
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 。
论文标题:Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification 论文作者:Yanping Fu, Yun Liu 论文来源:2021 aRxiv 论文地址:download 论文代码:download 视屏讲解:click 。
动机 :传统的域自适应方法侧重于减少源域和目标域之间的域差异,从而实现情绪迁移,忽略了有效源的选择,无法处理负转移,导致性能有限; 。
方法 :
贡献 :
思路:
Note : 共享私有模型,特征空间被划分为共享空间还是私有空间,主要取决于这些词在统计上是否相同。随后,通过应用深度神经网络将 pivot 和 non-pivots 提取为域共享和域私有特征。然而,这些方法也存在一些问题,如域不变特征,包括一些无关的域私有特征,共享的域特征被划分为私有空间,它们削弱了情绪分类器在 UCSC 任务中的识别能力.
多源域情感分类存在的问题:
整体框架:
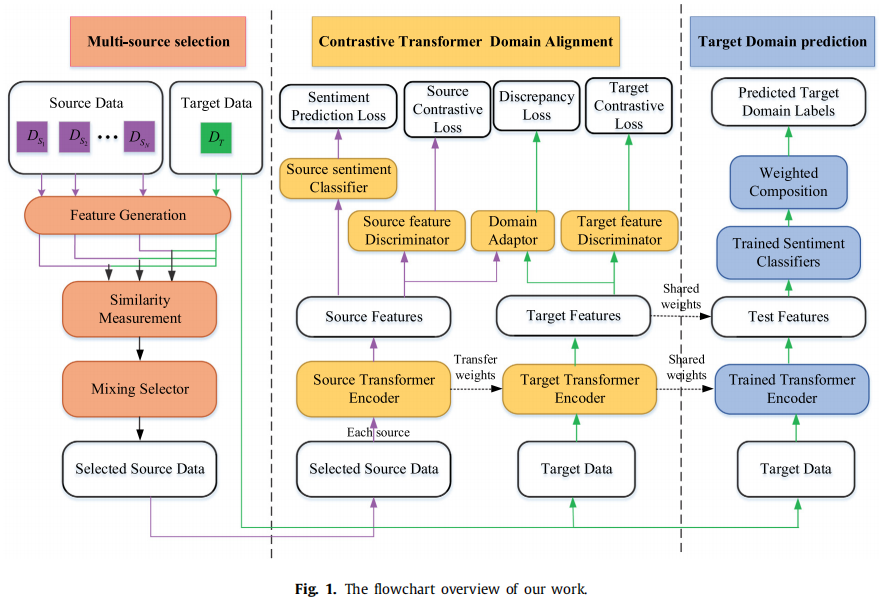
框架:

特征提取:
$R_{S_{i}}=\operatorname{BERT}\left(X_{S_{i}}\right) $ $R_{T}=\operatorname{BERT}\left(X_{T}\right)$ 。
考虑每个源域和目标域之间特征的 KL 散度来评估相似性:
$K L_{i}=K L\left(g_{S_{i}} \| g_{T}\right)+K L\left(g_{T} \| g_{S_{i}}\right)$ 。
其中:
$g_{S_{i}}=\exp \left(\operatorname{norm}\left(g_{S_{i}}^{\prime}\right)\right), \quad g_{S_{i}}^{\prime}=\frac{1}{n_{S_{i}}} \sum_{k=1}^{n_{S_{i}}} R_{S_{i}}(k)$ 。
$g_{T}=\exp \left(\operatorname{norm}\left(g_{T}^{\prime}\right)\right), \quad g_{T}^{\prime}=\frac{1}{n_{T}} \sum_{k=1}^{n_{T}} R_{T}(k)$ 。
Note :$\text{norm}$ 为 $\text{l2}$ 归一化操作,$k$ 表示第 $i$ 个源域中的第 $k$ 个样本; 。
相似性得分如下:
$S C_{i}=\beta K L_{i}$ 。
受 [44] 启发,多源选择器依赖于 “ 特征分布距离越近,实例越相关 ” 的理论。根据相似度方差提出了一种混合选择策略,其计算方法如下:
$V a^{2}=\frac{\sum_{i=1}^{N}\left(S C_{i}-M\right)^{2}}{N}$ 。
式中,$\text{M}$ 为相似度得分的平均值,$\text{N}$ 为源域的个数; 。
在得到相似性方差之后,混合选择策略包括如下两种方案:
加权选择方法 。
当相似度方差较小时,不同对源域和目标域之间的分布差异波动较小。即,所有的源域和目标域几乎都位于同一相似性级别上。因此,利用所有源的知识来预测目标域。由于每个源域的知识转移的贡献是不同的,加权选择方法是对最终预测器的所有加权源域进行和,将每个源的权值表示为 $\alpha_{s_{i}}$,转迁移如下:
$P_{T}=\sum_{i=1}^{n_{S_{i}}} \alpha_{S_{i}} P\left(X_{S_{i}}\right)$ 。
其中:
$\alpha_{S_{i}}=\frac{S C_{i}}{\sum_{i=1}^{n_{S_{i}}} S C_{i}}$ 。
注意:$P\left(X_{S_{i}}\right)$ 表示第 $i$ 个源预测器预测的目标域的边际分布,$P_{T}$ 表示目标域的最终边际分布; 。
当相似度方差较大时,不同对源域和目标域之间的分布差异波动较大。即,只有部分域对之间的分布差异较小,而其他域对之间的分布差异较大。因此,基于这个假设, 选择与 $\text{Top-K}$ 相关的源域作为可转移域,并消除其他源域以减少负转移。$\text{Top-K}$ 选择方法的具体计算过程与加权选择方法相同。在本文中,设置了 Top 30% 来验证该算法的可行性.
框架:
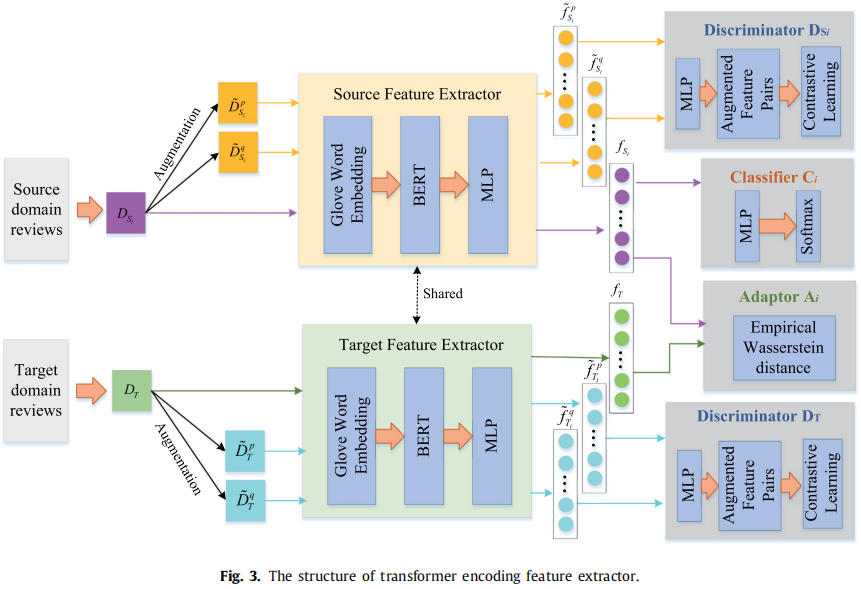
在本节中,我们描述了所提出的对比 transformer 域对齐框架,它将有效的信息从选定的源域传输到未标记的目标域。如 Figure 3 所示,对于每一对源域和目标域,我们的框架由一个 domain adaptor、两个 domain discriminator 和一个 sentiment classifier 组成。特别地,domain adaptor 通过评估瓦瑟斯坦距离来消除域偏移,获得域共享信息;domain discriminator 通过对比学习方法分别保留两个域的域私信息;利用域共享和域私信息等特征对源域的标记数据进行训练得到的 sentiment classifier.
目的:将有效信息从选定的源域传输到未标记的目标域; 。
特征提取器(以源域数据为例):
$w_{S_{i}}(k)=\operatorname{Glove}\left(x_{S_{i}}(k)\right)$ 。
$b_{S_{i}}(k)=B E R T\left(w_{S_{i}}(k)\right)$ 。
$f_{S_{i}}(k)=A b_{S_{i}}(k)+c$ 。
原始输入 $f_{S_{i}}$、$f_{T}$,源域特征 $\tilde{f}_{S_{i}}^{p}$、$\tilde{f}_{S_{i}}^{q}$,目标域特征 $ \tilde{f}_{T}^{p} $、$\tilde{f}_{T}^{q}$.
Domain adaptor 。
对于无监督的跨域分类,最关键的目标是通过减少域差异来消除域偏移。域自适应是一种有效的方法,其目的是通过最小化两个域之间的距离来捕获域共享特征。我们的域适配器应用瓦瑟斯坦距离来估计域的差异,并以对抗性的方式优化特征提取器,其理论优点是其梯度特性和有前途的泛化界.
目的 :通过减少域差异来消除域偏移; 。
策略 :对抗性训练(Wasserstein distance); 。
文档特征 $f_{S_{i}}$ 和 $f_{T}$,瓦瑟斯坦距离:
$W_{a}\left(f_{S_{i}}, f_{T}\right)=\underset{\left\|f_{w}\right\|_{L\le 1}}{\text{sup}} E_{f_{s_{i}}}\left[f_{w}\left(f_{S_{i}}\right)\right]-E_{f_{T}}\left[f_{w}\left(f_{T}\right)\right]$ 。
其中:$f_{w}$ 是满足 1-Lipschitz 约束 的特征映射函数,参数为 $θ_w$; 。
为实现域混淆,最小化两个域之间的距离 $L_{wf}$:
$L_{w f}\left(f_{S_{i}}, f_{T}\right)=\frac{1}{n_{S_{i}}} \sum_{f_{S_{i}} \in D_{S_{i}}} f_{w}\left(f_{S_{i}}\right)-\frac{1}{n_{t}} \sum_{f_{T} \in D_{t}} f_{w}\left(f_{t}\right)$ 。
因为 $fw$ 需满足 Lipschitz 约束,所以进行权重裁剪在 $[-c,c]$ 范围内。为避免由权重裁剪引起的梯度消失、爆炸,提出梯度惩罚函数 $L_{wg}$:
$L_{w g}\left(f_{S_{i}}, f_{T}\right)=\left\|\nabla_{\hat{d}} f_{w f}(\hat{d})\right\|-1$ 。
式中,$\hat{d}$ 为 $f_{S_{i}}$ 和 $f_{T}$ 串联中的随机点.
通过计算以下损失函数,得到瓦瑟斯坦距离:
$L_{w}= \underset{\theta_{w}}{\text{max}} \;\;\left\{L_{w f}\left(f_{S_{i}}, f_{T}\right)-\lambda \cdot L_{w g}\left(f_{S_{i}}, f_{T}\right)\right\}$ 。
Note:首先通过迭代学习特征表示来训练 $L_{w}$ 的最优性,优化完成后,固定参数并设置 $\lambda=0$,最小化瓦瑟斯坦距离 $L_{w}$。通过以较低的瓦瑟斯坦距离迭代学习特征,对抗性目标最终可以学习域不变特征。因此,最小化域适配器的损失函数被提出如下.
$\underset{W_{a}}{\text{min}}\;\left(\theta_{e}\right)=\underset{\theta_{e}}{\text{min}} L_{w}$ 。
其中,$\theta_{e}$ 表示特征提取器的参数.
框架:
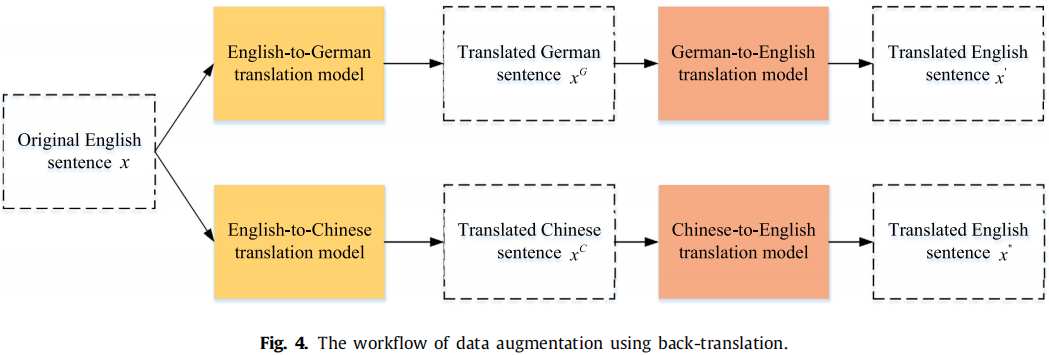
目的 :域对齐过程中,域自适应在捕获域共享特性时导致了域私有信息的丢失,所以本节提出了域鉴别器,用对比学习方法来保留域私有特征; 。
对比损失:
$l(p, q)=-\log \frac{\exp \left(\operatorname{sim}\left(\tilde{S_{S_{i}}^{p}}, \tilde{S_{S_{i}}^{q}}\right) / \delta\right)}{\sum_{j=1}^{2 M} \mathbb{I}_{[j \neq p]} \exp \left(\operatorname{sim}\left(\tilde{f}_{S_{i}}^{p}, \tilde{f}_{S_{i}}^{j}\right) / \delta\right)}$ 。
虽然 $\tilde{f}_{S_{i}}^{p}$,$\tilde{f}_{S_{i}}^{q}$ 的正对是一致的,但负对是不同的。受 [45] 的启发,最终的对比损失函数被表述为:
$L_{\text {con }}^{f_{i}}=\frac{1}{2 M} \sum_{k=1}^{M}[l(p(k), q(k))+I(q(k), p(k))]$ 。
由于为每对源域和目标域构造参数共享域鉴别器,所以最终对比损失如下:
$L_{c o n}=L_{c o n}^{s_{i}}+L_{c o n}^{T}$ 。
情绪分类器是一层的 MLP ,情绪损失如下:
$L_{\text {sent }}=-\frac{1}{n_{s_{i}}} \sum_{k=1}^{n_{s_{i}}} y_{s_{i}}^{P}(k) \ln \left(y_{S_{i}}^{t}(k)\right)+\left(1-y_{s_{i}}^{p}(k)\right)\left(1-\ln \left(y_{S_{i}}^{t}(k)\right)\right)$ 。
其中,$y_{S_{i}}^{t}(k)$ 表示情绪标签; 。
训练目标:
$L_{\text {totle }}=\sum_{j=1}^{\hat{N}} L_{\text {totle }}^{j}=\sum_{j=1}^{\hat{N}}\left(\sigma L_{W_{a}}^{j}+\tau L_{\text {con }}^{j}+L_{\text {sent }}^{j}\right)$ 。
其中,$\hat{N}$ 表示多源选择策略决定的源域数量; 。
算法:

对于 MCSC 任务,不同源分类器的组合方法会直接影响到预测性能。因此,提出了一种新的分类器加权组件,用于应用所选择的源域。对应于每个源域的模型,基于学习到的编码器提取目标域的特征 $f_{T}^{j}$,并使用训练好的情绪分类器得到情绪预测 $C_{T}^{j}\left(f_{T}^{j}\right)$。让所选的源域数为 $\hat{N}$,将每个源分类器的不同预测组合起来,得到最终结果:
$C_{T}=\sum_{j=1}^{N} \alpha_{S_{i}} C_{T}^{j}\left(f_{T}^{j}\right)$ 。
由于学习到的特征包含情感和语义信息,并且特征空间比原始数据可以更好地表示两个域之间的距离关系,因此使用了一个新的权重分量 $\alpha_{S_{i}}$。所提出的加权策略是强调更多相关的来源,而抑制不太相关的来源。应用训练模型中的第 $i$ 个源和目标之间估计的瓦瑟斯坦距离 $L_{W i}$,并将该距离映射到一个标准高斯分布 $\mathbb{N}(0,1)$。因此,每个域 $\alpha_{S_{i}}^{\prime}$ 的权值可以计算如下:
$\alpha_{S_{i}}^{\prime}=\frac{e \frac{-L_{W i}^{2}}{2}}{\sum_{i=1}^{n_{S_{i}}} e \frac{-L_{W i}^{2}}{2}}$ 。
实验关注的问题:
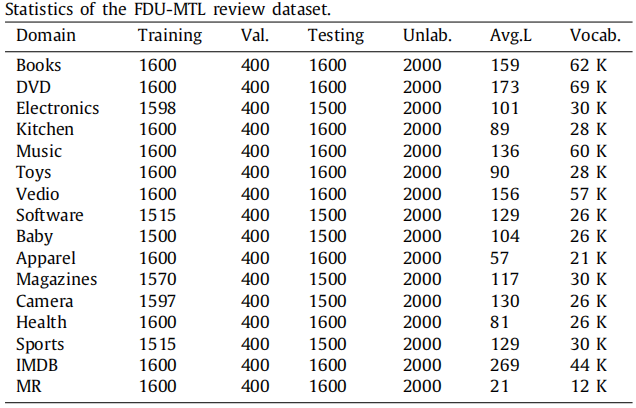
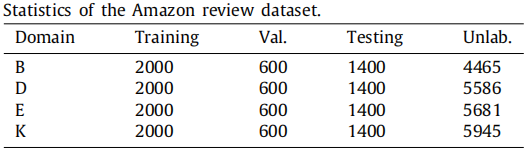
数据集 。
多源选择策略的效果 。
FDU-MTL数据集包括16个域,它们有足够的源来允许选择不同的策略,只在FDU-MTL审查数据集上进行了实验,以验证多源选择策略; 。
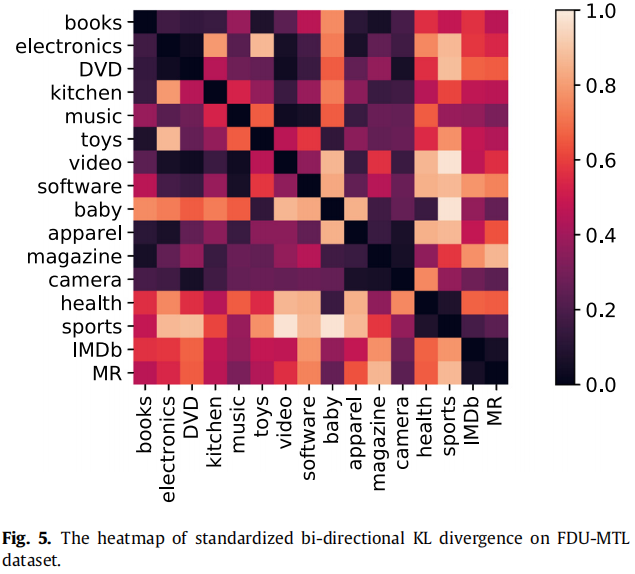
两个域之间的 KL 散度越小,其相似性越高.
为了评估目标域与其他源域之间的相似度的分散程度,我们计算了每个目标域的相似度得分的变化。Table 4 显示了每个源域和目标域对每个目标域形成的域对的相似度得分的方差。Table 4 显示了方差中的两个数量级,即 0.1 和 0.01。在概率论中,方差被用来度量离散值与其均值之间的偏差。对于方差为0.1的目标域,目标域与所有源域形成的域对的相似度得分相对分散;因此,在所有源域中,某些域的相关性高于其他域。而对于方差为0.01的目标域,则相反,所有的源域都与目标域具有相似的相关性。因此,对于域方差幅度为 0.1 级,如 baby, apparel, health, sports, IMDB, MR ,我们应用Top-K 选择方法选择来源,和域方差 0.01 数量级,如 books, music, software, electronics, toys, DVD, video, magazines, kitchen,camera ,使用加权选择的方法来选择源.

为了验证所提出的多源选择策略的效果,我们将所提出的算法的性能与来自随机Top-K源的选择方法进行了比较,平均所有源、单一最佳源,分别称为“Random Top-30%”、“Average All”、“Single Best”。Figure 6 显示了在FDU-MTL数据集上使用不同选择策略的不同方法的结果。从 Figure 6 可以看出,该算法对所有域都优于“Random Top-30%”、“Average All”和“Single Best”,证明了简单选择策略可能会引入太多的不相关域作为源域,导致负转移。因此,总体分析表明,所提出的混合选择策略减轻了负转移问题,并导致了显著的性能改进.
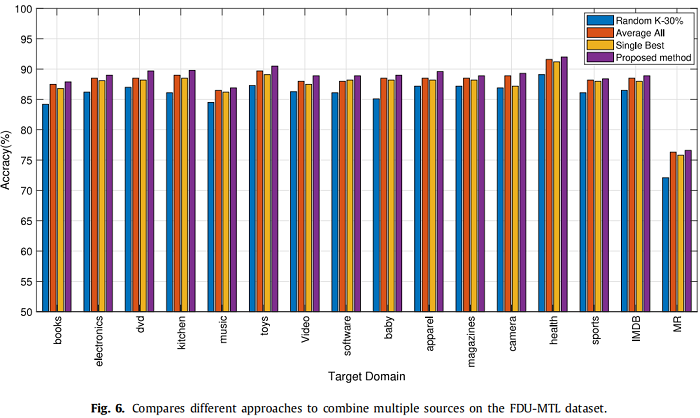
Amazon review dataset 仅包含四个域;当一个域作为目标域时,只有其他三个域可以是多源域。对于我们的Top-30%选择方法,可用源域的数量小于 $1$,因此,我们只将我们的加权选择方法应用于所有源域来传递每个目标域的情绪.
分类结果 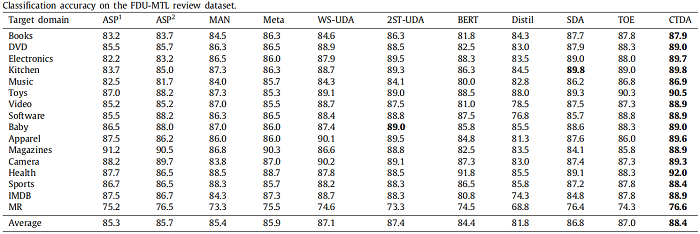

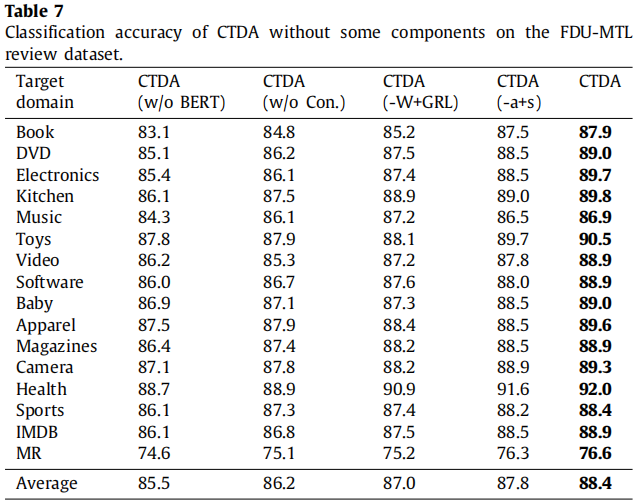
消融实验 。
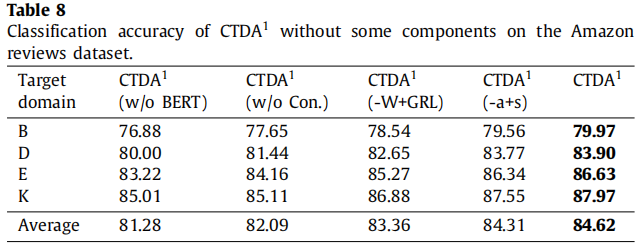
。
最后此篇关于论文解读(CTDA)《Contrastivetransformerbaseddomainadaptationformulti-sourcecross-domainsentimentclassification》的文章就讲到这里了,如果你想了解更多关于论文解读(CTDA)《Contrastivetransformerbaseddomainadaptationformulti-sourcecross-domainsentimentclassification》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我在这里的意图是创建一个单线程的 will-make-you-a-better-programmer-just-for-reading 之类的 文章 或 论文 或 真正站起来的博文作者付出了很多努力来
我想知道是否有人有很好的资源可以阅读或编写代码来试验“自动完成” 我想知道自动完成背后的理论是什么,从哪里开始什么是常见的错误等。 我发现 Enso、Launchy、Google chrome 甚至
市场上有许多工具,如 MPS,它们促进了面向语言的编程,据说这使程序员能够为任务设计(理想的?)语言。出于某种原因,这听起来既有趣又无聊,所以我想知道是否有人知道并可以推荐有关该主题的文章。 谢谢 最
我正在编写一个使用 JointJS 来显示图表的应用。 但是,我希望能够在页面中动态添加和删除图表。添加新图表相当简单,但是当我删除图表时,删除 DOM 元素并让图表和纸张对象被垃圾收集是否安全? 最
我在声明非成员函数listOverview()时出错; void listOverview() { std::cout #include class Book; class Paper
关闭。这个问题需要更多focused .它目前不接受答案。 想改进这个问题吗? 更新问题,使其只关注一个问题 editing this post . 关闭 3 年前。 Improve this qu
我正在将 Raphael 与 Meteor 一起使用,但遇到了问题。我正在创建一个 paper通过使用 var paper = Raphael("paper", 800, 600);如果我将此代码放在
我正在使用acm LaTeX template我在使纸张双倍行距时遇到困难。 我的 LaTeX 文档如下所示: \documentclass{acm_proc_article-sp} \usepack
H.Chi Wong、Marshall Bern 和 David Goldberg 的论文“An Image Signature for any kind image”中提到的算法步骤背后的原因是什么
我一直在使用Microsoft Academic Knoledge API一周了,直到现在我还没有遇到任何问题。我想获取某个 session 的所有论文,例如 ICLR 或 ICML。我正在尝试使用从
我正在读这篇论文Understanding Deep learning requires rethinking generalization我不明白为什么在第 5 页第 2.2 节“含义、Redema
就目前情况而言,这个问题不太适合我们的问答形式。我们希望答案得到事实、引用资料或专业知识的支持,但这个问题可能会引发辩论、争论、民意调查或扩展讨论。如果您觉得这个问题可以改进并可能重新开放,visit
我必须为非程序员(我们公司的客户)创建一个 DSL,它需要提供一些更高级别的语言功能(循环、条件表达式、变量...... - 所以它不仅仅是一个“简单”的 DSL)。 使用 DSL 应该很容易;人们应
在卷积神经网络中梯度数据的可视化中,使用 Caffe 框架,已经可视化了所有类的梯度数据,对特定类采用梯度很有趣。在“bvlc_reference_caffenet”模型的 deploy.protot
auto(x)表达式被添加到语言中。一个理性的原因是我们无法以此完善前向衰减。 template constexpr decay_t decay_copy(T&& v) noexcept( i

我是一名优秀的程序员,十分优秀!