
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 36
36
 4
4


最近人工智能大火,AI 应用所涉及的技术能力包括语音、图像、视频、NLP 等多方面,而这些都需要强大的计算资源支持。AI 技术对算力的需求是非常庞大的,虽然 GPU 的计算能力在持续提升,但是对于 AI 来说,单卡的计算能力就算再强,也是有极限的,这就需要多 GPU 组合。而 GPU 多卡的组合,主要分为单个服务器多张 GPU 卡和多个服务器,每个服务器多张卡这两种情况,无论是单机多卡还是多机多卡,GPU 之间需要有超强的通信支持。接下来,我们就来聊聊 GPU 通信技术.
GPU Direct 是 NVIDIA 开发的一项技术,可实现 GPU 与其他设备(例如网络接口卡 (NIC) 和存储设备)之间的直接通信和数据传输,而不涉及 CPU.
传统上,当数据需要在 GPU 和另一个设备之间传输时,数据必须通过 CPU,从而导致潜在的瓶颈并增加延迟。使用 GPUDirect,网络适配器和存储驱动器可以直接读写 GPU 内存,减少不必要的内存消耗,减少 CPU 开销并降低延迟,从而显著提高性能。GPU Direct 技术包括 GPUDirect Storage、GPUDirect RDMA、GPUDirect P2P 和 GPUDirect 视频.
GPUDirect Storage 允许存储设备和 GPU 之间进行直接数据传输,绕过 CPU,减少数据传输的延迟和 CPU 开销.
通过 GPUDirect Storage,GPU 可以直接从存储设备(如固态硬盘(SSD)或非易失性内存扩展(NVMe)驱动器)访问数据,而无需将数据先复制到 CPU 的内存中。这种直接访问能够实现更快的数据传输速度,并更高效地利用 GPU 资源.
GPUDirect Storage 的主要特点和优势包括:
某些工作负载需要位于同一服务器中的两个或多个 GPU 之间进行数据交换,在没有 GPUDirect P2P 技术的情况下,来自 GPU 的数据将首先通过 CPU 和 PCIe 总线复制到主机固定的共享内存。然后,数据将通过 CPU 和 PCIe 总线从主机固定的共享内存复制到目标 GPU,数据在到达目的地之前需要被复制两次.

有了 GPUDirect P2P 通信技术后,将数据从源 GPU 复制到同一节点中的另一个 GPU 不再需要将数据临时暂存到主机内存中。如果两个 GPU 连接到同一 PCIe 总线,GPUDirect P2P 允许访问其相应的内存,而无需 CPU 参与。前者将执行相同任务所需的复制操作数量减半.
在 GPUDirect P2P 技术中,多个 GPU 通过 PCIe 直接与 CPU 相连,而 PCIe3.0*16 的双向带宽不足 32GB/s,当训练数据不断增长时,PCIe 的带宽满足不了需求,会逐渐成为系统瓶颈。为提升多 GPU 之间的通信性能,充分发挥 GPU 的计算性能,NVIDIA 于 2016 年发布了全新架构的 NVLink。NVLink 是一种高速、高带宽的互连技术,用于连接多个 GPU 之间或连接 GPU 与其他设备(如CPU、内存等)之间的通信。NVLink 提供了直接的点对点连接,具有比传统的 PCIe 总线更高的传输速度和更低的延迟.
NVSwitch 。
NVLink 技术无法使单服务器中 8 个 GPU 达到全连接,为解决该问题,NVIDIA 在 2018 年发布了 NVSwitch,实现了 NVLink 的全连接。NVIDIA NVSwitch 是首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别达到 300GB/s 的速度同时进行通信.
△ NVSwitch 全连接拓扑 。
AI 计算对算力需求巨大,多机多卡的计算是一个常态,多机间的通信是影响分布式训练的一个重要指标。在传统的 TCP/IP 网络通信中,数据发送方需要将数据进行多次内存拷贝,并经过一系列的网络协议的数据包处理工作;数据接收方在应用程序中处理数据前,也需要经过多次内存拷贝和一系列的网络协议的数据包处理工作。经过这一系列的内存拷贝、数据包处理以及网络传输延时等,服务器间的通信时延往往在毫秒级别,不能够满足多机多卡场景对于网络通信的需求.
RDMA(Remote Direct Memory Access)是一种绕过远程主机而访问其内存中数据的技术,解决网络传输中数据处理延迟而产生的一种远端内存直接访问技术.
目前 RDMA 有三种不同的技术实现方式:
GPUDirect RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介.
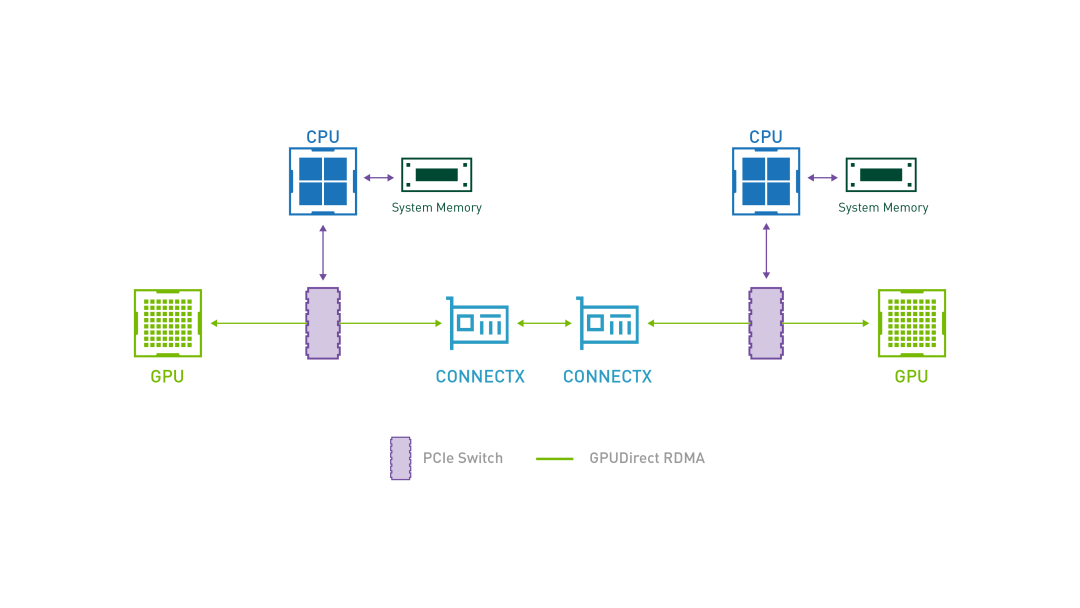
GPUDirect RDMA 通过绕过主机内存和 CPU,直接在 GPU 和 RDMA 网络设备之间进行数据传输,显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。另外,GPUDirect RDMA 技术允许 GPU 直接访问 RDMA 网络设备中的数据,避免了数据在主机内存中的复制,提高了数据传输的带宽利用率 。
IPOIB(IP over InfiniBand)是一种在 InfiniBand 网络上运行 IP 协议的技术。它将标准的 IP 协议栈与 IB 互连技术相结合,使得在 IB 网络上的节点能够使用 IP 协议进行通信和数据传输.
IPOIB 提供了基于 RDMA 之上的 IP 网络模拟层,允许应用无修改的运行在 IB 网络上。但是,IPoIB 仍然经过内核层(IP Stack),会产生大量系统调用,并且涉及 CPU 中断,因此 IPoIB 性能比 RDMA 通信方式性能要低,大多数应用都会采用 RDMA 方式获取高带宽低延时的收益,少数的关键应用会采用 IPoIB 方式通信.
在大规模计算中,单机多卡场景下使用 GPUDiect、NVLink 技术,分布式场景下使用 GPUDirect RDMA 技术,可以大大缩短通信时间,提升整体性能.
如果你对 GPU 相关技术感兴趣,你可以用它尝试搭建 AI 绘画平台或者做一些推理的工作。AI 绘画搭建的教程我先放在这里啦:《 从 0 到 1,带你玩转 AI 绘画 》 。
最后此篇关于聊透GPU通信技术——GPUDirect、NVLink、RDMA的文章就讲到这里了,如果你想了解更多关于聊透GPU通信技术——GPUDirect、NVLink、RDMA的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
36
4
 0
0
我是高性能计算 (HPC) 方面的新手,但我将有一个 HPC 项目,因此我需要一些帮助来解决一些基本问题。 应用场景很简单:通过InfiniBand(IB)网络连接几台服务器,一台服务器做Master
我正在尝试在 Azure 上的 A8 计算机上使用 InfiniBand。实际上,乒乓测试工作正常,但是我无法运行基于 RDMA 的简单程序。我可以通过 ibv_get_device_list(NUL
我正在尝试在 Azure 上的 A8 计算机上使用 InfiniBand。实际上,乒乓测试工作正常,但是我无法运行基于 RDMA 的简单程序。我可以通过 ibv_get_device_list(NUL
我正在为我的应用程序使用 Infiniband 驱动程序的 OFED 3.18r2 实现。特别是我正在使用 rdma 连接管理器包装函数。为了更好地理解幕后发生的事情,我习惯于查看源代码。这样做我发现
infiniband (RDMA) 的最大电缆长度是多少? 例如。这里已经说过,对于四 channel 铜缆可以达到 10 M 。并使用光纤连接电缆,与标准 InfiniBand 4x 和以太网 10
我的问题很简单:如果计算机的CPU / OS发生故障,是否仍可以通过远程计算机的远程直接内存访问(RDMA)使用其内存? 最佳答案 这实际上取决于系统遇到的故障类型。如果操作系统出现故障,则实施RDM
这个问题已经有答案了: How to use GPUDirect RDMA with Infiniband (1 个回答) 已关闭 6 年前。 是否可以在 GPU 和远程主机之间执行 RDMA 操作?
我正在尝试构建 perftest C library通过 RDMA 协议(protocol)运行一些延迟测试。 我的步骤: 我从 their GitHub 下载了库并将其解压缩到我要运行测试服务器的盒
我正在浏览 linux/drivers/net/ethernet/mellanox/mlx4/qp.c 有几个问题。如果有人能澄清一下,我将不胜感激: 函数中,mlx4_qp_alloc_icm, 要
RDMA 是绕过应用程序和操作系统内核之间无用数据拷贝的有效方法。 Mmap 是处理大文件的有效方法,就好像它只是一个字节数组一样。 我正在使用支持进程间 RDMA 网络操作的 Infiniband
我正在尝试构建和运行 RDMA 示例 here .但是因为我只是在探索,所以我没有任何能够管理 RDMA 的硬件。当我尝试运行示例代码时出现这样的错误。 librdmacm: couldn't rea
在我的应用程序中,我使用无限带宽基础设施将数据流从一台服务器发送到另一台服务器。我习惯于通过 infiniband 轻松开发 ip,因为我更熟悉套接字编程。到目前为止,性能(最大带宽)对我来说已经足够
最近人工智能大火,AI 应用所涉及的技术能力包括语音、图像、视频、NLP 等多方面,而这些都需要强大的计算资源支持。AI 技术对算力的需求是非常庞大的,虽然 GPU 的计算能力在持续提升,但是对于 A
我在Azure上购买了1台H16r虚拟机,并在“About H-series and compute-intensive A-series VMs”上尝试了RDMA的设置方法: azure confi
是否可以在不使用 IPoIB 的情况下通过 native InfiniBand 使用 RDMA(仅使用 guid 或 lit)? 我查过Infiniband addressing - host nam
Linux 命令 ibstat 和 ibv_devinfo 的手册页说 ibstat - query basic status of InfiniBand device(s) ibv_devinfo
我的小组(一个名为 Isis2 的项目)正在试验 RDMA。我们对缺乏单方面 RDMA 读取的原子性保证的文档感到困惑。在过去的一个半小时里,我一直在寻找有关这方面的任何信息,但无济于事。这包括仔细阅
我正在尝试学习 RDMA。 我的问题是,在执行 ibv_post_send 时,我应该在完成队列中得到一个完成事件。但是 ibv_post_send 如何知道发送到哪个完成队列?从我在这里看到的情况来
如何在 Windows 下使用 RDMA 将内存块从一台服务器复制到另一台服务器?我们没有 infiniband,但我们有 10gb 网络交换机。我只需要一个例子,但我在谷歌上运气不佳。 编辑: 到目
我有两台机器。每台机器上有多张特斯拉卡。每台机器上还有一张 InfiniBand 卡。我想通过 InfiniBand 在不同机器上的 GPU 卡之间进行通信。只需点对点单播就可以了。我当然想使用 GP

我是一名优秀的程序员,十分优秀!