
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


大家好,我是蓝胖子,关于性能分析的视频和文章我也大大小小出了有一二十篇了,算是已经有了一个系列,之前的代码已经上传到github.com/HobbyBear/performance-analyze,接下来这段时间我将在之前内容的基础上,结合自己在公司生产上构建监控系统的经验,详细的展示如何对线上服务进行监控,内容涉及到的指标设计,软件配置,监控方案等等你都可以拿来直接复刻到你的项目里,这是一套非常适合中小企业的监控体系.
在上一节我们是讲解了如何对应用服务进行监控,这一节我将会介绍如何对mysql进行监控,在传统监控mysql(对mysql整体服务质量的监控)的情况下,建立对表级别的监控,以及长事务,复杂sql的监控,并能定位到具体代码.
监控系列的代码已经上传到github 。
github.com/HobbyBear/easymonitor
无论是前文提到的 机器监控还是应用监控,我们都提到了四大黄金指标原则,对mysql 建立监控指标,我们依然可以从这几个维度去对mysql的指标进行分析.
四大黄金指标是流量,延迟,饱和度,错误数.
对于流量而言可以体现在mysql数据库操作的qps,数据库服务器进行流量大小。对于延迟,可以体现在慢查询记录上,饱和度可以用数据库的连接数,线程数,或者磁盘空间,cpu,内存等各种硬件资源来反映数据库的饱和情况。错误数则可以用,数据库访问报错信息来反应,比如连接不足,超时等错误.
由于我们是用的云数据库,上面提到的这些监控维度以及面板在云厂商那里其实都基本覆盖了,我称这些监控面板或者维度是数据库的传统监控指标。 这些指标能够反应数据库监控状况,但对于开发来讲,去进行问题排查还远远不足的,下面我讲下如果只有此类型的监控会有什么缺点以及我的解决思路.
在使用它们对mysql进行监控时当异常发生时,不是能很好的确定是哪部分业务导致的问题。比如,当你发现数据库的qps突然升高,但是接口qps比较低的时候,如何确定数据库qps升高的原因呢? 这中间存在的问题在于mysql的数据监控指标和应用服务代码逻辑没有很好的关联性,我们要如何去建立这种关联系?
答案就是建立表级别的监控 ,你可以发现传统的监控指标都是对mysql整体服务质量进行的监控,而应用业务逻辑代码本质上是对表进行操作,如果建立了表级别的监控,就能将业务与数据库监控指标联系起来。比如按表级别建立单个表的qps,当发现数据库整体的qps升高时,可以发现这是由于哪张表引起的,进而定位到具体业务,查看代码逻辑看看是哪部分逻辑会操作这张表那么多次.
下面我们就来看看如何建立表级别的监控.
mysql的performance schema其实已经暴露了表级别的某些监控项,不过由于某些原因我们线上并没有开启它,并且由于直接使用performance schema暴露的监控指标不能定制化,所以我将介绍一种在应用服务端埋点的方式建立表级别的qps。我们生产上是golang的应用服务,所以我会用它来举例.
用github.com/go-sql-driver/mysql 在golang中开启一个mysql连接是这样做
db, err = sql.Open("mysql", connStr)
sql.Open的第一个参数是驱动名,默认的驱动名是mysql,这个驱动是引入github.com/go-sql-driver/mysql时自动去创建的.
func init() {
sql.Register("mysql", &MySQLDriver{})
}
所以,我们完全可以包装默认驱动,自定义一个自己的驱动,驱动实现了open接口返回一个连接Conn的接口类型.
type Driver interface {
Open(name string) (Conn, error)
}
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}
type Stmt interface {
Close() error
NumInput() int
Exec(args []Value) (Result, error)
Query(args []Value) (Rows, error)
}
自定义的驱动类型在实现Open方法时,也可以自定义一个Conn连接类型,然后再实现它的查询接口,进行sql语句分析,解析表名后进行埋点统计.
完整的定义驱动代码已经上传到文章开头的github地址,总之,你需要明白,通过对默认驱动的包装,我们可以在sql执行前后做一些自定义的监控分析。我们定义了3个钩子函数,分别针对sql执行前后以及报错做了监控分析.
对于sql埋点的原理更详细的讲解可以参考 go database sql接口分析及sql埋点实现 。
// sql执行前做监控
if ctx, err = stmt.hooks.Before(ctx, stmt.query, list...); err != nil {
return nil, err
}
// sql执行
results, err := stmt.execContext(ctx, args)
if err != nil {
// sql 报错时做监控
return results, handlerErr(ctx, stmt.hooks, err, stmt.query, list...)
}
// sql执行后做监控
if _, err := stmt.hooks.After(ctx, stmt.query, list...); err != nil {
return nil, err
}
在sql执行前,通过SqlMonitor.parseTable对sql语句的分析,解析出当前sql涉及的表名,以及操作类型,是insert,select,delete,还是update,并且如果sql涉及到了多张表,那么会对其打上MultiTable的标签(这在下面讲sql审计时会提到),sql执行前的钩子函数如下所示:
func (h *HookDb) Before(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
ctx = context.WithValue(ctx, ctxKeyBeginTime, time.Now())
// 得到sql涉及的表名,以及这条sql是属于什么crud的哪种类型
tables, op, err := SqlMonitor.parseTable(query)
if err != nil || op == Unknown {
log.WithError(err).WithField(ctxKeySql, query).WithField("op", op).Error("parse sql fail")
}
if len(tables) >= 2 {
ctx = context.WithValue(ctx, ctxKeyMultiTable, 1)
}
if len(tables) >= 1 {
ctx = context.WithValue(ctx, ctxKeyTbName, tables[0])
}
if op != Unknown {
ctx = context.WithValue(ctx, ctxKeyOp, op)
}
return ctx, nil
}
分析出了表名并且记录上了sql的执行时长,我们可以利用prometheus的histogram 类型的指标建立表维度的p99延迟分位数,并且能够知道表级别的qps数量,如下,我们可以在sql执行后的钩子函数里完成统计,MetricMonitor.RecordClientHandlerSeconds封装了这个逻辑.
func (h *HookDb) After(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
// ....
if tbnameInf := ctx.Value(ctxKeyTbName); tbnameInf != nil && len(tbnameInf.(string)) != 0 {
tableName = tbnameInf.(string)
MetricMonitor.RecordClientHandlerSeconds(TypeMySQL, string(ctx.Value(ctxKeyOp).(SqlOp)), tbnameInf.(string), h.dbName, now.Sub(beginTime).Seconds())
// .....
}
我们可以利用这个指标在grafana上完成表级别的监控面板.
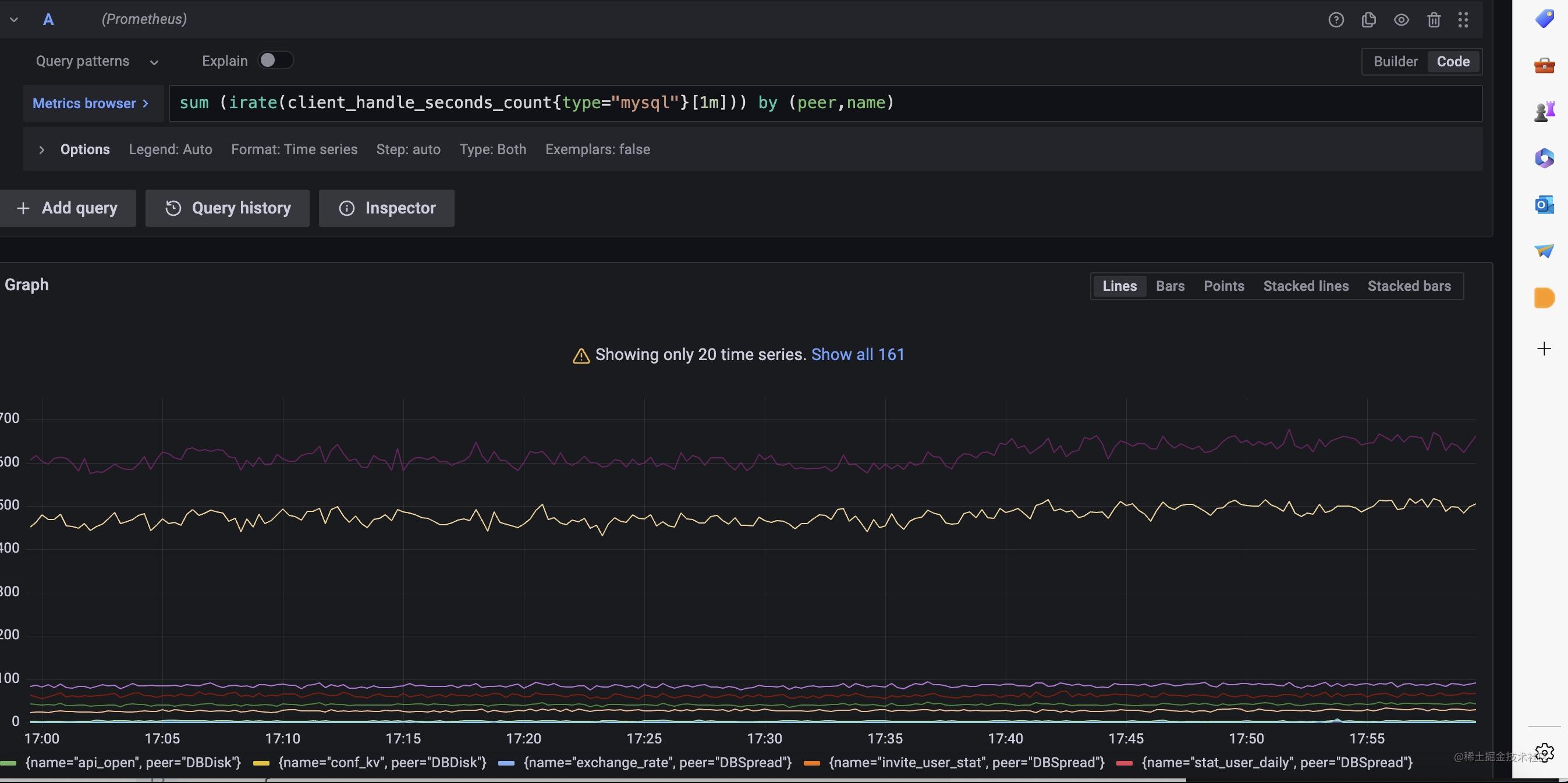
对于数据库还有要需要注意的地方,那就是长事务和复杂sql,慢sql的监控,往往出现上述情况时,就容易出现数据库的性能问题。现在我们来看看如何监控它们.
首先,来看下长事务的监控,我们可以为连接类型实现BeginTx方法,对原始driver.ConnBeginTx 事务类型进行包装,让事务携带上开始时间.
func (conn *Conn) BeginTx(ctx context.Context, opts driver.TxOptions) (driver.Tx, error) {
tx, err := conn.Conn.(driver.ConnBeginTx).BeginTx(ctx, opts)
if err != nil {
return tx, err
}
return &DriveTx{tx: tx, start: time.Now()}, nil
}
接着,在提交事务的时候,判断时间是不是超过某个8s,超过了则记录一条错误日志,并把堆栈信息也打印出来,这样方便定位是哪段逻辑产生的长事务。由于我们的错误等级的日志会被收集起来自动报警,这样就完成了长事务的实时监控报警.
func (d *DriveTx) Commit() error {
err := d.tx.Commit()
d.cost = time.Now().Sub(d.start).Milliseconds()
if d.cost > 8000 {
data := log.Fields{
Cost: d.cost,
MetricType: "longTx",
Stack: fmt.Sprintf("%+v", getStack()),
}
log.WithFields(data).Errorf("mysqlongTxlog ")
}
return err
}
接着,我们看下sql审计如何做,mysql可以打开sql审计的配置项,不过打开后将会采集所有执行的sql语句,这样会导致sql太多,我们往往只用关心那些影响性能的sql或者让数据产生变化的sql.
代码如下,我们在sql完成执行后,通过sql的执行时长,对慢sql进行告警出来,并且对涉及到两个表的sql进行日志打印,也会对修改数据的sql语句(insert,update,delete)进行记录,这对我们排查业务数据会很有帮助.
func (h *HookDb) After(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
beginTime := time.Now()
if begin := ctx.Value(ctxKeyBeginTime); begin != nil {
beginTime = begin.(time.Time)
}
now := time.Now()
tableName := ""
if tbnameInf := ctx.Value(ctxKeyTbName); tbnameInf != nil && len(tbnameInf.(string)) != 0 {
tableName = tbnameInf.(string)
MetricMonitor.RecordClientHandlerSeconds(TypeMySQL, string(ctx.Value(ctxKeyOp).(SqlOp)), tbnameInf.(string), h.dbName, now.Sub(beginTime).Seconds())
}
// 对慢sql进行实时监控,超过1s则认为是慢sql
slowquery := false
if now.Sub(beginTime).Seconds() >= 1 {
slowquery = true
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "slowLog",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Errorf("mysqlslowlog")
}
op := ctx.Value(ctxKeyOp).(SqlOp)
multitable := ctx.Value(ctxKeyMultiTable)
if !slowquery && (multitable != nil && multitable.(int) == 1) && op == Select {
// 对复杂sql进行监控,如果不是慢sql,但是sql涉及到两个表也会日志进行记录
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "multiTables",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Warnf("mysqlmultitableslog")
}
// 对修改数据的sql进行日志记录
if op != Select && op != Unknown {
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "oplog",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Infof("mysqloplog")
}
return ctx, nil
}
这一节我们完成了对mysql的监控,不过这个监控指标是在传统数据库监控项基础上建立的,目的是为了让监控指标更加容易反映到业务上,方便问题定位,在下一节我将会演示如何对redis进行监控,与mysql监控类似,我们也需要从业务维度思考对redis的监控.
最后此篇关于【升职加薪秘籍】我在服务监控方面的实践(6)-业务维度的mysql监控的文章就讲到这里了,如果你想了解更多关于【升职加薪秘籍】我在服务监控方面的实践(6)-业务维度的mysql监控的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
关闭。这个问题是opinion-based 。目前不接受答案。 想要改进这个问题吗?更新问题,以便 editing this post 可以用事实和引文来回答它。 . 已关闭 9 年前。 Improv
我在这里感觉有些不对劲,所以我希望社区提供意见 - 也许我以错误的方式处理这个问题...... 问:是否适合使用传统的基础架构日志框架(如 log4net)来记录业务事件? 当我说业务事件时,我的意思
技术也好,业务也罢; 01 【什么是业务?】 对于那些久经职场的人,也很难一句话说明白; 业务,作为工作中绝对的核心点,即便在一个公司待的足够久,
三天研发,两天设计; 01 【优先做设计方案】 职场中的那些魔幻操作,研发最烦的是哪个? 作为一个数年且资深的互联网普通开发,可以来说明一下为什么
业务、系统、接口(interface)、持久化类是什么意思?用一些例子解释一下? 最佳答案 业务可能是应用程序中所有功能部分发生的部分(即计算或规则) 系统是您的操作系统 接口(interface),
我无法创建带有指向移动应用的外部链接的简单广告。我已正确设置访问权限,可以创建广告系列、广告集、加载图像,但在创建广告期间出现错误: Ads and ad creatives must be asso
我是软件工程专业的学生,现在我正在为我的期末项目工作,安排在交易日进行商务配对。 这个想法是将卖家(开发人员)和买家(有经济能力的人)在一起。 算法应该像“快速约会”。 假设我有 15 张 table
我们只需按照以下说明在 AWS Cloudformation 上部署企业 WhatsApp API: AWS WhatsApp API 所以一切正常,部署正确完成,问题出在“SSL 配置”选项上,我们
我的应用因为以下原因被拒绝了 Guideline 3.2 - Business We found that your app is not appropriate for the App Store
您好,我想在我的网络应用程序中使用 WhatsApp 业务 API。我已经在 postman 中测试过了。 每当在 WhatsApp 选项卡下的 Facebook 业务页面中运行示例 curl 代码时
我是 Skype for Business 技术的新手,我正在尝试部署一个我愿意与 Skype WebSDK 和 AppSDK 一起使用的服务器。 起初我尝试使用Skype进行在线商务,但websdk
Apple 开发人员以此为由拒绝了我的应用。 “业务 - 3.1.1您的应用程序包含一个帐户注册功能,该功能被视为对外部机制的访问,以便在应用程序中使用购买或订阅。此功能不符合 App Store 审
我正在玩 Realm for Android。 我喜欢自动更新对象的想法,但我对它的软件架构有顾虑。 我已经看到许多提议的架构都指定了一个层来处理数据/数据库访问,理想情况下,更高层不会知道有关数据库
关闭。这个问题不符合Stack Overflow guidelines .它目前不接受答案。 这个问题似乎与 help center 中定义的范围内的编程无关。 . 关闭 10 个月前。 Impro
我正在尝试设置 Whatsapp 业务 API。 引用Link用于设置。 我正在使用 Windows 10 操作系统。 -- 仅供引用。 在初始设置部分,使用命令 docker-compose up
我正在尝试使用 Facebook Business SDK 创建一个 facebook Adaccount .但是当我使用方法 createAdAccount 时,它会给我一个错误。请参阅下面的图片。
我想写一个概念证明 MonoMac使用 c# 和 Razor 呈现 html“ View ”的应用程序。 这可能吗? 如果没有,是否有人推荐与 Razor 的简单性相比的任何其他模板引擎。如果必须的话
无法解析 ':business:diary@debug/compileClasspath': Could not resolve project :fun:push. 的依赖关系 无法解析项目:fun
当我尝试在 Visual Studio Professional 2015 14.0.23107.0 中打开某些 XML 文件时,XML 编辑器出现白屏并显示以下文本: 为什么我不能编辑这个文件?此项

我是一名优秀的程序员,十分优秀!