
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 27
27
 4
4


本文整理自 NebulaGraph 布道师 wey 在「夜谈 LLM」主题分享上的演讲,主要包括以下内容:
这里简单、快速地介绍下大语言模型:从 GPT-2 开始,到后来流行的 GPT-3,人们逐渐意识到语言模型达到一定规模,借助部分技术手段之后,程序好像可以变得和人一样,去理解人类复杂的思想表达。与此同时,一场技术变革也悄然发生了,曾经我们需要用复杂代码、深度学习才能够去描述的某些场景,或是实现的自动化、智能化的系统能力,现在借助 LLM(Large Language Model)大语言模型就能方便地实现。不只如此,一些大的生成模型可以做更多多模态的事情,去实现一些更有创造性的需求.
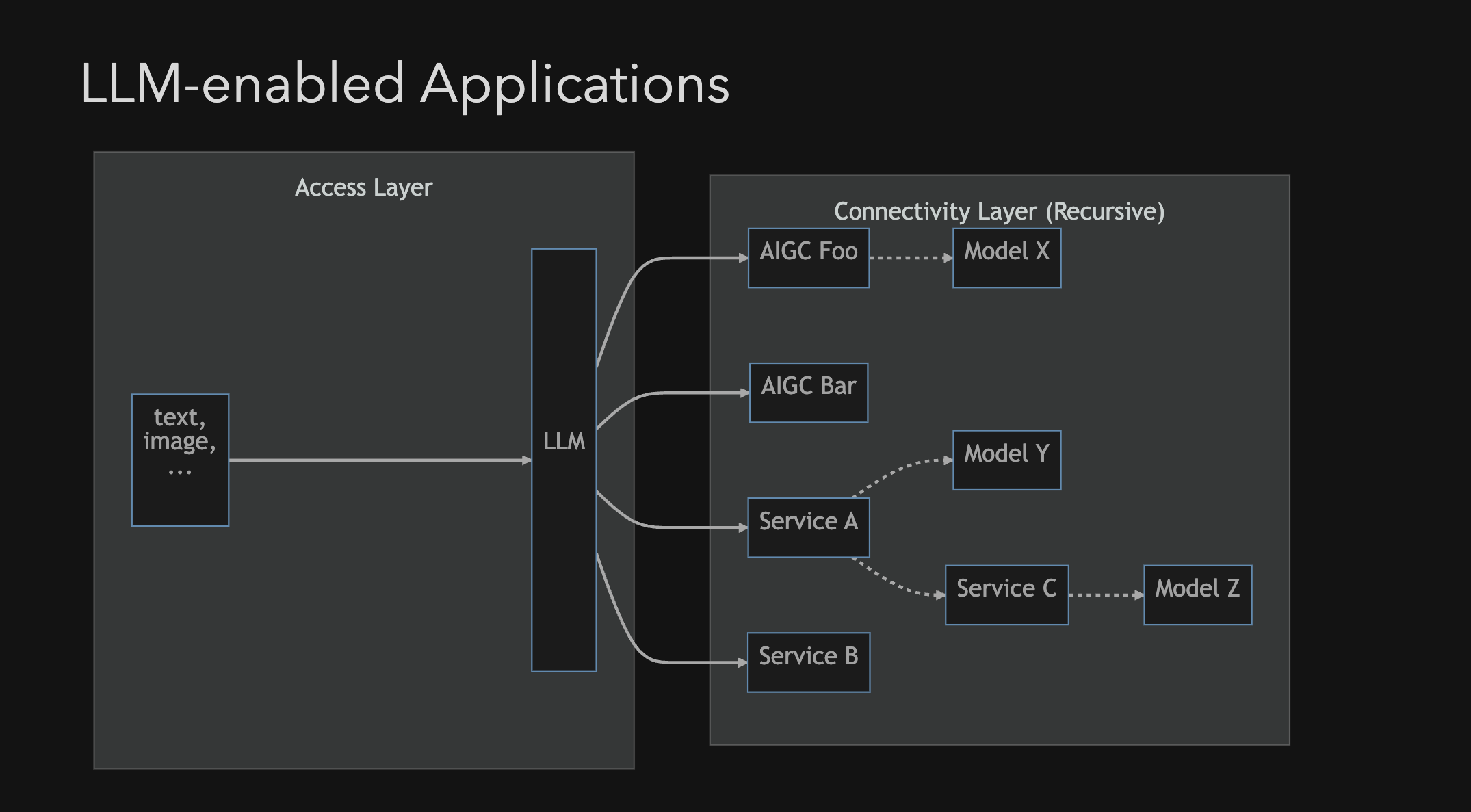
如上所示,目前我们利用大语言模型,将其当作通用智能感知层(接入层),再对接各类传统服务 Service 或者是生成模型服务 AIGC 的应用架构大概是这样.
而当中比较典型的模式可能就是 RAG.
RAG,全称 Retrieval Augmented Generation,检索增强生成模型,擅长处理知识密集型任务.
对应到上面的应用架构图,在 LLM 层,大语言模型会的知识不足以完成任务,此时我们需要借助其他的工具,来获得额外知识,可能在之前是昂贵的专家资源或者是 Fine-Tuning 微调模型。但是现在 RAG 它能解决这个问题,它可以辅助 LLM 获得额外的知识、数据,亦或是文档。RAG 在用户提交相关任务时,会将提问的问题进行解析,搭配已有的额外知识库,找寻到同它相关的那些知识.
上图下方就是 RAG 常用的方法,通过 Embedding 和向量数据库达到检索增强的效果。具体来说,RAG 就是将一个语义压缩到一个多维的空间里的向量。虽然在这个过程中,信息是有损失,但如果算法足够合理、压缩的空间足够大的话,也能帮助我们在比较快速的情况下找到相关信息.
举个例子,之前我们常用的以图搜图,在淘宝上传一个商品图片,它会找相似的商品,这背后其实就是淘宝把图片的特征向量化,(并非事实)可能是一万维的向量。而你上传的新照片,用同样的压缩 Embedding 的方式生成一个新向量。再在已有的历史商品图片的向量库里搜索距离相近的,也许是 Top100 的向量,将它对应的图片返回给你,也就是你上传商品的相似商品.
这种方式可以延伸一下,用来做语义搜索。通常来说,我们可以将一本书或者是几百页的文档,拆分成一片片,每个分片的含义做一个 Embedding。同以图搜图类似,我们在进行提问时,将这个语义的 Embedding 同已有的 Embedding 向量空间做匹配搜索,找到同这个提问相近的知识片,然后再把这些知识片作为上下文,和任务一起提交给大语言模型。像是 ChatGPT-4、ChatGLM、LLMam 2 之类的感知智能层,当它有了需要的上下文时,就可以很好地去回答我们问题或者是完成我们的任务.
这是最简单的、利用额外的知识做问答的 LLM 工作的方式,在 《图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index》 这篇文章中也有详细的介绍.
文中讲述了一些知识图谱驱动 LLM 的背景,但是这里可以稍微简略地说下。像是上图下方的选举,它其实会破坏到部分结构,比如说 TopN 要选多少才能够完成我们的任务,此外我们的知识分片也分散在各处。不过既然是知识,其实用知识图谱是一个非常方便的方式,这也是图数据库 NebulaGraph 典型的应用场景.
图是什么,这里简略待过.
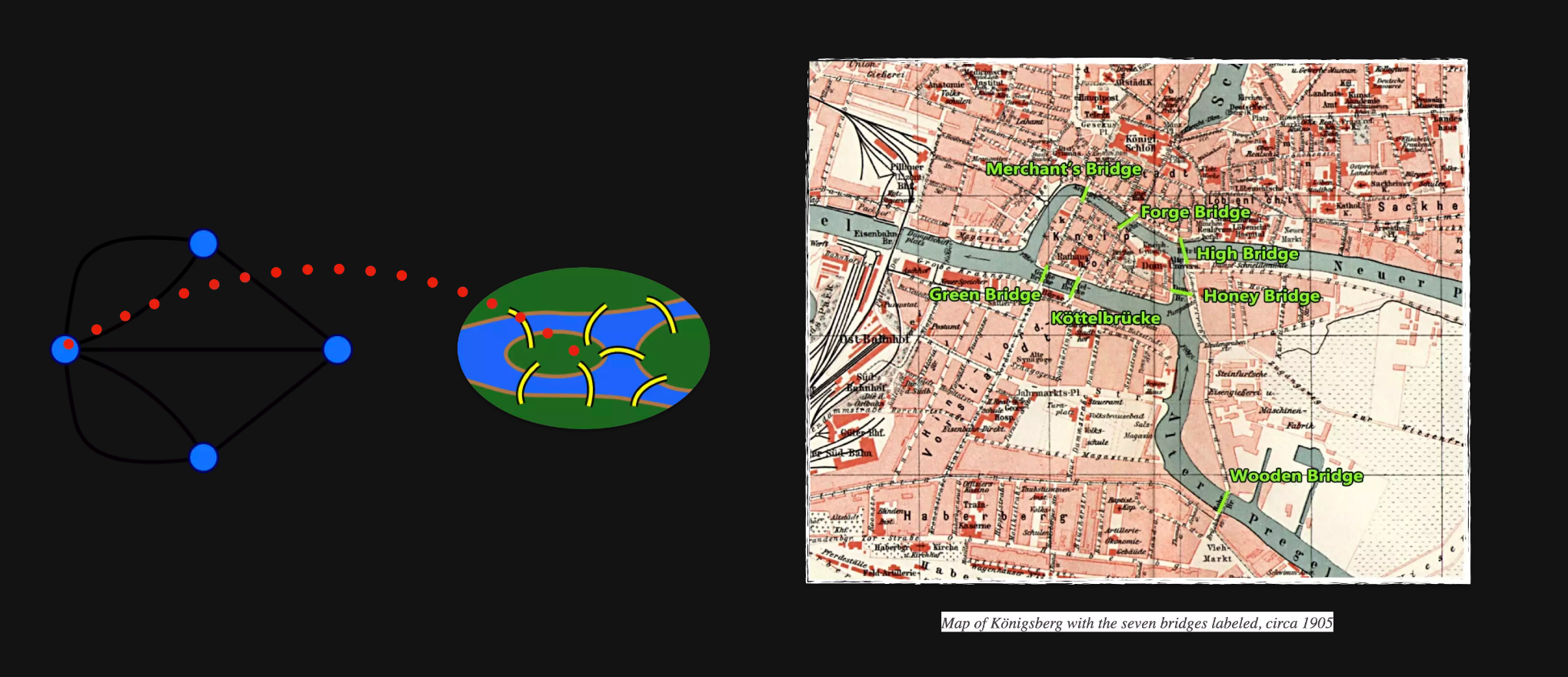
上述是图论的一个起源,有兴趣的读者可以自行去了解背景。这里着重讲下为什么我们要用到知识图谱、图数据库.
知识图谱,Knowledge Graph,最早是 Google 引入的技术。当我们检索词条时,搜索页面右侧会有相关词条卡片信息,这些信息是一种数据间的关联关系的内容体现。基于这种数据关联关系,我们可以进行词条推理工作,像是“yaoming's wife age”,找到姚明老婆的年龄。这种推理任务,采用传统的倒排索引是无法实现的,必须得基于知识的推理,而这背后的支撑的知识就是 Google 最开始从语义网络发展出来的叫 Knowledge Graph 的一个专业术语.
其实,不只有 Knowledge Graph 这一个图的应用场景.

简单来说,假如你有海量的图关联场景,你用非图的数据库写查询语句(像是上图 SQL 部分)。虽然理论上 SQL 是可以实现多跳的查询,或是查询是两点之间任意的路径,但往往这个查询语言不好写,并且响应速度满足不了业务需求。简单来说,非常痛苦.
而图数据库便是面向连接的存储,像雪人兄弟的跳转,其实就是 O(1) 的一跳,一种非常高效的方式解决跳转问题。而图数据库 NebulaGraph 是分布式的数据库,尤其是在海量数据库的场景下,会提供更高效的解决方案.
技术背景信息说完了,现在来讲讲大语言模型和图可以解决哪些问题?
LLM + Graph,首先能解决的是知识图谱的知识构建问题.
DEFAULT_KG_TRIPLET_EXTRACT_TMPL = (
"Some text is provided below. Given the text, extract up to "
"{max_knowledge_triplets} "
"knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n"
"---------------------\n"
"Example:"
"Text: Alice is Bob's mother."
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n"
"(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
上面是最简陋的构建方法.
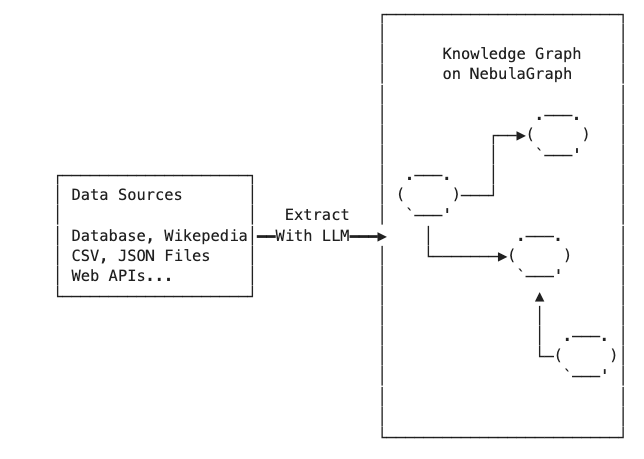
我们要构建一个知识图谱,它的知识源头可能是很多张表,或者是很多非结构化的数据,要从中抽取出来关键的实体以及实体之间的关联关系(谓词),如果你想通过程序化的方式来实现知识提取,其实是很有难度的。事实上,我们很多时候不只是在抽取知识,而是高质量地构建知识,这时候就需要用到 NLP 自然语言处理,或者是其他的技术。此外,这个抽取的数据最后还需要经过部分专家或者是人力去校验,把控数据质量。这个知识抽取的过程,其实成本是很昂贵的.
实际上,整个知识抽取的各个环节,都可以借助大语言模型得到快速地处理,比如:可以利用大语言模型生成代码,或者是直接提取非结构数据的知识。某种程度上,我们可以用大语言模型来实成整个知识的抽取过程.
上文是让大语言模型从一段文字中抽取三元组的示例,这是一个简单的 prompt,告诉程序:我现在提供了一些文字,你要帮我从中抽取最多 max_knowledge_triplets 的三元组,按照我给你的这个示例 (Philz, is, coffee shop) 的形式输出。当然,这里你可以让程序输出成 JSON、XML 格式。和大语言模型约定好输入和输出之后,这时候把文本批量丢给大语言模型,坐等大语言模型给你输出结果便是.
这里是我借助 Llama Index 这个大语言模型的 orchestrator 实现的多数据源的知识抽取,Llama Index 支持上百种数据源。实例中是抽取的维基百科数据,读取 Guardian of the Galaxy 第三部的长网页数据,Llama Index 会自动分割数据,通过我们之前 prompt 约定好的格式去处理数据,最终构建一个知识图.
这里有个完整的介绍和 Demo: https://www.siwei.io/demos/text2cypher/ 可以去试玩下。这里简单讲下一些使用:
from llama_index import download_loader
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
documents = loader.load_data(pages=['Guardians of the Galaxy Vol. 3'], auto_suggest=False)
kg_index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
max_triplets_per_chunk=10,
service_context=service_context,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
include_Embeddings=True,
)
抽取完之后的数据,可以进行图谱可视化展示或者是用 Cypher 查询语句.
这个过程中,其实有一些可优化点,比如:借助额外的 prompt 将近似的实体进行合并,不需要全部选取,或者是预定义实体中的 Schema。欢迎大家试玩之后,优化这个 Demo.
除了知识图谱的构建之外,大家在应用知识图谱或者是用图数据库 Graph Database 时,还面临着一个难题:query 的编写。往往写一些 query 语句时需要一定的知识储备,像是了解 Cypher 或者是 nGQL(NebulaGraph 的图查询语言),这无疑会带来学习成本.
这里,我们以基于 Knowledge Graph 的 QA 系统为例,具体展开讲讲这个问题如何解决。大家熟悉右侧的架构的话,其实知道这是我之前做的一个名叫 siwi 的问答系统,它主要基于 NebulaGraph 官方的 basketballplayer 的数据集实现.
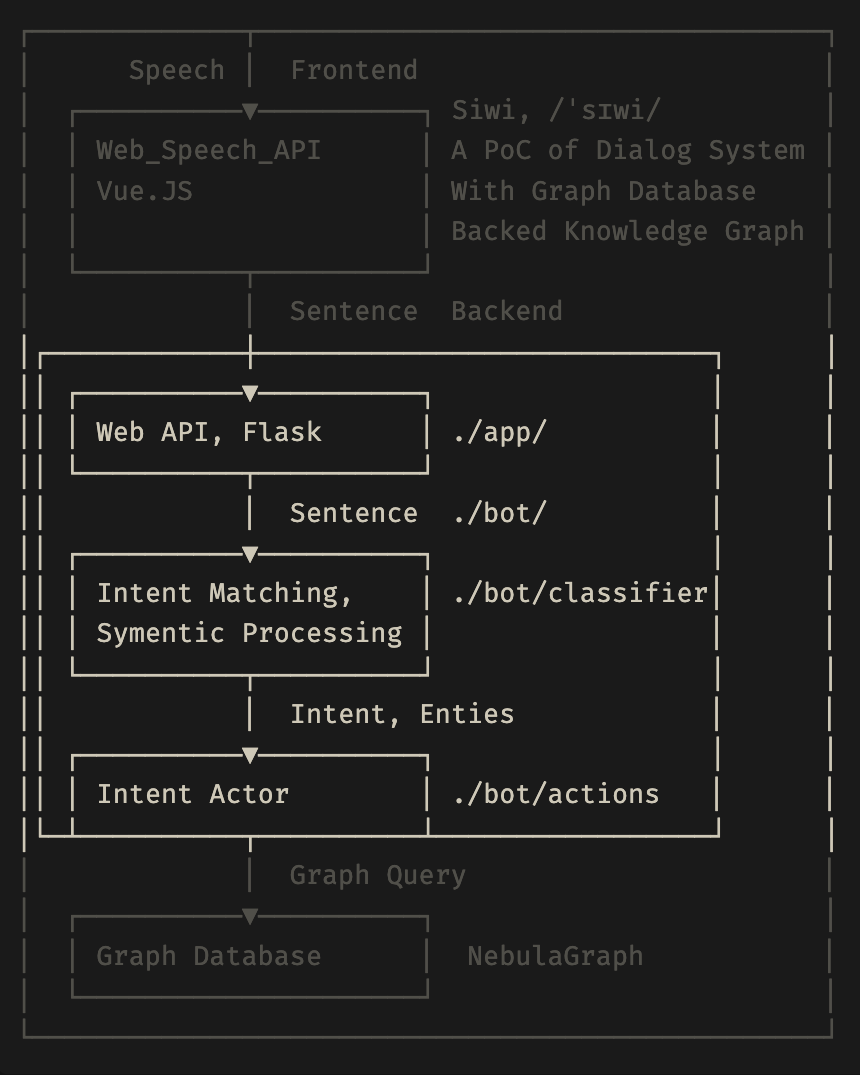
上面标注区域,主要实现的是文字到 Cypher 的功能。它接收到一个 Sentence 语句的时候,需要进行意图识别 Intent Matching,识别出来里面的实体,把实体按照语义抽取出来。再根据不同的意图,把对应的槽填进去,最后根据填充的意图和槽生成 NebulaGraph 的 query.
这个过程其实是蛮复杂的,如果这是一个单目的,像是问答,还挺好处理的,用穷举就可以实现。当然,追求质量或者情况复杂的话,可能会用到 NLP 技术.
当然,现在有了大语言模型,做这件事就更加方便、直观。这里可以提下在 ChatGPT 刚火的时候,大概今年 2 月份的时候,我做过一个更接近 Text2Cypher 的一个项目,叫 ngql-GTP 。在这个 Demo 视频里,你输入对应的 schema,再提出你的问题,系统就能自动帮我们写成一个适配 nGQL 语法的 query。而这件事也是大家期待大语言模型能帮我们解决的,GitHub 上也有许多相关的文本转 SQL 或者是其他查询语言的项目。事实上,做这么一个 Text2Cypher 或者类似的应用,你要输入给大模型的 prompt 是很简单的 。
你是一位 NebulaGraph Cypher 专家,请根据给定的图 Schema 和问题,写出查询语句。
schema 如下:
---
{schema}
---
问题如下:
---
{question}
---
下面写出查询语句:
像上面便是,你首先定义了这个大语言模型的 role,它要扮演什么角色。再告诉这个 NebulaGraph 专家,你的图空间中数据结构是什么样,再把问题放进来,最后你的理想输出结果是什么,这些都和大语言模型讲述清楚之后,这就是个理想的流程。但实操起来,你可能会增加一些额外的要求,像是:
就现状而言,你要得到满意的输出结果,来回调整你的 prompt 是一定的,而 prompt 的理想效果调试,也是一门玄学。为了节省大家调试的时间,我的这一套已经开源并贡献到了 LangChain 和 Llama Index,细节可以参考这篇文章 《Text2Cypher:大语言模型驱动的图谱查询生成》 。
Text2Cypher 这里也有个 Demo ,和上面的知识图谱是一个 Demo:

像是这样,很方便的,输入一个自然语言,就可以进行相关的查询。下面是对应 Text2Cypher 生成的查询语言 。
MATCH (p:`entity`)-[:relationship]->(e:`entity`)
WHERE p.`entity`.`name` == 'Peter Quill'
RETURN e.`entity`.`name`;
像上面展示的,我们还可以借助可视化工具,更直观地看到查询结果。而它具体实现的思路和我们之前说的 prompt 调试有点不同,以 LangChain 为例, 。
## Langchain
# Doc: https://python.langchain.com/docs/modules/chains/additional/graph_nebula_qa
from langchain.chat_models import ChatOpenAI
from langchain.chains import NebulaGraphQAChain
from langchain.graphs import NebulaGraph
# 连接 NebulaGraph 服务
graph = NebulaGraph(
space=space_name,
username="root",
password="nebula",
address="127.0.0.1",
port=9669,
session_pool_size=30,
)
# 实例化
chain = NebulaGraphQAChain.from_llm(
llm, graph=graph, verbose=True
)
chain.run(
"Tell me about Peter Quill?",
)
在 LangChain 中引入 NebulaGraph,再连接上你的 NebulaGraph 服务,实例化 NebulaGraphQAChain,再借助一行 chain.run() 函数,就能实现你的需求。类似的,在 Llama Index 有相同的代码实现:
## Llama Index
# Doc: https://gpt-index.readthedocs.io/en/latest/examples/query_engine/knowledge_graph_query_engine.html
from llama_index.query_engine import KnowledgeGraphQueryEngine
from llama_index.storage.storage_context import StorageContext
from llama_index.graph_stores import NebulaGraphStore
nl2kg_query_engine = KnowledgeGraphQueryEngine(
storage_context=storage_context,
service_context=service_context,
llm=llm,
verbose=True,
)
response = nl2kg_query_engine.query(
"Tell me about Peter Quill?",
)
上面是简略版的代码,如果你有兴趣可以看 Demo 完整 NoteBook 中的代码。这里再补充下,在 Llama Index 中还有额外的 generate_query 的方法,它主要实现返回 Cypher 而不做查询的功能,这样你就能获得对应的查询语句,而不是查询结果.
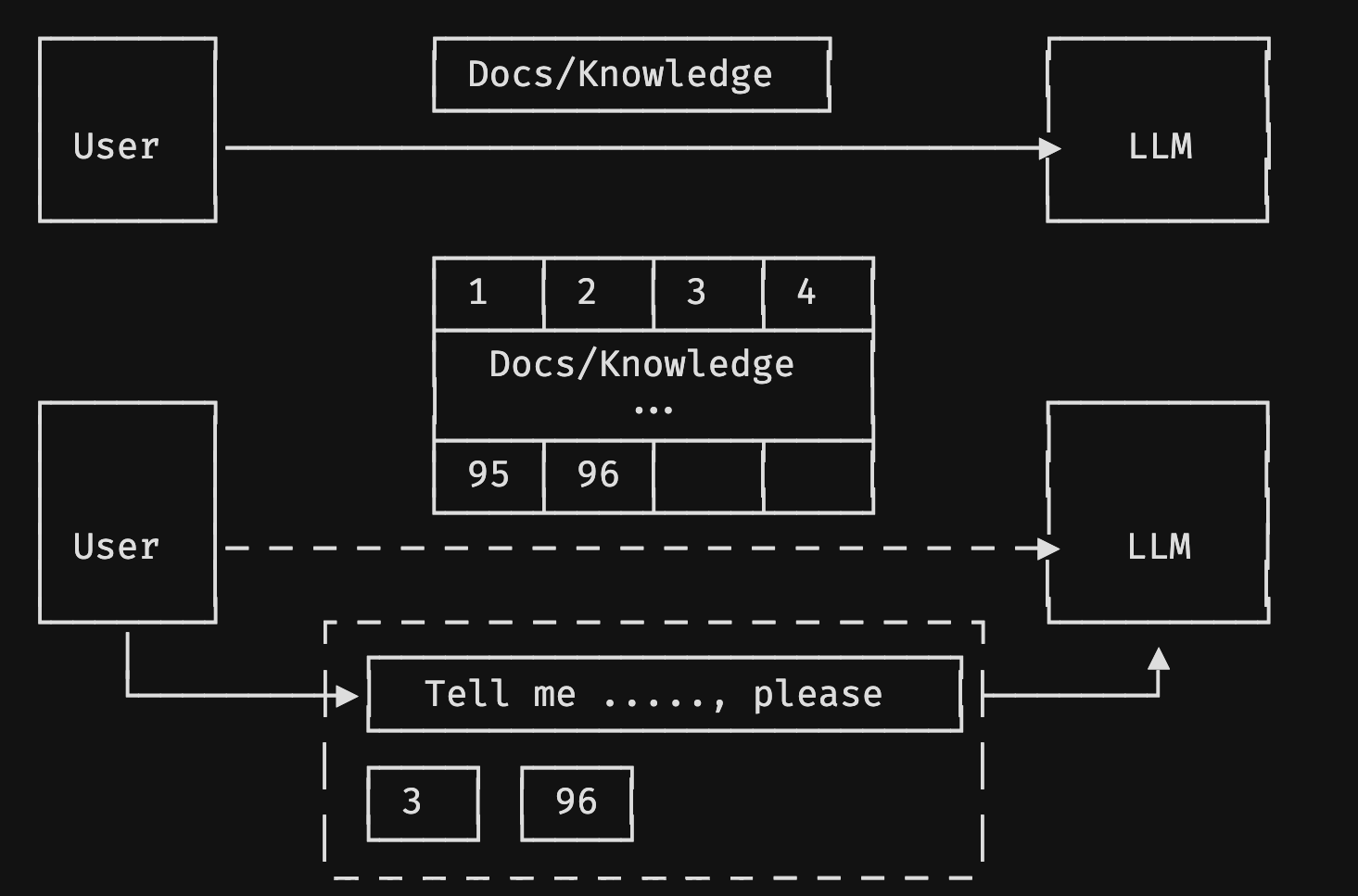
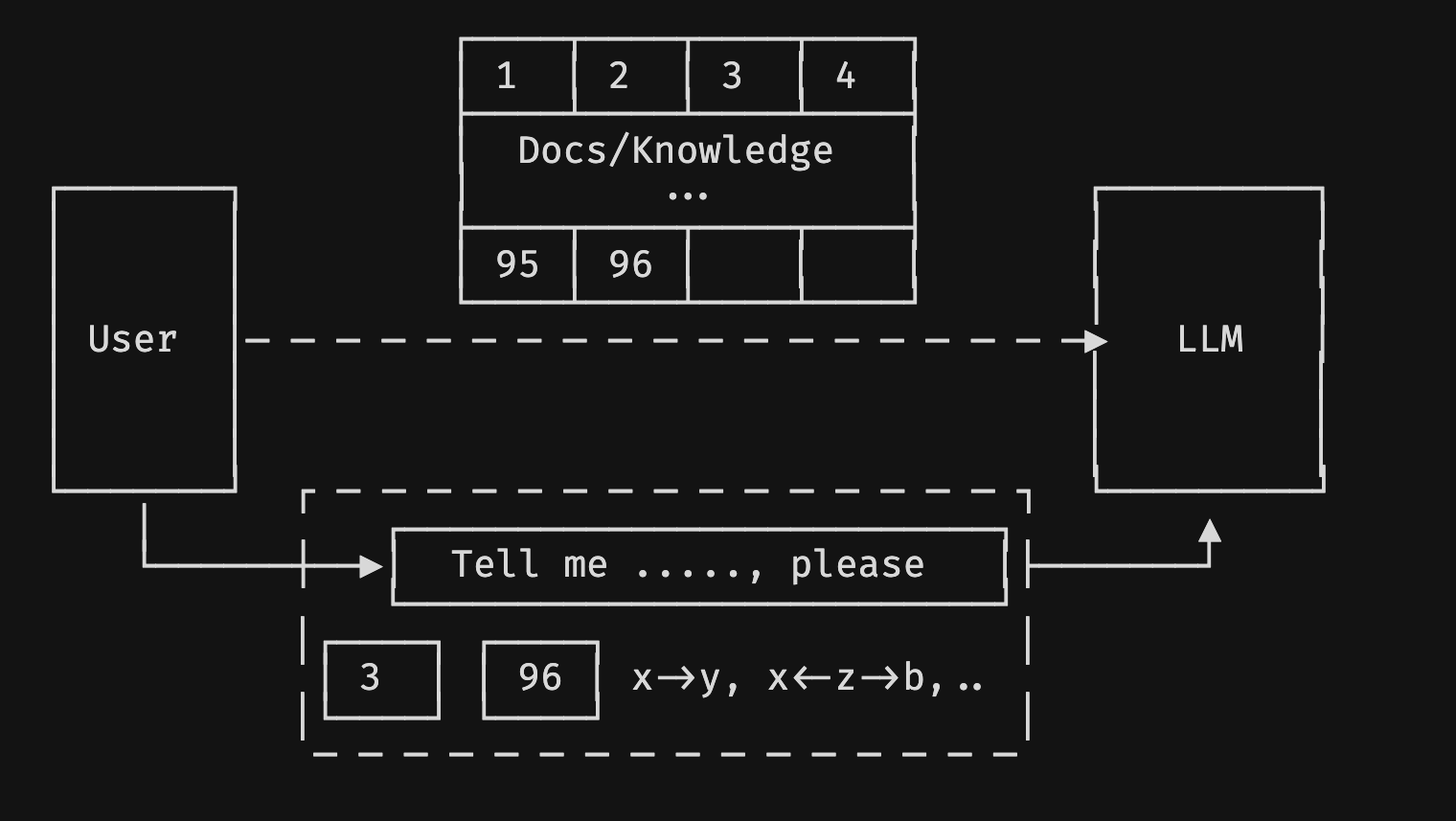
前文也有做简单的 RAG 介绍,这里再补充下额外的点.
一般来说,我们使用 RAG 时,会对文档进行 Embedding(对应上图的 1、2…96 分片),而我们提问“Tell me ...., please” 时,也会进行 Embedding,再在 vectordb 向量数据库中进行 TopN 的匹配搜索返回,将最接近它的文档块(对应上图的 3、96)作为上下文,同问题一起输入给大语言模型.
但,这样做有什么问题呢?
假如现在我们的问题是有关于乔布斯的,数据来源是乔布斯自传,而问题可能是他同苹果公司的关系,或者关于他在苹果发生的那些事。现在这个自传书籍中集中某个章节讲述了苹果公司的事情,它可能是 3、4 页的篇幅,而其他章节也有提到苹果公司,分布在 30 页中,这时候我们是不适宜采用 Top30 的,因为会超出我们的 Windows(token),导致对应的成本上升.
此外,我们把知识片的内容放大,如果里面抽取出来知识图谱的话,大概可能是这样:
┌──────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ .─. .─. │ .─. .─. │ .─. │ .─. .─. │
│( x )─────▶ y ) │ ( x )─────▶ a ) │ ( j ) │ ( m )◀────( x ) │
│ `▲' `─' │ `─' `─' │ `─' │ `─' `─' │
│ │ 1 │ 2 │ 3 │ │ 4 │
│ .─. │ │ .▼. │ │
│( z )◀────────────┼──────────────────┼───────────( i )─┐│ │
│ `◀────┐ │ │ `─' ││ │
├───────┼──────────┴──────────────────┴─────────────────┼┴──────────────────┤
│ │ Docs/Knowledge │ │
│ │ ... │ │
│ │ │ │
├───────┼──────────┬──────────────────┬─────────────────┼┬──────────────────┤
│ .─. └──────. │ .─. │ ││ .─. │
│ ( x ◀─────( b ) │ ( x ) │ └┼▶( n ) │
│ `─' `─' │ `─' │ │ `─' │
│ 95 │ │ │ 96 │ │ │ 98 │
│ .▼. │ .▼. │ │ ▼ │
│ ( c ) │ ( d ) │ │ .─. │
│ `─' │ `─' │ │ ( x ) │
└──────────────────┴──────────────────┴──────────────────┴──`─'─────────────┘
可以看到,它里面的数据,有些是跨越 data triplet 的,像是分布在 1、3 片区的 i -> z ,如果我们只是用 Embedding 的话,这种关联关系就会被分割,从而丢失信息。此外,之前也提过,一般来说我们创建 Embedding 时,没有将我们的私有知识考虑进去,而是针对通用型知识进行创建 Embedding。举个例子,保温大棚和保温杯,在语义上二者是有相似之处的。在我们未了解具体的领域知识时,光从语义角度,当我们输入“保温杯”时,从向量相似度上,可能在在结果中会混杂二者一起输出给用户。这也是 Embedding 会产生的一些误解,或者是丢失上下文关系的例子.
而采用 Knowledge Graph 这种方式,它是更精炼,以及更高密度的知识总结。在保证精确度的情况下,还会保留领域知识的语义,它是一个更细颗粒度的分割,且保留了全局的数据连接.
基于此,在 RAG 基础之上,我们将问题中的实体进行抽取,生成大概这样的一个结构:
找到在问题实体的基础上构建的图的相关子图,将其同作为上下文一起输入给 LLM 这套工作流。最终实践下来,效果还是不错的.

可以看到,在原有的基础上,输出结果会更加的丰富,因为借助了子图。具体的 demo 大家可以参考文末延伸阅读里的链接,可以在线实时试玩一下.
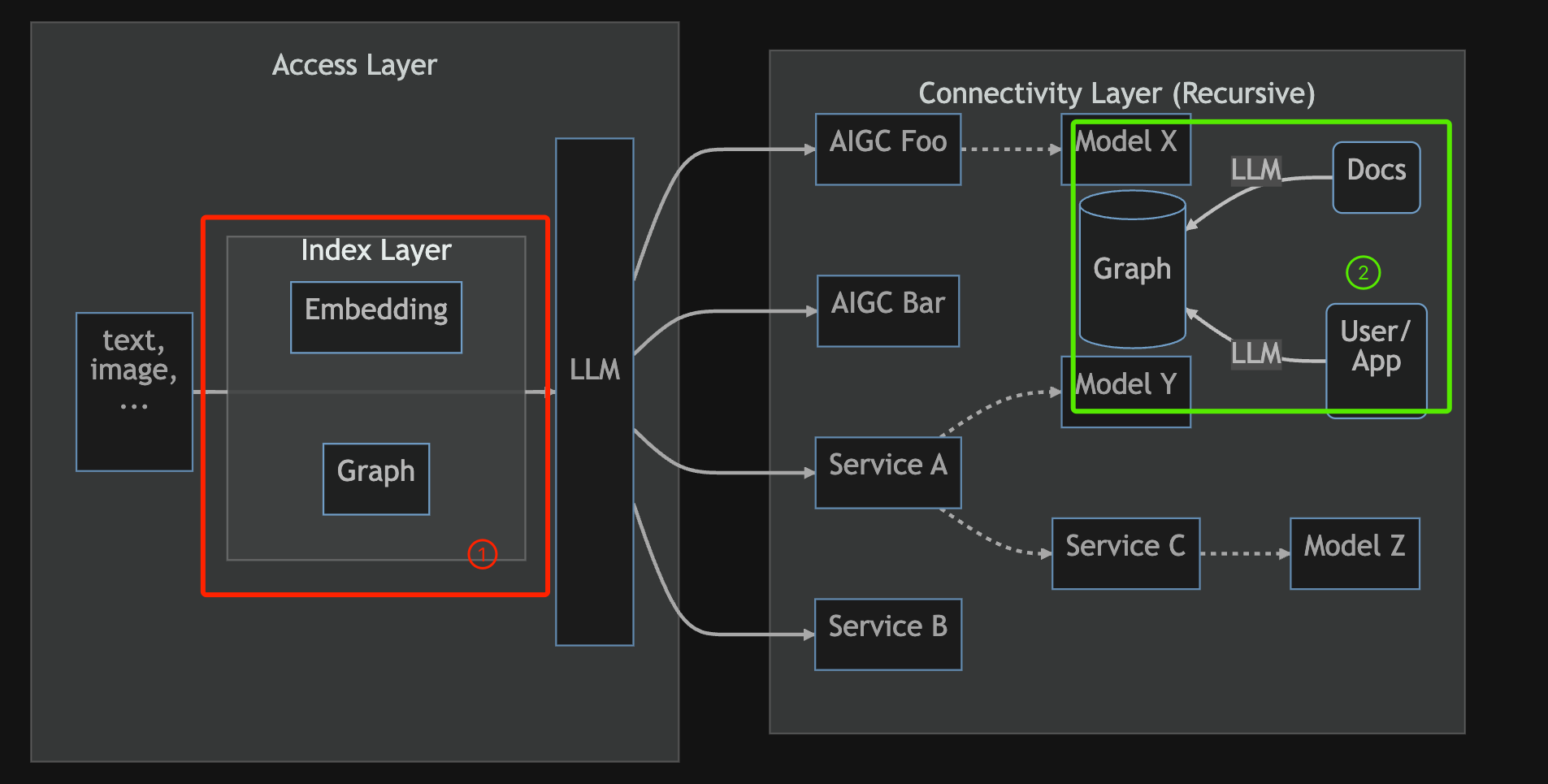
这是一个大语言模型,它可以做什么事呢?如上图 ① 所示,Graph(图 / 图数据库)可以在 Encounter Learning 或者是 RAG 时,帮助我们辅助 Embedding 工作。或是 ② 所示,借助 LLM,构建 Knowledge Graph,就是知识图谱。当然,当中涉及到 prompt 的调试。此外,还有用户同数据库交互时,之前需要用到查询语言,现在借助 LLM,可以某种程度上用自然语言就能进行图数据库的查询.
而 NebulaGraph 未来在 LLM 这块的应用实践的话,我们考虑在做图分析时,为 Graph 引入 analysis 的 Embedding,或者是从 Graph 出发,为它的子图创建更长的 Embedding,再根据 Embedding 进行搜索.
下面问题整理收集于本场直播,由 Wey 同社区用户陈卓见一起回复.
Q:目前大模型和知识图谱的结合案例有吗?有什么好的分享吗 ?
Wey:之前卓见老师在我们社区分享过一篇文章 《利用 ChatGLM 构建知识图谱》 ,包括我上面的分享,也算是一种实践分享。当然我们后续会有更多的介绍。看看卓见有没有其他补充.
陈卓见:我是相关的 LLM 从业人员,不过内部保密的缘故,这块可能不能和大家分享很多。基本上就是我之前文章所讲的那些,你如果有其他的问题交流,可以给文章留言,大家一起进一步交流下.
Q:现在如果要入门大语言模型的话,有什么好的入门教材 ?
Wey:如果是利用大语言模型的话,可以看下 LangChain 作者和吴恩达老师出的 教程 ,据说这个教程还挺不错的。而我个人的话,会看一些论文,或者是追 LangChain 和 Llama Index 这两个项目的最新实现,或者已经实现的东西,从中来学习下 LLM 能做什么,以及它是如何实现这些功能的。而一些新的论文实现,这两个项目也对其做了最小实现,可以很方便地快速使用起来,像是怎么用 Embedding,它们支持哪些 Embedding 模型之类的事情.
陈卓见:思为分享的可能是偏应用层的,而对我们这些 LLM 从业者而言更多的可能是如何训练大模型。比如说,我们想实现某个功能,我们应该如何去构造数据,选择大模型。像是我们团队,如果是来了一个实习生,会看他数学能力如何。假如数学不好的话,会先考虑让他先多学点数学;如果数学水平不错,现在同大模型相关的综述文章也挺多的,会让他去看看综述文章,无论中文还是英文,都有不少相关的资料可以学习。像 transform 层,大模型训练的细节,分布式怎么做,工程化如何实现 ,都是要去了解的。当然,这里面肯定是有侧重点的,你如果是想了解工程的知识,你可以去多看看工程知识;想了解底层原理,就多看看理论,因人而异.
这里给一些相关的资料,大家有兴趣可以学习下:
Q:NebulaGraph 论坛现在累计的问答数据和点赞标记,是不是很好的样本数据,可以用来搞个不错的专家客服 ?
Wey:在之前卓见老师的分享中,也提到了如果有高质量的问答 Pair,且有一定的数据量,是可以考虑用微调的方式,训练一个问答专家。当然,最直接、最简单的方式可能是上面分享说的 RAG 方式,用向量数据库 Embedding 下.
Q:想问部署 65b 大模型最低成本的硬件配置和实现路径 ?
陈卓见:先看你有没有 GPU 的机器,当然 CPU 内存够大也是可以的,有一台 256B 内存的机器,应该 65b 也是能推理的。因为大模型分不同精度,一般我们训练用到的精度是 fp16。而 fp16 的话,对于 65b 的模型,它大概显存占用大概是 120GB 到 130GB 之间。如果你用的内存训练的话,内存得超过这个量级,一般是 256GB,就能推理的。但是不大推荐用 CPU,因为它的速度可能只有同等规模 GPU 的 1/10,甚至 1/20、1/50 都有可能的,这具体得看你的环境.
如果你用 GPU,它是有几种选择,如果你用 fp16 的精度想去做推理的话,那么你可能需要 2 张 80GB 显存的机器,比如说 A100、A800 这样机器才能行。但最低实现的话,你可以选择 INT4 精度,这时候需要一个 40GB 左右的显存,比如买个 A6000,48GB 显存,它应该也是能推理的。但这个推理其实是有限制的,因为推理是不断的 next token prediction,是要一直生成 token 的,这就会占用你的显存。如果你让它写一篇长文的话,这时候 48GB 显存应该是不够用的,显存会爆。所以,你准备 2 个 48GB 的显存,在 INT4 下可以方便地进行推理之余,还能搞搞模型并行,QPS 也会有所体现。但是单 48GB 显存的话,内存可能会爆.
最近比较流行的有个 LLaMA CPP 项目,就支持 INT4 量化,而且未来还计划支持 INT2 量化。但 INT2 量化这个效果就不敢保证了,因为 INT4 至少有不少项目,像是 LLaMA、ChatGLM 都做过实验,测试下来精度损失不会那么大,但是 INT2 还没有实践数据出来,不知道到底精度损失会有多少?
小结下,我建议你最好是准备一个 A800 的机器,或者是两个 A6000 这样的机器,或者四个 A30,都能做 65b 的推理。这个配置会比较稳妥一点。 下个问题.
Wey:这里我想追问下卓见一个问题。我有一个穷人版的 24GB 显存,暂时还没试过 Fine-Tuning,但是我现在做正常精度的 6b 推理是 OK 的。如果是 INT4 的话,据说 6GB 显存就可以推理?
陈卓见:这里解释下显存和模型参数量的关系,如果你是 6b 模型的话,一般显存是 12GB,就能做正常的 fp16 推理,而 INT4 的话,直接显存除以 3,大概 4 GB 就可以做 INT4 的推理。如果你现在是 24GB 的显存,其实可以试试 13b 的模型.
Q:非结构化的数据,比如就一本书,如何先存储到 graph 里 ?
Wey:😂 穷人的实现思路,这个书如果是有 PDF 的话,直接用 Llama Index 6、7 行代码就可以扫入到数据库中。如果是之前我们的 prompt 的话,用 NLP 专业角度判断的话,它其实效果并没有那么的好,但是可以接受。此外,Llama Index 还有个 hub 项目,如果你的 PDF 是纯光学扫描的话,它会自动 OCR 提取信息.
陈卓见:这里我补充下,你数据存储到图中要干嘛?如果是做一个问答,那么 Llama Index 是个不错的方案。如果是其他的需求,其实一个纯文本的 txt,可能也就行了.
Q:训练模型或者是进行 Fine-Tuning,在数据准备方面有什么经验分享 ?
陈卓见:Fine-Tuning 要准备的数据量取决于你要实现的功能,不同的事情难度,所需的数据量是不同的。比如,你要用 LLaMA 做一个中文问答,你要做中文的词表,准备中文的问答数据,再搭配一部分英文的问答数据,这样做一个 LoRA 微调。但你如果是只做英文的问答,中文这块的数据就不需要了,用少量的英文数据,就能很好地调好模型。一般就是写 prompt,再写输出,组成对,LoRA 有标准格式,整成标准格式就能用.
Q:在实际应用中,如何做领域知识图谱的品控,确保 kg 就是知识图谱的内容完备跟准确性,如果知识图谱的内容都错了怎么办 ?
陈卓见:其实,我们一般是准备好几个模型。大模型只是一部分,比如说我们准备三个模型,第一个模型是用大模型,第二个模型是 Bert + NER,第三个是基于规则的模型,然后这三个模型组成一个类似的投票模型。三个模型都通过的数据就放进去,两个模型通过的数据就让人校验下,只有一个通过的数据,目前我们是不采用的,直接不要。目前,实践下来,N+ 的准确率只有 70-80%,准确率并不是很高。但再经过一道 LoRA,准确率会提高点。建议还是做多模型,相对会保险一点.
Q:大模型的语言 ASR 处理有什么经验分享,比如:语音的特征提取怎么做 ?
陈卓见:这就是大模型的多模态,一般是先做小模型,对语音、图像进行 Embedding 之后,再归一成一个大模型。可以先看看语音的 Embedding 是如何实现的,再看看多模态的大模型是如何将其相结合。不过目前来说,尚在一个摸索阶段,没有非常成熟的解决方案.
Q:让模型以固定形式回复问题,怎么构建数据训练模型呢?比如说法律问题要以什么法规去回答问题 ?
Wey:如果是训练的话,我其实没有做过 Fine-Tuning。如果是纯 prompt 的话,有几个原则:给出各种例子、各种强调输出结果格式,prompt 这套就是个黑匣子,有时候你来回调整语序就能得到不错的结果。当然有些边缘 case,可能难以按照固定的格式输出,你可以用正则表达做个兜底,确保最后的一个输出格式.
陈卓见:我们在做 Fine-Tuning 的时候,在数据收集时,可以过滤掉一些偏见数据。还有就是在模型训练的微调阶段,有一个 Reward model,就是回答打分,你可以把某一类问题中你觉得回答的不好的回复打低分,然后在 PPO 阶段,模型进行学习时,就会降低输出这类回答的概率。一般来说,还是在 prompt 里加巨长的 prompt,可能是几百个 prompt,类似于不要回答什么,优先回答什么,写个很长这样的东西让它去做回答。一般不建议在训练阶段,去做输出的格式的实现,因为成本非常昂贵,相对的写 prompt 的成本就低多了.
谢谢你读完本文 (///▽///) 。
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、( з )-☆ star 它 -> GitHub ;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下 「你的名片」 一起玩耍呀~ 。
最后此篇关于关于LLM和图数据库、知识图谱的那些事的文章就讲到这里了,如果你想了解更多关于关于LLM和图数据库、知识图谱的那些事的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
27
4
 0
0
Facebook今天发布了事件页面的新设计(http://allfacebook.com/testing-new-layout-for-events_b111326) 有什么方法可以访问封面网址并使用
这个问题在这里已经有了答案: What's the Facebook's Graph API call limit? (5 个答案) 关闭 5 年前。 我已经研究并得出结论,Facebook Gra
我刚开始使用 Facebook,老实说,我发现它非常令人困惑,术语和文档在很多情况下似乎非常模糊。有人可以用简单的英语解释我如何实现以下目标吗? 将图片发布到 Facebook(在用户页面上),然后检
有人有关于如何使用 Android Graph API 的示例吗? 我受困于基础知识,例如在 Facebook 上将文本发布到墙上。 我正在使用适用于 Android 的 Facebook SDK。这
我的任务是使用 Instagram Graph API 获取我的商业 Instagram 帐户的照片数据。我按照 Instagram Graph API 的说明进行操作 - https://devel
我正在使用 Facebook Graph API我想知道哪些字段可用于 &fields 参数,以及在哪里可以找到有关这些字段的文档。 我只能在文档中找到 &type 参数的搜索类型,例如 page 搜
我曾经使用 Facebook 的 PHP 在我的应用程序中返回 RSS 提要。现在已弃用。在 Facebook 开发者页面上它说 “页面 RSS Feed 端点 - 位于 https://www.fa
尝试了以下端点: https://graph.facebook.com/v2.6/{video-id}/video_insights/total_video_views?access_token={t
Facebook 发布了其著名图形 API 的新版本,我认为 https://developers.facebook.com/ 提供的文档很困惑。我实际上正在开发一个需要 facebook 连接的应用
这是我在 StackOverflow 上的第一篇文章,但我已经使用了很长时间... 我的问题基本上很简单,我想把一个UITextView(mShareText)的内容分享到用户的墙上,不提示任何Dia
我正在尝试为此issue 提供关联ID但我不确定如何获得它。我想应该是回应,对吗?可能是 client-request-id 吗? HTTP 响应 HTTP/1.1 403 Forbidden Cac
我正在尝试使用 this 集成 Facebook android sdk|关联。一切运行完美,除了我在尝试为已登录用户获取 email 时收到一个 JSONException。 下面是我得到的logc
我想显示我在单独网页上发布的公共(public) Facebook 事件列表,以便更轻松地保持更新 - 只需更新 Facebook,下次调用图形 API 就会显示我当前的事件。 我已经在页面上运行了
我正在尝试在我的 Android 应用程序中添加访问 friend 列表的额外权限,有很多关于旧 API 图的资源,但找不到新 API 的任何内容,所以我尝试向数组添加新权限,但没有成功'无法正常工作
根据 Facebook 的 Graph API 文档 (here),您可以通过以下 URL 访问用户个人资料图片的各种尺寸: https://graph.facebook.com/(userid)/p
想象一下当我以 userA 身份登录 facebook web 应用程序时的情况。我知道 userB 的昵称,但他不在我的好友列表中,我也不知道他的 ID。当然,他不使用我的应用程序。 如何通过昵称获
对于我的测试用户,我可以获得的访问 token 始终具有相同的范围: public_profile, basic_info, user_friends 我没有找到修改测试用户在界面中或通过 API 调
我知道一旦我拥有访问 token 就可以显示公共(public)图像,但我该如何获取它?我发现 facebook 开发文档在扩展权限方面有点令人困惑。 我是否需要以某种方式将图片库/作品集注册为应用程

我是一名优秀的程序员,十分优秀!