70989.66
1998-06-01 76109.30
Name: order_amount, dtype: float64
# plt.plot(df.groupby(by='month')['order_amount'].sum())
df.groupby(by='month')['order_amount'].sum().plot()
AxesSubplot:xlabel='month' 。
df.groupby(by='month')['order_product'].sum().plot()
AxesSubplot:xlabel='month' 。
# count() 统计总共有多少行数据
df.groupby(by='month')['user_id'].count()
month
1997-01-01 8928
1997-02-01 11272
1997-03-01 11598
1997-04-01 3781
1997-05-01 2895
1997-06-01 3054
1997-07-01 2942
1997-08-01 2320
1997-09-01 2296
1997-10-01 2562
1997-11-01 2750
1997-12-01 2504
1998-01-01 2032
1998-02-01 2026
1998-03-01 2793
1998-04-01 1878
1998-05-01 1985
1998-06-01 2043
Name: user_id, dtype: int64
df.groupby(by='month')['user_id'].nunique()
month
1997-01-01 7846
1997-02-01 9633
1997-03-01 9524
1997-04-01 2822
1997-05-01 2214
1997-06-01 2339
1997-07-01 2180
1997-08-01 1772
1997-09-01 1739
1997-10-01 1839
1997-11-01 2028
1997-12-01 1864
1998-01-01 1537
1998-02-01 1551
1998-03-01 2060
1998-04-01 1437
1998-05-01 1488
1998-06-01 1506
Name: user_id, dtype: int64
df.groupby(by='user_id')['order_amount'].sum()
user_id
1 11.77
2 89.00
3 156.46
4 100.50
5 385.61
...
23566 36.00
23567 20.97
23568 121.70
23569 25.74
23570 94.08
Name: order_amount, Length: 23570, dtype: float64
df.groupby(by='user_id').count()['order_dt']
user_id
1 1
2 2
3 6
4 4
5 11
..
23566 1
23567 1
23568 3
23569 1
23570 2
Name: order_dt, Length: 23570, dtype: int64
user_amount_sum = df.groupby(by='user_id')['order_amount'].sum()
user_product_sum = df.groupby(by='user_id')['order_product'].sum()
plt.scatter(user_product_sum,user_amount_sum)
<matplotlib.collections.PathCollection at 0x29d3cd9f370> 。
df.groupby(by='user_id').sum().query('order_amount <= 1000')['order_amount']
df.groupby(by='user_id').sum().query('order_amount <= 1000')['order_amount'].hist()
AxesSubplot
df.groupby(by='user_id').sum().query('order_product <= 100')['order_product'].hist()
AxesSubplot
df.groupby(by='user_id')['month'].min()
user_id
1 1997-01-01
2 1997-01-01
3 1997-01-01
4 1997-01-01
5 1997-01-01
...
23566 1997-03-01
23567 1997-03-01
23568 1997-03-01
23569 1997-03-01
23570 1997-03-01
Name: month, Length: 23570, dtype: datetime64[ns]
# value_counts() 统计每一个元素出现的次数
df.groupby(by='user_id')['month'].min().value_counts()
df.groupby(by='user_id')['month'].min().value_counts().plot()
AxesSubplot
df.groupby(by='user_id')['month'].max().value_counts()
1997-02-01 4912
1997-03-01 4478
1997-01-01 4192
1998-06-01 1506
1998-05-01 1042
1998-03-01 993
1998-04-01 769
1997-04-01 677
1997-12-01 620
1997-11-01 609
1998-02-01 550
1998-01-01 514
1997-06-01 499
1997-07-01 493
1997-05-01 480
1997-10-01 455
1997-09-01 397
1997-08-01 384
Name: month, dtype: int64
df.groupby(by='user_id')['month'].max().value_counts().plot()
AxesSubplot
new_old_user_df = df.groupby(by='user_id')['order_dt'].agg(['min','max']) # agg对分组后的结果进行多种指定聚合
new_old_user_df
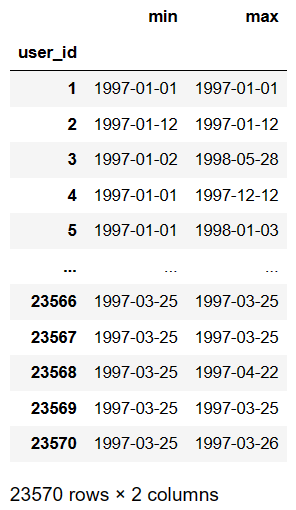
new_old_user_df['min'] == new_old_user_df['max'] # True新用户,False老用户
user_id
1 True
2 True
3 False
4 False
5 False
...
23566 True
23567 True
23568 False
23569 True
23570 False
Length: 23570, dtype: bool
# 统计True和False的个数
(new_old_user_df['min'] == new_old_user_df['max']).value_counts()
True 12054
False 11516
dtype: int64
# 使用透视表
rfm = df.pivot_table(index='user_id',aggfunc={'order_product':'sum','order_amount':'sum','order_dt':"max"})
rfm
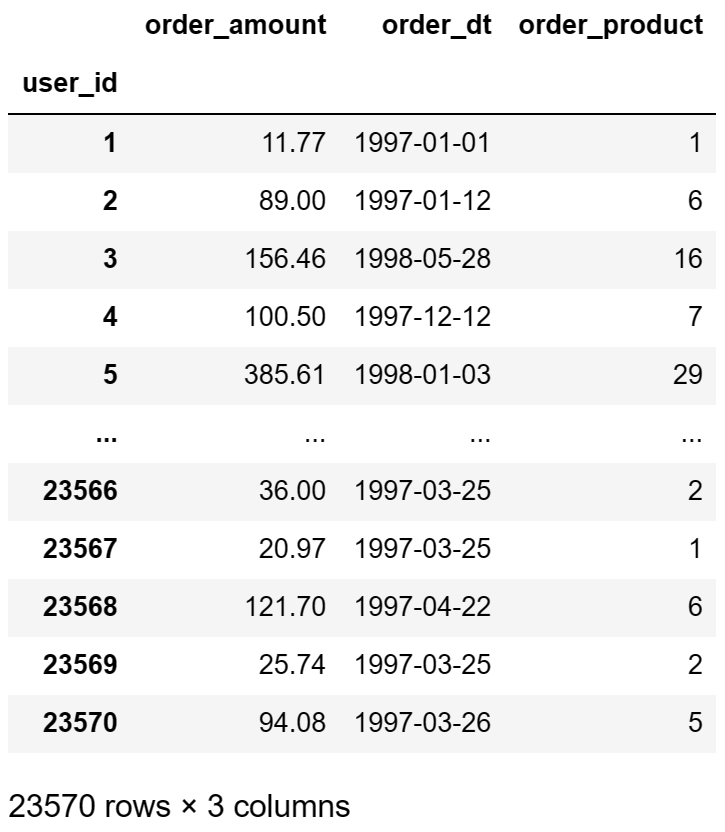
max_dt = df['order_dt'].max() # 今天的日期
# 每个用户最后一次交易的时间
-(df.groupby(by='user_id')['order_dt'].max() - max_dt)
# R表示客户最近一次交易时间的间隔
# /np.timedelta64(1,'D'):去除days
rfm['R'] = -(df.groupby(by='user_id')['order_dt'].max() - max_dt) /np.timedelta64(1,'D')
rfm.drop(labels='order_dt',axis=1,inplace=True)
# 重新给每一列取名
rfm.columns = ['M','F','R']
rfm.head()
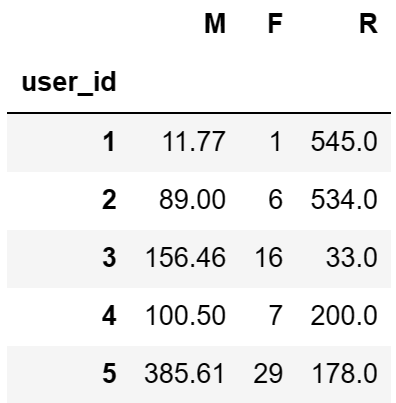
# 固定算法
def rfm_func(x):
# 存储存储的是三个字符串形式的0或者1
level = x.map(lambda x :'1' if x >= 0 else '0')
label = level.R + level.F + level.M
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
}
result = d[label]
return result
# df.apply(func):可以对df中的行或者列进行某种(func)形式的运算
rfm['label'] = rfm.apply(lambda x : x - x.mean()).apply(rfm_func,axis = 1)
rfm.head()
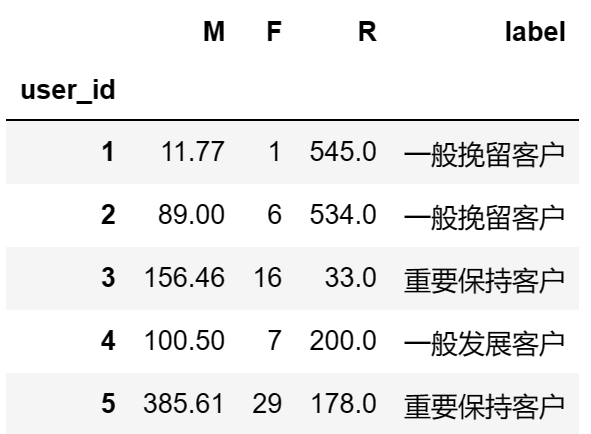
user_month_count_df = df.pivot_table(index='user_id',values='order_dt',aggfunc='count',columns='month').fillna(0)
user_month_count_df.head()
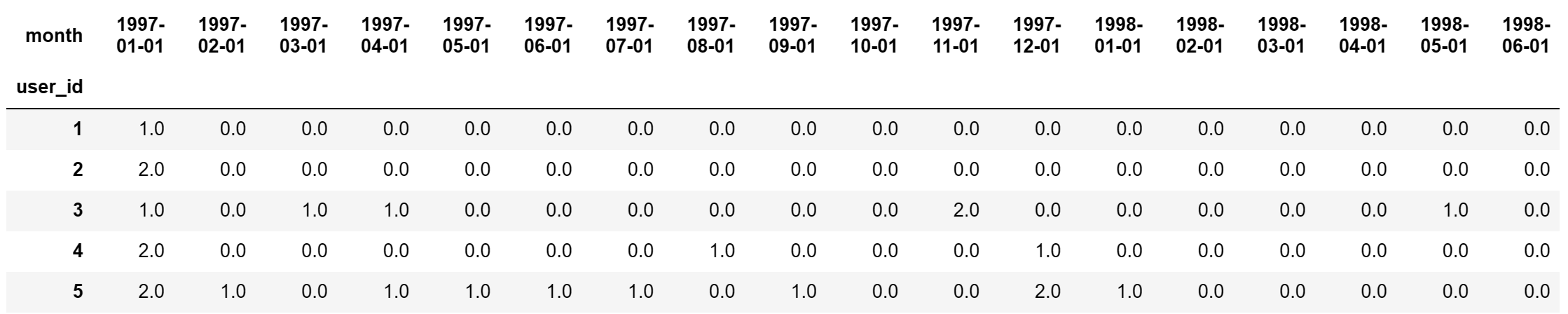
# applymap() 对DataFrame中每个元素进行操作
# apply() 对DataFrame中行或列进行操作
df_purchase = user_month_count_df.applymap(lambda x:1 if x >= 1 else 0)
df_purchase.head()
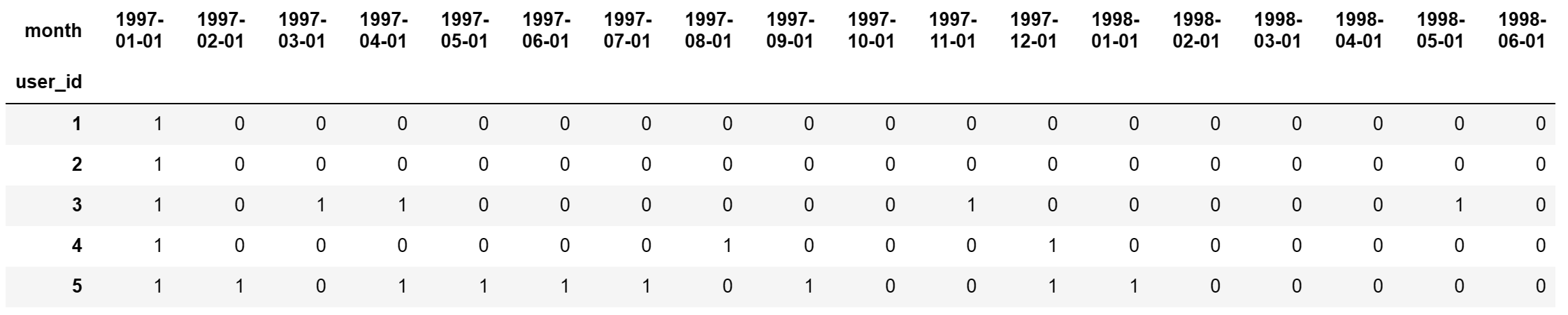
# 将df_purchase中的原始数据0和1修改为new,unactive......,返回新的df叫做df_purchase_new
# 固定算法
def active_status(data):
status = [] # 某个用户每一个月的活跃度
for i in range(18):
# 若本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return status
pivoted_status = df_purchase.apply(active_status,axis = 1)
pivoted_status.head()
user_id
1 [new, unactive, unactive, unactive, unactive, ...
2 [new, unactive, unactive, unactive, unactive, ...
3 [new, unactive, return, active, unactive, unac...
4 [new, unactive, unactive, unactive, unactive, ...
5 [new, active, unactive, return, active, active...
dtype: object
df_purchase_new = DataFrame(data=pivoted_status.values.tolist(),index=df_purchase.index,columns=df_purchase.columns)
df_purchase_new
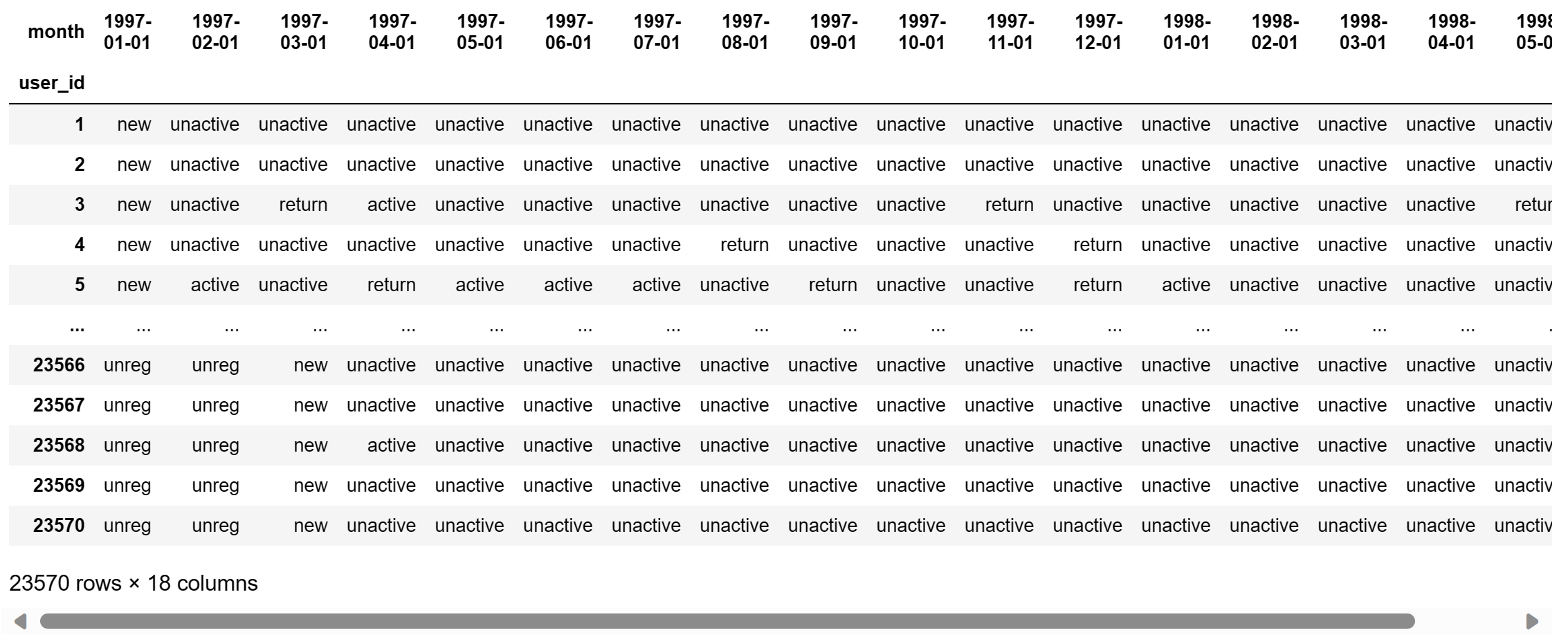
purchase_status_ct = df_purchase_new.apply(lambda x : pd.value_counts(x)).fillna(0)
purchase_status_ct

purchase_status_ct.T
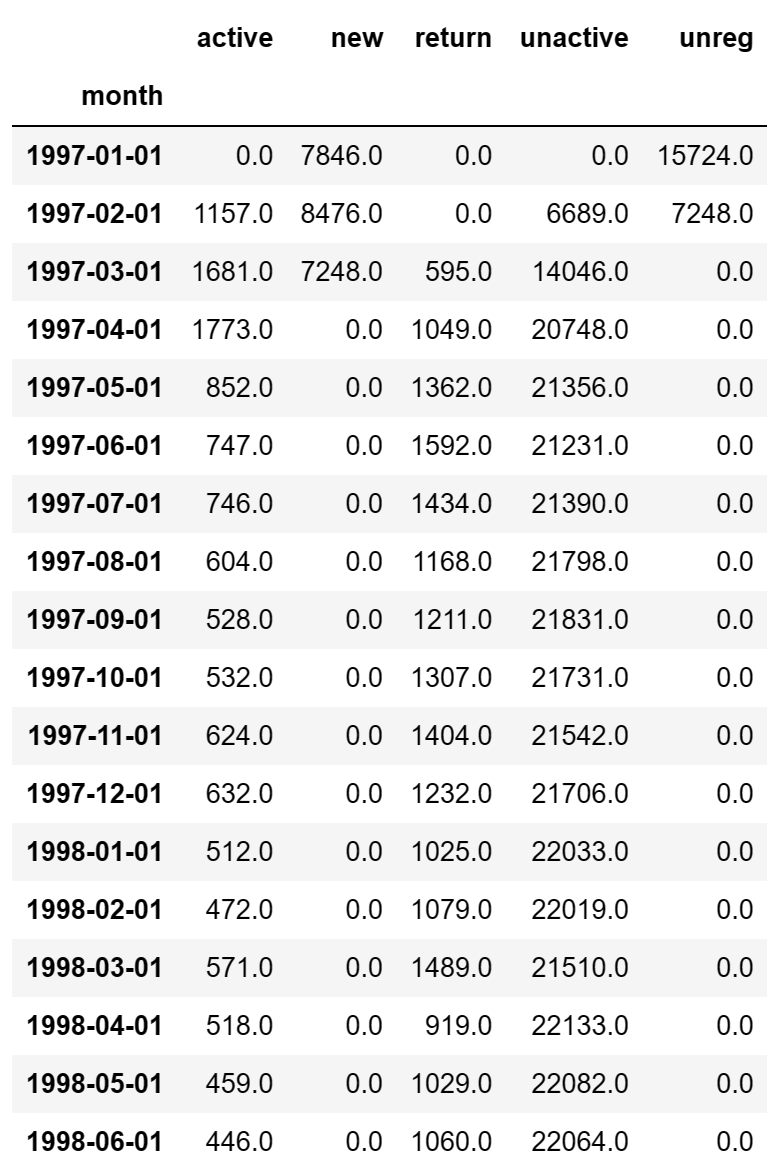
最后此篇关于解析用户消费记录(数据分析三剑客综合使用)的文章就讲到这里了,如果你想了解更多关于解析用户消费记录(数据分析三剑客综合使用)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
35
4
 0
0
1.摘要 在数据可视化、统计绘图和图表生成领域,Python 被广泛使用,其中 Matplotlib 是一个极其重要的基础三方库。本博客旨在介绍 Python 及其三方库 Matplotlib
为什么要学习pandas? numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢? numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数
0. 数据说明 本项目所用数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月。 这些数据包括有功功率、无功功率、电压、电流强度、分项计量1(厨房)、分项计量2(洗衣房
由于我现在不知道自己在做什么,所以我的措辞听起来很有趣。但是说真的,我需要学习。 我面临的问题是提出一种方法(模型)来估计软件程序的工作方式:即运行时间和最大内存使用量。我已经拥有了大量数据。此数据集
我在 PostgreSQL 中有一个表,其结构和数据如下: Question | Answer | Responses ------------------------------
numbers = LabelEncoder() State_Data['Quality'] = numbers.fit_transform(State_Data['Quality Paramet
我一直在尝试解决这个问题: 我有一组数据点,对应于一组时间值。即 values =[1,2,3,4,5,6,7,8,4] times = [0.1,0.2,0.3,0.4]... 等等,这是一个示例速
哔哔一下 雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~ 豆瓣评分5.8,说明我还是没说错它的。 当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿
在 Pandas 中是否有任何可重用的数据分析代码,可以在 html 输出中给出结果。 我已经尝试过来自以下链接的命令,但没有一个输出是 html 格式。 https://kite.com/blog/
吴京近年拍的影视都是非常富有国家情怀的,大人小孩都爱看,每次都是票房新高,最新的长津湖两部曲大家都有看吗,第一步还可以,第二部水门桥也不差,截止目前已经36.72亿票房。 某眼评分9.6,某瓣评分7.
我有一个 .csv 文件,其中包含来自 eBay 拍卖的以下数据: auctionid - 拍卖的唯一标识符 bidtime - 出价的时间(以天为单位),从拍卖开始 投标人 - 投标人的 eBay
目录 1、爬虫 1.1 爬取目标 1.2 分析页面 1.3 爬虫代码 1.4 结果数据
我是 pyspark 的新手,我有这个示例数据集: Ticker_Modelo Ticker Type Period Product Geography Source Unit

我是一名优秀的程序员,十分优秀!