
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos 。


int[] fathers = new int[100001];
先回顾一下解题思路,整个流程如下图所示 。
假设此题的入参是这四个数字:4,6,15, 35,回顾什么时候咱们会用到这四个数字,显然计算每个数字的质因数的时候必然会用到,计算完成后,得到了下图的关系(这是前文的内容) 。
然后,咱们根据上图,得到了每个质因数对应的数字集合,也就是下图 。
看着上图,重点来了: 从上图开始,再到后面的并查集操作,再到最终的结束,都不会用4、6、15、35这样的数字去计算什么了 。
所以,上面那幅图中的4、6、15、35,是不是可以替换成他们在入参数组中的下标?假设入参数组是[4,6,15,35],他们的数组下标就分别是:0、1、2、3 。
将数字替换成数组下标后,上面那幅图的内容就有了变化,变成了下图的样子,之前的[4,6,15,35]四个数字变成了[0,1,2,3] 。
接下来的并查集操作中,也可以用[0,1,2,3]取代[4,6,15,35]也可以吗?
当然可以,之前是合并4和6,现在变成了合并0和1,题目是要的是连通的数量,而某个唯一的数字到底是4还是它的数组下标0,这不重要了,重要的是合并不能有错就行 。
这样替换后,如果入参是四个数字,不论值是多少,在并查集操作时,只需要用到它们的数组下标:0、1、2、3,最大也只有3 。
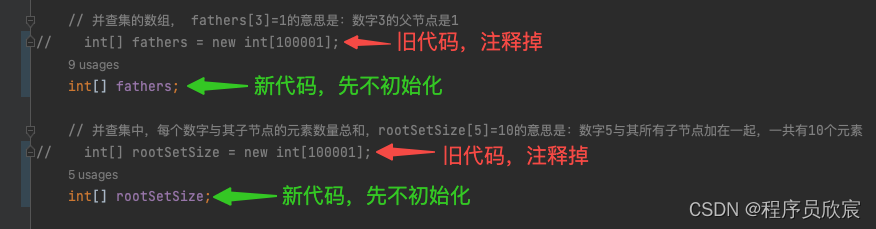
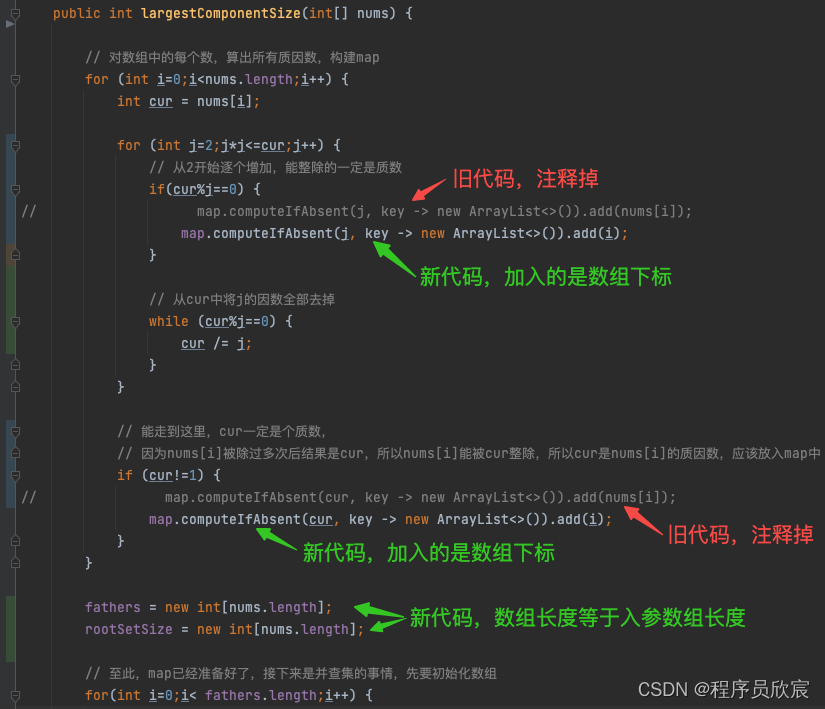
这就有意思了,数组fathers和rootSetSize的大小从100001变成了入参数组的长度! 。
准备工作完成了,可以正式动手优化了 。
class Solution {
// 并查集的数组, fathers[3]=1的意思是:数字3的父节点是1
// int[] fathers = new int[100001];
int[] fathers;
// 并查集中,每个数字与其子节点的元素数量总和,rootSetSize[5]=10的意思是:数字5与其所有子节点加在一起,一共有10个元素
// int[] rootSetSize = new int[100001];
int[] rootSetSize;
// map的key是质因数,value是以此key作为质因数的数字
// 例如题目的数组是[4,6,15,35],对应的map就有四个key:2,3,5,7
// key等于2时,value是[4,6],因为4和6的质因数都有2
// key等于3时,value是[6,15],因为6和16的质因数都有3
// key等于5时,value是[15,35],因为15和35的质因数都有5
// key等于7时,value是[35],因为35的质因数有7
Map<Integer, List<Integer>> map = new HashMap<>();
// 用来保存并查集中,最大树的元素数量
int maxRootSetSize = 1;
/**
* 带压缩的并查集查找(即寻找指定数字的根节点)
* @param i
*/
private int find(int i) {
// 如果执向的是自己,那就是根节点了
if(fathers[i]==i) {
return i;
}
// 用递归的方式寻找,并且将整个路径上所有长辈节点的父节点都改成根节点,
// 例如1的父节点是2,2的父节点是3,3的父节点是4,4就是根节点,在这次查找后,1的父节点变成了4,2的父节点也变成了4,3的父节点还是4
fathers[i] = find(fathers[i]);
return fathers[i];
}
/**
* 并查集合并,合并后,child会成为parent的子节点
* @param parent
* @param child
*/
private void union(int parent, int child) {
int parentRoot = find(parent);
int childRoot = find(child);
// 如果有共同根节点,就提前返回
if (parentRoot==childRoot) {
return;
}
// child元素根节点是childRoot,现在将childRoot的父节点从它自己改成了parentRoot,
// 这就相当于child所在的整棵树都拿给parent的根节点做子树了
fathers[childRoot] = fathers[parentRoot];
// 合并后,这个树变大了,新增元素的数量等于被合并的字数元素数量
rootSetSize[parentRoot] += rootSetSize[childRoot];
// 更像最大数量
maxRootSetSize = Math.max(maxRootSetSize, rootSetSize[parentRoot]);
}
public int largestComponentSize(int[] nums) {
// 对数组中的每个数,算出所有质因数,构建map
for (int i=0;i<nums.length;i++) {
int cur = nums[i];
for (int j=2;j*j<=cur;j++) {
// 从2开始逐个增加,能整除的一定是质数
if(cur%j==0) {
// map.computeIfAbsent(j, key -> new ArrayList<>()).add(nums[i]);
map.computeIfAbsent(j, key -> new ArrayList<>()).add(i);
}
// 从cur中将j的因数全部去掉
while (cur%j==0) {
cur /= j;
}
}
// 能走到这里,cur一定是个质数,
// 因为nums[i]被除过多次后结果是cur,所以nums[i]能被cur整除,所以cur是nums[i]的质因数,应该放入map中
if (cur!=1) {
// map.computeIfAbsent(cur, key -> new ArrayList<>()).add(nums[i]);
map.computeIfAbsent(cur, key -> new ArrayList<>()).add(i);
}
}
fathers = new int[nums.length];
rootSetSize = new int[nums.length];
// 至此,map已经准备好了,接下来是并查集的事情,先要初始化数组
for(int i=0;i< fathers.length;i++) {
// 这就表示:数字i的父节点是自己
fathers[i] = i;
// 这就表示:数字i加上其下所有子节点的数量等于1(因为每个节点父节点都是自己,所以每个节点都没有子节点)
rootSetSize[i] = 1;
}
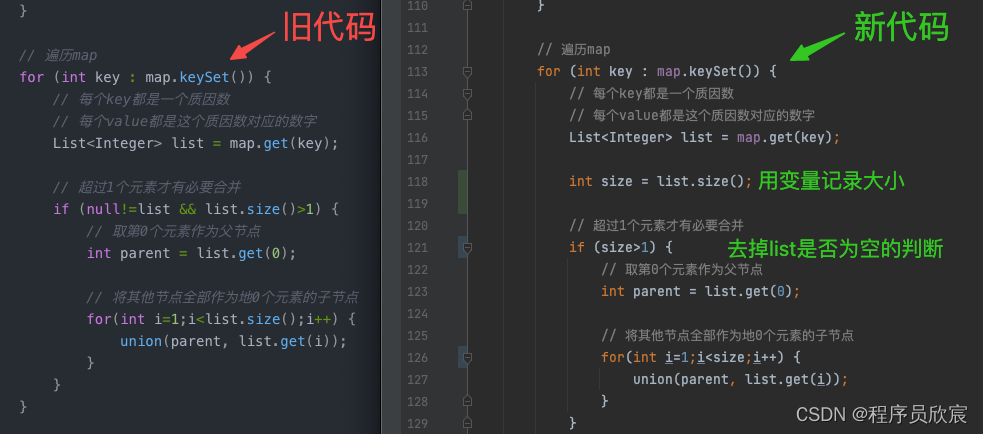
// 遍历map
for (int key : map.keySet()) {
// 每个key都是一个质因数
// 每个value都是这个质因数对应的数字
List<Integer> list = map.get(key);
int size = list.size();
// 超过1个元素才有必要合并
if (size>1) {
// 取第0个元素作为父节点
int parent = list.get(0);
// 将其他节点全部作为地0个元素的子节点
for(int i=1;i<size;i++) {
union(parent, list.get(i));
}
}
}
return maxRootSetSize;
}
}

这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos 。
学习路上,你不孤单,欣宸原创一路相伴... 。
最后此篇关于LeetCode952三部曲之二:小幅度优化(137ms->122ms,超39%->超51%)的文章就讲到这里了,如果你想了解更多关于LeetCode952三部曲之二:小幅度优化(137ms->122ms,超39%->超51%)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
比较代码: const char x = 'a'; std::cout > (0C310B0h) 00C3100B add esp,4 和 const i
您好,我正在使用 Matlab 优化求解器,但程序有问题。我收到此消息 fmincon 已停止,因为目标函数值小于目标函数限制的默认值,并且约束满足在约束容差的默认值范围内。我也收到以下消息。警告:矩
处理Visual Studio optimizations的问题为我节省了大量启动和使用它的时间 当我必须进行 J2EE 开发时,我很难回到 Eclipse。因此,我还想知道人们是否有任何提示或技巧可
情况如下:在我的 Excel 工作表中,有一列包含 1-name 形式的条目。考虑到数字也可以是两位数,我想删除这些数字。这本身不是问题,我让它工作了,只是性能太糟糕了。现在我的程序每个单元格输入大约
这样做有什么区别吗: $(".topHorzNavLink").click(function() { var theHoverContainer = $("#hoverContainer");
这个问题已经有答案了: 已关闭11 年前。 Possible Duplicate: What is the cost of '$(this)'? 我经常在一些开发人员代码中看到$(this)引用同一个
我刚刚结束了一个大型开发项目。我们的时间紧迫,因此很多优化被“推迟”。既然我们已经达到了最后期限,我们将回去尝试优化事情。 我的问题是:优化 jQuery 网站时您要寻找的最重要的东西是什么。或者,我
所以我一直在用 JavaScript 编写游戏(不是网络游戏,而是使用 JavaScript 恰好是脚本语言的游戏引擎)。不幸的是,游戏引擎的 JavaScript 引擎是 SpiderMonkey
这是我在正在构建的页面中使用的 SQL 查询。它目前运行大约 8 秒并返回 12000 条记录,这是正确的,但我想知道您是否可以就如何使其更快提出可能的建议? SELECT DISTINCT Adve
如何优化这个? SELECT e.attr_id, e.sku, a.value FROM product_attr AS e, product_attr_text AS a WHERE e.attr
我正在使用这样的结构来测试是否按下了所需的键: def eventFilter(self, tableView, event): if event.type() == QtCore.QEven
我正在使用 JavaScript 从给定的球员列表中计算出羽毛球 double 比赛的所有组合。每个玩家都与其他人组队。 EG。如果我有以下球员a、b、c、d。它们的组合可以是: a & b V c
我似乎无法弄清楚如何让这个 JS 工作。 scroll function 起作用但不能隐藏。还有没有办法用更少的代码行来做到这一点?我希望 .down-arrow 在 50px 之后 fade out
我的问题是关于用于生产的高级优化级联样式表 (CSS) 文件。 多么最新和最完整(准备在实时元素中使用)的 css 优化器/最小化器,它们不仅提供删除空格和换行符,还提供高级功能,如删除过多的属性、合
我读过这个: 浏览器检索在 中请求的所有资源开始呈现 之前的 HTML 部分.如果您将请求放在 中section 而不是,那么页面呈现和下载资源可以并行发生。您应该从 移动尽可能多的资源请求。
我正在处理一些现有的 C++ 代码,这些代码看起来写得不好,而且调用频率很高。我想知道我是否应该花时间更改它,或者编译器是否已经在优化问题。 我正在使用 Visual Studio 2008。 这是一
我正在尝试使用 OpenGL 渲染 3 个四边形(1 个背景图,2 个 Sprite )。我有以下代码: void GLRenderer::onDrawObjects(long p_dt) {
我确实有以下声明: isEnabled = false; if(foo(arg) && isEnabled) { .... } public boolean foo(arg) { some re
(一)深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录。微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(no
一、写在前面 css的优化方案,之前没有提及,所以接下来进行总结一下。 二、具体优化方案 2.1、加载性能 1、css压缩:将写好的css进行打包,可以减少很多的体积。 2、css单一样式:在需要下边

我是一名优秀的程序员,十分优秀!