
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


现在信创是搞得如火如荼,在这个浪潮下,数据库也是从之前熟悉的Mysql换到了某国产数据库.
该数据库我倒是想吐槽吐槽,它是基于Postgre 9.x的基础上改的,至于改了啥,我也没去详细了解,当初的数据库POC测试和后续的选型没太参与,但对于我一个开发人员的角度来说,它给我带来的不便主要是客户端GUI工具这块.
我们读写数据库,程序这块还好,CURD代码用到的语法,基本是sql标准兼容的那些,没用多少mysql的特殊语法,所以这块没啥感觉.
客户端GUI这块,pg的客户端软件目前知道几个:
基于以上原因,一直用dbeaver来着,之前两次把mysql项目的表结构换成pg,一次是写了个乱七八糟的代码来做建表语句转换,一次是用dbeaver建的,太繁琐了.
这次又来了个项目,我就换回了我熟悉的sqlyog(一款mysql客户端),几下就把表建好了(mysql版本),然后写了个工具代码,来把mysql的DDL转换成pg的.
下面简单介绍下这个转换代码.
以前写这种代码,都是各种字符串操作(正则、匹配、替换等等),反正代码最终是非常难以维护。这次就先去网上查了下,发现有人有类似需求,还发了文章: https://zhuanlan.zhihu.com/p/314069540 。
我发现其中利用了一个java库,JSqlParser( https://github.com/JSQLParser/JSqlParser),我在网上也找了下其他的库,java这块没有更好的了,遥遥领先.
其官方说明:
JSqlParser parses an SQL statement and translate it into a hierarchy of Java classes. 。
它支持解析sql语句这种非结构化文本为结构化数据,比如,针对如下的一个建库sql:
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
可以解析为如下的类及属性:
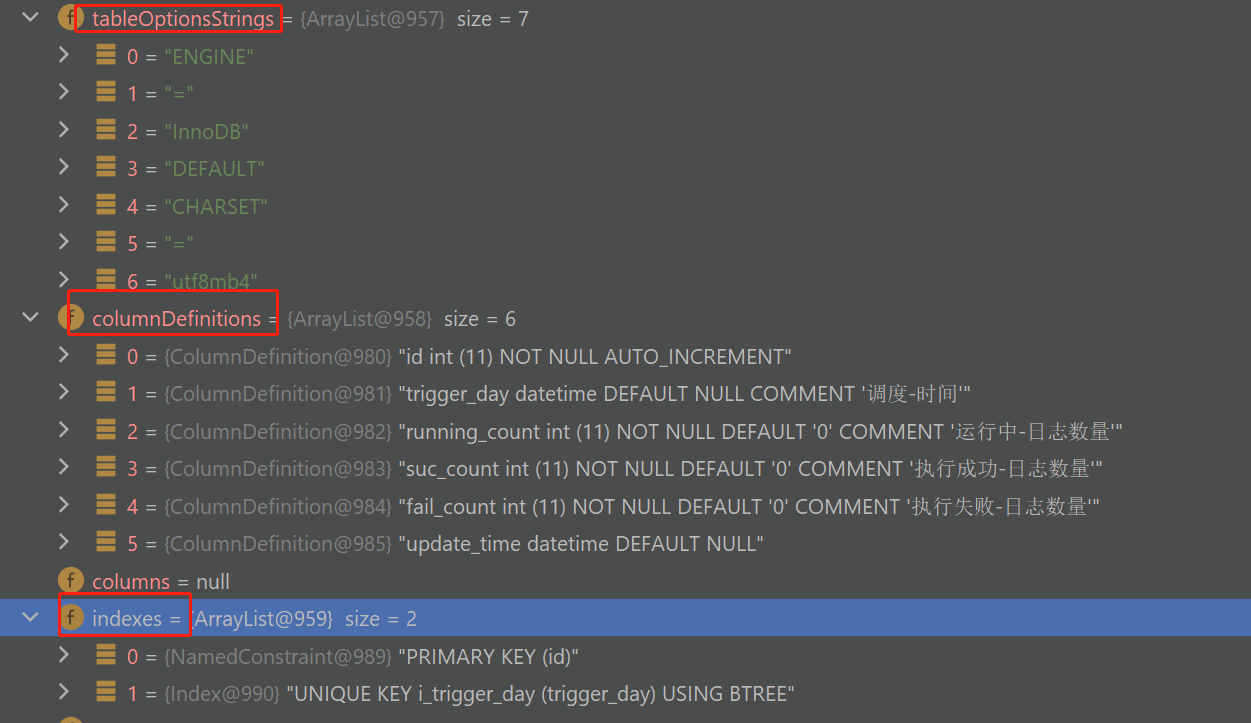
如上就包含了索引、列定义、建表选项等等.
我们接下来就只需要根据这些字段,获取数据并转换为对应的Postgre的语法即可.
源码: https://github.com/cctvckl/convertMysqlDdlToPostgre.git 。
对于以上的类,给大家看看转换效果:
CREATE TABLE xxl_job_log_report (
id serial PRIMARY KEY,
trigger_day timestamp NULL,
running_count int NOT NULL DEFAULT '0',
suc_count int NOT NULL DEFAULT '0',
fail_count int NOT NULL DEFAULT '0',
update_time timestamp NULL
);
COMMENT ON COLUMN xxl_job_log_report.trigger_day IS '调度-时间';
COMMENT ON COLUMN xxl_job_log_report.running_count IS '运行中-日志数量';
COMMENT ON COLUMN xxl_job_log_report.suc_count IS '执行成功-日志数量';
COMMENT ON COLUMN xxl_job_log_report.fail_count IS '执行失败-日志数量';
这个sql,基本都满足我们的要求了.
当然,我这个工具类,还没特别完善,对于索引这块,只支持了主键索引,其他索引类型,后面空了我补一下.
支持的DDL类型,目前仅限于create table和drop table,目前能满足我个人需求了,反正mysqldump那些导出来的sql结构基本就这样.
暂不支持DML,如insert那些.
Statements statements = CCJSqlParserUtil.parseStatements(sqlContent);
for (Statement statement : statements.getStatements()) {
if (statement instanceof CreateTable) {
String sql = ProcessSingleCreateTable.process((CreateTable) statement);
totalSql.append(sql).append("\n");
} else if (statement instanceof Drop) {
String sql = ProcessSingleDropTable.process((Drop) statement);
totalSql.append(sql).append("\n");
} else {
throw new UnsupportedOperationException();
}
}
如上,CCJSqlParserUtil 是 JSqlParser 的工具类,将我们的sql转换为一个一个的statement(即sql语句),我这边利用instanceof检查属于哪种DDL,再调用对应的代码进行处理,设计模式也懒得弄,if else写起来多快.
List<String> tableOptionsStrings = createTable.getTableOptionsStrings();
String tableCommentSql = null;
int commentIndex = tableOptionsStrings.indexOf("COMMENT");
if (commentIndex != -1) {
tableCommentSql = String.format("COMMENT ON TABLE %s IS %s;", tableFullyQualifiedName,tableOptionsStrings.get(commentIndex + 2));
}
解析出的表的相关属性,全都被放在一个list中,我们根据 COMMENT 关键字定位索引,然后找后两个,即是表注释具体值.
由于我是直接在作者基础上改的, https://zhuanlan.zhihu.com/p/314069540,所以也是像他那样,复用了其代码,提取每一列的注释,逻辑也是根据COMMENT关键字找到index,然后index+1就是注释值.
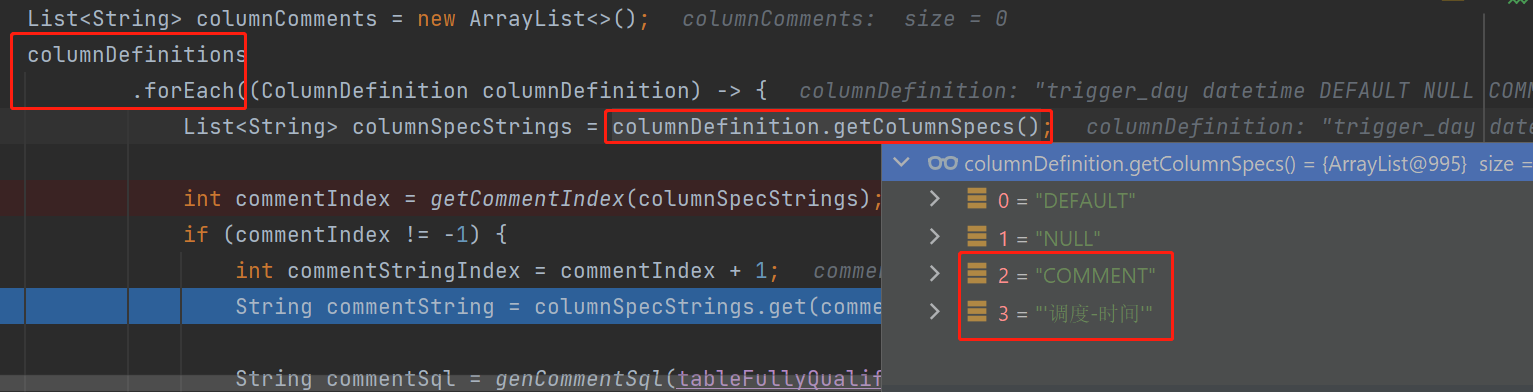
提取出来后,格式化为pg语法:
String.format("COMMENT ON COLUMN %s.%s IS %s;", table, column, commentValue);
Index primaryKey = createTable.getIndexes().stream()
.filter((Index index) -> Objects.equals("PRIMARY KEY", index.getType()))
.findFirst().orElse(null);
String createTableFirstLine = String.format("CREATE TABLE %s (", tableFullyQualifiedName);
这里涉及数据类型转换,如mysql中的bigint,在pg中,使用bigserial即可:
String dataType = primaryKeyColumnDefinition.getColDataType().getDataType();
if (Objects.equals("bigint", dataType)) {
primaryKeyType = "bigserial";
} else if (Objects.equals("int", dataType)) {
primaryKeyType = "serial";
} else if (Objects.equals("varchar", dataType)){
primaryKeyType = primaryKeyColumnDefinition.getColDataType().toString();
}
String sql = String.format("%s %s PRIMARY KEY", primaryKeyColumnName, primaryKeyType);
这部分有几块:
类型转换,mysql的类型,转换为pg的,我这边定义了一个map,大致如下:
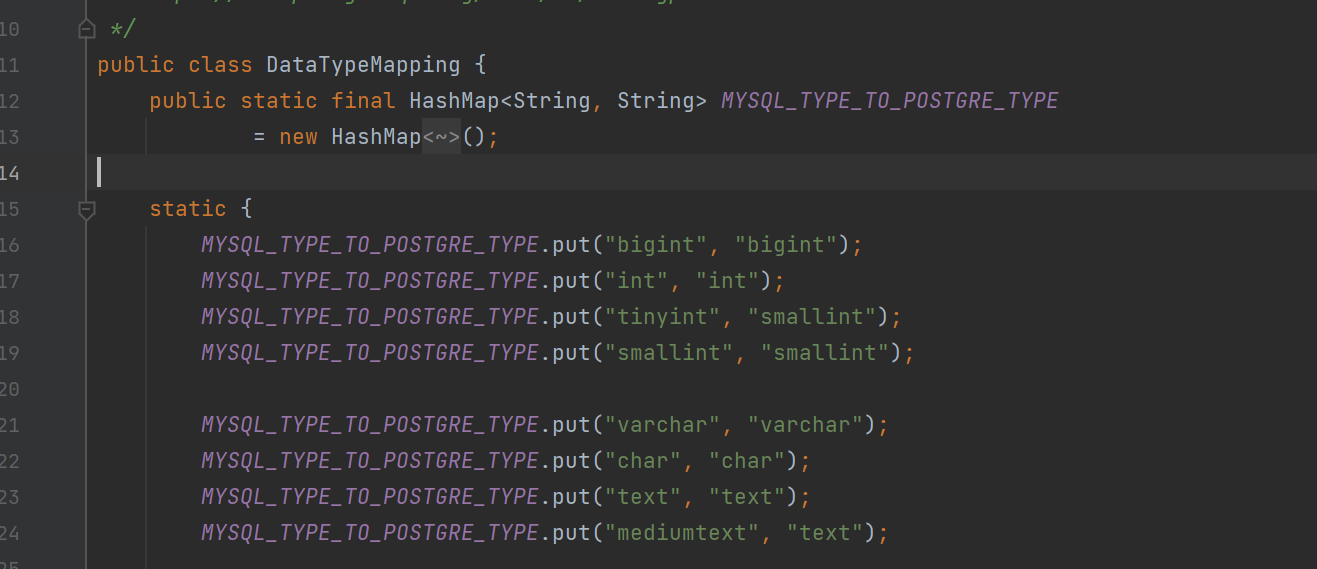
以上仅是部分,具体查看代码 。
默认值处理 。
这块也比较麻烦,比如mysql中的函数这种,如CURRENT_TIMESTAMP这种默认值,转换为pg中的对应函数,我大概定义了几个,满足当前需要:
static {
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("NULL", "NULL");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIMESTAMP", "CURRENT_TIMESTAMP");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_DATE", "CURRENT_DATE");
MYSQL_DEFAULT_TO_POSTGRE_DEFAULT.put("CURRENT_TIME", "CURRENT_TIME");
}
删除pg不支持的mysql语法 。
// postgre不支持unsigned
sourceSpec = sourceSpec.replaceAll("unsigned", "");
// postgre不支持ON UPDATE CURRENT_TIMESTAMP
sourceSpec = sourceSpec.replaceAll("ON UPDATE CURRENT_TIMESTAMP", "");
这块就不说了,上面效果展示部分有.
生成出来的sql,会在项目根路径下的target.sql文件中 。
生成的target.sql文件,在idea中打开,如果有语法错误会飘红,如果大家有java开发能力,直接debug改就行,不行就提issue,我看到了空了就改; 。
我之前拿着有语法错误的sql就去dbeaver执行了,报错也不详细,看得一脸懵,idea还是厉害.
mysql官方的迁移指南,里面包含了pg的各种类型对应到mysql的什么类型
https://dev.mysql.com/doc/workbench/en/wb-migration-database-postgresql-typemapping.html
mysql中的各种类型查阅
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
pg中的各种类型查阅,我看得低版本的,谁让我们的信创数据库是基于pg 9版本的呢
https://www.postgresql.org/docs/11/datatype-numeric.html#DATATYPE-INT
这边直接贴一下吧,方便大家看:
| Pg Source Type | Taret MySQL Type | Comment |
| INT | INT | |
| SMALLINT | SMALLINT | |
| BIGINT | BIGINT | |
| SERIAL | INT | Sets AUTO_INCREMENT in its table definition. |
| SMALLSERIAL | SMALLINT | Sets AUTO_INCREMENT in its table definition. |
| BIGSERIAL | BIGINT | Sets AUTO_INCREMENT in its table definition. |
| BIT | BIT | |
| BOOLEAN | TINYINT(1) | |
| REAL | FLOAT | |
| DOUBLE PRECISION | DOUBLE | |
| NUMERIC | DECIMAL | |
| DECIMAL | DECIMAL | |
| MONEY | DECIMAL(19,2) | |
| CHAR | CHAR/LONGTEXT | |
| NATIONAL CHARACTER | CHAR/LONGTEXT | |
| VARCHAR | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| NATIONAL CHARACTER VARYING | VARCHAR/MEDIUMTEXT/LONGTEXT | |
| DATE | DATE | |
| TIME | TIME | |
| TIMESTAMP | DATETIME | |
| INTERVAL | TIME | |
| BYTEA | LONGBLOB | |
| TEXT | LONGTEXT | |
| CIDR | VARCHAR(43) | |
| INET | VARCHAR(43) | |
| MACADDR | VARCHAR(17) | |
| UUID | VARCHAR(36) | |
| XML | LONGTEXT | |
| JSON | LONGTEXT | |
| TSVECTOR | LONGTEXT | |
| TSQUERY | LONGTEXT | |
| ARRAY | LONGTEXT | |
| POINT | POINT | |
| LINE | LINESTRING | |
| LSEG | LINESTRING | |
| BOX | POLYGON | |
| PATH | LINESTRING | |
| POLYGON | POLYGON | |
| CIRCLE | POLYGON | |
| TXID_SNAPSHOT | VARCHAR |
最后此篇关于纯分享:将MySql的建表DDL转为PostgreSql的DDL的文章就讲到这里了,如果你想了解更多关于纯分享:将MySql的建表DDL转为PostgreSql的DDL的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我有一台 MySQL 服务器和一台 PostgreSQL 服务器。 需要从多个表中复制或重新插入一组数据 MySQL 流式传输/同步到 PostgreSQL 表。 这种复制可以基于时间(Sync)或事
如果两个表的 id 彼此相等,我尝试从一个表中获取数据。这是我使用的代码: SELECT id_to , email_to , name_to , status_to
我有一个 Excel 工作表。顶行对应于列名称,而连续的行每行代表一个条目。 如何将此 Excel 工作表转换为 SQL 表? 我使用的是 SQL Server 2005。 最佳答案 这取决于您使用哪
我想合并两个 Django 模型并创建一个模型。让我们假设我有第一个表表 A,其中包含一些列和数据。 Table A -------------- col1 col2 col3 col
我有两个表:table1,table2,如下所示 table1: id name 1 tamil 2 english 3 maths 4 science table2: p
关闭。此题需要details or clarity 。目前不接受答案。 想要改进这个问题吗?通过 editing this post 添加详细信息并澄清问题. 已关闭 1 年前。 Improve th
下面两个语句有什么区别? newTable = orginalTable 或 newTable.data(originalTable) 我怀疑 .data() 方法具有性能优势,因为它在标准 AX 中
我有一个表,我没有在其中显式定义主键,它并不是真正需要的功能......但是一位同事建议我添加一个列作为唯一主键以随着数据库的增长提高性能...... 谁能解释一下这是如何提高性能的? 没有使用索引(
如何将表“产品”中的产品记录与其不同表“图像”中的图像相关联? 我正在对产品 ID 使用自动增量。 我觉得不可能进行关联,因为产品 ID 是自动递增的,因此在插入期间不可用! 如何插入新产品,获取产品
我有一个 sql 表,其中包含关键字和出现次数,如下所示(尽管出现次数并不重要): ____________ dog | 3 | ____________ rat | 7 | ____
是否可以使用目标表中的LAST_INSERT_ID更新源表? INSERT INTO `target` SELECT `a`, `b` FROM `source` 目标表有一个自动增量键id,我想将其
我正在重建一个搜索查询,因为它在“我看到的”中变得多余,我想知道什么 (albums_artists, artists) ( ) does in join? is it for boosting pe
以下是我使用 mysqldump 备份数据库的开关: /usr/bin/mysqldump -u **** --password=**** --single-transaction --databas
我试图获取 MySQL 表中的所有行并将它们放入 HTML 表中: Exam ID Status Assigned Examiner
如何查询名为 photos 的表中的所有记录,并知道当前用户使用单个查询将哪些结果照片添加为书签? 这是我的表格: -- -- Table structure for table `photos` -
我的网站都在 InnoDB 表上运行,目前为止运行良好。现在我想知道在我的网站上实时发生了什么,所以我将每个页面浏览量(页面、引荐来源网址、IP、主机名等)存储在 InnoDB 表中。每秒大约有 10
我在想我会为 mysql 准备两个表。一个用于存储登录信息,另一个用于存储送货地址。这是传统方式还是所有内容都存储在一张表中? 对于两个表...有没有办法自动将表 A 的列复制到表 B,以便我可以引用
我不是程序员,我从这个表格中阅读了很多关于如何解决我的问题的内容,但我的搜索效果不好 我有两张 table 表 1:成员 id*| name | surname -------------------
我知道如何在 ASP.NET 中显示真实表,例如 public ActionResult Index() { var s = db.StaffInfoDBSet.ToList(); r
我正在尝试运行以下查询: "insert into visits set source = 'http://google.com' and country = 'en' and ref = '1234

我是一名优秀的程序员,十分优秀!