
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 。
论文标题:WIND: Weighting Instances Differentially for Model-Agnostic Domain Adaptation
论文作者:
论文来源:2021 ACL
论文地址:download
论文代码: download
视屏讲解:click
出发点:传统的实例加权方法由于不能学习权重,从而不能使模型在目标领域能够很好地泛化; 。
方法:为了解决这个问题,在元学习的启发下,将领域自适应问题表述为一个双层优化问题,并提出了一种新的可微模型无关的实例加权算法。提出的方法可以自动学习实例的权重,而不是使用手动设计的权重度量。为了降低计算复杂度,在训练过程中采用了二阶逼近技术; 。
贡献:
事实:把域外、域内数据联合训练做领域适应,但并不是所有来自域外数据集的样本在训练过程中都具有相同的效果。一些关于神经机器翻译(NMT)任务的研究表明,与域内数据相关的域外实例是有益的,而与域内数据无关的实例甚至可能对翻译质量有害 .
目前的实列加权方法:
为避免域内数据的性能较差,如何有效地利用 $\mathcal{D}_{\text {in }}$ 是域转移的关键。为解决这个问题,首先从 $\mathcal{D}_{\text {in }}$ 中抽取子集 $\mathcal{D}_{i t}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{n_{1}}$,并为每个实例 $\left(x_{i}, y_{i}\right) \in \mathcal{D}_{i t} \cup \mathcal{D}_{\text {out }}$ 分配一个标量权值 $w_{i}$。本文希望在训练过程中,模型能够找到最优的权重 $\boldsymbol{w}=\left(w_{1}, \ldots, w_{n_{1}+m}\right)$,因此,权重 $w$ 是可微的,并可通过梯度下降优化。此外,将 DNN 表示为由 $\theta$ 参数化的函数 $f_{\theta}: \mathcal{X} \rightarrow \mathcal{Y}$,并将 $x_{i}$ 从输入空间映射到标签空间.
最终训练损失遵循一个加权和公式:
$\mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \boldsymbol{w})=\frac{1}{n_{1}+m} \sum_{\substack{\left(x_{i}, y_{i}\right) \;\in \; \mathcal{D}_{i t}\; \cup\; \mathcal{D}_{\text {out }}}} \; w_{i} \ell\left(f_{\boldsymbol{\theta}}\left(x_{i}\right), y_{i}\right)$ 。
其中 $\ell$ 表示损失函数,可以是任何类型的损失,如分类任务的交叉熵损失,或标签平滑交叉熵损失.
由于域内和域外数据集的数据分布存在差异,简单联合优化 $\boldsymbol{\theta}$ 和 $\boldsymbol{w}$ 可能会对 $\boldsymbol{w}$ 引入偏差。本文期望在 $\boldsymbol{w}$ 上训练的模型可以推广到域内数据。受 MAML 的启发,本文建议从 $\mathcal{D}_{i n}$ 中采样另一个子集 $\mathcal{D}_{q}=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{n_{2}}$ 命名为 查询集 ,使用这个查询集来优化 $\boldsymbol{w}$。具体来说,目标是得到一个权重向量 $w$ 减少 $\mathcal{D}_{q}$ 上的损失:
$\mathcal{L}_{q}(\boldsymbol{\theta})=\frac{1}{n_{2}} \sum_{\left(x_{i}, y_{i}\right) \in \mathcal{D}_{q}} \ell\left(f_{\boldsymbol{\theta}}\left(x_{i}\right), y_{i}\right)$ 。
总结 :随机初始化 $\boldsymbol{w}$,用 $\mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \boldsymbol{w})$ 训练一个模型,得到优化后的参数 $\boldsymbol{\theta}^{*}$,接着固定 $\boldsymbol{\theta}^{*}$ ,最小化在查询集上的损失,得到新的 $\boldsymbol{w}$.
该过程表述为以下双层优化问题:
$\begin{array}{ll}\underset{\boldsymbol{w}}{\text{min}}& \mathcal{L}_{q}\left(\boldsymbol{\theta}^{*}\right) \\\text { s.t. } & \boldsymbol{\theta}^{*}=\underset{\boldsymbol{\theta}}{\arg \min }\; \mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \boldsymbol{w})\end{array}$ 。
上述双层优化问题由于求解复杂性高,难以直接解决。受 MAML 中的优化技术启发,将每次迭代的训练过程分为以下三个步骤:
$\widehat{\boldsymbol{\theta}}=\boldsymbol{\theta}-\beta \cdot \nabla_{\boldsymbol{\theta}} \mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \boldsymbol{w})$ 。
$\begin{aligned}\boldsymbol{w}^{*} & =\underset{\boldsymbol{w}}{\arg \min } \mathcal{L}_{q}(\widehat{\boldsymbol{\theta}}) \\& =\underset{\boldsymbol{w}}{\arg \min } \mathcal{L}_{q}\left(\boldsymbol{\theta}-\beta \cdot \nabla_{\boldsymbol{\theta}} \mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \boldsymbol{w})\right)\end{aligned}$ 。
$\widehat{\boldsymbol{w}}=\boldsymbol{w}-\gamma \cdot \nabla_{\boldsymbol{w}} \mathcal{L}_{q}(\widehat{\boldsymbol{\theta}})$ 。
$\boldsymbol{\theta} \leftarrow \boldsymbol{\theta}-\beta \cdot \nabla_{\boldsymbol{\theta}} \mathcal{L}_{\text {train }}(\boldsymbol{\theta}, \widehat{\boldsymbol{w}})$ 。
对 $\nabla_{\boldsymbol{w}} \mathcal{L}_{q}(\widehat{\boldsymbol{\theta}})$ 使用链式法则:
$\begin{aligned}\widehat{\boldsymbol{w}} & =\boldsymbol{w}-\gamma \cdot \nabla_{\boldsymbol{w}} \mathcal{L}_{q}(\widehat{\boldsymbol{\theta}}) \\& =\boldsymbol{w}-\gamma \cdot \nabla_{\widehat{\boldsymbol{\theta}}} \mathcal{L}_{q} \cdot \nabla_{\boldsymbol{w}} \widehat{\boldsymbol{\theta}} \\& =\boldsymbol{w}+\beta \gamma \cdot \nabla_{\widehat{\boldsymbol{\theta}}} \mathcal{L}_{q} \cdot \nabla_{\boldsymbol{\theta}, \boldsymbol{w}}^{2} \mathcal{L}_{\text {train }}\end{aligned}$ 。
问题 :使用 $|\boldsymbol{\theta}|$,$|\boldsymbol{w}|$ 分别表示 $\boldsymbol{\theta}$,$\boldsymbol{w}$ 的维数,二阶推导 $\nabla_{\boldsymbol{\theta}, \boldsymbol{w}}^{2} \mathcal{L}_{\text {train }}$ 是一个 $|\boldsymbol{\theta}| \times|\boldsymbol{w}|$ 矩阵,无法计算和存储。幸运的是,可采用 DARTS 中使用的近似技术来解决这个问题,这种技术使用了有限差分近似:
$\begin{array}{c}\nabla_{\widehat{\boldsymbol{\theta}}} \mathcal{L}_{q} \cdot \nabla_{\boldsymbol{\theta}, \boldsymbol{w}}^{2} \mathcal{L}_{\text {train }} \approx \frac{\nabla_{\boldsymbol{w}} \mathcal{L}_{\text {train }}\left(\boldsymbol{\theta}^{+}, \boldsymbol{w}\right)-\nabla_{\boldsymbol{w}} \mathcal{L}_{\text {train }}\left(\boldsymbol{\theta}^{-}, \boldsymbol{w}\right)}{2 \epsilon} \\\boldsymbol{\theta}^{+}=\boldsymbol{\theta}+\epsilon \nabla_{\widehat{\boldsymbol{\theta}}} \mathcal{L}_{q} \\\boldsymbol{\theta}^{-}=\boldsymbol{\theta}-\epsilon \nabla_{\widehat{\boldsymbol{\theta}}} \mathcal{L}_{q} \\\end{array}$ 。
算法 。

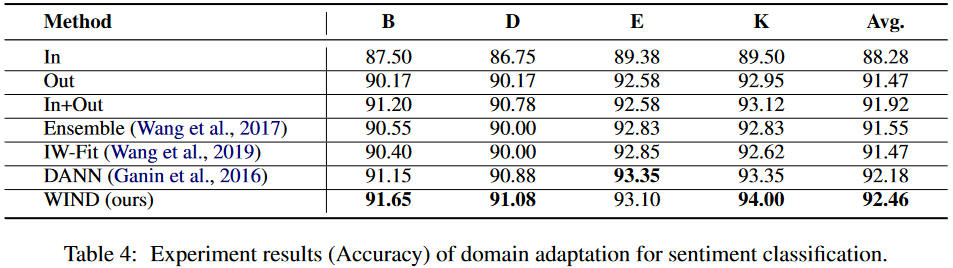
情感分析 。
。
最后此篇关于论文解读(WIND)《WIND:WeightingInstancesDifferentiallyforModel-AgnosticDomainAdaptation》的文章就讲到这里了,如果你想了解更多关于论文解读(WIND)《WIND:WeightingInstancesDifferentiallyforModel-AgnosticDomainAdaptation》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
引言 深拷贝是指创建一个新对象,该对象的值与原始对象完全相同,但在内存中具有不同的地址。这意味着如果您对原始对象进行更改,则不会影响到复制的对象 常见的C#常见的深拷贝方式有以下4类:
人工智能是一种未来性的技术,目前正在致力于研究自己的一套工具。一系列的进展在过去的几年中发生了:无事故驾驶超过300000英里并在三个州合法行驶迎来了自动驾驶的一个里程碑;IBM Waston击败了
我已经阅读了所有 HERE Maps API 文档,但找不到答案。 HERE实时流量REST API输出中的XML标签是什么意思? 有谁知道如何解释这个输出(我在我的请求中使用了接近参数)? 最佳答
我的 iPad 应用程序工作正常,我将其留在现场进行测试,但现在崩溃了[保存时?] 这是崩溃日志, Incident Identifier: 80FC6810-9604-4EBA-A982-2009A
我的程序需要 qsort 的功能才能运行,但到目前为止还没有完成它的工作。 我实际上是在对单个字符值的数组进行排序,以便将它们分组,这样我就可以遍历数组并确定每个属性的计数。我的问题是 qsort 返
就目前情况而言,这个问题不太适合我们的问答形式。我们希望答案得到事实、引用资料或专业知识的支持,但这个问题可能会引发辩论、争论、民意调查或扩展讨论。如果您觉得这个问题可以改进并可能重新开放,visit
我正在尝试使用 AVR 代码对 Arduino Uno 进行编程,因为我不被允许在 9 月份开始的高级项目中使用 Arduino 库。我找到了数据表,让数字引脚正常工作,然后尝试通过 USB 串行连接
我遇到了多次崩溃,似乎 native iOS 方法正在从第三方库调用函数。这是一个例子: Thread: Unknown Name (Crashed) 0 libsystem_kernel.d
我理解如何按照 Dijkstra 算法的解释找到从头到尾的最短路径,但我不明白的是解释。在这里,从图中的图形来看,从 A 到 E 添加到我已知集合的顺序是 A,C,B,D,F,H,G,E 我没有得到的
我正在查看一些 Django 源代码并遇到了 this . encoding = property(lambda self: self.file.encoding) 究竟是做什么的? 最佳答案 其他两
Sentry 提供了很好的图表来显示消息频率,但关于它们实际显示的内容的信息很少。 这些信息是每分钟吗? 5分钟? 15分钟?小时? 最佳答案 此图表按分钟显示。这是负责存储该图数据的模型。 http
我对 JavaScript 和 Uniswap 还很陌生。我正在使用 Uniswap V3 从 DAI/USDC 池中获取价格。我的“主要”功能如下所示: async function main()
我正在尝试弄清楚我下载的 Chrome 扩展程序是如何工作的(这是骗子用来窃取 CS:GO 元素的东西,并不重要...)。我想知道使用什么电子邮件地址(或使用什么其他通信方式)来提交被钓鱼的数据。 这
引言 今天同事问了我一个问题, System.Windows.Forms.Timer 是前台线程还是后台线程,我当时想的是它是跟着UI线程一起结束的,应该是前台线程吧? 我确实没有仔
我需要一些使用 scipy.stats.t.interval() 函数的帮助 http://docs.scipy.org/doc/scipy/reference/generated/scipy.sta
当我在 Oracle 查询计划中看到类似的内容时: HASH JOIN TABLE1 TABLE2 这两个表中的哪一个是 hashed ? Oracle 文档指的是通常被散列的“较小”
我想知道 GridSearchCV 返回的分数与按如下方式计算的 R2 指标之间的差异。在其他情况下,我收到的网格搜索分数非常负(同样适用于 cross_val_score),我将不胜感激解释它是什么
本文分享自华为云社区《 多主创新,让云数据库性能更卓越 》,作者: GaussDB 数据库。 华为《Taurus MM: bringing multi-master to the clou
我真的需要一些帮助来破译这个崩溃报告: Process: Farm Hand [616] Path: /Applications/Farm
我写了一个从 YUV_420_888 到 Bitmap 的转换,考虑到以下逻辑(据我所知): 总结该方法:内核的坐标 x 和 y 与 Y 平面(2d 分配)的非填充部分的 x 和 y 以及输出位图的

我是一名优秀的程序员,十分优秀!