
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 26
26
 4
4


测试环境有一个后台服务,部署在内网服务器A上(无外网地址),给app提供接口。app访问这个后台服务时,ip地址是公网地址,那这个请求是如何到达我们的内网服务器A呢,这块我咨询了网络同事,我画了简图如下:
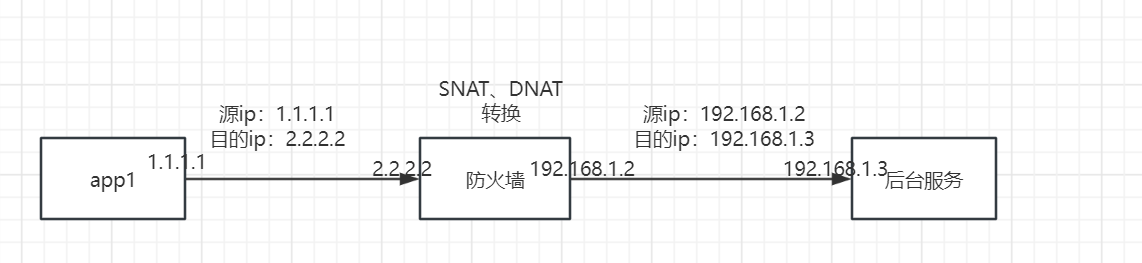
请求会直接打到防火墙上,防火墙对请求先做了DNAT转换(将目的地址转换为后台服务器的地址192.168.1.3),另外,为了确保后台服务处理完请求后,能正常返回响应,所以,防火墙还做了SNAT转换(将源地址转换为防火墙的内网地址192.168.1.2).
其实我之前测试过,不做SNAT也可以正常回包,但我只是一个开发,网工这块并不了解,所以网络同事肯定是有自己的其他考虑,总之,外网发来的进入后台服务器的报文,其源ip都变成了防火墙的ip.
简单而言,这也是一个典型的NAT环境.
再来说,我们遇到啥问题。我们这次变更,在192.168.1.3这个服务器上,加了个openresty(nginx增强版本),由openresty承接请求,然后反向代理到后台服务.
结果,测试同事反馈,app发出去的一些包,在三次握手的第一次握手就失败了.
当时,是在后台服务的机器上抓包,发现:app侧,好几个请求发了syn,但是后端没有回应,然后一直重传syn,重传n次后放弃.
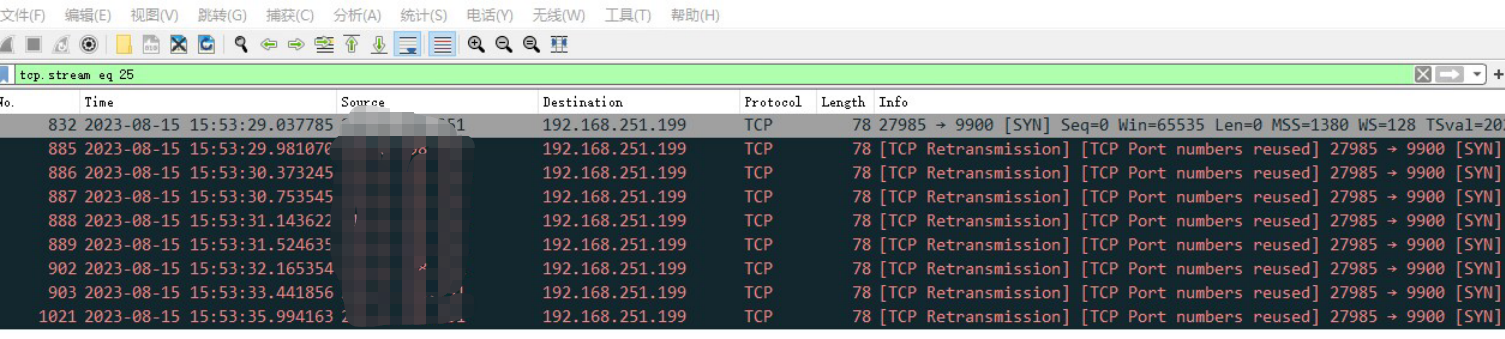
我一想,这难道是本次引入的openresty组件的问题?这要是上线了还得了,赶紧查查.
先是自己在本地开发环境试了好久,app被我玩得死去活来,并没有复现问题.
由于本周测试同事休假了,然后,我自己在测试环境又玩了好久,还是没有复现问题,但是之前,测试同事复现了好些次,我当时也在场。怎么,这次我自己就复现不出来呢?
复现不出来就在网上随便逛逛,然后找到一些文章,说了一些可能的原因,至于是哪个原因,那得执行命令来确诊.
// 检查指标,看看有没有因为时间戳丢弃syn包的情况
netstat -s |egrep -e SYNs -e "time stamp"
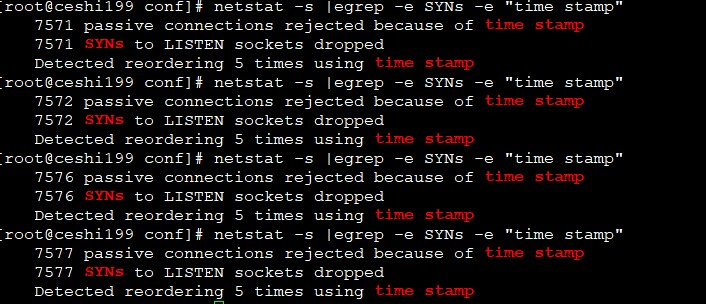
我一看,果然和网上说的对得上:tcp_tw_recycle参数在nat环境下,触发了linux的paws机制,导致丢包.
这个paws机制在nat环境下丢包,开启的前提是,服务器上打开了如下参数:
[root@VM-0-6-centos ~]# sysctl -a |egrep -e tcp_tw_recycle -e tcp_timestamps
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_recycle = 1
此时,我大概感觉就是这么个事情了,然后了解了这个问题场景后,果然在本地复现了,复现后就是照着改,然后问题就解决了.
解决不代表结束,我们得详细了解下这个机制,这个机制启动的参数中有一个 net.ipv4.tcp_tw_recycle ,这个参数,乍一看,是回收time_wait状态的socket,而在网上搜索 linux time_wait 时,出来的第一页的答案,很多都会跟你说,改下面的参数,改了就好了:
vi /etc/sysctl.conf
编辑文件,加入以下内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
改了有什么后果呢,不知道。这就在某些场景下埋下了隐患。要讲清楚这个问题,还得先了解下这个time_wait.
请看状态变迁图:
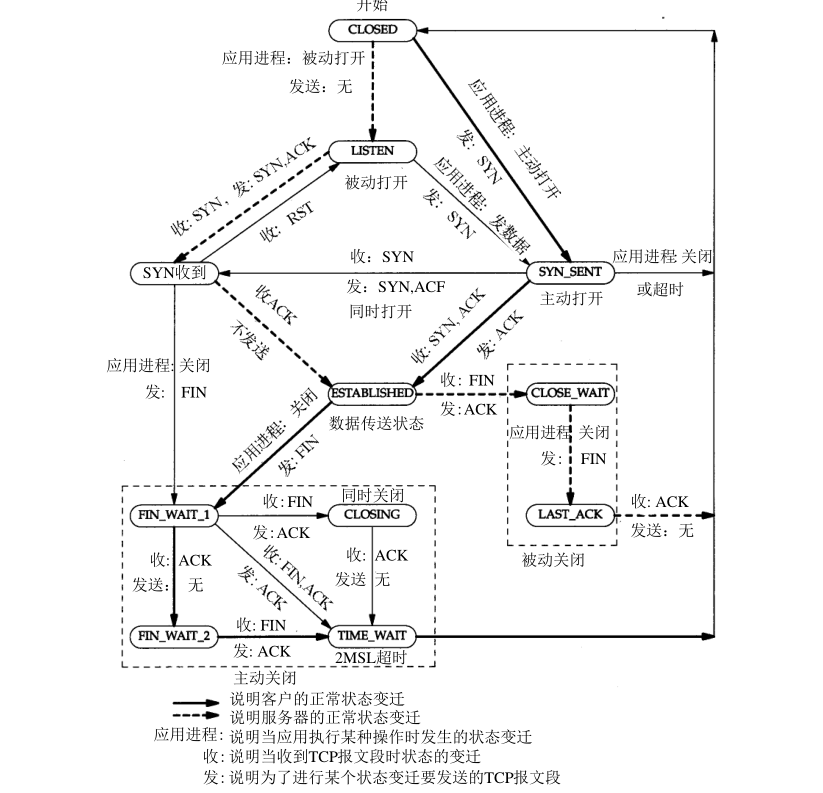
大家知道四次挥手关闭连接吧,其中,首先发起挥手的一方(或者叫:首先发起关闭连接的一方),在经历FIN_WAIT_1/CLOSING/FIN_WAIT_2等路径后,最终会进入time_wait状态.
其实,此时已经完成了4次挥手,为什么连接不直接进入关闭状态呢,为啥还要等到2MSL后,才能进入关闭状态呢?
既然tcp协议组设计了这么一个状态,自然是为了解决某些问题。在讲它能解决的问题之前,我们先简单实践下,看看什么情况下会出现该状态.
在我们传统的cs模型里,app/web网页是客户端,后端是服务端,那么,一定是app端/web网页发起主动关闭吗,不见得。后端也可以主动发起挥手.
按照我们上面的说法,主动关闭方最终进入time_wait状态.
看下面的例子,我本地 telnet 10.80.121.114 9900 (9900是一个nginx进程在监听)后,在dos框里随便输,这时就会导致后端主动关闭连接.
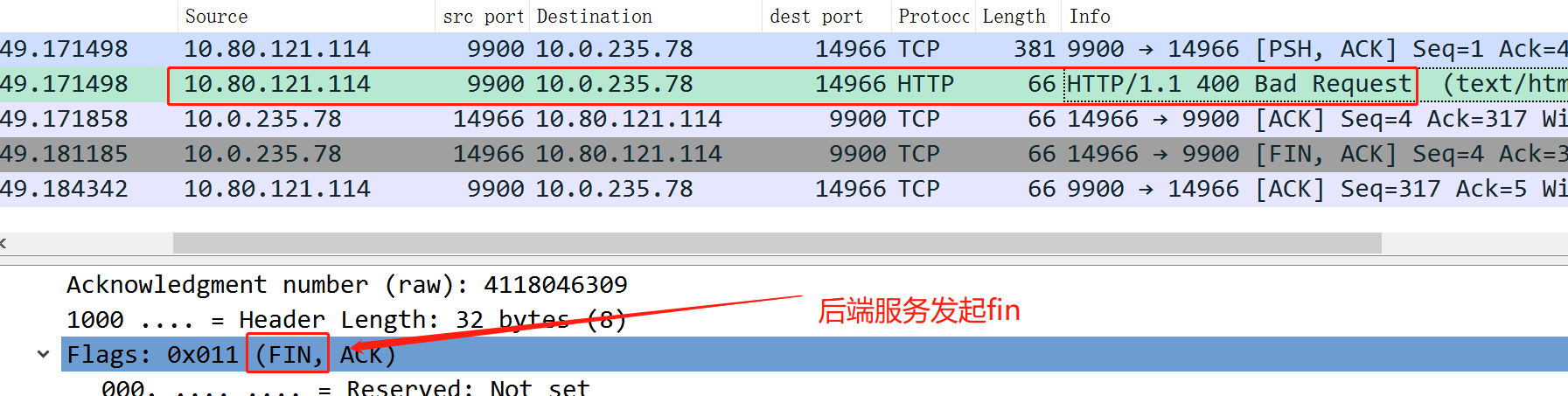
此时,在后端就会出现time_wait:
[root@xxx-access ~]# netstat -ntp|grep 9900
tcp 0 0 10.80.121.114:9900 10.0.235.78:14966 TIME_WAIT -
所以,因为后端发起挥手,所以后端进入time_wait.
另外,测试了下本机发起http短连接的场景,此时也是由后端主动发起挥手的,因此,也是后端进入time_wait.
GET / HTTP/1.1
Connection: close
User-Agent: PostmanRuntime/7.32.3
Accept: */*
Host: 10.80.121.114:9900
Accept-Encoding: gzip, deflate, br

发起挥手的一端,进入time_wait后,会在该状态下持续一段时间,协议规定这个时间等于2MSL,这个时间还是比较长的,以分钟为单位.
在这个时间段内,不能出现重复的四元组。大家看如下的例子.
我在服务器上去telnet 百度,正常来说,我可以打开n个和百度服务器之间的tcp连接。但每个连接都需要耗费一个本地的端口。如果我们在耗尽本地可用的端口后,会出现什么事情呢?
我们先设置本机只运行使用两个端口:
echo "61000 61001" > /proc/sys/net/ipv4/ip_local_port_range
首先,打开一个shell,执行:
## 110.242.68.4是www.baidu.com后的某个ip
[root@VM-0-6-centos ~]# telnet 110.242.68.4 443
Trying 110.242.68.4...
Connected to 110.242.68.4.
Escape character is '^]'.
查看状态:
[root@VM-0-6-centos ~]# netstat -ntp|grep 443
tcp 0 0 10.0.0.6:61000 110.242.68.4:443 ESTABLISHED 987835/telnet
再打开一个shell,进行同样动作后,查看:
[root@VM-0-6-centos ~]# netstat -ntp|grep 443
tcp 0 0 10.0.0.6:61000 110.242.68.4:443 ESTABLISHED 987835/telnet
tcp 0 0 10.0.0.6:61001 110.242.68.4:443 ESTABLISHED 987986/telnet
此时,本机的61000/61001端口都已被使用,此时,本机已经没有端口可用了,再执行telnet:
[root@VM-0-6-centos ~]# telnet 110.242.68.4 443
Trying 110.242.68.4...
telnet: connect to address 110.242.68.4: Cannot assign requested address
这里,我们模拟的不是time_wait状态的socket,而是established状态,但结果是一样的,因为,socket四元组不能完全一致,在服务端ip+端口+本地ip已经确定的情况下,唯一可以发生变化的就是本地端口,但是本地端口已经全被占用,因此,新的连接就无法建立.
但是,只要我们四元组其他部分可以改变,就还是可以建立连接,比如我们对www.baidu.com后的另一个ip来连接,就可以连上了:
[root@VM-0-6-centos ~]# telnet 110.242.68.3 443
Trying 110.242.68.3...
Connected to 110.242.68.3.
Escape character is '^]'.
此时状态:
[root@VM-0-6-centos ~]# netstat -ntp|grep 443
tcp 0 0 10.0.0.6:61000 110.242.68.3:443 ESTABLISHED 990953/telnet
tcp 0 0 10.0.0.6:61000 110.242.68.4:443 ESTABLISHED 990886/telnet
tcp 0 0 10.0.0.6:61001 110.242.68.4:443 ESTABLISHED 990927/telnet
这里,简单总结下,time_wait出现在主动关闭端,如果该端短时间内和对端建立了大量连接,然后又主动关闭,就会导致该端的大量端口被占用(由于端口号最大为65535,除去1-1024这些著名端口,可用的就是64000多个,也就是说短时间内,该端和对端最多建立6w多个连接再关闭,就会把这些端口全耗尽);此时,该端再想和对端建立连接,就会失败.
除了这部分的危害,其余的会额外占用内存、cpu之类的,基本不是什么太大的事情(除非在某些嵌入式设备上,我工作反正不涉及这块).
再背一遍:只有主动关闭方才会进入time_wait.
典型场景,服务提供给外网访问,且,我方服务端主动关闭连接。此时的四元组:
本端:localip + 服务端口,对端:用户外网ip + 随机端口.
但此时,由于对端ip和端口都是用户真实ip+端口,虽然出现大量time_wait,但因为四元组不重复,此时,不会导致用户连接不能建立的问题.
此时,防火墙或者lvs的ip作为客户端,访问后台业务接入层nginx等。此时:
本端:防火墙 ip + 本地端口,对端:nginx + 固定端口,此时,对端ip端口固定,本端ip固定,可变的唯有本地端口,如果此时是本端主动关闭,本端就会出现大量time_wait,影响到和接入层的新连接建立.
典型场景,nginx机器(本端)将请求反向代理给后端,且本端主动关闭连接。此时的四元组:
本端:nginx ip + 本地端口,对端:后端机器ip + 固定端口,此时,对端的ip和端口是固定的,本端ip固定,如果和后端发生大量短连接,就可能导致本地端口耗尽,无法建立新的连接.
该场景下,如果也是我方主动关闭连接,陷入time_wait的话。此时的四元组:
本端:后端服务ip + 本地端口,对端:中间件、db等ip + 固定端口,此时,面临的是和上面2/3类似的问题.
先看看,到底需不需要解决,如上面的第一种场景,如果只考虑新连接不能建立的问题,那么,是不需要解决time_wait过多的问题; 。
2/3/4,理论上需要解决,如果真的有这么大的量,导致新连接无法建立的话。但是,解决的办法,很多,不考虑系统内核参数的话,只需要保证四元组不重复即可.
就像我们上面那个telnet百度的实验一样,百度有多个ip,在ip1:443上耗尽了本地端口,那可以换到百度的ip2上.
大家可以参考下面这个文章,写得很好: https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux 。
The solution is more quadruplets . 5 This can be done in several ways (in the order of difficulty to setup)
- use more client ports by setting
net.ipv4.ip_local_port_rangeto a wider range;- use more server ports by asking the web server to listen to several additional ports (81, 82, 83, …);
- use more client IP by configuring additional IP on the load balancer and use them in a round-robin fashion; 6 or
- use more server IP by configuring additional IP on the web server.
翻译下就是:
解决办法就是拥有更多的四元组即可.
- 更多的本地端口可供使用,通过net.ipv4.ip_local_port_range,但最大也就65535
- 更多的服务端端口,如服务端可以监听81/82/83,多个端口都可以处理请求
- 更多的客户端ip
- 更多的服务端ip
上面我们说,time_wait会导致新连接无法建立。但是,如果打开了参数: net.ipv4.tcp_tw_reuse = 1 ,新连接建立的时候,就可以在time_wait状态下已持续超过1s的那些socket中选一个来用.
我们怎么知道哪些socket在time_wait状态已经持续超过1s了呢,那就依赖另一个参数:
net.ipv4.tcp_timestamps = 1 (默认就是1)
这个参数是默认打开的,它会给socket关联上一个时间戳.
这块具体的,还是参考文章吧:
https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux 。
总之,这是一个推荐的方案,适用于time_wait过多,新连接建立不起来的问题。但是,注意,这个只适用于发起连接的一方,不适用于接收连接的一方.
终于来到了恶名昭彰的参数: net.ipv4.tcp_tw_recycle . 它也是依托于 net.ipv4.tcp_timestamps 参数才能生效.
这个参数,首先会加快time_wait状态socket的回收,如果你在服务器上执行netstat,经常看不到time_wait状态的socket,那就很可能是打开了这个参数.
其次,它还有个副作用,它会启用一个叫做PAWS(PAWS : Protection Against Wrapping Sequence)的机制.
这个机制就是解决sequence回绕的问题,比如,本端和对端建立了一个连接,此时开始发送请求,假设seq为1,数据包长度100. 但这个包在路由给对端的时候,可能进入了某个异常的路由器,被阻塞了,迟迟未能到达对端.
这时,本端就会重传这个seq=1的包,本次,走了一条比较快的路由,到达对端了.
接下来,我们又和对端进行了很多交互,seq来到了最大值附近,最大为2*32次方 - 1。此时,我们关闭本次连接.
接下来,我们又建立了一个新的连接(正巧,四元组和刚关闭的这个一致),由于seq已经最大,发生了回绕,变成了从头开始,此时,我们又发了一个seq为1,数据包长度200的包给对端;而此时,之前上一轮那个走了歧路的包,意外到达对端了,此时,对端就会认为第一轮那个包是ok的,反而把我们本轮的包给丢了.
我找了个网图(侵删):
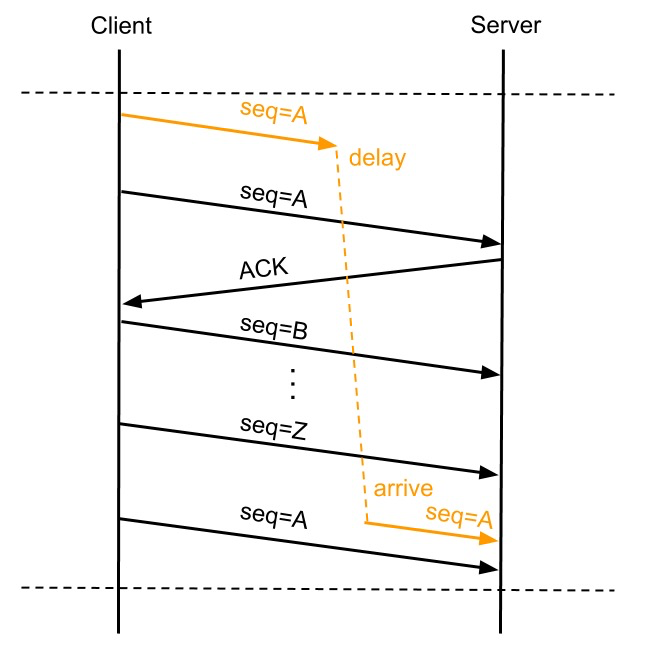
为了解决这个问题,就引入了时间戳机制,每个包中都带了自己本地生成的一个时间戳,而且,这个时间戳就是本地生成的,但是是递增的,比如,下面的第一个包,时间戳为96913730,第二包为:96913734 。
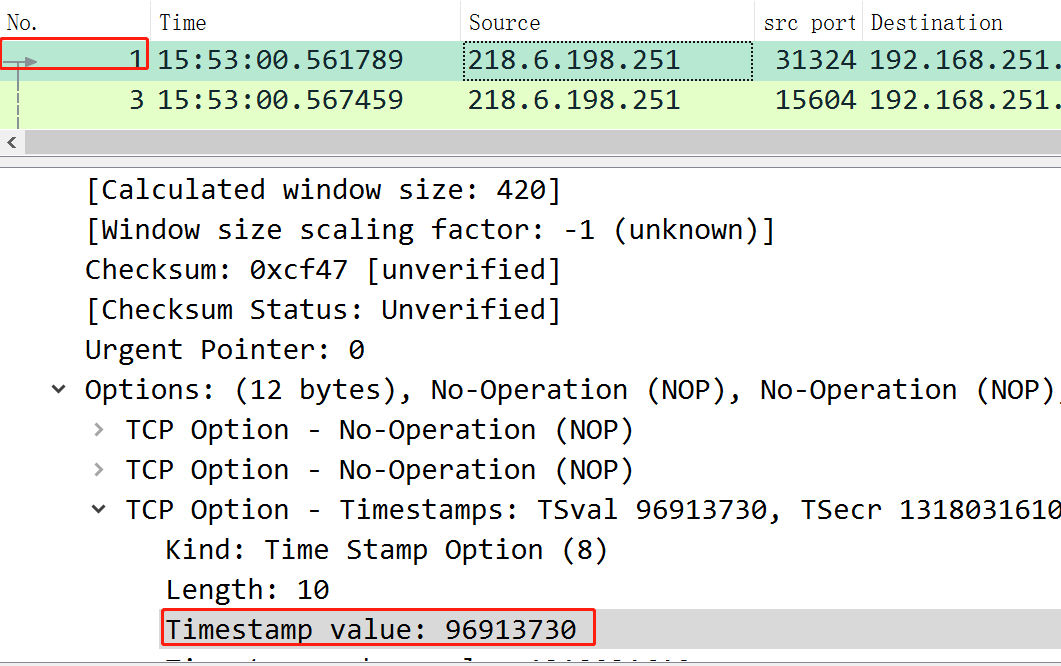
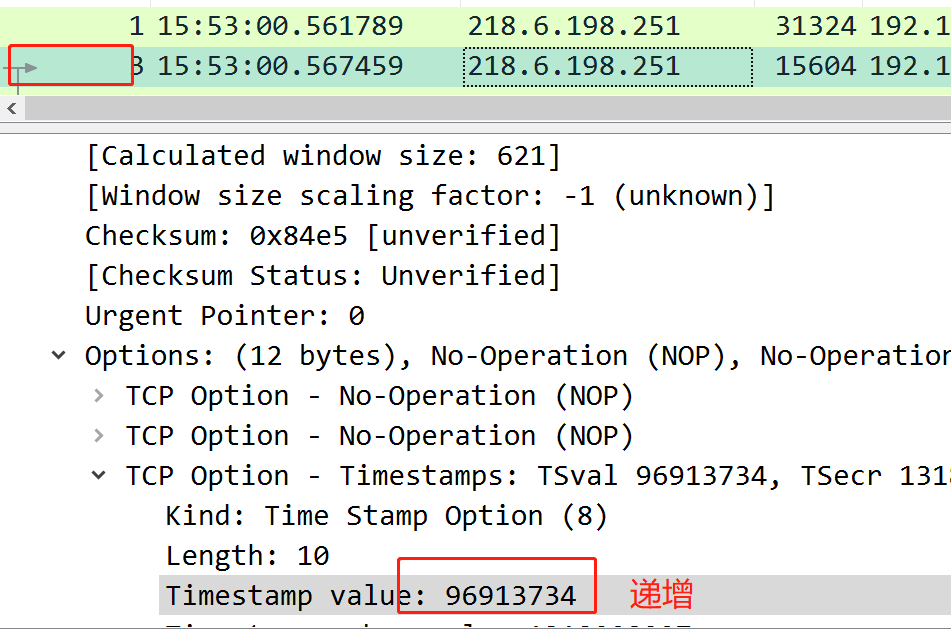
引入这个时间戳机制后,就可以解决上面的seq回绕问题了,因为每次收到这种带时间戳的包时,服务端都会维护下我方的最新时间戳,当收到在第一轮中误入歧途的包时,由于其时间戳比较小(比较老),比当前服务端维护的时间戳小,就会认定这个包有问题,直接丢弃.
但是,服务端(对端)是针对我方ip维护了一个时间戳,回到开头的例子,我方ip在通过防火墙以后,访问到后端服务时,后端服务看到的ip是防火墙的ip;那么,后端服务器就只会维护一个防火墙的最新时间戳,这是有问题的.
比如我们两个人各自用app访问服务,此时,各自本地生成的时间戳是不一致的,假设A生成的时间戳较大,此时,服务端维护的时间戳就是A生成的,接到B生成的时间戳较小的包时,就会直接丢弃.
比如,下面的第807包,时间戳为12亿左右:
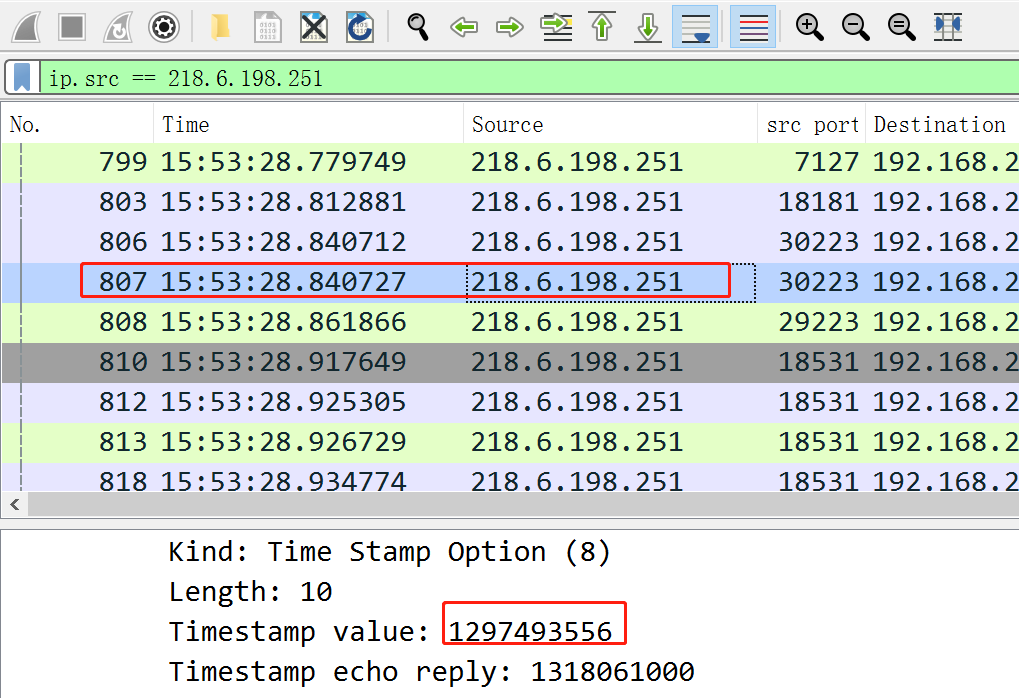
而到了808包,时间戳到了2亿,这就会导致错乱:
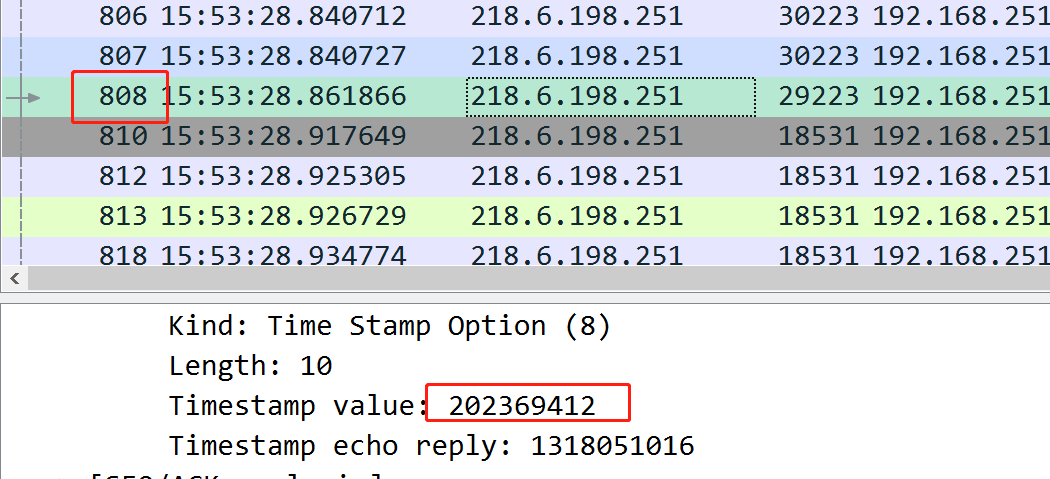
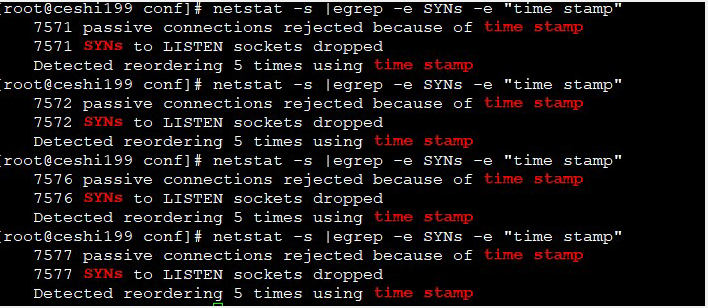
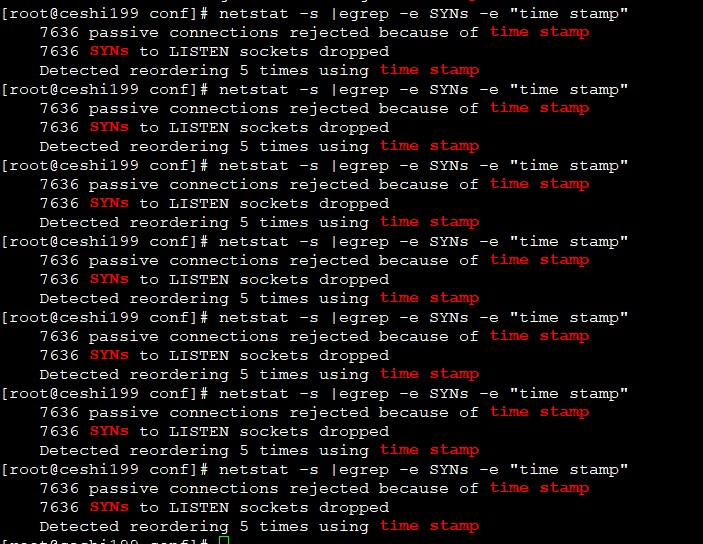
在这期间,服务端的netstat统计可以看到,很多被拒绝的syn:
补充下:
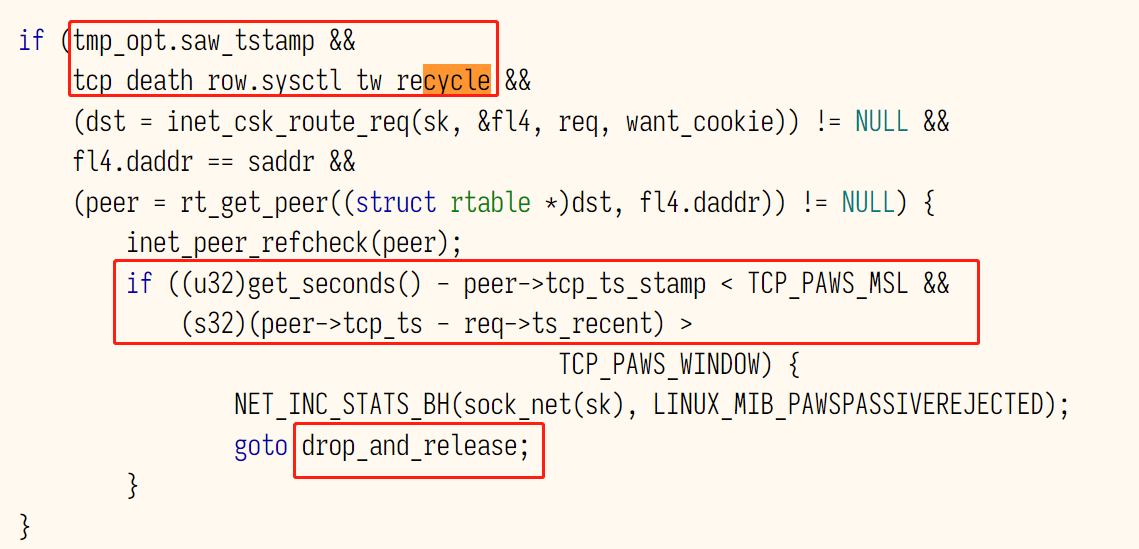
在处理三次握手的第一次握手时,协议栈相关代码中根据时间戳丢弃syn的逻辑:
我是直接关闭了 net.ipv4.tcp_tw_recycle 参数,关闭后,再测试多手机同时使用app,已经没有拒绝syn的指标继续增长的情况了.
由于其在nat环境存在的巨大问题,基本就只剩下很少场景可以用了。后来linux 4.1内核又上了一个特性,导致这个参数彻底失效,然后在4.2版本被删除.

https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=4396e46187ca5070219b81773c4e65088dac50cc 。
https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux 。
https://zhuanlan.zhihu.com/p/356087235 。
https://elixir.bootlin.com/linux/v3.10/source/net/ipv4/tcp_ipv4.c#L203 。
https://stackoverflow.com/questions/6426253/tcp-tw-reuse-vs-tcp-tw-recycle-which-to-use-or-both 。
https://blog.csdn.net/qq_25046827/article/details/131839126 。
https://www.ietf.org/rfc/rfc1323.txt 。
https://www.cnxct.com/coping-with-the-tcp-time_wait-state-on-busy-linux-servers-in-chinese-and-dont-enable-tcp_tw_recycle/#ftoc-heading-11 。
https://github.com/y123456yz/Reading-and-comprehense-linux-Kernel-network-protocol-stack 。
https://mp.weixin.qq.com/s/2xkYbczdHKgpUnicBw0pkA 。
https://www.suse.com/support/kb/doc/?id=000019286 。
最后此篇关于服务端不回应客户端的syn握手,连接建立失败原因排查的文章就讲到这里了,如果你想了解更多关于服务端不回应客户端的syn握手,连接建立失败原因排查的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
26
4
 0
0
当我测试我的网站性能时,我注意到 SSL 握手是连接设置的一部分。我了解(页面的)第一个请求需要完整的 SSL 握手。 但是,如果您从 pingdom 测试中注意到,只有某些其他资源在进行 SSL 握
在 SSL 握手期间,浏览器会根据需要使用提供的 URL 从主机 Web 服务器下载任何中间证书。我相信浏览器附带来自公共(public) CA 的预安装证书,这些证书只有根证书的公钥。 1) 当使用
在配置了客户端身份验证的 TLS 握手中,有一个步骤,服务器接收客户端的证书并选择是否信任它(例如,在 Java 中,它是通过 TrustManager 完成的)。 我想知道来自服务器的最终“信任失败
我正在尝试了解 Android 与服务器的 TLS 连接。有人可以纠正我吗? 有两种启动 TLS 连接的方式。首先,只有服务器有证书,客户端决定是否信任它。其次,客户端和服务器都获得了证书。我说得对吗
我正在创建一个社交网站,我希望用户在其中聊天并接收实时通知,例如 Facebook,我尝试搜索可能的解决方案并找到了 ejabberd 的 pubsub 模块(我正在使用 ejabberd 进行聊天)
我正在编写一个应用程序来(非正式地)替换在 adobe air 中制作的客户端,他们使用 RTMP 作为连接协议(protocol),我必须创建自己的类来实现它:< 据我所知,RTMP 属于 TCP
我正在做一个关于 TLS 握手的学术项目,我已经捕获了由多个客户端(谷歌浏览器、Firefox ......)生成的一些 TLS 流量,我想看看对于给定的浏览器,客户端 hello 消息是否总是相同的
我使用 openssl 实现了一个 DTLS 服务器。 (我有一个 udp 套接字,我正在使用内存 bio 与 openssl 通信。)但是,如果丢包,DTLS 握手可能需要 1-2 秒,这在我的情况
我编写了一个 PHP 程序来执行包含 openssl 命令的批处理文件: openssl s_client -showcerts -connect google.com:443 >test.cert
我编写了一个 PHP 程序来执行包含 openssl 命令的批处理文件: openssl s_client -showcerts -connect google.com:443 >test.cert
客户: var socket = new WebSocket('ws://localhost:8183/websession'); socket.onopen =
当有这么多证书时,浏览器如何知道在 ssl 握手中的客户端身份验证步骤中将哪个证书发送到服务器。我的意思是它如何识别哪个证书适用于哪个服务器 最佳答案 现在是 CyberMonk 的问题 如果您在
我正在尝试使用 python 连接到 XMPP 服务器。我有要连接的 XML,只是不确定如何进行连接的 TLS 部分?我可以找到很多 HTTPS TLS 示例和 XMPP 示例,只是不知道如何将两者放
我需要在我的 Python 服务器中实现 Websocket 握手。我的 python 服务器正在使用 Twisted 进行事件处理。我找到了 this webpage这解释了这个过程,但是当涉及到这
是否可以在当前 SSL 连接保持事件状态时重新协商 SSL 握手。当新的握手成功时,服务器应响应新握手的确认。 我搜索过 SSL 重新协商,但找不到任何具体内容。有谁知道这样的事情是否可能? 最佳答案
我编写了一个客户端-服务器应用程序,旨在通过局域网交换文件(以及其他内容)。在服务器模式下,应用程序监听具有特定标识 header 的 TCP 连接。在客户端模式下,它会尝试与用户提供的 IP 地址建
我有两台服务器通过 SSL 进行通信。 server1 通过 SSL 启动到 server2 的 SSL 连接。服务器 1 有一个 key 大小为 1k 的 keystore ,而服务器 2 有一个
架构是中间层 Liberty 服务器,它接收 http 请求和代理到各种后端,一些是 REST,一些只是 JSON。当我为 SSL 配置时(仅通过非常酷的 envVars)......似乎我得到了每个
我需要一些关于 TLS 的解释:每次客户端想要将自己连接到服务器时是否都执行 TLS 握手?每次都重新创建 session key ? premasterkey 和 masterkey 也是吗?Cli
我正在尝试将 TimeoutMixin 合并到基于 SSL 的协议(protocol)中。但是,当超时发生并且它调用 transport.loseConnection() 时,什么也没有发生。我认为这

我是一名优秀的程序员,十分优秀!