
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 29
29
 4
4


在日常开发中,文件上传是常见的操作之一。文件上传技术使得用户可以方便地将本地文件上传到Web服务器上,这在许多场景下都是必需的,比如网盘上传、头像上传等.
但是当我们需要上传比较大的文件的时候,容易碰到以下问题:
这两个问题会导致上传时候的用户体验是很不好的,针对存在的这些问题,我们可以通过 分片上传 来解决,这节课我们就在学习下什么是切片上传,以及怎么实现切片上传.
分片上传的原理就像是把一个大蛋糕切成小块一样.
首先,我们将要上传的大文件分成许多小块,每个小块大小相同,比如每块大小为2MB。然后,我们逐个上传这些小块到服务器。上传的时候,可以同时上传多个小块,也可以一个一个地上传。上传每个小块后,服务器会保存这些小块,并记录它们的顺序和位置信息.
所有小块上传完成后,服务器会把这些小块按照正确的顺序拼接起来,还原成完整的大文件。最后,我们就成功地上传了整个大文件.
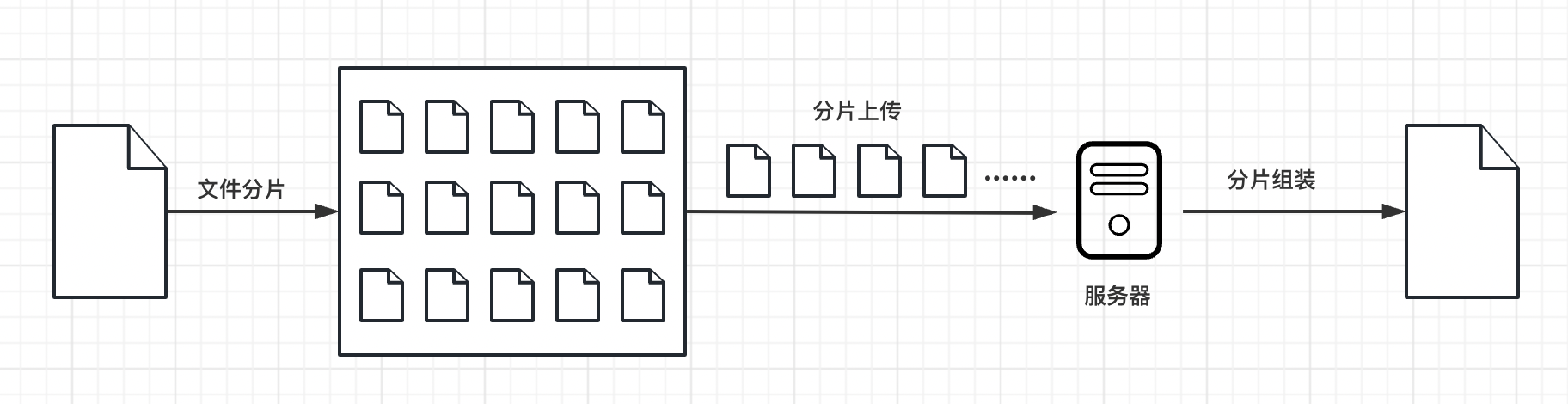
分片上传的好处在于它可以减少上传失败的风险。如果在上传过程中出现了问题,只需要重新上传出错的那个小块,而不需要重新上传整个大文件.
此外,分片上传还可以加快上传速度。因为我们可以同时上传多个小块,充分利用网络的带宽。这样就能够更快地完成文件的上传过程.
要实现大文件上传,还需要后端的支持,所以我们就用nodejs来写后端代码.
前端: vue3 + vite 。
后端: express 框架,用到的工具包: multiparty 、 fs-extra 、 cors 、 body-parser 、 nodemon 。
通过监听 input 的 change 事件,当选取了本地文件后,可以在回调函数中拿到对应的文件:
const handleUpload = (e: Event) => {
const files = (e.target as HTMLInputElement).files
if (!files) {
return
}
// 读取选择的文件
console.log(files[0]);
}
文件分片的核心是用 Blob对象的slice方法 ,我们在上一步获取到选择的文件是一个 File 对象,它是继承于 Blob ,所以我们就可以用 slice 方法对文件进行分片,用法如下:
let blob = instanceOfBlob.slice([start [, end [, contentType]]]};
start 和 end 代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。contentType 会给新的 Blob 赋予一个新的文档类型,在这里我们用不到。接下来就来使用 slice 方法来实现下对文件的分片.
const createFileChunks = (file: File) => {
const fileChunkList = []
let cur = 0
while (cur < file.size) {
fileChunkList.push({
file: file.slice(cur, cur + CHUNK_SIZE),
})
cur += CHUNK_SIZE // CHUNK_SIZE为分片的大小
}
return fileChunkList
}
先来思考一个问题,在向服务器上传文件时,怎么去区分不同的文件呢?如果根据文件名去区分的话可以吗?
答案是不可以,因为文件名我们可以是随便修改的,所以不能根据文件名去区分。但是每一份文件的文件内容都不一样,我们可以根据文件的内容去区分,具体怎么做呢?
可以根据文件内容生产一个唯一的 hash 值,大家应该都见过用 webpack 打包出来的文件的文件名都有一串不一样的字符串,这个字符串就是根据文件的内容生成的 hash 值,文件内容变化, hash 值就会跟着发生变化。我们在这里,也可以用这个办法来区分不同的文件。而且通过这个办法,我们还可以实现秒传的功能,怎么做呢?
就是服务器在处理上传文件的请求的时候,要先判断下对应文件的 hash 值有没有记录,如果A和B先后上传一份内容相同的文件,所以这两份文件的 hash 值是一样的。当A上传的时候会根据文件内容生成一个对应的 hash 值,然后在服务器上就会有一个对应的文件,B再上传的时候,服务器就会发现这个文件的 hash 值之前已经有记录了,说明之前已经上传过相同内容的文件了,所以就不用处理B的这个上传请求了,给用户的感觉就像是实现了秒传.
那么怎么计算文件的hash值呢?可以通过一个工具: spark-md5 ,所以我们得先安装它.
在上一步获取到了文件的所有切片,我们就可以用这些切片来算该文件的 hash 值,但是如果一个文件特别大,每个切片的所有内容都参与计算的话会很耗时间,所有我们可以采取以下策略:
第一个和最后一个切片的内容全部参与计算 。
中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算 。
这样就既能保证所有的切片参与了计算,也能保证不耗费很长的时间 。
/**
* 计算文件的hash值,计算的时候并不是根据所用的切片的内容去计算的,那样会很耗时间,我们采取下面的策略去计算:
* 1. 第一个和最后一个切片的内容全部参与计算
* 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算
* 这样做会节省计算hash的时间
*/
const calculateHash = async (fileChunks: Array<{file: Blob}>) => {
return new Promise(resolve => {
const spark = new sparkMD5.ArrayBuffer()
const chunks: Blob[] = []
fileChunks.forEach((chunk, index) => {
if (index === 0 || index === fileChunks.length - 1) {
// 1. 第一个和最后一个切片的内容全部参与计算
chunks.push(chunk.file)
} else {
// 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算
// 前面的2字节
chunks.push(chunk.file.slice(0, 2))
// 中间的2字节
chunks.push(chunk.file.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2))
// 后面的2字节
chunks.push(chunk.file.slice(CHUNK_SIZE - 2, CHUNK_SIZE))
}
})
const reader = new FileReader()
reader.readAsArrayBuffer(new Blob(chunks))
reader.onload = (e: Event) => {
spark.append(e?.target?.result as ArrayBuffer)
resolve(spark.end())
}
})
}
前面已经完成了上传的前置操作,接下来就来看下如何去上传这些切片.
我们以1G的文件来分析,假如每个分片的大小为1M,那么总的分片数将会是1024个,如果我们同时发送这1024个分片,浏览器肯定处理不了,原因是切片文件过多,浏览器一次性创建了太多的请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。因此,我们有必要限制前端请求个数.
怎么做呢,我们要创建最大并发数的请求,比如6个,那么同一时刻我们就允许浏览器只发送6个请求,其中一个请求有了返回的结果后我们再发起一个新的请求,依此类推,直至所有的请求发送完毕.
上传文件时一般还要用到 FormData 对象,需要将我们要传递的文件还有额外信息放到这个 FormData 对象里面.
const uploadChunks = async (fileChunks: Array<{file: Blob}>) => {
const data = fileChunks.map(({ file }, index) => ({
fileHash: fileHash.value,
index,
chunkHash: `${fileHash.value}-${index}`,
chunk: file,
size: file.size,
}))
const formDatas = data
.map(({ chunk, chunkHash }) => {
const formData = new FormData()
// 切片文件
formData.append('chunk', chunk)
// 切片文件hash
formData.append('chunkHash', chunkHash)
// 大文件的文件名
formData.append('fileName', fileName.value)
// 大文件hash
formData.append('fileHash', fileHash.value)
return formData
})
let index = 0;
const max = 6; // 并发请求数量
const taskPool: any = [] // 请求队列
while(index < formDatas.length) {
const task = fetch('http://127.0.0.1:3000/upload', {
method: 'POST',
body: formDatas[index],
})
task.then(() => {
taskPool.splice(taskPool.findIndex((item: any) => item === task))
})
taskPool.push(task);
if (taskPool.length === max) {
// 当请求队列中的请求数达到最大并行请求数的时候,得等之前的请求完成再循环下一个
await Promise.race(taskPool)
}
index ++
percentage.value = (index / formDatas.length * 100).toFixed(0)
}
await Promise.all(taskPool)
}
后端我们处理文件时需要用到 multiparty 这个工具,所以也是得先安装,然后再引入它.
我们在处理每个上传的分片的时候,应该先将它们临时存放到服务器的一个地方,方便我们合并的时候再去读取。为了区分不同文件的分片,我们就用文件对应的那个hash为文件夹的名称,将这个文件的所有分片放到这个文件夹中.
// 所有上传的文件存放到该目录下
const UPLOAD_DIR = path.resolve(__dirname, 'uploads');
// 处理上传的分片
app.post('/upload', async (req, res) => {
const form = new multiparty.Form();
form.parse(req, async function (err, fields, files) {
if (err) {
res.status(401).json({
ok: false,
msg: '上传失败'
});
}
const chunkHash = fields['chunkHash'][0]
const fileName = fields['fileName'][0]
const fileHash = fields['fileHash'][0]
// 存储切片的临时文件夹
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目录不存在,则创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir)
}
const oldPath = files.chunk[0].path;
// 把文件切片移动到我们的切片文件夹中
await fse.move(oldPath, path.resolve(chunkDir, chunkHash))
res.status(200).json({
ok: true,
msg: 'received file chunk'
});
});
});
写完前后端代码后就可以来试下看看文件能不能实现切片的上传,如果没有错误的话,我们的 uploads 文件夹下应该就会多一个文件夹,这个文件夹里面就是存储的所有文件的分片了.
上一步我们已经实现了将所有切片上传到服务器了,上传完成之后,我们就可以将所有的切片合并成一个完整的文件了,下面就一块来实现下.
前端只需要向服务器发送一个合并的请求,并且为了区分要合并的文件,需要将文件的hash值给传过去 。
/**
* 发请求通知服务器,合并切片
*/
const mergeRequest = () => {
// 发送合并请求
fetch('http://127.0.0.1:3000/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
size: CHUNK_SIZE,
fileHash: fileHash.value,
fileName: fileName.value,
}),
})
.then((response) => response.json())
.then(() => {
alert('上传成功')
})
}
在之前已经可以将所有的切片上传到服务器并存储到对应的目录里面去了,合并的时候需要从对应的文件夹中获取所有的切片,然后利用文件的读写操作,就可以实现文件的合并了。合并完成之后,我们将生成的文件以hash值命名存放到对应的位置就可以了.
// 提取文件后缀名
const extractExt = filename => {
return filename.slice(filename.lastIndexOf('.'), filename.length)
}
/**
* 读的内容写到writeStream中
*/
const pipeStream = (path, writeStream) => {
return new Promise((resolve, reject) => {
// 创建可读流
const readStream = fse.createReadStream(path)
readStream.on('end', async () => {
fse.unlinkSync(path)
resolve()
})
readStream.pipe(writeStream)
})
}
/**
* 合并文件夹中的切片,生成一个完整的文件
*/
async function mergeFileChunk(filePath, fileHash, size) {
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
const chunkPaths = await fse.readdir(chunkDir)
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => {
return a.split('-')[1] - b.split('-')[1]
})
const list = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
})
await Promise.all(list)
// 文件合并后删除保存切片的目录
fse.rmdirSync(chunkDir)
}
// 合并文件
app.post('/merge', async (req, res) => {
const { fileHash, fileName, size } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
// 如果大文件已经存在,则直接返回
if (fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
msg: '合并成功'
});
return
}
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 切片目录不存在,则无法合并切片,报异常
if (!fse.existsSync(chunkDir)) {
res.status(200).json({
ok: false,
msg: '合并失败,请重新上传'
});
return
}
await mergeFileChunk(filePath, fileHash, size)
res.status(200).json({
ok: true,
msg: '合并成功'
});
});
到这里,我们就已经实现了大文件的分片上传的基本功能了,但是我们没有考虑到如果上传相同的文件的情况,而且如果中间网络断了,我们就得重新上传所有的分片,这些情况在大文件上传中也都需要考虑到,下面,我们就来解决下这两个问题.
我们在上面有提到,如果内容相同的文件进行hash计算时,对应的hash值应该是一样的,而且我们在服务器上给上传的文件命名的时候就是用对应的hash值命名的,所以在上传之前是不是可以加一个判断,如果有对应的这个文件,就不用再重复上传了,直接告诉用户上传成功,给用户的感觉就像是实现了秒传。接下来,就来看下如何实现的.
前端在上传之前,需要将对应文件的hash值告诉服务器,看看服务器上有没有对应的这个文件,如果有,就直接返回,不执行上传分片的操作了.
/**
* 验证该文件是否需要上传,文件通过hash生成唯一,改名后也是不需要再上传的,也就相当于秒传
*/
const verifyUpload = async () => {
return fetch('http://127.0.0.1:3000/verify', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
fileName: fileName.value,
fileHash: fileHash.value
})
})
.then((response) => response.json())
.then((data) => {
return data; // data中包含对应的表示服务器上有没有该文件的查询结果
});
}
// 点击上传事件
const handleUpload = async (e: Event) => {
// ...
// uploadedList已上传的切片的切片文件名称
const res = await verifyUpload()
const { shouldUpload } = res.data
if (!shouldUpload) {
// 服务器上已经有该文件,不需要上传
alert('秒传:上传成功')
return;
}
// 服务器上不存在该文件,继续上传
uploadChunks(fileChunks)
}
因为我们在合并文件时,文件名时根据该文件的hash值命名的,所以只需要看看服务器上有没有对应的这个hash值的那个文件就可以判断了.
// 根据文件hash验证文件有没有上传过
app.post('/verify', async (req, res) => {
const { fileHash, fileName } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
if (fse.existsSync(filePath)) {
// 文件存在服务器中,不需要再上传了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
}
});
} else {
// 文件不在服务器中,就需要上传
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
}
});
}
});
完成上面的步骤后,当我们再上传相同的文件,即使改了文件名,也会提示我们秒传成功了,因为服务器上已经有对应的那个文件了.
上面我们解决了重复上传的文件,但是对于网络中断需要重新上传的问题没有解决,那该如何解决呢?
如果我们之前已经上传了一部分分片了,我们只需要再上传之前拿到这部分分片,然后再过滤掉是不是就可以避免去重复上传这些分片了,也就是只需要上传那些上传失败的分片,所以,再上传之前还得加一个判断.
我们还是在那个 verify 的接口中去获取已经上传成功的分片,然后在上传分片前进行一个过滤 。
const uploadChunks = async (fileChunks: Array<{file: Blob}>, uploadedList: Array<string>) => {
const formDatas = fileChunks
.filter((chunk, index) => {
// 过滤服务器上已经有的切片
return !uploadedList.includes(`${fileHash.value}-${index}`)
})
.map(({ file }, index) => {
const formData = new FormData()
// 切片文件
formData.append('file', file)
// 切片文件hash
formData.append('chunkHash', `${fileHash.value}-${index}`)
// 大文件的文件名
formData.append('fileName', fileName.value)
// 大文件hash
formData.append('fileHash', fileHash.value)
return formData
})
// ...
}
只需要在 /verify 这个接口中加上已经上传成功的所有切片的名称就可以,因为所有的切片都存放在以文件的hash值命名的那个文件夹,所以需要读取这个文件夹中所有的切片的名称就可以.
/**
* 返回已经上传切片名
* @param {*} fileHash
* @returns
*/
const createUploadedList = async fileHash => {
return fse.existsSync(path.resolve(UPLOAD_DIR, fileHash))
? await fse.readdir(path.resolve(UPLOAD_DIR, fileHash)) // 读取该文件夹下所有的文件的名称
: []
}
// 根据文件hash验证文件有没有上传过
app.post('/verify', async (req, res) => {
const { fileHash, fileName } = req.body
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)
if (fse.existsSync(filePath)) {
// 文件存在服务器中,不需要再上传了
res.status(200).json({
ok: true,
data: {
shouldUpload: false,
}
});
} else {
// 文件不在服务器中,就需要上传,并且返回服务器上已经存在的切片
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
uploadedList: await createUploadedList(fileHash)
}
});
}
});
最后此篇关于每日一题:吃透大文件上传问题(附可运行的前后端源码)的文章就讲到这里了,如果你想了解更多关于每日一题:吃透大文件上传问题(附可运行的前后端源码)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
29
4
 0
0
关闭。这个问题是off-topic .它目前不接受答案。 想要改进这个问题? Update the question所以它是on-topic用于堆栈溢出。 关闭 12 年前。 Improve thi
我有一个动态网格,其中的数据功能需要正常工作,这样我才能逐步复制网格中的数据。假设在第 5 行中,我输入 10,则从第 6 行开始的后续行应从 11 开始读取,依此类推。 如果我转到空白的第一行并输入
我有一个关于我的按钮消失的问题 我已经把一个图像作为我的按钮 用这个函数动画 function example_animate(px) { $('#cont
我有一个具有 Facebook 连接和经典用户名/密码登录的网站。目前,如果用户单击 facebook_connect 按钮,系统即可运行。但是,我想将现有帐户链接到 facebook,因为用户可以选
我有一个正在为 iOS 开发的应用程序,该应用程序执行以下操作 加载和设置注释并启动核心定位和缩放到位置。 map 上有很多注释,从数据加载不会花很长时间,但将它们实际渲染到 map 上需要一段时间。
我被推荐使用 Heroku for Ruby on Rails 托管,到目前为止,我认为我真的会喜欢它。只是想知道是否有人可以帮助我找出问题所在。 我按照那里的说明在该网站上创建应用程序,创建并提交
我看过很多关于 SSL 错误的帖子和信息,我自己也偶然发现了一个。 我正在尝试使用 GlobalSign CA BE 证书通过 Android WebView 访问网页,但出现了不可信错误。 对于大多
我想开始使用 OpenGL 3+ 和 4,但我在使用 Glew 时遇到了问题。我试图将 glew32.lib 包含在附加依赖项中,并且我已将库和 .dll 移动到主文件夹中,因此不应该有任何路径问题。
我已经盯着这两个下载页面的源代码看了一段时间,但我似乎找不到问题。 我有两个下载页面,一个 javascript 可以工作,一个没有。 工作:http://justupload.it/v/lfd7不是
我一直在使用 jQuery,只是尝试在单击链接时替换文本字段以及隐藏/显示内容项。它似乎在 IE 中工作得很好,但我似乎无法让它在 FF 中工作。 我的 jQuery: $(function() {
我正在尝试为 NDK 编译套接字库,但出现以下两个错误: error: 'close' was not declared in this scope 和 error: 'min' is not a m
我正在使用 Selenium 浏览器自动化框架测试网站。在测试过程中,我切换到特定的框架,我们将其称为“frame_1”。后来,我在 Select 类中使用了 deselectAll() 方法。不久之
我正在尝试通过 Python 创建到 Heroku PostgreSQL 数据库的连接。我将 Windows10 与 Python 3.6.8 和 PostgreSQL 9.6 一起使用。 我从“ht
我有一个包含 2 列的数据框,我想根据两列之间的比较创建第三列。 所以逻辑是:第 1 列 val = 3,第 2 列 val = 4,因此新列值什么都没有 第 1 列 val = 3,第 2 列 va
我想知道如何调试 iphone 5 中的 css 问题。 我尝试使用 firelite 插件。但是从纵向旋转到横向时,火石占据了整个屏幕。 有没有其他方法可以调试 iphone 5 中的 css 问题
所以我有点难以理解为什么这不起作用。我正在尝试替换我正在处理的示例站点上的类别复选框。我试图让它做以下事情:未选中时以一种方式出现,悬停时以另一种方式出现(选中或未选中)选中时以第三种方式出现(而不是
Javascript CSS 问题: 我正在使用一个文本框来写入一个 div。我使用以下 javascript 获取文本框来执行此操作: function process_input(){
你好,我很难理解 P、NP 和多项式时间缩减的主题。我试过在网上搜索它并问过我的一些 friend ,但我没有得到任何好的答案。 我想问一个关于这个话题的一般性问题: 设 A,B 为 P 中的语言(或
你好,我一直在研究 https://leetcode.com/problems/2-keys-keyboard/并想到了这个动态规划问题。 您从空白页上的“A”开始,完成后得到一个数字 n,页面上应该
我正在使用 Cocoapods 和 KIF 在 Xcode 服务器上运行持续集成。我已经成功地为一个项目设置了它来报告每次提交。我现在正在使用第二个项目并收到错误: Bot Issue: warnin

我是一名优秀的程序员,十分优秀!