
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 35
35
 4
4


自然语言处理(NLP)涵盖了从基础理论到实际应用的广泛领域,本文深入探讨了NLP的关键概念,包括词向量、文本预处理、自然语言理解与生成、统计与规则驱动方法等,为读者提供了全面而深入的视角.
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人 。

自然语言处理(NLP)是一门交叉学科领域,涵盖了计算机科学、人工智能、语言学等多个学科。它旨在使计算机能够理解、解释和生成人类语言的方式,从而创建与人类之间的自然、无缝的交互.
自然语言处理的主要任务是让计算机能够像人类一样理解和生成自然语言。它能够让机器读懂人类的语言,使得人们与计算机的交互更加自然流畅。这不仅可以大大提高人机交互的效率,而且也为许多行业如客服、医疗、教育等提供了极大的便利.
语言模型是自然语言处理中的核心概念之一。它描述了语言的统计属性,能够评估一个句子在给定语言中的可能性。下面我们将详细介绍几种主要的语言模型,并通过理论解释和代码示例来展现它们的工作原理.
统计语言模型(Statistical Language Models, SLM)是一种利用概率和统计理论来表示文本中词汇、短语和句子的相对频率的模型。SLM在许多自然语言处理任务中都有应用,如语音识别、文本生成、机器翻译等.
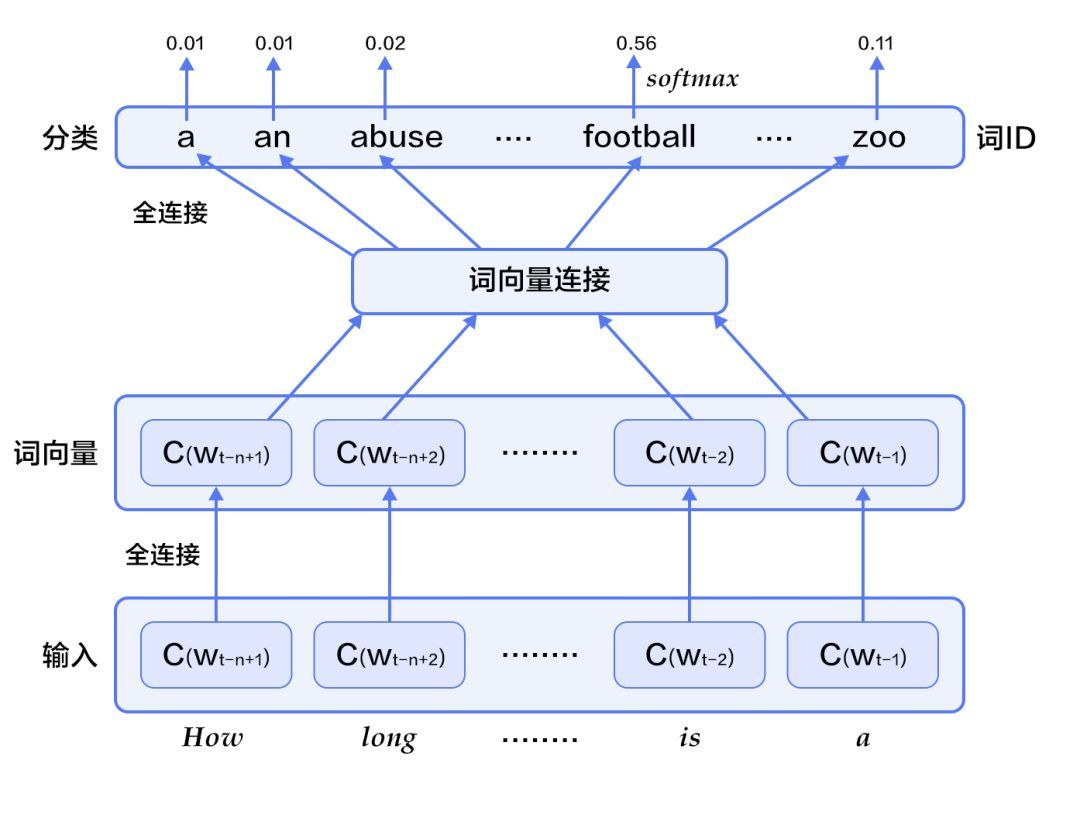
n-gram模型是一种常见的SLM,其中n表示窗口内的词数。以下是一个使用Python的例子来展示n-gram的基本概念.
from collections import Counter
from nltk.util import ngrams
text = "自然语言处理是人工智能的一个重要方向。"
tokens = text.split()
bigrams = ngrams(tokens, 2)
bigram_freq = Counter(bigrams)
# 输出
# Counter({('自然语言', '处理'): 1, ('处理', '是'): 1, ...})
n-gram模型通过统计每个n-gram出现的频率来估计其概率。虽然n-gram模型可以捕捉一些局部依赖性,但它并不能很好地理解句子的长距离依赖关系.
连续词袋模型(CBOW)是一种神经网络语言模型,它试图根据上下文词来预测当前词。CBOW通过嵌入层将词转化为向量,然后通过隐藏层来捕捉上下文信息.
以下是一个简单的CBOW模型的PyTorch实现:
import torch
import torch.nn as nn
class CBOW(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.linear1 = nn.Linear(embed_dim, 128)
self.linear2 = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs))
out = torch.relu(self.linear1(embeds))
out = self.linear2(out)
return out
连续词袋模型通过捕捉词之间的相互关系来理解句子的结构。与n-gram模型相比,CBOW可以捕捉更复杂的语义关系.
当然,下面我们将继续深入探讨自然语言处理中的基础概念之一:词向量.
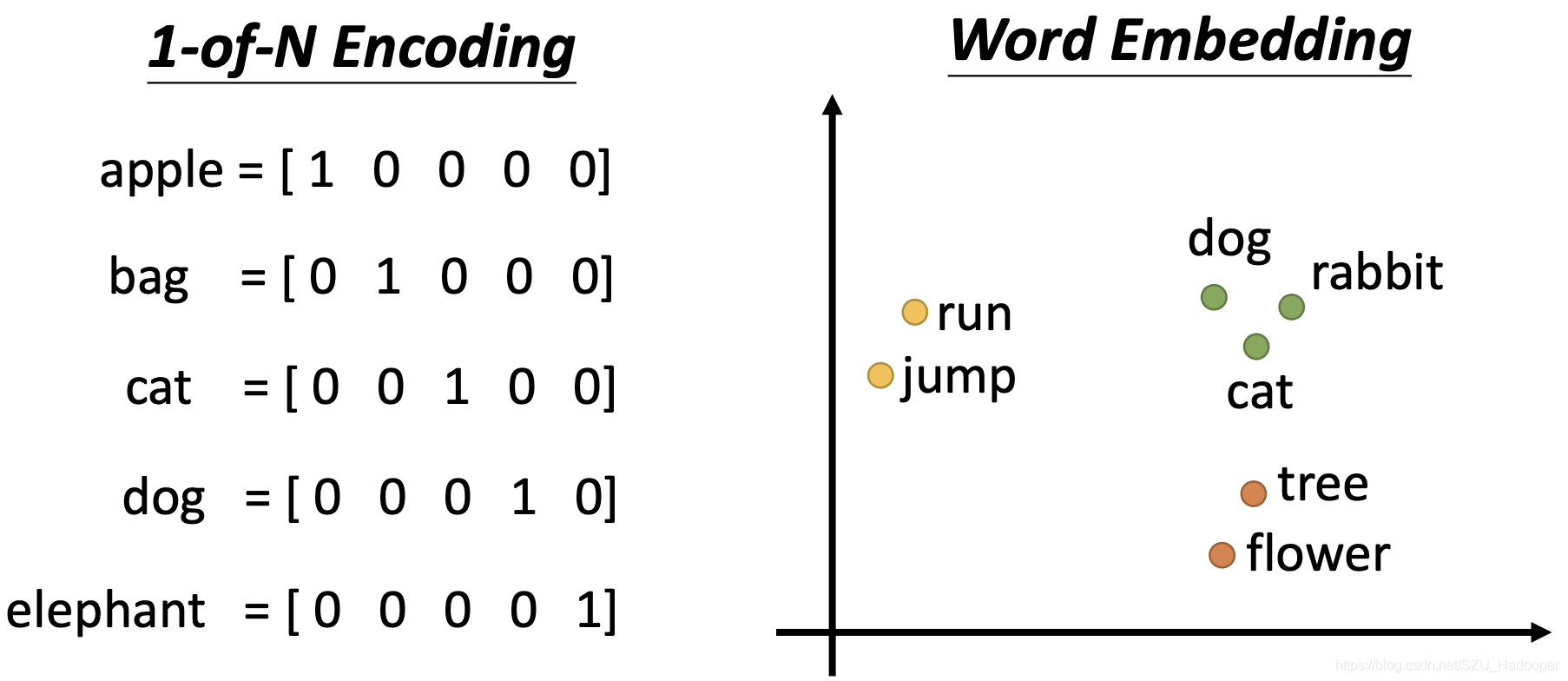
词向量,也被称为词嵌入,是自然语言处理中的关键概念。它通过将词映射到连续的向量空间中,使得机器能够捕捉词之间的相似性和语义关系。接下来我们将详细介绍几种主要的词向量模型.
Word2Vec是一种流行的词嵌入方法,通过无监督学习从大量文本中学习词向量。Word2Vec包括Skip-Gram和CBOW两种架构.
Skip-Gram模型通过当前词来预测周围的上下文词。以下是一个简化的Skip-Gram模型的PyTorch实现:
class SkipGram(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(SkipGram, self).__init__()
self.in_embeddings = nn.Embedding(vocab_size, embed_dim)
self.out_embeddings = nn.Embedding(vocab_size, embed_dim)
def forward(self, target, context):
in_embeds = self.in_embeddings(target)
out_embeds = self.out_embeddings(context)
scores = torch.matmul(in_embeds, out_embeds.t())
return scores
GloVe(Global Vectors for Word Representation)是另一种流行的词嵌入方法,它通过统计共现矩阵并对其进行分解来获取词向量.
以下是一个GloVe模型的简化实现:
class GloVe(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(GloVe, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embed_dim)
self.context_embeddings = nn.Embedding(vocab_size, embed_dim)
self.bias = nn.Embedding(vocab_size, 1)
self.context_bias = nn.Embedding(vocab_size, 1)
def forward(self, target, context):
target_embeds = self.embeddings(target)
context_embeds = self.context_embeddings(context)
target_bias = self.bias(target)
context_bias = self.context_bias(context)
dot_product = (target_embeds * context_embeds).sum(1)
logits = dot_product + target_bias.squeeze() + context_bias.squeeze()
return logits
FastText是由Facebook AI Research (FAIR)团队开发的一种词向量和文本分类模型。与Word2Vec等模型相比,FastText的主要特点是考虑了词内的子词信息。这一特性使其在许多语言和任务上都表现优异.
FastText通过将每个词分解为字符n-grams来捕捉词内结构信息。例如,对于单词“apple”,其3-grams包括"app"、"ppl"、"ple"等。这种子词表示有助于捕捉形态学信息,特别是在形态丰富的语言中.
下面的代码使用Gensim库训练FastText模型,并展示如何使用训练后的模型.
from gensim.models import FastText
# 示例句子
sentences = [["natural", "language", "processing"],
["language", "model", "essential"],
["fasttext", "is", "amazing"]]
# 训练模型
model = FastText(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取单词"language"的向量
vector_language = model.wv["language"]
# 找到最相似的单词
similar_words = model.wv.most_similar("language")
# 输出:
# [('natural', 0.18541546112537384), ('model', 0.15876708467006683), ...]
FastText还提供了一种高效的文本分类方法。与许多深度学习模型不同,FastText在文本分类任务上的训练非常快速.
与Word2Vec一样,也有许多针对特定语言和领域的预训练FastText模型。这些模型可用于各种自然语言处理任务.
文本预处理是自然语言处理任务的基础阶段,它涉及将原始文本转换为适合机器学习模型处理的格式。这个过程通常包括以下几个主要步骤.
分词是将文本划分为单词或符号的过程。这一步骤可能会涉及特定语言的复杂规则.
例如,使用Python的nltk库进行英文分词:
from nltk.tokenize import word_tokenize
text = "Natural Language Processing is fascinating."
tokens = word_tokenize(text)
# 输出
# ['Natural', 'Language', 'Processing', 'is', 'fascinating', '.']
停用词是在文本中频繁出现但通常对分析没有太大意义的词汇,如“the”、“is”等。去除它们可以减少数据的噪声.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_tokens = [w for w in tokens if w not in stop_words]
# 输出
# ['Natural', 'Language', 'Processing', 'fascinating', '.']
词干提取是将词汇还原为其基本形态(或词干)。词形还原则考虑了词的词性,并将词还原为其基本形态.
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
stemmed = [stemmer.stem(word) for word in filtered_tokens]
lemmatized = [lemmatizer.lemmatize(word) for word in filtered_tokens]
# 输出
# stemmed: ['natur', 'languag', 'process', 'fascin', '.']
# lemmatized: ['Natural', 'Language', 'Processing', 'fascinating', '.']
文本编码是将文本转换为数字形式,以便机器学习模型可以处理。常见的方法有词袋模型、TF-IDF编码等.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform([text])
# 输出: X是一个稀疏矩阵,包含TF-IDF编码的文本
自然语言理解是一项使计算机理解、解释和响应人类语言的技术。这不仅涉及单纯的语法分析,还包括深层次的语义、情感、语境和意图分析。下面我们将详细探讨自然语言理解的几个关键方面.
依存句法分析是分析句子中单词之间的语法关系,例如主语和动词之间的关系。这有助于理解句子的结构和意义.
例如,使用Spacy进行依存句法分析:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Natural Language Processing is fascinating.")
for token in doc:
print(token.text, token.dep_, token.head.text)
# 输出:
# Natural amod Processing
# Language compound Processing
# Processing nsubj fascinating
# is aux fascinating
# fascinating ROOT fascinating
# . punct fascinating
语义角色标注是一种分析句子中谓词与其相关论元(如主语、宾语等)之间语义关系的任务。简而言之,它试图理解句子的“谁做了什么给谁”.
在SRL中,通常考虑以下几种主要的语义角色:
语义角色标注广泛应用于问答系统、信息抽取、机器翻译等任务,因为它有助于理解句子的深层含义.
我们可以使用AllenNLP库进行语义角色标注。下面的代码加载了预训练的模型并运用于示例句子.
from allennlp.predictors.predictor import Predictor
import allennlp_models.structured_prediction
# 加载预训练模型
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/bert-base-srl-2020.11.19.tar.gz")
# 示例句子
sentence = "John gave a book to Mary."
# 进行语义角色标注
result = predictor.predict(sentence=sentence)
# 输出结果
for word, tag in zip(result["words"], result["verbs"][0]["tags"]):
print(f"{word}: {tag}")
# 输出:
# John: B-ARG0
# gave: B-V
# a: B-ARG1
# book: I-ARG1
# to: B-ARG2
# Mary: I-ARG2
# .: O
这里的 B-ARG0 , B-ARG1 等标签代表了不同的语义角色,其中 B- 和 I- 分别表示角色的开始和内部.
实体识别是确定文本中提到的命名实体,如人名、地点、组织等,并将它们分类为预定义的类别.
for ent in doc.ents:
print(ent.text, ent.label_)
# 输出:
# Natural Language Processing ORG
当然,情感分析是自然语言处理中的一个广泛应用领域。下面是对情感分析的详细介绍以及相关代码示例.
情感分析是分析文本作者情感倾向的过程,通常用于分析社交媒体、评论、意见等文本的情感色彩。情感可以分为正面、负面、中性或更复杂的情感类型.
下面是使用PyTorch构建一个简单的LSTM模型进行情感分析的代码示例.
import torch
import torch.nn as nn
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, output_size, embedding_dim, hidden_dim, n_layers):
super(SentimentLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
embedded = self.embedding(x)
lstm_out, _ = self.lstm(embedded)
lstm_out = lstm_out.contiguous().view(-1, hidden_dim)
output = self.fc(lstm_out)
sig_out = self.sigmoid(output)
return sig_out
# 示例参数
vocab_size = 1000
output_size = 1
embedding_dim = 400
hidden_dim = 256
n_layers = 2
model = SentimentLSTM(vocab_size, output_size, embedding_dim, hidden_dim, n_layers)
# 示例输入
input_text = torch.randint(0, vocab_size, (1, 10))
# 情感预测
output = model(input_text)
# 输出情感分析结果
print(output) # 值越接近1表示正面,越接近0表示负面
自然语言生成是一个复杂的过程,其中计算机系统使用算法来创建类似人类的文字描述。NLG是许多应用的关键组成部分,包括聊天机器人、报告生成和更复杂的创造性任务。以下是自然语言生成的几个关键方面.
文本模板生成是一种基本的自然语言生成技术,通过填充预定义模板来创建文本.
template = "Today's weather in {city} is {weather} with a temperature of {temperature} degrees."
text = template.format(city="New York", weather="sunny", temperature=25)
# 输出: "Today's weather in New York is sunny with a temperature of 25 degrees."
当然!基于规则的生成在自然语言生成(NLG)中起着关键作用,特别是在结构化的或领域特定的场景中。下面是基于规则的生成的详细介绍和代码示例.
基于规则的生成是一种使用预定义规则和模板来生成文本的方法。与基于数据驱动的机器学习方法不同,基于规则的方法不需要训练数据。它通常在具有清晰结构和限制范围的任务中非常有效.
下面的Python代码示例展示了如何使用简单的规则生成天气报告.
import random
def generate_weather_report(city, temperature, weather_condition):
templates = [
f"The weather in {city} today is {weather_condition} with a temperature of {temperature}°C.",
f"In {city}, expect {weather_condition} conditions with temperatures around {temperature}°C.",
f"If you're in {city}, you'll experience {weather_condition} weather with temperatures at {temperature}°C."
]
# 随机选择一个模板
return random.choice(templates)
# 示例输入
city = "New York"
temperature = 22
weather_condition = "sunny"
# 生成报告
report = generate_weather_report(city, temperature, weather_condition)
print(report) # 输出: "In New York, expect sunny conditions with temperatures around 22°C."
统计语言模型使用文本的统计特性来生成新的文本。n-gram模型是这种方法的一个例子,其中n表示文本中连续出现的单词数量.
序列到序列(Seq2Seq)模型可以用于更复杂的文本生成任务,如机器翻译和摘要生成。以下是使用PyTorch实现Seq2Seq模型的示例.
import torch
import torch.nn as nn
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, source, target):
# 编码源序列
encoder_outputs, hidden = self.encoder(source)
# 解码生成目标序列
output = self.decoder(target, hidden, encoder_outputs)
return output
# 输出: Seq2Seq模型可用于任务如机器翻译
预训练语言模型,如GPT系列模型,已经在自然语言生成方面取得了显著成功。这些模型通过在大型文本语料库上进行预训练,捕捉了丰富的语言结构和知识.
自然语言处理不仅是一门具有挑战性的科学,还是一项充满潜力的技术,能够推动许多行业和应用的发展。从理论到实践,本文提供了对NLP核心概念和方法的全面视角,旨在为研究人员、工程师和爱好者提供深入而完整的理解。无论是在商业、教育还是娱乐领域,自然语言处理都是连接人类和计算机的重要桥梁,其前景和影响将持续深远.
如有帮助,请多关注 个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。 TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人.
最后此篇关于一文详解自然语言处理两大任务与代码实战:NLU与NLG的文章就讲到这里了,如果你想了解更多关于一文详解自然语言处理两大任务与代码实战:NLU与NLG的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
35
4
 0
0
问题情景 混淆群内的小伙伴遇到这么个问题,Mailivery 这个网站登录后,明明提交的表单(邮箱和密码也正确)、请求头等等都没问题,为啥一直重定向到登录页面呢?唉,该出手时就出手啊,我也看看咋回事
实战-行业攻防应急响应 简介: 服务器场景操作系统 Ubuntu 服务器账号密码:root/security123 分析流量包在/home/security/security.pcap 相
背景 最近公司将我们之前使用的链路工具切换为了 OpenTelemetry. 我们的技术栈是: OTLP C
一 同一类的方法都用 synchronized 修饰 1 代码 package concurrent; import java.util.concurrent.TimeUnit; public c
一 简单例子 1 代码 package concurrent.threadlocal; /** * ThreadLocal测试 * * @author cakin */ public class T
1. 问题背景 问题发生在快递分拣的流程中,我尽可能将业务背景简化,让大家只关注并发问题本身。 分拣业务针对每个快递包裹都会生成一个任务,我们称它为 task。task 中有两个字段需要
实战环境 elastic search 8.5.0 + kibna 8.5.0 + springboot 3.0.2 + spring data elasticsearch 5.0.2 +
Win10下yolov8 tensorrt模型加速部署【实战】 TensorRT-Alpha 基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10、
yolov8 tensorrt模型加速部署【实战】 TensorRT-Alpha 基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10、linux,
目录如下: 为什么需要自定义授权类型? 前面介绍OAuth2.0的基础知识点时介绍过支持的4种授权类型,分别如下: 授权码模式 简化模式 客户端模式 密码模式
今天这篇文章介绍一下如何在修改密码、修改权限、注销等场景下使JWT失效。 文章的目录如下: 解决方案 JWT最大的一个优势在于它是无状态的,自身包含了认证鉴权所需要的所有信息,服务器端
前言 大家好,我是捡田螺的小男孩。(求个星标置顶) 我们日常做分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。本文将分四个方案,讨论如何优化MySQL百万数
前言 大家好,我是捡田螺的小男孩。 平时我们写代码呢,多数情况都是流水线式写代码,基本就可以实现业务逻辑了。如何在写代码中找到乐趣呢,我觉得,最好的方式就是:使用设计模式优化自己
我们先讲一些arm汇编的基础知识。(我们以armv7为例,最新iphone5s上的64位暂不讨论) 基础知识部分: 首先你介绍一下寄存器: r0-r3:用于函数参数及返回值的传递 r4-r6
一 同一类的静态方法都用 synchronized 修饰 1 代码 package concurrent; import java.util.concurrent.TimeUnit; public
DRF快速写五个接口,比你用手也快··· 实战-DRF快速写接口 开发环境 Python3.6 Pycharm专业版2021.2.3 Sqlite3 Django 2.2 djangorestfram
一 添加依赖 org.apache.thrift libthrift 0.11.0 二 编写 IDL 通过 IDL(.thrift 文件)定义数据结构、异常和接口等数据,供各种编程语言使用 nam
我正在阅读 Redis in action e-book关于semaphores的章节.这是使用redis实现信号量的python代码 def acquire_semaphore(conn, semn
自定义控件在WPF开发中是很常见的,有时候某些控件需要契合业务或者美化统一样式,这时候就需要对控件做出一些改造。 目录 按钮设置圆角
师父布置的任务,让我写一个服务练练手,搞清楚socket的原理和过程后跑了一个小demo,很有成就感,代码内容也比较清晰易懂,很有教育启发意义。 代码 ?

我是一名优秀的程序员,十分优秀!