
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 32
32
 4
4


作为一名后端软件工程师,工作中你肯定和 Redis 打过交道。但是Redis 为什么快呢?很多人只能答出Redis 因为它是基于内存实现的,但是对于其它原因都是模棱两可.
那么今天就一起来看看是Redis 为什么快吧:
。
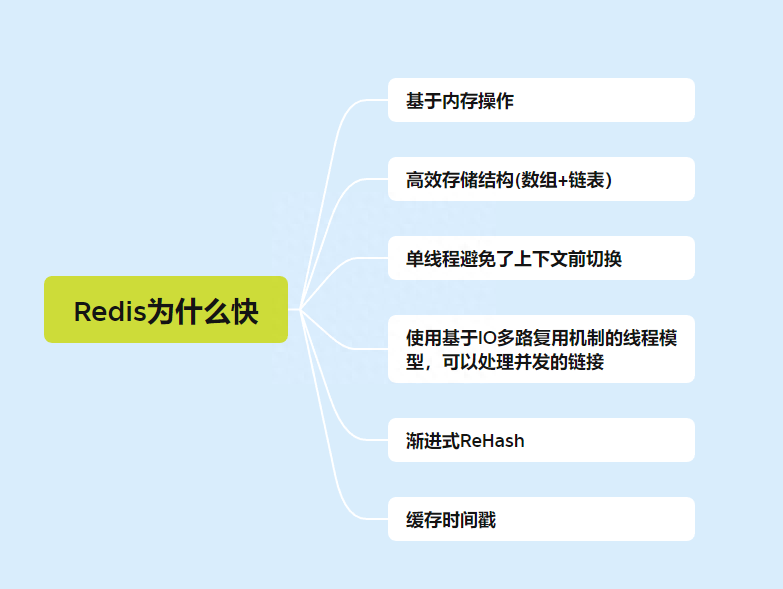
Redis 为什么这么快?
。
Redis 是基于内存的数据库,那不可避免的就要与磁盘数据库做对比。对于磁盘数据库来说,是需要将数据读取到内存里的,这个过程会受到磁盘 I/O 的限制。而对于内存数据库来说,本身数据就存在于内存里,也就没有了这方面的开销.
通过下面的表格我们可以知道读取内存和读取磁盘的性能差距.
| 计算机设备 。 |
读取的速度 。 |
类比 。 |
| 机械硬盘 。 |
0.1G/S 。 |
以机械盘为基准 。 |
| 固态盘 。 |
1.3G/S 。 |
13倍机械硬盘 。 |
| 内存 。 |
30G/S 。 |
300倍机械硬盘 。 |
| L3 。 |
190G/S 。 |
1900倍机械硬盘 。 |
| L2 。 |
200G/S 。 |
2000倍 机械硬盘 。 |
| L1 。 |
800G/S 。 |
8000倍机械硬盘 。 |
。
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据.
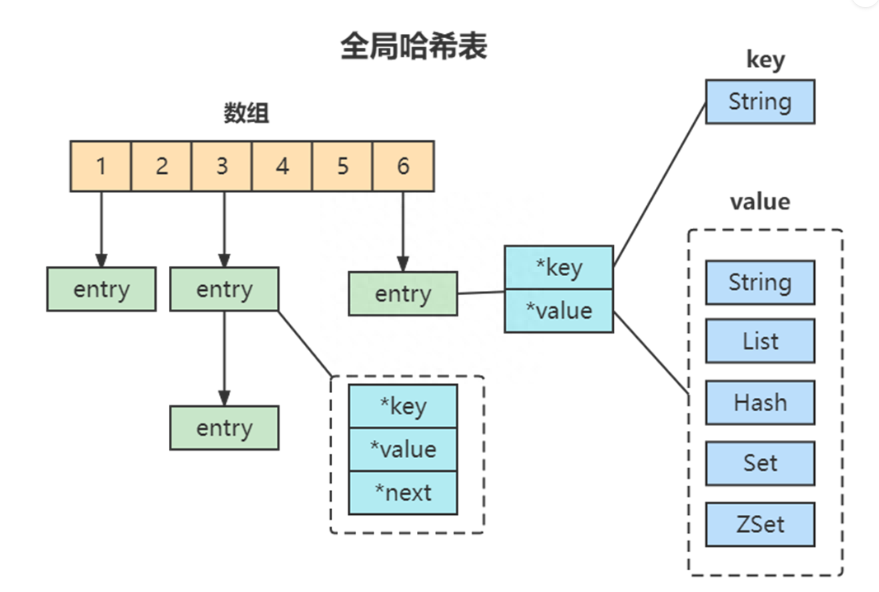
全局哈希表 。
。
哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,因为其value的多样性,哈希表中存储的并不是具体的值,而是一个内存引用地址,在通过内存引用的地址查找到对应的具体的值。这样一来,即使value是一个集合,也可以通过*value指针被查找到。因为这个哈希表保存了所有的键值对,所以,我也把它称为全局哈希表.
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对:我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。但当你往 Redis 中写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞.
当你往哈希表中写入更多数据时,哈希冲突是不可避免的问题。这里的哈希冲突,两个 key 的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中.
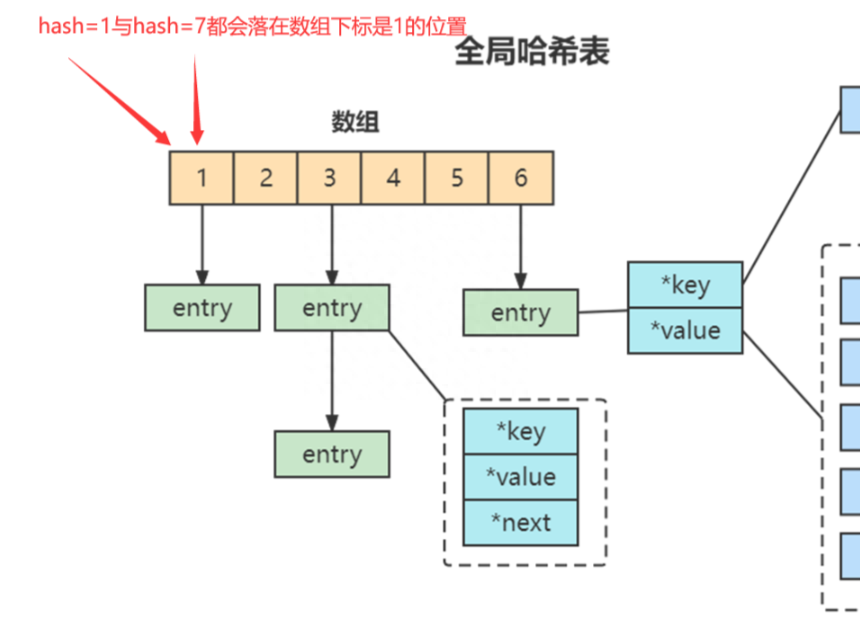
哈希表的哈希冲突 。
。
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接.
。
省去了很多上下文切换的时间以及CPU消耗,不存在竞争条件,不用去考虑各种锁的问题,不存在加锁释放锁操作,也不会出现死锁而导致的性能消耗.
。
Redis采用了epoll 模型进行IO多路复用。Java中也有类似的模型比如NIO,才epoll模型之前还有selector、poll这里不多讲解,epoll模型可以参考下图:
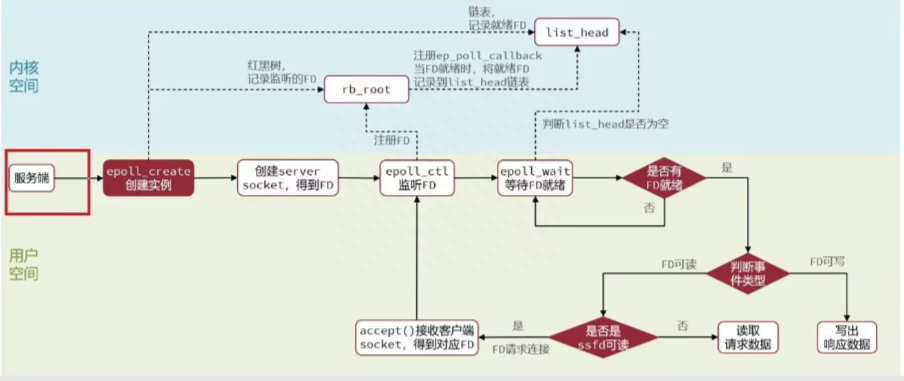
epoll 模型 。
。
Redis是当然如果这个数组一直不变,那么hash冲突会变很多,这个时候检索效率会大打折扣,所以Redis就需要把数组进行扩容(一般是扩大到原来的两倍),但是问题来了,扩容后每个hash桶的数据会分散到不同的位置,这里设计到元素的移动,必定会阻塞IO,所以这个ReHash过程会导致很多请求阻塞.
为了避免这个问题,Redis 采用了渐进式 rehash.
首先、Redis 默认使用了 两个全局哈希表 :哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash.
1、给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍 。
2、把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中 。
3、释放哈希表 1 的空间 。
在上面的第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。此时,Redis 就无法快速访问数据了.
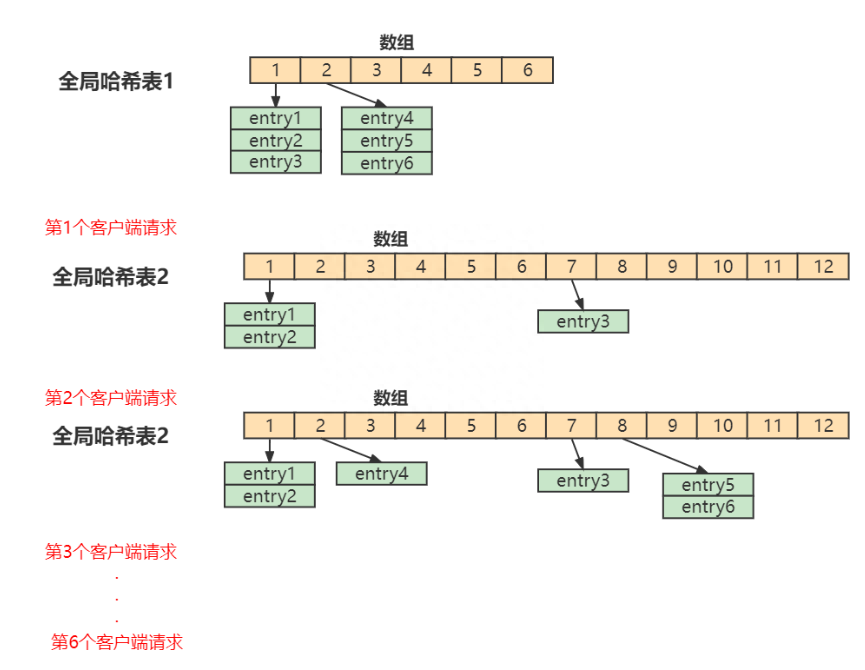
渐进式rehash 。
。
在Redis 开始执行 rehash,Redis仍然正常处理客户端请求,但是要加入一个额外的处理:
处理第1个请求时,把哈希表 1中的第1个索引位置上的所有 entries 拷贝到哈希表 2 中 。
处理第2个请求时,把哈希表 1中的第2个索引位置上的所有 entries 拷贝到哈希表 2 中 。
如此循环,直到把所有的索引位置的数据都拷贝到哈希表 2 中.
这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问.
所以这里基本上也可以确保根据key找value的操作在 O(1) 左右.
过这里要注意,如果Redis中有海量的key值的话,这个Rehash过程会很长很长,虽然采用渐进式Rehash,但在Rehash的过程中还是会导致请求有不小的卡顿。并且像一些统计命令也会非常卡顿:比如keys 。
按照Redis的配置每个实例能存储的最大的key的数量为2的32次方,即2.5亿,但是尽量把key的数量控制在千万以下,这样就可以避免Rehash导致的卡顿问题,如果数量确实比较多,建议采用分区hash存储.
。
我们平常使用系统时间戳时, 常常是不假思索地使用System.currentTimeMillis()或者 new Date() .getTime() 来获取系统的毫秒时间戳。但是Redis不能这样做,因为每一次获取系统时间戳都是一次系统调用,而且每次去系统调用是比较费时间的,作为单线程的Redis是无法承受的,所以它需要对于时间戳进行一次缓存,由一个定时任务进行每毫秒更新时间戳,从而获取时间戳都是直接从缓存就取出.
最后此篇关于Redis为什么这么快?的文章就讲到这里了,如果你想了解更多关于Redis为什么这么快?的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
32
4
 0
0
我有一个关于 Redis Pubsub 的练习,如下所示: 如果发布者发布消息但订阅者没有收到服务器崩溃。订阅者如何在重启服务器时收到该消息? 请帮帮我,谢谢! 最佳答案 在这种情况下,消息将永远消失
我们正在使用 Service Stack 的 RedisClient 的 BlockingDequeue 来保存一些数据,直到它可以被处理。调用代码看起来像 using (var client =
我有一个 Redis 服务器和多个 Redis 客户端。每个 Redis 客户端都是一个 WebSocket+HTTP 服务器,其中包括管理 WebSocket 连接。这些 WebSocket+HTT
我有多个 Redis 实例。我使用不同的端口创建了一个集群。现在我想将数据从预先存在的 redis 实例传输到集群。我知道如何将数据从一个实例传输到集群,但是当实例多于一个时,我无法做到这一点。 最佳
配置:三个redis集群分区,跨三组一主一从。当 Master 宕机时,Lettuce 会立即检测到中断并开始重试。但是,Lettuce 没有检测到关联的 slave 已经将自己提升为 master
我想根据从指定集合中检索这些键来删除 Redis 键(及其数据集),例如: HMSET id:1 password 123 category milk HMSET id:2 password 456
我正在编写一个机器人(其中包含要禁用的命令列表),用于监视 Redis。它通过执行禁用命令,例如 (rename-command ZADD "")当我重新启动我的机器人时,如果要禁用的命令列表发生变化
我的任务是为大量听众使用发布/订阅。这是来自 docs 的订阅的简化示例: r = redis.StrictRedis(...) p = r.pubsub() p.subscribe('my-firs
我一直在阅读有关使用 Redis 哨兵进行故障转移的内容。我打算有1个master+1个slave,如果master宕机超过1分钟,就把slave变成master。我知道这在 Sentinel 中是
与仅使用常规 Redis 和创建分片相比,使用 Redis 集群有哪些优势? 在我看来,Redis Cluster 更注重数据安全(让主从架构解决故障)。 最佳答案 我认为当您需要在不丢失任何数据的情
由于 Redis 以被动和主动方式使 key 过期, 有没有办法得到一个 key ,即使它的过期时间已过 (但 在 Redis 中仍然存在 )? 最佳答案 DEBUG OBJECT myKey 将返回
我想用redis lua来实现monitor命令,而不是redis-cli monitor。但我不知道怎么办。 redis.call('monitor') 不起作用。 最佳答案 您不能从 Redis
我读过 https://github.com/redisson/redisson 我发现有几个 Redis 复制设置(包括对 AWS ElastiCache 和 Azure Redis 缓存的支持)
Microsoft.AspNet.SignalR.Redis 和 StackExchange.Redis.Extensions.Core 在同一个项目中使用。前者需要StackExchange.Red
1. 认识 Redis Redis(Remote Dictionary Server)远程词典服务器,是一个基于内存的键值对型 NoSQL 数据库。 特征: 键值(key-value)型,value
1. Redis 数据结构介绍 Redis 是一个 key-value 的数据库,key 一般是 String 类型,但 value 类型多种多样,下面就举了几个例子: value 类型 示例 Str
1. 什么是缓存 缓存(Cache) 就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。 缓存的作用: 降低后端负载 提高读写效率,降低响应时间 缓存的成本: 数据一致性成本 代码维护成本
我有一份记录 list 。对于我的每条记录,我都需要进行一些繁重的计算,因为我要在Redis中创建反向索引。为了达到到达记录,需要在管道中执行多个redis命令(sadd为100 s + set为1
我有一个三节点Redis和3节点哨兵,一切正常,所有主服务器和从属服务器都经过验证,并且哨兵配置文件已与所有Redis和哨兵节点一起更新,但是问题是当Redis主服务器关闭并且哨兵希望选举失败者时再次
我正在尝试计算Redis中存储的消息之间的响应时间。但是我不知道该怎么做。 首先,我必须像这样存储chat_messages的时间流 ZADD conversation:CONVERSATION_ID

我是一名优秀的程序员,十分优秀!