
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 。
论文标题:Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis 论文作者:Hui Wu、Xiaodong Shi 论文来源:2022 ACL 论文地址:download 论文代码:download 视屏讲解:click 。
动机 :直接使用固定的预定义模板进行跨域研究,不能对不同域的 $\text{[MASK]}$ 标记在不同域中的不同分布进行建模,因此没有充分利用提示调优技术。在本文中,提出了一种新的对抗性软提示调优方法(AdSPT)来更好地建模跨域情绪分析; 。
贡献 :
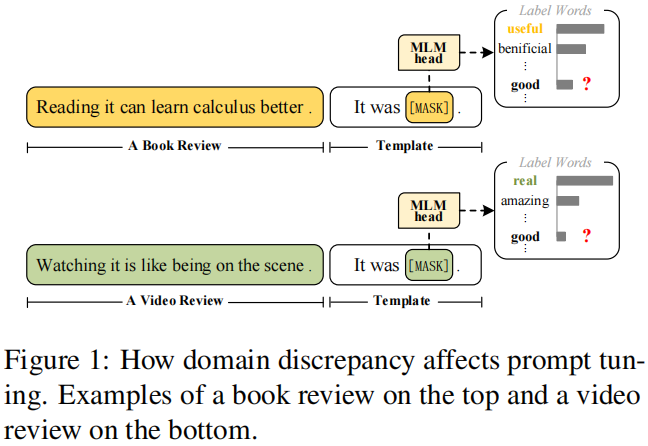
通常使用预定义模板(例如 “It was [MASK].” )在二元情绪分析的提示调优中,正或负的分类结果依赖于掩蔽语言建模(MLM)任务中预定义的标签词(例如,“好,坏”)的概率。然而,不同领域的MLM预测结果的分布可能会有所不同。图1显示了一个例子,图书域审查和视频域审查之间的差异导致了标签词的不同可能性。图书领域评论中的高频标签词是“有用的”,而视频领域评论是“真实的”,两者都不在预定义的“ 。
提示输入 $\boldsymbol{x}_{\text {prompt }}$:
$\boldsymbol{x}_{\text {prompt }}= {[\mathbf{e}(\text { "CLS }] "), \mathbf{e}(\boldsymbol{x}), \mathbf{h}_{0}, \ldots, \mathbf{h}_{k-1}, }\mathbf{e}(\text { "[MASK]") }, \mathbf{e}(\text { "[SEP]") })]$ 。
注意:输入 $\boldsymbol{x}_{\text {prompt }}$ 不是一个 $\text{raw text}$ ,而是一个嵌入矩阵,$\text{nn.Embedding}$ 后的结果; 。
将提示输出作为编码器的输入,得到:
$\mathbf{h}_{[\mathrm{MASK}]}, \mathbf{s}_{[\mathrm{MASK}]}=\mathcal{M}\left(\boldsymbol{x}_{\text {prompt }}\right) $ 。
其中,$\mathbf{h}_{[\text {MASK }]} \in \mathbb{R}^{h}$,$\mathbf{s}_{[\text {MASK }]} \in \mathbb{R}^{|\mathcal{V}|}$,$\mathrm{s}_{[\mathrm{MASK}]}= f\left(\mathbf{h}_{[\text {MASK }]}\right) $,$f$ 是 $\text{MLM head function}$; 。
情感预测:
$\begin{aligned}p(y \mid \boldsymbol{x}) & =p\left(\mathcal{V}_{y}^{*} \leftarrow[\mathrm{MASK}] \mid \boldsymbol{x}_{\text {prompt }}\right) \\& =\frac{\exp \left(\mathbf{s}_{[\mathrm{MASK}]}\left(\mathcal{V}_{y}^{*}\right)\right)}{\sum_{y^{\prime} \in \mathcal{Y}} \exp \left(\mathbf{s}_{[\mathrm{MASK}]}\left(\mathcal{V}_{y^{\prime}}^{*}\right)\right)}\end{aligned}$ 。
其中,$\mathcal{V}^{*} \in \{ \text{good,bad} \}$; 。
情感分类损失:
$\mathcal{L}_{\text {class }}\left(\mathcal{S} ; \theta_{\mathcal{M}, p, f}\right) =-\sum_{i=1}^{N} {\left[\log p\left(y_{i} \mid \boldsymbol{x}_{i}\right)^{\mathbb{I}\left\{\hat{y}_{i}=1\right\}}\right.} \left.+\log \left(1-p\left(y_{i} \mid \boldsymbol{x}_{i}\right)\right)^{\mathbb{I}\left\{\hat{y}_{i}=0\right\}}\right]$ 。
设有 $\text{m}$ 个源域 ,源域、目标域的域标签分别为 $0 , 1$,$m$ 个域鉴别器 $\mathbf{g}=\left\{g_{l}\right\}_{l=1}^{m}$; 。
域预测:
$p(d \mid \boldsymbol{x})=\frac{\exp \left(g_{l}^{d}\left(\mathbf{h}_{[\mathrm{MASK}]}\right)\right)}{\sum_{d^{\prime} \in \mathcal{D}} \exp \left(g_{l}^{d^{\prime}}\left(\mathbf{h}_{[\mathrm{MASK}]}\right)\right)}$ 。
域分类损失:
$\mathcal{L}_{\text {domain }}\left(\hat{\mathcal{S}}, \mathcal{T} ; \theta_{\mathcal{M}, p, \mathbf{g}}\right) =-\sum_{l=1}^{m} \sum_{i=1}^{N_{l}^{s}+N^{t}} {\left[\log p\left(d_{i} \mid \boldsymbol{x}_{i}\right)^{\mathbb{I}\left\{\hat{d}_{i}=1\right\}}\right.}\left.+\log \left(1-p\left(d_{i} \mid \boldsymbol{x}_{i}\right)\right)^{\mathbb{I}\left\{\hat{d}_{i}=0\right\}}\right]$ 。
域对抗训练:
$\underset{\mathcal{M}, p}{\text{max}}\; \underset{\mathbf{g}}{\text{min}} \;\mathcal{L}_{\text {domain }}\left(\hat{\mathcal{S}}, \mathcal{T} ; \theta_{\mathcal{M}, p, \mathbf{g}}\right)$ 。
优化 $\text{PLM}$ $\mathcal{M}$ ,$\text{soft prompt embeddings}$ $p$ , $\text{MLM head function}$ $f$,$\text{domain discriminators }$ $\mathbf{g}$:
$\underset{\mathcal{M}, p, f}{\text{min}} \{ \lambda \mathcal{L}_{\text {class }}\left(\mathcal{S} ; \theta_{\mathcal{M}, p, f}\right) \left.-\underset{\mathbf{g}}{\text{min}} \mathcal{L}_{\text {domain }}\left(\hat{\mathcal{S}}, \mathcal{T} ; \theta_{\mathcal{M}, p, \mathbf{g}}\right)\right\}$ 。
如下:

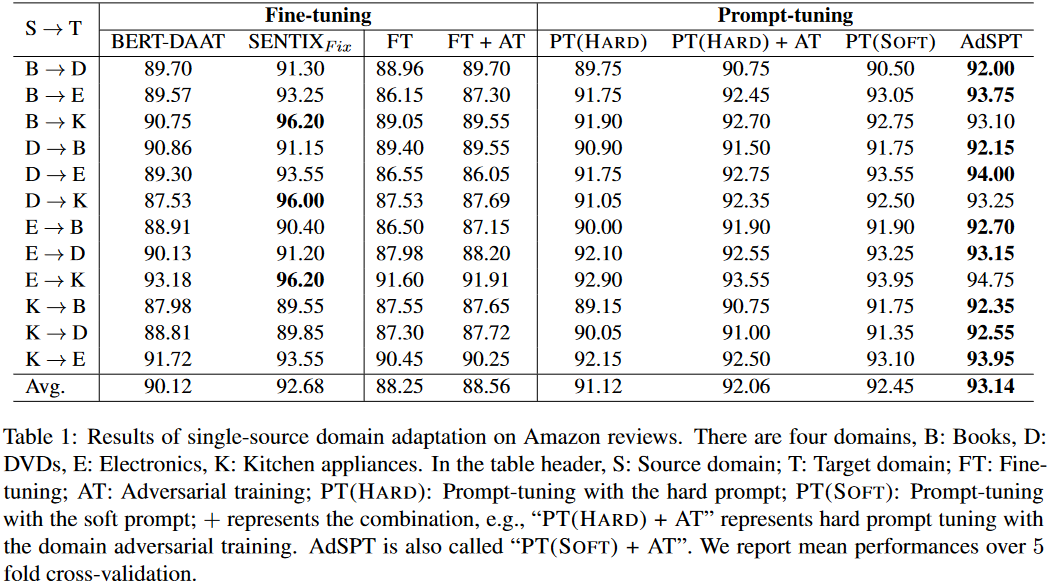
single-source domain adaptation on Amazon reviews 。
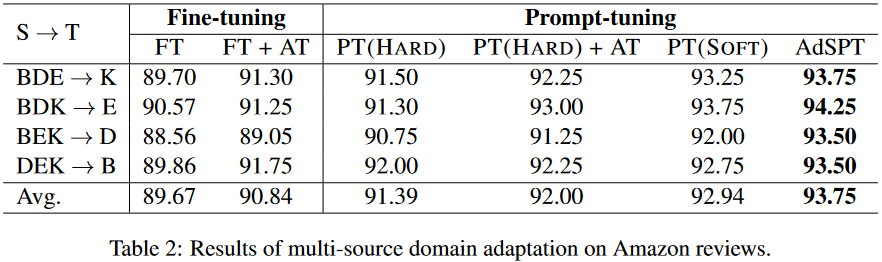
Results of multi-source domain adaptation on Amazon reviews 。
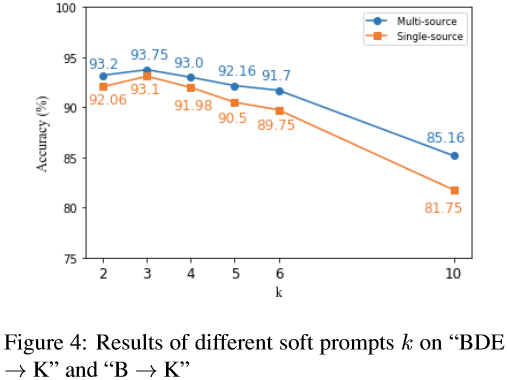
Ablation experiments 。
最后此篇关于论文解读(AdSPT)《AdversarialSoftPromptTuningforCross-DomainSentimentAnalysis》的文章就讲到这里了,如果你想了解更多关于论文解读(AdSPT)《AdversarialSoftPromptTuningforCross-DomainSentimentAnalysis》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0

我是一名优秀的程序员,十分优秀!