
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 36
36
 4
4


CSS 样式表引入有 3种方式 : 外部样式表、内部样式表、行内样式,不同的引入方式,解码样式表的字符集原理不一样.
外部样式表由 link 标签引入,当 WebKit 解析到 link 标签时就会构造 CachedCSSStyleSheet 对象。这个对象持有 CachedResourceRequest 对象和 TextResourceDecoder 对象。CachedResourceRequest 对象负责发送请求,TextResourceDecoder 对象负责对下载回来的 CSS 数据进行解码。TextResourceDecoder 对象里面的 m_encoding 属性,就是存储着解码 CSS 数据使用的字符编码信息。相关类图如下所示
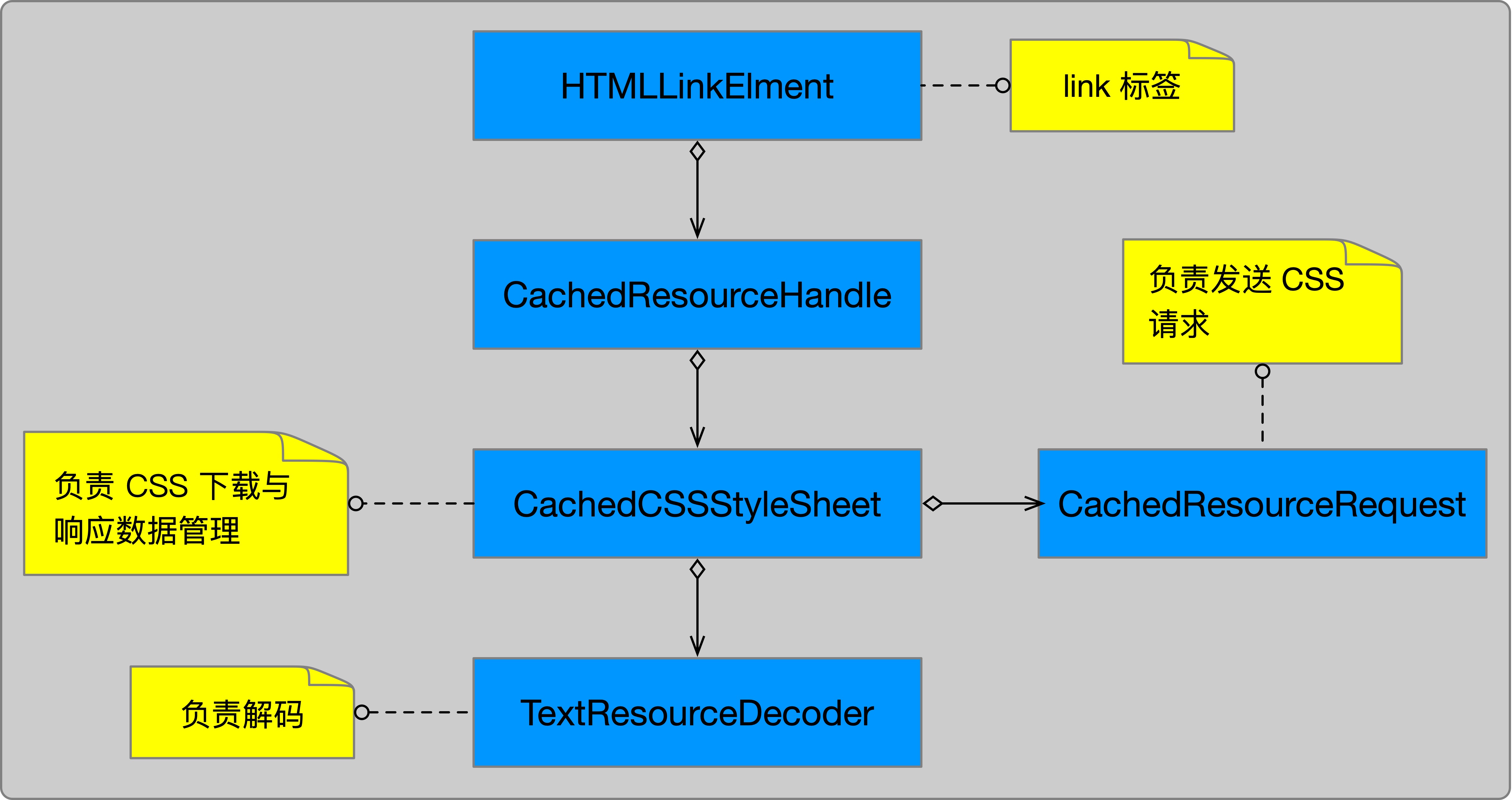
在创建 TextResourceDecoder 对象时,会传入 CachedResourceRequest 使用的字符集信息,代码如下所示
CachedCSSStyleSheet::CachedCSSStyleSheet(CachedResourceRequest&& request, PAL::SessionID sessionID,
const
CookieJar*
cookieJar)
: CachedResource(WTFMove(request), Type::CSSStyleSheet, sessionID, cookieJar)
//
1. 创建 TextResourceDecoder,传入 CachedResourceRqeuest 字符集
, m_decoder(TextResourceDecoder::create(cssContentTypeAtom(), request.charset()))
{
}
在上面代码注释 1 处,就是 CachedCSSStyleSheet 创建 TextResourceDecoder 对象,并且传入了 CachedResourceReqeust 的字符集用来初始化 TextResourceDecoder 内部的 m_encoding 属性,代码如下
inline TextResourceDecoder::TextResourceDecoder(
const
String& mimeType,
const
PAL::TextEncoding& specifiedDefaultEncoding,
bool
usesEncodingDetector)
: m_contentType(determineContentType(mimeType))
//
1. specifiedDefaultEncoding 就是传入的 CachedResourceRequest 的字符集
//
m_contentType 此时是 CSS
, m_encoding(defaultEncoding(m_contentType, specifiedDefaultEncoding))
, m_usesEncodingDetector(usesEncodingDetector)
{
}
在上面代码注释 1 处初始化 TextResourceDecoder 的 m_encoding 属性,m_contentType 此时的值是 CSS,specifiedDefaultEncoding 就是 CachedResourceRequest 的字符集。但是在初始化 m_encoding 时,并不是直接将 m_encoding 直接赋值为 specifiedDefaultEncoding,而是调用了 TextResourceDecoder::defaultEncoding 函数,相关代码如下
const
PAL::TextEncoding& TextResourceDecoder::defaultEncoding(ContentType contentType,
const
PAL::TextEncoding&
specifiedDefaultEncoding)
{
//
Despite 8.5 "Text/xml with Omitted Charset" of RFC 3023, we assume UTF-8 instead of US-ASCII
//
for text/xml. This matches Firefox.
//
1. 如果解码的是 XML ,那么无论传入的 specifiedDefaultEncoding 是什么值,都使用 UTF-8 作为默认解码字符集
if
(contentType ==
XML)
return
PAL::UTF8Encoding();
//
2. 对于其他资源类型,如果 specifiedDefaultEncoding 使用的字符集名为 null,就默认使用 Latin-1 字符集,
//
也就是 ISO-8859-1
if
(!
specifiedDefaultEncoding.isValid())
return
PAL::Latin1Encoding();
//
3. 将 specifiedDefaultEncoding 作为 TextResourceDecoder 的默认解码字符集
return
specifiedDefaultEncoding;
}
上面代码注释 1 处可以看出,TextResourceDecoder 不仅用来解码 CSS,还可以用来解码其他资源类型。如果解码的资源类型是 XML,那么默认的解码字符集就是 UTF-8.
从注释 2 处可以看到,如果不是 XML 资源类型,并且 specifiedDefaultEncoding 不合法,也就是 specifiedDefaultEncoding 内部代码字符集名的 m_name 属性为 null,那么就使用 Latin-1(也就是 ISO-8859-1) 作为 TextResourceDecoder 的默认解码字符集.
从注释 3 可以看到,对于非 XML 资源类型,specifiedDefaultEncoding 就会作为 TextResourceDecoder 的默认解码字符集。也就是会说,解码 CSS 的默认字符集和 CacheResourceRequest 使用同一个字符集.
。
那么,CacheResourceRequest 的字符集是如何来的呢?相关代码如下
void
HTMLLinkElement::process()
{
...
if
(m_disabledState != Disabled && treatAsStyleSheet && document().frame() &&
m_url.isValid()) {
//
1. 解析 link 标签的 charset 属性值
String charset =
attributeWithoutSynchronization(charsetAttr);
if
(!
PAL::TextEncoding { charset }.isValid())
//
2. 获取文档 Document 使用的字符集
charset =
document().charset();
...
//
3. 设置 CachedResourceRequest 的字符集
request.setCharset(WTFMove(charset));
...
return
;
}
...
}
上面代码注释 1 处首先解析 link 标签的 charset 属性,如果解析到就使用这个字符集作为 CachedResourceRequest 的字符集,如 注释 3所示。如果解析不到,就使用文档 Document 的字符集作为 CachedResourceReqeust 的字符集,如注释 2 所示。文档 Document 的字符集由 <meta> 标签指定,如果没有 <meta> 标签,那么文档 Document 默认使用 Latin-1 字符集(ISO-8859-1).
。
但是,解码 CSS 使用的字符集此时还并没有完全确定,因为 CSS 样式表本身支持 @charset at-rule,它可以指定解码 CSS 样式表需要使用什么字符集。因此,当从网络上下载到 CSS 样式表之后,还需要检测 CSS 样式表里面是否有 @charset at-rule,相关代码如下
String TextResourceDecoder::decode(
const
char
*
data, size_t length)
{
...
if
(m_contentType == CSS && !
m_checkedForCSSCharset)
//
1. 当下载完 CSS 样式表,这里调用 checkForCSSCharset 函数,检测样式表里是否有 @charset
if
(!
checkForCSSCharset(data, length, movedDataToBuffer))
return
emptyString();
...
}
上面代码注释 1处,当下载完 CSS 样式表使用 TextResourceDecoder 进行解码时,会调用 TextResourceDecoder::checkForCSSCharset 检测 CSS 样式表里面是否有 @charset at-rule。如果有 @charset at-rule,那么就将 TextResourceDecoder 的 m_encoding 属性值设置为 @charset 指定的字符集.
。
综上所述,对于外部引入的样式表,解码字符集的优先级为
1 如果样式表有 @charset at-rule,就优先使用 @charset 指定的字符集; 。
2 否则,就看 link 标签有没有 charset 属性,有的话就优先使用 link 标签 charset 属性指定的字符集; 。
3 否则,就使用文档 Document 的字符集.
由于内部样式表和行内样式本身就在 HTML 文件里面,因此对于它们的解码就使用 HTML 字符集。HTML 解码字符集确认规则如下
1 如果有 <meta> 标签,就使用 <meta> 标签使用的字符集; 。
2 否则,就默认使用 Latin-1(ISO-8859-1) 字符集 。
。
最后此篇关于WebKitInside:CSS样式表解码字符集的文章就讲到这里了,如果你想了解更多关于WebKitInside:CSS样式表解码字符集的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
36
4
 0
0
我有一个名为 main.css 的 css 文件和另一个名为 style.css 的文件。我怎样才能在 main.css 中做到这一点? .someClass { //apply rules to
在更新我的 css 之前,我在 Login.css 中有以下内容: body { background-image: url('./pictures/fond.png'); bac
我的 share point 2013 核心 css 和我的 css 之间存在 css 冲突。所以我想把我所有的类都放在 div #s4-workspace 下但是我搜索了一种方法来将所有类分组到这个
我知道您可以覆盖 jsp 页面从 jsp 包含 CSS 文件(即全局 CSS 文件)继承的 CSS 属性。 但是,如果元素中的某个属性弄乱了特定页面,而我不想只使用内联 CSS 在该页面中使用它怎么办
我刚刚发现了 initial-scale 元属性。 以前,我一直在使用 default.css 来定义我所有的样式和大小(用于字体和元素),以便它们在桌面计算机的屏幕上显示得很好。然后,如果您使用的是
我正在尝试使用 LESS CSS 来编写我的 CSS。我已经按顺序导入了 style.less 和 less.js 文件。 现在我想提取 LESS 生成的 CSS。有什么办法可以做到吗?我不想使用脚本
我想知道是否有任何一种软件可以读取大量内联样式中的 HTML 文档并将所有这些样式转换为外部 css 文件。如果只有一页,我可以手动完成。但是有100页。有人有想法吗? 最佳答案 就像有人说的那样,“
当我想从 Styled Components 迁移到 CSS Modules 时,出现了以下问题。 假设我有以下样式组件,它接受动态参数 offset和一个动态 CSS 字符串 theme : con
有没有办法将 CSS 类定义为与另一个类相等?例如,如果我有一个类: .myClass{ background-color: blue; } 有没有一种方法可以将第二个类定义为与 myClas
我正在尝试制作一组按钮,这些按钮贴在页面底部并且由固定的空间隔开。我正在使用 angularJS 的 ng-repeat 指令通过 ajax 请求获取数据,然后我用它来显示按钮。 我的问题在于让按
浏览器是否在加载 CSS 文件时解析 CSS?还是在整个 CSS 文件被浏览器下载后才进行解析?不同浏览器的做法有区别吗?我在哪里可以找到这种底层信息? 这个问题不是 Load and executi
这个问题在这里已经有了答案: Can a CSS class inherit one or more other classes? (29 个答案) 关闭 3 年前。 标题有点乱,我给大家看一下。假
我遇到了最奇怪的问题...... 在最简单的形式中,我有一个包含以下内容的 index.html 文件: (在尝试确定根本原因的过程中,我已经大大减少了它) 当我查看页面的源代码时,我得到以下信息:
我正在使用 Mindscape Workbench 来最小化我的 scss 文件。我的页面设置为使用 *.min.css 文件。在随机时间,min 文件不会与系统的其余部分一起发布。 我有很多 css
请告诉我 CSS 框架和 CSS 网格之间的区别。 最佳答案 CSS 框架也可以是 CSS 网格框架。 CSS 网格框架用于构建 CSS 布局。有一些框架除了构建布局还有其他用途,例如 Hartija
我有无法从页面中删除或更改的 original.css 文件。原始.css table { border-collapse: collapse; border-spacing: 0;
我以前使用 bootstrap css import 很好。 但是我正在尝试使用 CSS 模块,所以我添加了几行。 { test: /\.css$/, use:
有没有办法在 css 选择器中创建一个 css 组。 例如: .SectionHeader { include: .foo; include: .bar; include: .
今天我学习了 CSS 中的两个概念,一个是 CSS 定位(静态、相对、绝对、固定),另一个是 CSS Margin,它定义了元素之间的空间。 假设我想移动一个元素,这是最好的方法吗?因为这两个概念似乎
var paths = { css: './public/apps/user/**/*.css' } var dest = { css: './public/apps/user/css/' } /

我是一名优秀的程序员,十分优秀!