
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 41
41
 4
4



上图的意思: 百战百胜,屡试不爽.

程序员小张: 刚毕业,参加工作1年左右,日常工作是CRUD 。

架构师老李: 多个大型项目经验,精通各种开发架构屠龙宝术; 。
小张注意到,在实际的项目开发场景中,很多开发人员只关注编写SQL脚本来满足功能需求,而忽略了脚本的可重复执行性.
这就意味着,如果脚本中的某个部分执行失败,运维人员就必须从头提供一个新的脚本,这对运维团队和开发人员来说是一个挑战.
因此,小张决定研究如何编写基于MySQL的可以重复执行的SQL脚本,以提高开发效率和简化运维流程.
他向公司的架构师老李咨询了这个问题。老李是一位经验丰富的架构师, 。
他在多个大型项目中积累了许多宝贵的经验,精通各种开发架构屠龙宝术.
老李听了小张的问题后,笑了笑并开始给予指导。他向小张解释了如何编写一个具有可重复执行性的SQL脚本,并分享了以下几个关键点:
a.使用事务:事务是一组SQL语句的逻辑单元,可以保证这组语句要么全部执行成功,要么全部回滚.
通过使用事务,可以确保脚本的所有修改操作要么完整地执行,要么不执行。
b.使用条件检查:在每个需要修改数据的语句之前,添加条件检查以确保只有当数据不存在或满足特定条件时才进行修改.
这样可以避免重复插入相同的数据,或者执行不必要的更新操作。
c.错误处理:在编写脚本时,考虑到可能出现的错误情况,并提供适当的错误处理机制。例如,使用IF...ELSE语句来处理特定条件下的执行逻辑.
d.使用存储过程:如果脚本非常复杂,包含多个步骤和业务逻辑,可以考虑将它们封装为存储过程。这样可以更好地组织和管理代码,并提高脚本的可读性和维护性.
小张听得津津有味,他开始将老李的建议付诸实践。他仔细研究每个SQL语句,根据老李的指导进行修改和优化.
他使用了事务来包裹整个脚本,添加了条件检查来避免重复插入数据,并实现了错误处理机制以应对异常情况.
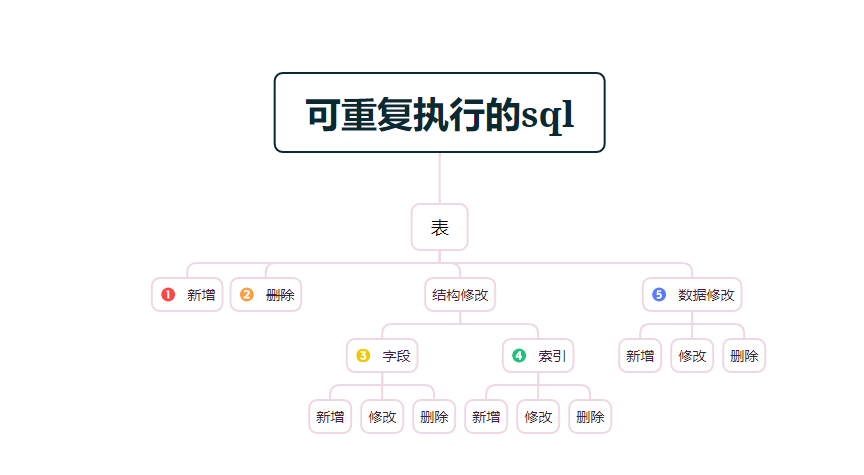
所以开发提供给到运维的SQL脚本有一定基本要求:
1.能重复执行; 。
2.不出错,(不报错,逻辑正确); 。
如果脚本不可重复执行,则运维无法自动化,会反过来要求后端开发人员给出适配当前环境的新的SQL脚本,增加了运维和沟通成本.
那么怎么写可重复执行的SQL脚本呢?
分成4个场景,来介绍举例.
create table if not exists nginx_config (
id varchar(36) not null default '' comment 'UUID',
namespace varchar(255) not null default '' comment '环境命名空间',
config_content text comment "nginx http块配置",
content_md5 varchar(64) not null default '' comment '配置内容的MD5值',
manipulator varchar(64) not null default '' comment '操作者',
description varchar(512) not null default '' comment '描述',
gmt_created bigint unsigned not null default 0 comment '创建时间',
primary key(id)
)ENGINE=InnoDB comment 'nginx配置表' ;
删除表在生产环境是禁止的.
修改表名: 先创建新表,再copy历史数据进去,不允许删除表; 。
DELIMITER //
drop procedure if exists modify_table_name;
CREATE PROCEDURE modify_table_name(
IN table_name VARCHAR(255),
IN new_name VARCHAR(255)
)
BEGIN
DECLARE database_name VARCHAR(255);
DECLARE table_exists INT DEFAULT 0;
DECLARE new_table_exists INT DEFAULT 0;
SELECT DATABASE() INTO database_name;
set @db_table_name=concat(database_name,'/',table_name);
select count(t1.TABLE_ID) INTO table_exists from information_schema.INNODB_TABLES t1 where t1.NAME=@db_table_name ;
set @db_table_name_new=concat(database_name,'/',new_name);
select count(t1.TABLE_ID) INTO new_table_exists from information_schema.INNODB_TABLES t1 where t1.NAME=@db_table_name_new ;
IF table_exists = 1 AND new_table_exists = 0 THEN
SET @query = CONCAT('create table ',new_name,' like ',table_name);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @query = CONCAT('insert into ', new_name, ' select * from ',table_name);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT 'table name modify successfully.' AS result ,@db_table_name,@db_table_name_new,table_exists,new_table_exists;
ELSE
SELECT 'table name not exists or new_name already exists.' AS result,@db_table_name,@db_table_name_new,table_exists,new_table_exists;
END IF;
END //
DELIMITER ;
测试脚本:
create table user(id bigint auto_increment primary key ,name varchar(30),age tinyint)comment 'user表';
insert into user(id, name, age) VALUES (1,'a',1),(2,'b',2),(3,'c',3);
call modify_table_name('user','user1');
select * from user1;
call modify_table_name('user','user2');
select * from user2;
测试结果符合预期.
drop procedure if exists modify_table_field;
CREATE PROCEDURE modify_table_field(IN tableName VARCHAR(50), IN fieldName VARCHAR(50), IN fieldAction VARCHAR(10), IN fieldType VARCHAR(255))
BEGIN
IF fieldAction = 'add' THEN
IF NOT EXISTS (SELECT * FROM information_schema.columns WHERE table_name = tableName AND column_name = fieldName) THEN
SET @query = CONCAT('ALTER TABLE ', tableName, ' ADD COLUMN ', fieldName, ' ', fieldType);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT 'Field added successfully.' AS result;
ELSE
SELECT 'Field already exists.' AS result;
END IF;
ELSEIF fieldAction = 'modify' THEN
IF EXISTS (SELECT * FROM information_schema.columns WHERE table_name = tableName AND column_name = fieldName) THEN
SET @query = CONCAT('ALTER TABLE ', tableName, ' CHANGE COLUMN ', fieldName, ' ', fieldName, ' ', fieldType);
select @query;
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT 'Field modified successfully.' AS result;
ELSE
SELECT 'Field does not exist or has the same name.' AS result;
END IF;
ELSEIF fieldAction = 'delete' THEN
IF EXISTS (SELECT * FROM information_schema.columns WHERE table_name = tableName AND column_name = fieldName) THEN
SET @query = CONCAT('ALTER TABLE ', tableName, ' DROP COLUMN ', fieldName);
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SELECT 'Field deleted successfully.' AS result;
ELSE
SELECT 'Field does not exist.' AS result;
END IF;
ELSE
SELECT 'Invalid field action.' AS result;
END IF;
END;
create table if not exists sys_agent
(
agent_id bigint not null comment '客服唯一id' primary key,
agent_name varchar(64) null comment '客服名称',
agent_type varchar(30) null comment '客服类型(场地客服、直聘客服)',
district varchar(30) null comment '地区',
service_language varchar(30) null comment '服务语种',
agent_description varchar(500) null comment '客户描述',
status tinyint(1) null comment '状态(0=无效,1=有效),默认为1',
del_flag tinyint(1) null comment '是否删除(0=false,1=true)',
user_id bigint null comment '用户id(关联的用户信息)',
time_zone varchar(50) null comment '时区',
create_by varchar(50) null comment '创建者',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间',
update_by varchar(50) null comment '修改者',
update_time datetime default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP comment '修改时间'
) comment '客服管理';
CALL modify_table_field('sys_agent', 'sex', 'add', 'tinyint not null comment ''性别''');
CALL modify_table_field('sys_agent', 'sex2', 'add', 'tinyint not null comment ''性别''');
CALL modify_table_field('sys_agent', 'sex', 'modify', 'int not null comment ''性别''');
CALL modify_table_field('sys_agent', 'sex', 'delete', '');
CALL modify_table_field('sys_agent', 'sex2', 'delete', '');
测试结果符合预期.
一般放在建表语句中,80%的情况; 。
如果是项目后期增加索引,进行调优,可以参考字段,写一个存储过程支持索引的新增可以重复执行; 。
DELIMITER //
drop procedure if exists modify_table_index;
CREATE PROCEDURE modify_table_index(
IN table_name VARCHAR(255),
IN index_name VARCHAR(255),
IN index_action ENUM('add', 'modify', 'delete'),
IN index_columns VARCHAR(255)
)
BEGIN
DECLARE database_name VARCHAR(255);
DECLARE index_exists INT DEFAULT 0;
DECLARE index_exists_action INT DEFAULT 0;
-- 获取当前数据库名
SELECT DATABASE() INTO database_name;
set @db_table_name=concat(database_name,'/',table_name);
-- 检查索引是否存在
select count(t2.INDEX_ID) INTO index_exists from information_schema.INNODB_TABLES t1 left join information_schema.INNODB_INDEXES t2 on t1.TABLE_ID=T2.TABLE_ID
where t1.NAME=@db_table_name and t2.NAME=index_name;
set index_exists_action=index_exists;
IF index_action = 'add' THEN
-- 添加索引
IF index_exists < 1 THEN
SET @query = CONCAT('ALTER TABLE `', database_name, '`.`', table_name, '` ADD INDEX `', index_name, '` (', index_columns, ')');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
select count(t2.INDEX_ID) INTO index_exists_action from information_schema.INNODB_TABLES t1 left join information_schema.INNODB_INDEXES t2 on t1.TABLE_ID=T2.TABLE_ID where t1.NAME=@db_table_name and t2.NAME=index_name;
SELECT 'Index added successfully.' AS result ,database_name,index_exists,@db_table_name,index_exists_action;
ELSE
SELECT 'Index already exists.' AS result,database_name,index_exists,@db_table_name,index_exists_action;
END IF;
ELSEIF index_action = 'modify' THEN
-- 修改索引(先删除后添加)
IF index_exists > 0 THEN
SET @query = CONCAT('ALTER TABLE `', database_name, '`.`', table_name, '` DROP INDEX `', index_name, '`');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @query = CONCAT('ALTER TABLE `', database_name, '`.`', table_name, '` ADD INDEX `', index_name, '` (', index_columns, ')');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
select count(t2.INDEX_ID) INTO index_exists_action from information_schema.INNODB_TABLES t1 left join information_schema.INNODB_INDEXES t2 on t1.TABLE_ID=T2.TABLE_ID where t1.NAME=@db_table_name and t2.NAME=index_name;
SELECT 'Index modified successfully.' AS result,database_name,index_exists,@db_table_name,index_exists_action;
ELSE
SELECT 'Index does not exist. create' AS result,database_name,index_exists,@db_table_name,index_exists_action;
SET @query = CONCAT('ALTER TABLE `', database_name, '`.`', table_name, '` ADD INDEX `', index_name, '` (', index_columns, ')');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
select count(t2.INDEX_ID) INTO index_exists_action from information_schema.INNODB_TABLES t1 left join information_schema.INNODB_INDEXES t2 on t1.TABLE_ID=T2.TABLE_ID where t1.NAME=@db_table_name and t2.NAME=index_name;
SELECT 'Index added successfully.' AS result ,database_name,index_exists,@db_table_name,index_exists_action;
END IF;
ELSEIF index_action = 'delete' THEN
-- 删除索引
IF index_exists > 0 THEN
SET @query = CONCAT('ALTER TABLE `', database_name, '`.`', table_name, '` DROP INDEX `', index_name, '`');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
select count(t2.INDEX_ID) INTO index_exists_action from information_schema.INNODB_TABLES t1 left join information_schema.INNODB_INDEXES t2 on t1.TABLE_ID=T2.TABLE_ID where t1.NAME=@db_table_name and t2.NAME=index_name;
SELECT 'Index deleted successfully.' AS result,database_name,index_exists,@db_table_name,index_exists_action;
ELSE
SELECT 'Index does not exist.' AS result,database_name,index_exists,@db_table_name,index_exists_action;
END IF;
ELSE
SELECT 'Invalid index action.' AS result,database_name,index_exists,@db_table_name,index_exists_action;
END IF;
END //
DELIMITER ;
create table if not exists sys_agent
(
agent_id bigint not null comment '客服唯一id'
primary key,
agent_name varchar(64) null comment '客服名称',
agent_type varchar(30) null comment '客服类型(场地客服、直聘客服)',
district varchar(30) null comment '地区',
service_language varchar(30) null comment '服务语种',
agent_description varchar(500) null comment '客户描述',
status tinyint(1) null comment '状态(0=无效,1=有效),默认为1',
del_flag tinyint(1) null comment '是否删除(0=false,1=true)',
user_id bigint null comment '用户id(关联的用户信息)',
time_zone varchar(50) null comment '时区',
create_by varchar(50) null comment '创建者',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间',
update_by varchar(50) null comment '修改者',
update_time datetime default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP comment '修改时间'
)comment '客服管理';
CALL modify_table_index('sys_agent', 'ix_agentName', 'add', 'agent_name,agent_type');
CALL modify_table_index('sys_agent', 'ix_agentName', 'delete', '');
CALL modify_table_index('sys_agent', 'ix_agentName', 'modify', 'agent_name,agent_type');
replace into语句 按照主键或者唯一值,存在则先删除再插入,不存在则直接插入; 。
注意: 一定要写字段名称 .
REPLACE INTO route_config (route_id, route_order, route_uri, route_filters, route_predicates, route_metadata, memo, created, updated, deleted) VALUES ('app-metadata-runtime', 1, 'lb://app-metadata-runtime', '[{"name":"StripPrefix","args":{"parts":"2"}}]', '[{"name":"Path","args":{"pattern":"/api/mr/**"}}]', '{}', '云枢服务app-metadata-runtime', '2020-07-31 21:44:11', '2020-09-07 20:24:13', 0);
按照不同的场景写了对应的存储过程,使得修改字段,修改索引,修改表,插入数据可以重复执行.
如果有使用问题或者优化建议,欢迎提出来。还原跟我交流 ,
原创不易,关注诚可贵,转发价更高!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流.
最后此篇关于程序员:你如何写可重复执行的SQL语句?的文章就讲到这里了,如果你想了解更多关于程序员:你如何写可重复执行的SQL语句?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
41
4
 0
0
我需要(我必须)将大量 float 写入 qdatastream 并且我只使用 4 个字节是必要的。setFloatingPointPrecision 或为 float 和 double 写入 4 或
我有一些 C 代码,我用 Python 对其进行了扩展。扩展的 C 代码有一个将一些结构附加到二进制文件的函数: void writefunction(const struct struct1* so
我正在用 C 语言开发一个小软件,用于在布告栏中读取和写入消息。每条消息都是一个以渐进数字命名的 .txt。 软件是多线程的,有很多用户可以并发操作。 用户可以进行的操作有: 阅读整个公告板(所有 .
我有 2 个线程同时访问同一个大文件 (.txt)。 第一个线程正在从文件中读取。第二个线程正在写入文件。 两个线程都访问同一个 block ,例如(开始:0, block 大小:10),但具有不同的
我做了很多谷歌搜索,但我仍然不确定如何继续。 Linux 下最常见的剪贴板读写方式是什么?我想要同时支持 Gnome 和 KDE 桌面。 更新:我是否认为没有简单的解决方案,必须将多个来源(gnome
1. 定义配置文件信息 有时候我们为了统一管理会把一些变量放到 yml 配置文件中 例如 图片 用 @ConfigurationProperties 代替 @Value 使用方法 定义对应字段的实体
在开始之前,我必须先声明我是 FORTRAN 的新手。我正在维护 1978 年的一段遗留代码。它的目的是从文件中读取一些数据值,处理这些值,然后将处理过的值输出到另一个文本文件。 给定以下 FORTR
我正在制作一个应用程序,我需要存储用户提供的一些信息。我尝试使用 .plist 文件来存储信息,我发现: NSString *filePath = @"/Users/Denis/Documents/X
在delphi类中声明属性时是否可能有不同类型的结果? 示例: 属性月份:字符串读取monthGet(字符串)写入monthSet(整数); 在示例中,我希望在属性(property)月份中,当我:读
我正在以二进制形式将文件加载到数组中,这似乎需要一段时间有没有更好更快更有效的方法来做到这一点。我正在使用类似的方法写回文件。 procedure openfile(fname:string); va
我想实现一个运行模拟的C#控制台应用程序。另外,我想给用户机会在控制台上按“+”或“-”来加速/减速模拟的速度。 有没有办法在编写控制台时读取控制台?我相信我可以为此使用多线程,但是我却不怎么做(我对
这是我的代码: use std::fs::File; use std::io::Write; fn main() { let f = File::create("").unwrap();
我有一个应用程序可以访问 csv 文本文件中的单词。由于它们通常不会更改,因此我将它们放置在 .jar 文件中,并使用 .getResourceAsStream 调用读取它们。我真的很喜欢这种方法,因
我使用kubeadm,docker 17.12.1-ce和法兰绒网络安装了Kubernetes 1.13.1集群 但是,我发现Kubernetes主服务器上有许多空文件,权限为666,该文件允许任何用
我的工作区中有一些 java 文件。现在我想编写一个java程序,它可以读取来自不同源的文本文件,一次一个,一行一行,并将这些行插入到工作区中各自的java文件中。 文本文件会告诉我将哪个文件插入到哪
用户A要求系统读取文件foo,同时用户B想要将他或她的数据保存到同一个文件中。在文件系统级别如何处理这种情况? 最佳答案 大多数文件系统(但不是全部)使用锁定来保护对同一文件的并发访问。锁可以是独占的
我对保护移动应用程序的 firebase 数据库有一些疑问。 例如,在反编译Android应用程序后,黑客可以获取firebase api key 然后访问firebase数据库,这是正确的吗? 假设
我想让文件从外部不可删除,并希望使用java从程序对该文件进行读/写操作。 S0,我使用以下代码使用java创建了不可删除的文件: Process pcs = Runtime.getRunti
当 Selector.select() 以阻塞模式等待读/写操作时,是否可以将写消息推送到客户端?如何将选择器从阻塞模式移至写入模式?触发器可以是一个后台线程,用于放置需要写入给定 channel 的
我目前正在学习在 Linux 环境中使用 C 进行套接字编程。作为一个项目,我正在尝试编写一个基本的聊天服务器和客户端。 目的是让服务器为每个连接的客户端派生一个进程。 我遇到的问题是读取一个 chi

我是一名优秀的程序员,十分优秀!