
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 32
32
 4
4



前段时间我们想实现 Pulsar 消息的追踪流程,追踪实现的效果图如下:
实现其实比较简单,其中最重要的就是如何存储消息.
消息的读取我们是通过 Pulsar 自带的 BrokerInterceptor 实现的,对这个感兴趣的朋友后面会单独做一个分享.
根据这里的显示内容我们大概需要存储这些信息:
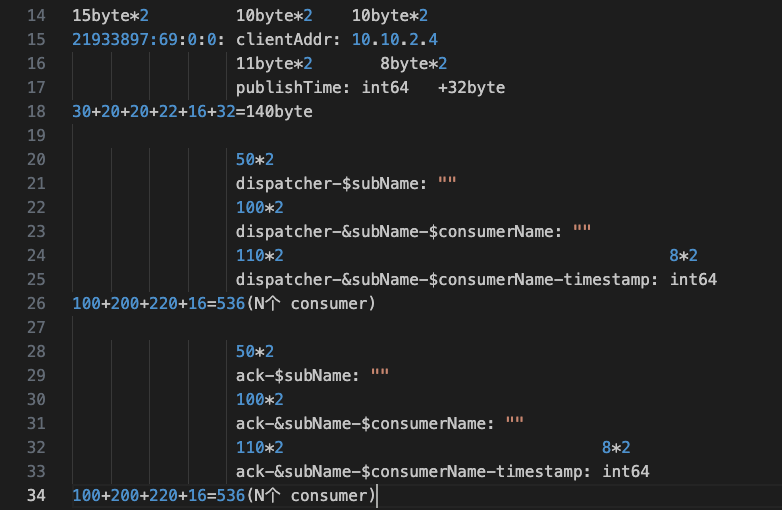
都以两个 consumer 计算: 一条消息占用内存: 140+ 535*2 + 536*2 =2282byte 存储三天: TPS * 86400 * 3 = TPS*259200 条 总存储: 2282*TPS*259200≈ 百GB 。
根据我们的 TPS 计算,三天的大概会使用到 上百 G 的存储,这样首先就排除了 Redis 这种内存型数据库.
同样的换成 MySQL 存储也不划算,因为其实这些数据并不算那么重要.
做了几个技术选型都不太满意,不是资源开销太大就是没有相关的运维经验.
后面在领导的提醒下,我们使用的 VictoriaMetrics 开源了一个 VictoriaLogs ,虽然当时的版本还是 0.1.0 ,使用过他们家 Metrics 的应该都会比较信任他们的技术能力,所以就调研了一下.
具体的信息可以查看官方文档: https://docs.victoriametrics.com/VictoriaLogs/ 。

简单来说就是它也是一个日志存储数据库,并且有着极低的资源占有率,相对于 ElasticSearch 来说内存、磁盘、CPU 都是几十倍的下降率.
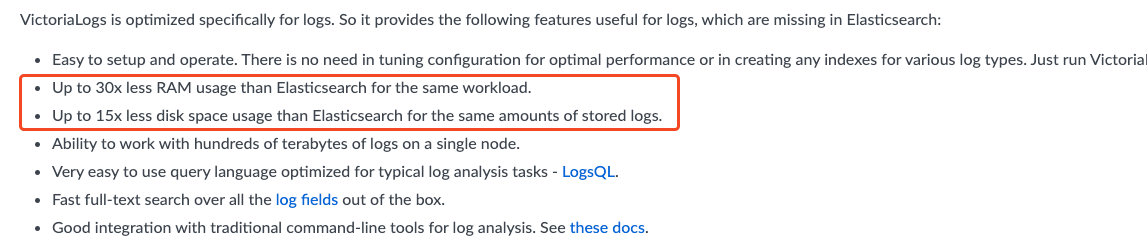
通过官方的压测对比图会发现确实在各方面对 ES 都是碾压.
官方宣传的第一反应是不能全信,于是我自己压测了一下,果然 CPU 内存 磁盘的占用都是极低的.
同时也发现运维部署确实简单,直接一个 helm install 就搞定,就是一个二进制文件,不会依赖第二个组件.
按照刚才同样的数据存储三天,只需要不到 6G 的磁盘空间,我们生产环境已经平稳运行一段时间了。 因为我们是批量写入数据的,所以在最高峰 20K 的 TPS 下 CPU 使用不到 0.1 核,内存使用最高 120M ,这点确实是对 ES 碾压了.
磁盘占用也是非常少.
这些有点得归功于它有些的压缩、编解码算法,以及 Golang 带来的相对于 Java 的极低资源占用.
如果一切都这么完美的话那 VictoriaLogs 确实也太变态了, 自然他也有一些不太完美的地方.
首先第一个是分词功能有限,只能做简单的搜索,无法做到类似于 ES 的各种分词,插件当然也别想了.
当前版本不支持集群部署,也就是无法横向扩展了;不过幸好他的的单机性能已经非常强了.
这也是目前阶段部署简单的原因.
VictoriaLogs 支持为数据配置过期时间自动删除,有点类似于 Redis,它会在后台启动一个协程定期判断数据是否过期,但只能对所有数据统一设置.
比如我想在 VictoriaLogs 中存放两种不同类型的数据,同时他们的过期删除时间也不相同;比如一个是三天删除,一个是三月后删除.
这样的需求目前是无法实现的,只能部署两个 VictoriaLogs . 。
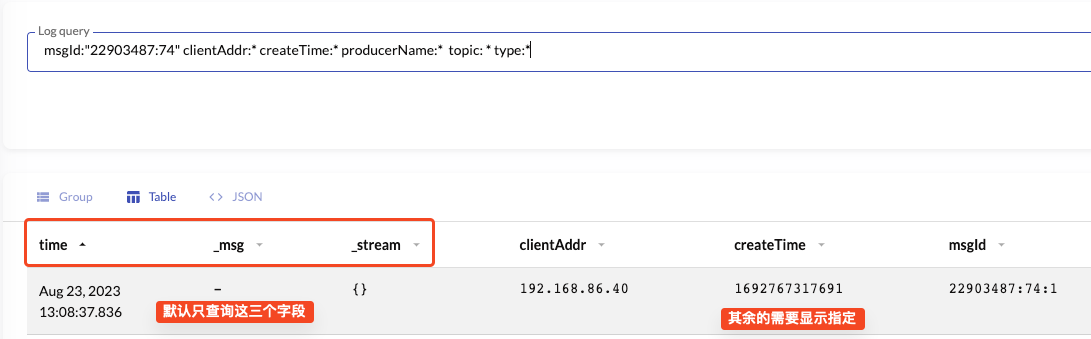
由于 VictoriaLogs 可以存储非结构化数据,默认情况下只能查询内置的三个字段,我们自定义的字段目前没法自动查询,需要我们手动指定.
这个倒不是致命问题,只是使用起来稍微麻烦一些;社区也有一些反馈,相信不久就会优化该功能.
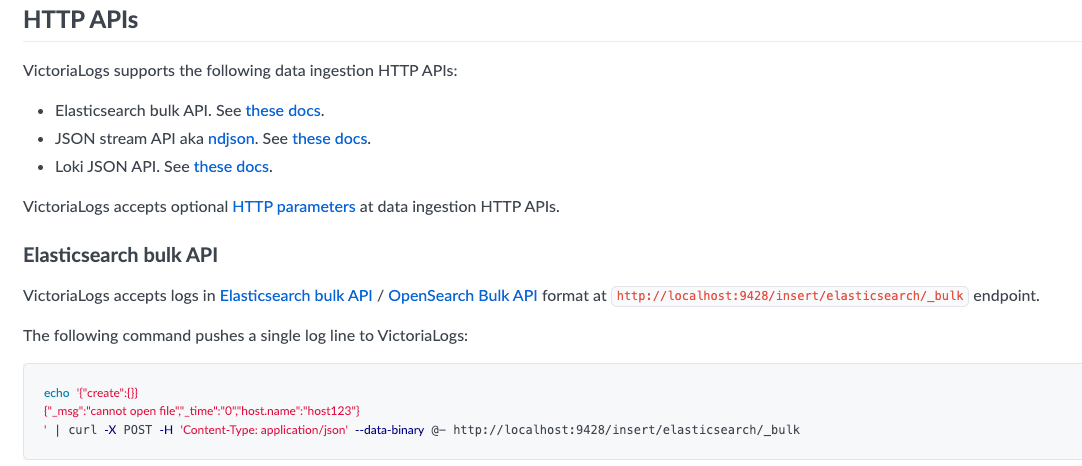
这也是个有了更好的一个功能,目前只能根据 REST API 自己编写.
当前我们只用来存储 Pulsar 链路追踪数据,目前看来非常稳定,各方面资源占用极少;所以后续我们会陆续讲一些日志类型的数据迁移过来,比如审计日志啥的.
之后再逐步完善功能后,甚至可以将所有应用存放在 ElasticSeach 中的日志也迁移过来,这样确实能省下不少资源.
总得来说 VictoriaLogs 资源占用极少,如果只是拿来存储日志相关的数据,没有很强的分词需求那它将非常合适.
截止到目前最新版也才 0.3.0 还有很大的进步空间,有类似需求的可以持续关注.
最后此篇关于VictoriaLogs:一款超低占用的ElasticSearch替代方案的文章就讲到这里了,如果你想了解更多关于VictoriaLogs:一款超低占用的ElasticSearch替代方案的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
32
4
 0
0
我在这里有一个问题,我不知道这是否正常。 但是我认为这里有些湖,安装插件elasticsearch-head之后,我在浏览器中启动url“http://localhost:9200/_plugin/h
我写了这个 flex 搜索查询: es.search(index=['ind1'],doc_type=['doc']) 我得到以下结果: {'_shards': {'failed': 0, 'skip
在ElasticSearch.Net v.5中,存在一个属性 Elasticsearch.Net.RequestData.Path ,该属性在ElasticSearch.Net v.6中已成为depr
如何让 elasticsearch 应用新配置?我更改了文件 ~ES_HOME/config/elasticsearch.yml 中的一个字符串: # Disable HTTP completely:
我正在尝试使用以下分析器在 elastic serach 7.1 中实现部分子字符串搜索 PUT my_index-001 { "settings": { "analysis": {
假设一个 elasticsearch 服务器在很短的时间内接收到 100 个任务。有些任务很短,有些任务很耗时,有些任务是删除任务,有些是插入和搜索查询。 elasticsearch 是如何决定先运行
我需要根据日期过滤一组值(在此处添加字段),然后按 device_id 对其进行分组。所以我正在使用以下东西: { "aggs":{ "dates_between":{ "fi
我在 Elasticsearch 中有一个企业索引。索引中的每个文档代表一个业务,每个业务都有business_hours。我试图允许使用星期几和时间过滤营业时间。例如,我们希望能够进行过滤,以显示我
我有一个这样的过滤查询 query: { filtered: { query: { bool: { should: [{multi_match: {
Elasticsearch 相当新,所以可能不得不忍受我,我遇到了一个问题,如果我使用 20 个字符或更少的字符搜索文档,文档会出现,但是查询中同一个单词中的任何更多字符,我没有结果: 使用“苯氧甲基
我试图更好地理解 ElasticSearch 的内部结构,所以我想知道 ElasticSearch 在内部计算以下两种情况的术语统计信息的方式是否存在任何差异。 第一种情况是当我有这样的文件时: {
在我的 elasticsearch 索引中,我索引了一堆工作。为简单起见,我们只说它们是一堆职位。当人们在我的搜索引擎中输入职位时,我想“自动完成”可能的匹配。 我在这里调查了完成建议:http://
我在很多映射中使用多字段。在 Elastic Search 的文档中,指示应将多字段替换为“fields”参数。参见 http://www.elasticsearch.org/guide/en/ela
我有如下查询, query = { "query": {"query_string": {"query": "%s" % q}}, "filter":{"ids
我有一个Json数据 "hits": [ { "_index": "outboxprov1", "_type": "deleted-c
这可能是一个初学者的问题,但我对大小有一些疑问。 根据 Elasticsearch 规范,大小的最大值可以是 10000,我想在下面验证我的理解: 示例查询: GET testindex-2016.0
我在 Elastic Search 中发现了滚动功能,这看起来非常有趣。看了那么多文档,下面的问题我还是不清楚。 如果偏移量已经存在那么为什么要使用滚动? 即将到来的记录呢?假设它完成了所有数据的滚动
我有以下基于注释的 Elasticsearch 配置,我已将索引设置为不被分析,因为我不希望这些字段被标记化: @Document(indexName = "abc", type = "efg
我正在尝试在单个索引中创建多个类型。例如,我试图在host索引中创建两种类型(post,ytb),以便在它们之间创建父子关系。 PUT /ytb { "mappings": { "po
我尝试创建一个简单的模板,包括一些动态模板,但我似乎无法为文档编制索引。 我得到错误: 400 {"error":"MapperParsingException[mapping [_default_]

我是一名优秀的程序员,十分优秀!