
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明.
在上篇文章中,介绍了使用tcmalloc或jemalloc定位native内存泄露的方法,但使用这个方法相当于更换了原生内存分配器,以至于使用时会有一些顾虑.
经过一些摸索,发现glibc自带的ptmalloc2分配器,也提供有追踪内存泄露的机制,即mtrace,这使得发生内存泄露时,可直接定位,而不需要额外安装及重启操作.
glibc中提供了mtrace这个函数来开启追踪内存分配的功能,开启后每次应用程序调用malloc或free函数时,会将内存分配释放操作记录在MALLOC_TRACE环境变量所指的文件里面,如下:
$ pid=`pgrep java`
# 配置gdb不调试信号,避免JVM收到信号后被gdb暂停
$ cat <<"EOF" > ~/.gdbinit
handle all nostop noprint pass
handle SIGINT stop print nopass
EOF
# 设置MALLOC_TRACE环境变量,将内存分配操作记录在malloc_trace.log里
$ gdb -q -batch -ex 'call setenv("MALLOC_TRACE", "./malloc_trace.log", 1)' -p $pid
# 调用mtrace开启内存分配追踪
$ gdb -q -batch -ex 'call mtrace()' -p $pid
# 一段时间后,调用muntrace关闭追踪
$ gdb -q -batch -ex 'call muntrace()' -p $pid
然后查看malloc_trace.log,内容如下: 可以发现,在开启mtrace后,glibc将所有malloc、free操作都记录了下来,通过从日志中找出哪些地方执行了malloc后没有free,即是内存泄露点.
于是glibc又提供了一个mtrace命令,其作用就是找出上面说的执行了malloc后没有free的记录,如下:
$ mtrace malloc_trace.log | less -n
Memory not freed:
-----------------
Address Size Caller
0x00007efe08008cc0 0x18 at 0x7efe726e8e5d
0x00007efe08008ea0 0x160 at 0x7efe726e8e5d
0x00007efe6cabca40 0x58 at 0x7efe715dc432
0x00007efe6caa9ad0 0x1bf8 at 0x7efe715e4b88
0x00007efe6caab6d0 0x1bf8 at 0x7efe715e4b88
0x00007efe6ca679c0 0x8000 at 0x7efe715e4947
# 按Caller分组统计一下,看看各Caller各泄露的次数及内存量
$ mtrace malloc_trace.log | sed '1,/Caller/d'|awk '{s[$NF]+=strtonum($2);n[$NF]++;}END{for(k in s){print k,n[k],s[k]}}'|column -t
0x7efe715e4b88 1010 7231600
0x7efe715dc432 1010 88880
0x7efe715e4947 997 32669696
0x7efe726e8e5d 532 309800
0x7efe715eb2f4 1 72
0x7efe715eb491 1 38
可以发现,0x7efe715e4b88这个调用点,泄露了1010次,那怎么知道这个调用点在哪个函数里呢?
之前我们介绍过Linux进程的虚拟内存布局,如下:
而对于JVM来说,bin/java只是一个启动进程的壳,真正的代码基本都在动态库中,如libjvm.so、libzip.so等.
而在Linux中,动态库都是直接加载的,如下: 因此,通过如下步骤,即可知道某个指令地址来自哪个函数,如下:
$ pmap -x $pid -p -A 0x7efe715e4b88
Address Kbytes RSS Dirty Mode Mapping
00007efe715d9000 108 108 0 r-x-- /opt/jdk8u222-b10/jre/lib/amd64/libzip.so
---------------- ------- ------- -------
total kB 108 163232 160716
通过pmap的-A选项,可以通过内存地址找内存映射区域,如上,Mapping列就是内存映射区域对应的动态库文件,而Address列是其在进程虚拟内存空间中的起始地址.
# 指令地址减去动态库起始地址
$ printf "%x" $((0x7efe715e4b88-0x00007efe715d9000))
bb88
$ objdump -d /opt/jdk8u222-b10/jre/lib/amd64/libzip.so | less -n
可以发现,进程地址 0x7efe715e4b88 上的指令,在 inflateInit2_ 函数中.
当然,上面步骤有点复杂,其实也可以通过gdb来查,如下:
gdb -q -batch -ex 'info symbol 0x7efe715e4b88' -p $pid
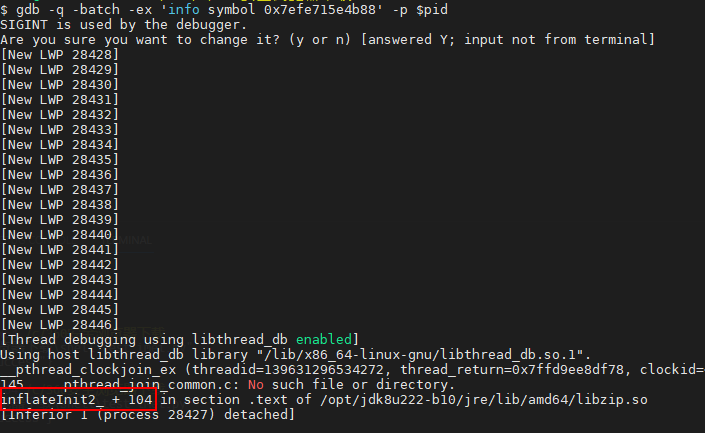
这样,我们找到了泄露的原生函数名,那是什么java代码调用到这个函数的呢?
通过arthas的profiler命令,可以采样到原生函数的调用栈,如下:
[arthas@1]$ profiler execute 'start,event=inflateInit2_,alluser'
Profiling started
[arthas@1]$ profiler stop
OK
profiler output file: .../arthas-output/20230923-173944.html
打开这个html文件,可以发现相关的Java调用栈,如下: 至此,我们堆外内存泄露的代码路径就找到了,只需要再看看代码,识别一下哪些代码路径确实会导致内存泄露即可.
注:经过测试,发现profiler其实可以直接使用指令地址,所以不转换为函数名称,也是OK的.
gdb实际是C/C++的调试程序,通过gdb来直接调用native函数,可能会出现一些不确定因素.
众所周知,Java提供了JNI机制,可实现Java调用native函数,而jna(Java Native Access)则对JNI技术进行了封装,大大简化了Java调用native函数的开发工作.
因此,我们可以使用jna来调用mtrace等native函数,如下:
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.2.2</version>
</dependency>
public class JnaTool {
public interface CLibrary extends Library {
void malloc_stats();
void malloc_trim(int pad);
void setenv(String name, String value, int overwrite);
void mtrace();
void muntrace();
}
private static CLibrary cLibrary;
static {
try {
cLibrary = (CLibrary) Native.loadLibrary("c", CLibrary.class);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void mtrace(String traceFile) {
if (cLibrary == null) return;
cLibrary.setenv("MALLOC_TRACE", traceFile, 1);
cLibrary.mtrace();
}
public static void muntrace() {
if (cLibrary == null) return;
cLibrary.muntrace();
}
public static void mallocStats() {
if (cLibrary == null) return;
cLibrary.malloc_stats();
}
public static void mallocTrim() {
if (cLibrary == null) return;
cLibrary.malloc_trim(0);
}
}
这样,就可以避免使用gdb而调用一些C库函数了😎 。
最后此篇关于使用mtrace追踪JVM堆外内存泄露的文章就讲到这里了,如果你想了解更多关于使用mtrace追踪JVM堆外内存泄露的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
我正在使用 gnu mtrace 工具来检查 C 代码中的内存泄漏。这会生成一个难以阅读的文本文件(大概是所有动态内存操作的日志),该文件可以由也称为 mtrace 的 perl 脚本解释。 我试过使
如何启用 mtrace() (和 MALLOC_TRACE env)用于没有源的二进制程序? mtrace 是 glibc 的特性:http://www.gnu.org/s/hello/manual/
我有一个程序执行 5 个 mallocs 和 3 个 free。我在开始时调用 mtrace(),在结束时调用 muntrace()。如果我正常运行程序,mtrace 将报告丢失的释放。如果我这样做:
我正在尝试使用 mtrace 检测 Fortran 程序中的内存泄漏。我正在使用 gfortran 编译器。有关 mtrace 的(工作)C 示例,请参见维基百科条目:http://en.wikipe
当我在我的 c++ 程序中使用 mtrace 时,我得到如下输出 内存未释放: Address Size Caller 0x0804a3c8 0
我是一名 c 程序员,我是 c++ 的新手。在 c 中,我们有 mtrace() 函数来跟踪有关分配和释放内存的信息。 是否有任何类似的功能可以做到这一点,但在 c++ 中。 最佳答案 mtrace不
为什么 Linux mtrace 实用程序不跟踪通过 mmap()/munmap() 调用完成的内存分配?如何实现以及实现的挑战是什么? 我需要一个可靠的工具来跟踪我的应用程序完成的内存分配,该应用程
所以我遇到了一个奇怪的问题,我希望有人能解释一下......我有以下代码: #include #include #include static void *run(void *args) {
我正在尝试调试内存泄漏问题。我正在使用 mtrace()获取 malloc/free/realloc 跟踪。我已经运行了我的程序,现在有一个巨大的日志文件。到目前为止,一切都很好。但是我在解释文件时遇

我是一名优秀的程序员,十分优秀!