
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 。
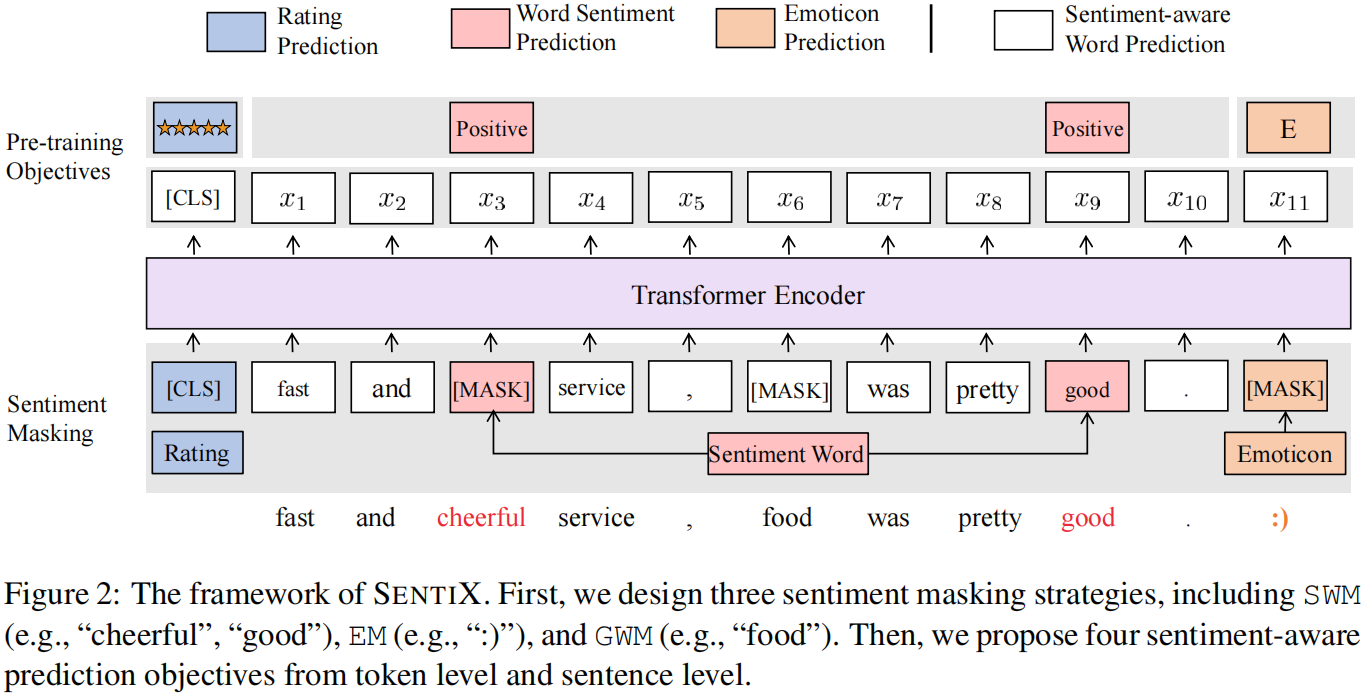
论文标题:SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis 论文作者:Jie Zhou, Junfeng Tian, Rui Wang, Yuanbin Wu, Wenming Xiao, Liang He 论文来源: 论文地址: download 论文代码: download 视屏讲解:click 。
出发点 :预先训练好的语言模型已被广泛应用于跨领域的 NLP 任务,如情绪分析,实现了最先进的性能。然而,由于用户在不同域间的情绪表达的多样性,在源域上对预先训练好的模型进行微调往往会过拟合,导致在目标域上的结果较差; 。
思路:通过大规模 review 数据集的领域不变情绪知识对情感软件语言模型(SENTIX)进行预训练,并将其用于跨领域情绪分析任务,而无需进行微调。本文提出了一些基于现有的标记和句子级别的词汇和注释的训练前任务,如表情符号、情感词汇和评级,而不受人为干扰。进行了一系列的实验,结果表明,该模型具有巨大的优势.
预训练模型在跨域情感分析上存在的问题:
贡献:
评论包含了许多半监督的情绪信号,如 情绪词汇 、 表情符号 和 评级 ,而大规模的评论数据可以从像 Yelp 这样的在线评论网站上获得.
策略:
$\mathcal{L}_{w}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(\left|x_{i}\right| \hat{x}_{i}\right)\right)$ 。
Word Sentiment Prediction (WSP) 。
根据情感知识,把词的情绪分为积极的、消极的和其他的。因此,设计了 WSP 来学习标记的情感知识。我们的目的是推断单词 $w_{i}$ 的情绪极性 $s_{i}$ 根据 $h_{i}$,$P\left(s_{i} \mid \hat{x_{i}}\right)= \operatorname{Softmax}\left(W_{s} \cdot h_{i}+b_{s}\right) $。这里使用交叉熵损失:
$\mathcal{L}_{s}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(s_{i} \mid \hat{x}_{i}\right)\right)$ 。
Rating Prediction (RP) 。
以上任务侧重于学习 Token 水平的情感知识。评级代表了句子级评论的情绪得分。推断评级将带来句子水平的情感知识。与BERT类似,使用最终状态 $h_{[\mathrm{CLS}]}$ 作为句子表示。该评级由 $P(r \mid \hat{x})=\operatorname{Softmax}\left(W_{r} \cdot h_{[C L S]}+b_{r}\right)$ 进行预测,并根据预测的评级分布计算损失:
$\mathcal{L}_{r}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \log (P(r \mid \hat{x}))$ 。
$\mathcal{L}=\mathcal{L}_{T}+\mathcal{L}_{S}$ 。
其中:
$\mathcal{L}_{T}=\mathcal{L}_{w}+\mathcal{L}_{s}+\mathcal{L}_{e} $ 。
$\mathcal{L}_{S}=\mathcal{L}_{r}$ 。

最后此篇关于论文解读(SentiX)《SentiX:ASentiment-AwarePre-TrainedModelforCross-DomainSentimentAnalysis》的文章就讲到这里了,如果你想了解更多关于论文解读(SentiX)《SentiX:ASentiment-AwarePre-TrainedModelforCross-DomainSentimentAnalysis》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
我在这里的意图是创建一个单线程的 will-make-you-a-better-programmer-just-for-reading 之类的 文章 或 论文 或 真正站起来的博文作者付出了很多努力来
我想知道是否有人有很好的资源可以阅读或编写代码来试验“自动完成” 我想知道自动完成背后的理论是什么,从哪里开始什么是常见的错误等。 我发现 Enso、Launchy、Google chrome 甚至
市场上有许多工具,如 MPS,它们促进了面向语言的编程,据说这使程序员能够为任务设计(理想的?)语言。出于某种原因,这听起来既有趣又无聊,所以我想知道是否有人知道并可以推荐有关该主题的文章。 谢谢 最
我正在编写一个使用 JointJS 来显示图表的应用。 但是,我希望能够在页面中动态添加和删除图表。添加新图表相当简单,但是当我删除图表时,删除 DOM 元素并让图表和纸张对象被垃圾收集是否安全? 最
我在声明非成员函数listOverview()时出错; void listOverview() { std::cout #include class Book; class Paper
关闭。这个问题需要更多focused .它目前不接受答案。 想改进这个问题吗? 更新问题,使其只关注一个问题 editing this post . 关闭 3 年前。 Improve this qu
我正在将 Raphael 与 Meteor 一起使用,但遇到了问题。我正在创建一个 paper通过使用 var paper = Raphael("paper", 800, 600);如果我将此代码放在
我正在使用acm LaTeX template我在使纸张双倍行距时遇到困难。 我的 LaTeX 文档如下所示: \documentclass{acm_proc_article-sp} \usepack
H.Chi Wong、Marshall Bern 和 David Goldberg 的论文“An Image Signature for any kind image”中提到的算法步骤背后的原因是什么
我一直在使用Microsoft Academic Knoledge API一周了,直到现在我还没有遇到任何问题。我想获取某个 session 的所有论文,例如 ICLR 或 ICML。我正在尝试使用从
我正在读这篇论文Understanding Deep learning requires rethinking generalization我不明白为什么在第 5 页第 2.2 节“含义、Redema
就目前情况而言,这个问题不太适合我们的问答形式。我们希望答案得到事实、引用资料或专业知识的支持,但这个问题可能会引发辩论、争论、民意调查或扩展讨论。如果您觉得这个问题可以改进并可能重新开放,visit
我必须为非程序员(我们公司的客户)创建一个 DSL,它需要提供一些更高级别的语言功能(循环、条件表达式、变量...... - 所以它不仅仅是一个“简单”的 DSL)。 使用 DSL 应该很容易;人们应
在卷积神经网络中梯度数据的可视化中,使用 Caffe 框架,已经可视化了所有类的梯度数据,对特定类采用梯度很有趣。在“bvlc_reference_caffenet”模型的 deploy.protot
auto(x)表达式被添加到语言中。一个理性的原因是我们无法以此完善前向衰减。 template constexpr decay_t decay_copy(T&& v) noexcept( i

我是一名优秀的程序员,十分优秀!