
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 39
39
 4
4


下面的系列文章记录了如何使用一块linux开发扳和一块OLED屏幕实现视频的播放
这是此系列文章的第3篇, 主要总结和记录了如何使用cuda编程释放GPU的算力. 在此之前尝试过使用python调用opencv直接处理视频数据, 但使用之后发现处理过程效率不高, 处理时间偏长. 后来想到还有一块显卡没利用起来, 毕竟在前司见证了某国产GPGPU芯片从立项, 到流片再到回片验证的整个过程, cuda编程也算是传统艺能了. 最终效果看下面的视频
跳转到6:48, 直接观看演示 。
这里不会介绍cuda的编程模型, cuda开发工具的使用等, 这部分内容可以参考 cuda的官方文档 , 学习cuda编程的话, 看这个文档就足够了. 。
原始的视频文件, 每帧画面的分辨率一般不会和我们的屏幕尺寸128x64匹配, 并且视频是彩色的, 使用的OLED屏幕只能显示黑白图像. 所以视频的数据必须经过resize和灰度处理之后才能发送给beaglebone black板子连接的OLED屏幕, 这部分视频处理工作就是在GPU上进行的. 。
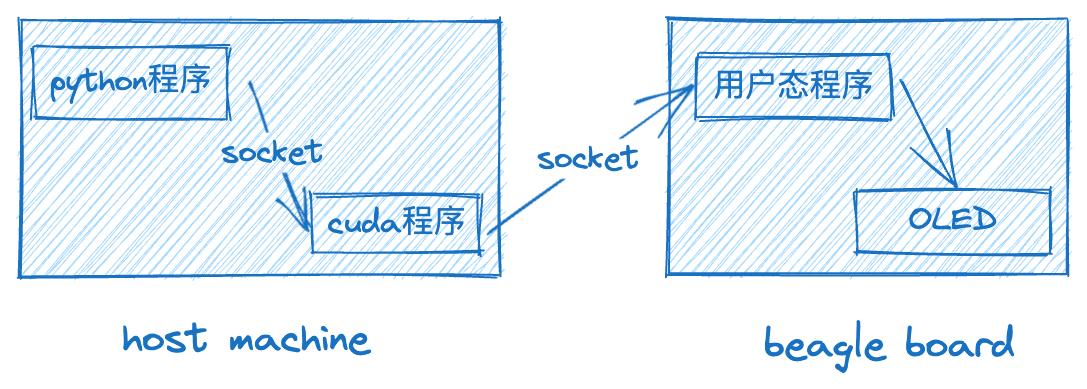
在host machine上的python程序使用opencv读取视频文件中的每一帧, 通过socket发送给cuda程序; cuda程序处理完数据之后, 再通过socket把数据发送给beagle board上的用户态程序; beagle board上的用户态程序, 把一帧数据写入屏幕, 完成绘制. 。
下面是kernel函数的部分代码, oframe, ow, oh, 分别表示原始画面数据, 原始的宽度和高度, nframe, nw, nh分别表示处理之后的画面数据, 新的宽度和高度. 。
kernel中的resize操作, 使用最近临方式, (i, j)是新画面中的像素位置, 计算得到对应的原始画面像素位置(oi, oj), 取出原始的rgb值, 使用公式计算出亮度, 最后根据阈值确定(i, j)这个像素的亮灭. 。
__global__ void resize_frame_kernel(unsigned char *oframe, int ow, int oh,
unsigned char *nframe, int nw, int nh,
int threshold, unsigned int *locks)
{
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i < nw;
i += blockDim.x * gridDim.x) {
for (int j = blockDim.y * blockIdx.y + threadIdx.y; j < nh;
j += blockDim.y * gridDim.y) {
int oi = i * ow / nw;
int oj = j * oh / nh;
unsigned char b = oframe[oj * ow * 3 + oi * 3];
unsigned char g = oframe[oj * ow * 3 + oi * 3 + 1];
unsigned char r = oframe[oj * ow * 3 + oi * 3 + 2];
unsigned char brightness =
r * 0.3 + g * 0.59 + b * 0.11;
brightness = brightness >= threshold ? 1 : 0;
brightness = brightness << (j % 8);
// 以下代码实现了一个自旋锁
bool leaveloop = false;
while (!leaveloop) {
if (atomicExch(&locks[j / 8 * nw + i], 1u) ==
0u) {
nframe[j / 8 * nw + i] |= brightness;
leaveloop = true;
atomicExch(&locks[j / 8 * nw + i], 0u);
}
}
}
}
}
在上面的代码清单中使用原子交换指令atomicExch实现了一个自旋锁. 在kernel函数中使用锁是因为, nframe的大小是128x8字节, 屏幕分辨率是128x64, nframe的每个bit控制一个像素, 当kernel中更新nframe时, 可能同时有多个线程想更新nframe中的同一个字节. 关于这个自选锁中while循环的写法, 可以参考 stack overflow . 。
欢迎关注我的 B站账号 , 或者加入 QQ群838923389 , 一起研究计算机底层技术, 一起搞事情:P 。
最后此篇关于用OLED屏幕播放视频(3):使用cuda编程加速视频处理的文章就讲到这里了,如果你想了解更多关于用OLED屏幕播放视频(3):使用cuda编程加速视频处理的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
39
4
 0
0
我做了一个项目,使用两个不同的textview进行触摸来播放两个音频。 这是一个文本 View 的简单代码 tv.setOnTouchListener(new OnTouchListener() {
我正在使用 pygame 模块在 python 中操作声音文件。它在交互式 python session 中工作正常,但相同的代码在 bash 中不会产生任何结果: 交互式Python $ sudo
请注意它只能是 JavaScript。请参阅下面我当前的 HTML。我需要像当前代码一样在页面之间旋转。但是,我需要能够在页面之间暂停/播放。
我有一个带有一堆音频链接的html。我正在尝试使所有音频链接都在单击时播放/暂停,并且尝试了here解决方案。这正是我所追求的,只是我现在不得不修改此功能以应用于代码中的所有音频链接(因为我不能为每个
在尝试进入我的代码中的下一个文件之前,我尝试随机播放.wav文件数毫秒。最好的方法是什么? 我目前有以下代码: #!/usr/bin/env python from random import ran
我有2个回调函数,一个播放音频,另一个停止音频。 function Play_Callback(hObject, eventdata, handles) global path; global pla
我有一个电台应用程序,并与carplay集成。在Carplay仪表板中,我仅看到专辑封面图像和停止按钮。我想在仪表板上显示播放/暂停和跳过按钮。如果您对该站有任何了解,可以帮我吗? 最佳答案 您需要使
我正在使用 ffmpeg 创建一个非常基本的视频播放器。库,我有所有的解码和重新编码,但我坚持音频视频同步。 我的问题是,电影有音频和视频流混合(交织),音频和视频以“突发”(多个音频包,然后是并列的
我不知道我在做什么错 $(document).ready(function() { var playing = false; var audioElement = document.
我正在尝试通过(input:file)Elem加载本地音频文件,当我将其作为对象传递给音频构造函数Audio()时,它不会加载/播放。 文件对象参数和方法: lastModified: 1586969
在 Qt 中创建播放/暂停按钮的最佳方法是什么?我应该创建一个操作并在单击时更改其图标,还是应该创建两个操作然后以某种方式在单击时隐藏一个操作?如何使用一个快捷键来激活这两个操作? (播放时暂停,暂停
我正在用 Python 和 SQLite 构建一个预订系统。 我有一个 Staff.db 和 Play.db (一对多关系)。这个想法是这样的:剧院的唯一工作人员可以通过指定开始日期和时间来选择何时添
我有一个服务于 AAC+ (HE v2) 的 Icecast 服务器。我在我的网页中使用 JPlayer 来播放内容。在没有 Flash Player 的 Chromium 中,它工作得很好。 对于支
当我运行我的方法时,我收到一个MediaException。我使用 playSound("src/assets/timeup.mp3"); 调用该方法。 private void playSound(
我有一项正在播放播客的服务。我希望该服务检测用户何时按下暂停或从他们的 BT radio 播放,以便我可以停止和启动它。对于我的生活,我无法弄清楚要向我的监听器添加什么过滤器(当我按下 BT 按钮时,
我对 Java 不是很在行,在研究网站上的音乐循环的简单播放/暂停按钮后,我得到了这段代码。它可以很好地离线测试,但在上传到 FTP 服务器后,它不会在任何浏览器中播放音频,我得到 SyntaxErr
我有一个使用 flickity carousel library 创建的视频轮播, 见过 here on codepen .我想要发生的是,当用户滑动轮播时,所选幻灯片停止播放,然后占据所选中间位置的
这是一个 JSFiddle: http://jsfiddle.net/8LczkwLz/19/ HTML: JS: var flashcardAudio = documen
我的问题是我无法将歌曲标题文本保持在 line-height: 800px;当用户播放或暂停播放器时。我设法在 :hover 上做到了。这似乎是一件非常棘手的事情,这真的是我第一次遇到 CSS 如此困
我还没有找到与我的完全一样的帖子,所以这就是问题所在。我正在制作一个 mp3 播放器,播放/暂停是两个单独的按钮。这是我的代码。 prevButton = document.getElementByI

我是一名优秀的程序员,十分优秀!