
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


Pandas 可以很方便的处理 JSON 数据 。
demo.json 。
[
{
"name":"张三",
"age":23,
"gender":true
},
{
"name":"李四",
"age":24,
"gender":true
},
{
"name":"王五",
"age":25,
"gender":false
}
]
非常方便,只要通过 pd.read_json 读出JSON数据,再通过 df.to_csv 写入 CSV 即可 。
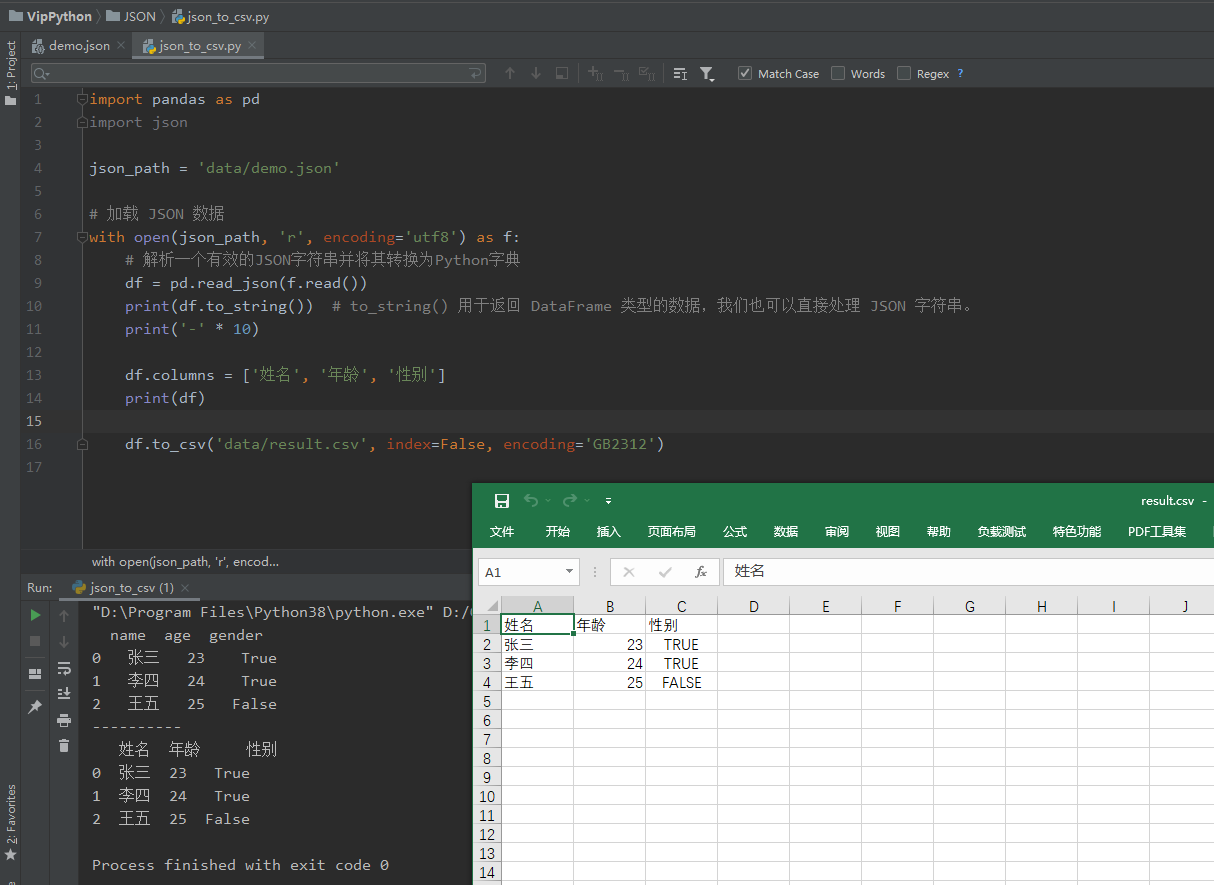
import pandas as pd
json_path = 'data/demo.json'
# 加载 JSON 数据
with open(json_path, 'r', encoding='utf8') as f:
# 解析一个有效的JSON字符串并将其转换为Python字典
df = pd.read_json(f.read())
print(df.to_string()) # to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
print('-' * 10)
# 重新定义标题
df.columns = ['姓名', '年龄', '性别']
print(df)
df.to_csv('data/result.csv', index=False, encoding='GB2312')
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL) # 和读文件一样
print(df)
输出:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
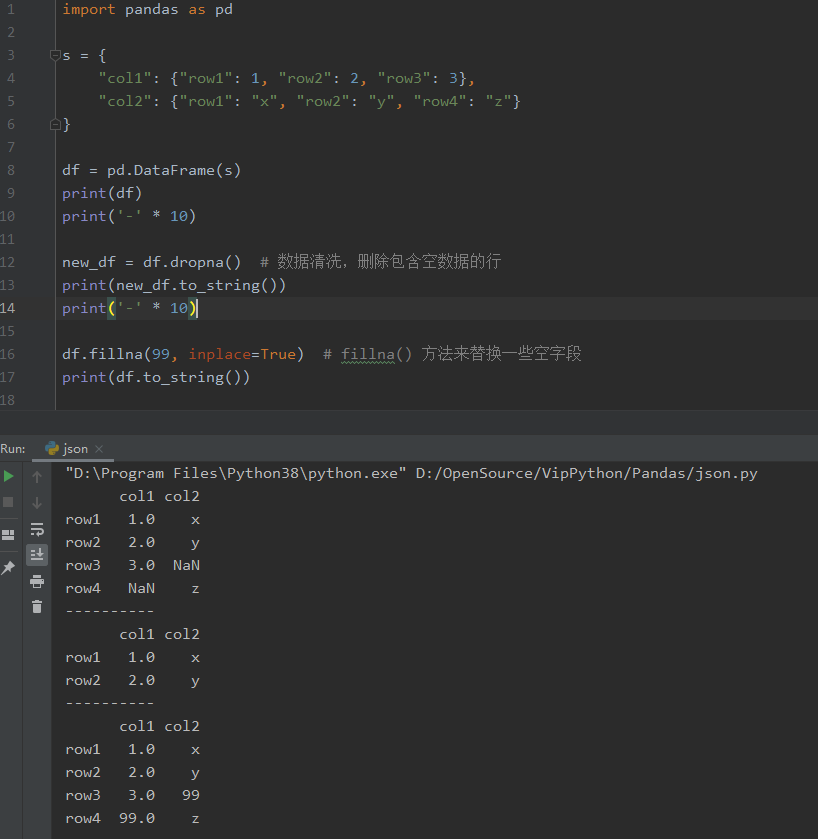
import pandas as pd
s = {
"col1": {"row1": 1, "row2": 2, "row3": 3},
"col2": {"row1": "x", "row2": "y", "row4": "z"}
}
df = pd.DataFrame(s)
print(df)
print('-' * 10)
new_df = df.dropna() # 数据清洗,删除包含空数据的行
print(new_df.to_string())
print('-' * 10)
df.fillna(99, inplace=True) # fillna() 方法来替换一些空字段
print(df.to_string())
输出:不同的行会用 NaN 填充 。
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 NaN
row4 NaN z
----------
col1 col2
row1 1.0 x
row2 2.0 y
----------
col1 col2
row1 1.0 x
row2 2.0 y
row3 3.0 99
row4 99.0 z
nested_list.json 嵌套的JSON数据 。
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}
]
}
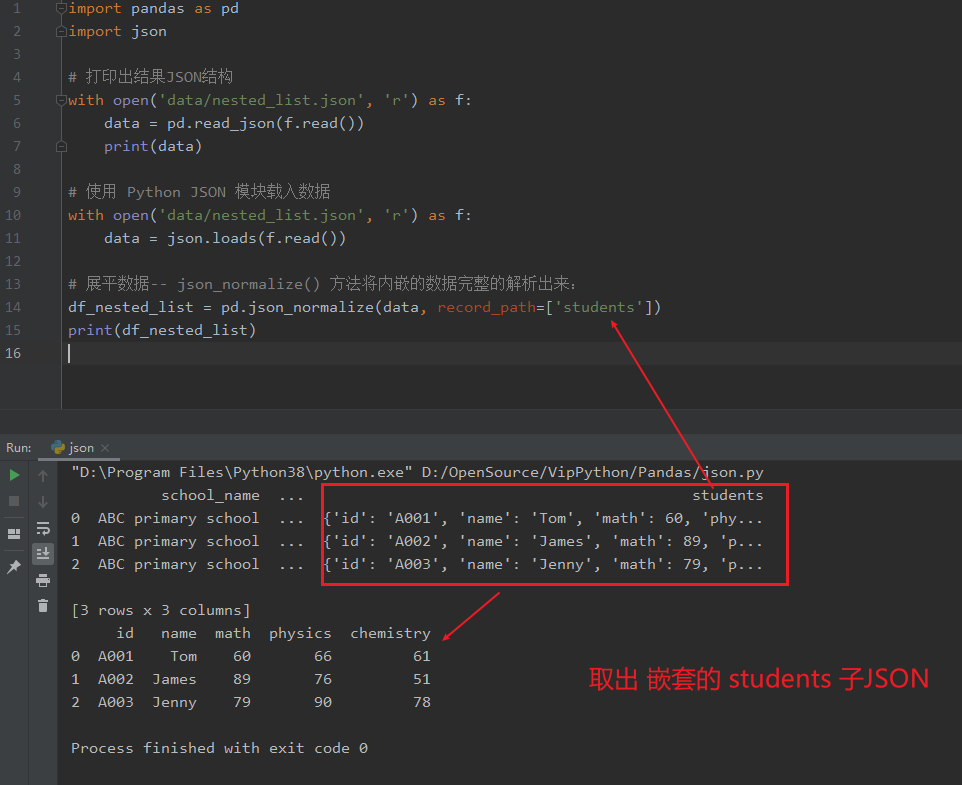
运行代码 data = json.loads(f.read()) 使用 Python JSON 模块载入数据。 json_normalize() 使用了参数 record_path 并设置为 ['students'] 用于展开内嵌的 JSON 数据 students.
import pandas as pd
import json
# 打印出结果JSON结构
with open('data/nested_list.json', 'r') as f:
data = pd.read_json(f.read())
print(data)
# 使用 Python JSON 模块载入数据
with open('data/nested_list.json', 'r') as f:
data = json.loads(f.read())
# 展平数据-- json_normalize() 方法将内嵌的数据完整的解析出来:
df_nested_list = pd.json_normalize(data, record_path=['students'])
print(df_nested_list)
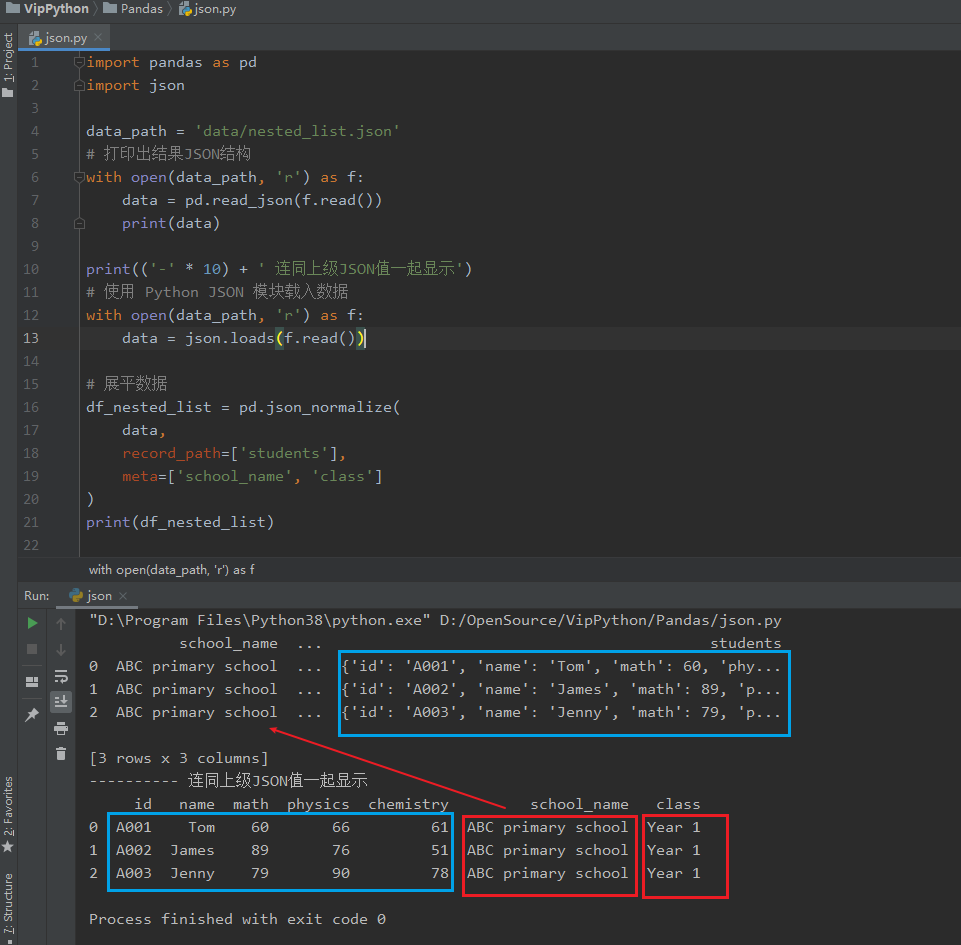
import pandas as pd
import json
data_path = 'data/nested_list.json'
print(('-' * 10) + ' 连同上级JSON值一起显示')
# 使用 Python JSON 模块载入数据
with open(data_path, 'r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path=['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
该数据嵌套了列表和字典,数据文件 nested_mix.json 如下 nested_mix.json 。
{
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "admin@e.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('data/nested_mix.json', 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'], # 类似 info.president
['info', 'contacts', 'tel']
]
)
print(df)
id name math ... class info.president info.contacts.tel
0 A001 Tom 60 ... Year 1 John Kasich 123456789
1 A002 James 89 ... Year 1 John Kasich 123456789
2 A003 Jenny 79 ... Year 1 John Kasich 123456789
[3 rows x 8 columns]
读取内嵌数据中的一组数据 nested_deep.json 。
{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性.
第一次使用我们需要安装 glom: pip3 install glom -i https://pypi.tuna.tsinghua.edu.cn/simple 。
import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
输出:
0 60
1 89
2 79
最后此篇关于Pandas使用教程JSON的文章就讲到这里了,如果你想了解更多关于Pandas使用教程JSON的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
pandas.crosstab 和 Pandas 数据透视表似乎都提供了完全相同的功能。有什么不同吗? 最佳答案 pivot_table没有 normalize争论,不幸的是。 在 crosstab
我能找到的最接近的答案似乎太复杂:How I can create an interval column in pandas? 如果我有一个如下所示的 pandas 数据框: +-------+ |
这是我用来将某一行的一列值移动到同一行的另一列的当前代码: #Move 2014/15 column ValB to column ValA df.loc[(df.Survey_year == 201
我有一个以下格式的 Pandas 数据框: df = pd.DataFrame({'a' : [0,1,2,3,4,5,6], 'b' : [-0.5, 0.0, 1.0, 1.2, 1.4,
所以我有这两个数据框,我想得到一个新的数据框,它由两个数据框的行的克罗内克积组成。正确的做法是什么? 举个例子:数据框1 c1 c2 0 10 100 1 11 110 2 12
TL;DR:在 pandas 中,如何绘制条形图以使其 x 轴刻度标签看起来像折线图? 我制作了一个间隔均匀的时间序列(每天一个项目),并且可以像这样很好地绘制它: intensity[350:450
我有以下两个时间列,“Time1”和“Time2”。我必须计算 Pandas 中的“差异”列,即 (Time2-Time1): Time1 Time2
从这个 df 去的正确方法是什么: >>> df=pd.DataFrame({'a':['jeff','bob','jill'], 'b':['bob','jeff','mike']}) >>> df
我想按周从 Pandas 框架中的列中累积计算唯一值。例如,假设我有这样的数据: df = pd.DataFrame({'user_id':[1,1,1,2,2,2],'week':[1,1,2,1,
数据透视表的表示形式看起来不像我在寻找的东西,更具体地说,结果行的顺序。 我不知道如何以正确的方式进行更改。 df示例: test_df = pd.DataFrame({'name':['name_1
我有一个数据框,如下所示。 Category Actual Predicted 1 1 1 1 0
我有一个 df,如下所示。 df: ID open_date limit 1 2020-06-03 100 1 2020-06-23 500
我有一个 df ,其中包含与唯一值关联的各种字符串。对于这些唯一值,我想删除不等于单独列表的行,最后一行除外。 下面使用 Label 中的各种字符串值与 Item 相关联.所以对于每个唯一的 Item
考虑以下具有相同名称的列的数据框(显然,这确实发生了,目前我有一个像这样的数据集!:() >>> df = pd.DataFrame({"a":range(10,15),"b":range(5,10)
我在 Pandas 中有一个 DF,它看起来像: Letters Numbers A 1 A 3 A 2 A 1 B 1 B 2
如何减去两列之间的时间并将其转换为分钟 Date Time Ordered Time Delivered 0 1/11/19 9:25:00 am 10:58:00 am
我试图理解 pandas 中的下/上百分位数计算,但有点困惑。这是它的示例代码和输出。 test = pd.Series([7, 15, 36, 39, 40, 41]) test.describe(
我有一个多索引数据框,如下所示: TQ bought HT Detailed Instru
我需要从包含值“低”,“中”或“高”的数据框列创建直方图。当我尝试执行通常的df.column.hist()时,出现以下错误。 ex3.Severity.value_counts() Out[85]:
我试图根据另一列的长度对一列进行子串,但结果集是 NaN .我究竟做错了什么? import pandas as pd df = pd.DataFrame([['abcdefghi','xyz'],

我是一名优秀的程序员,十分优秀!