
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 30
30
 4
4


Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文标题:Moka‑ADA: adversarial domain adaptation with model‑oriented knowledge adaptation for cross‑domain sentiment analysis 论文作者:Maoyuan ZhangXiang LiFei Wu 论文来源:2023 aRxiv 论文地址: download 论文代码:download 视屏讲解:click 。
出发点 :以往方法将特征表示转换为域不变的方法倾向于只对齐边缘分布,并且不可避免地会扭曲包含判别知识的原始特征表示,从而使条件分布不一致; 。
以往方法和本文方法的对比:我们采用对抗性判别域自适应(ADDA)框架来学习边际分布对齐的领域不变知识,在此基础上,在源模型和目标模型之间进行知识自适应以实现条件分布对齐。具体地说,我们设计了一个对中间特征表示和fnal分类概率具有相似性约束的对偶结构,以便训练中的目标模型从训练后的源模型中学习鉴别知识。在一个公开的情绪分析数据集上的实验结果表明,我们的方法取得了新的最先进的性能.
跨域情绪分析相关工作的联系 :
方法对比 :

贡献 :
为了使训练中的目标编码器从训练后的源编码器中学习鉴别性知识,设计了一个面向模型的知识自适应模块,包括中间特征表示相似度约束(ISC)和最终分类概率相似度约束(FSC).
源域数据 $\boldsymbol{x}_{s} \sim \mathbb{D}_{S}$,通过源域编码器 $E_{s}$ 和 目标编码器 $E_{t}$ 分别得到特征表示 $\boldsymbol{h}_{s}=E_{s}\left(\boldsymbol{x}_{s}\right)$、 $\hat{\boldsymbol{h}}_{t}=E_{t}\left(\boldsymbol{x}_{s}\right)$,且满足 $\boldsymbol{H}_{S}=\left\{\left(\boldsymbol{h}_{s}^{i}\right)\right\}_{i=1}^{n} \sim \mathbb{H}_{S}$ 和 $\boldsymbol{H}_{T}=\left\{\left(\hat{\boldsymbol{h}}_{t}^{i}\right)\right\}_{i=1}^{n} \sim \mathbb{H}_{T} $,特征分布 $\mathbb{H}_{S}$ 和 $\mathbb{H}_{T}$ 之间的距离使用 $\text{MMD}$ 计算:
$\begin{aligned}\underset{E_{t}}{\text{min}} \; & \mathcal{L}_{\mathrm{ISC}}\left(\boldsymbol{x}_{s}\right) \\= & \operatorname{MMD}^{2}\left[\mathcal{F}, \boldsymbol{h}_{s}, \hat{\boldsymbol{h}}_{t}\right] \\= & \left\|\mathbb{E}_{\boldsymbol{h}_{s} \sim \mathbb{H}_{S}} \phi\left(\boldsymbol{h}_{s}\right)-\mathbb{E}_{\hat{\boldsymbol{h}}_{\boldsymbol{t}} \sim \mathbb{H}_{T}} \phi\left(\hat{\boldsymbol{h}}_{t}\right)\right\|_{\mathcal{H}}^{2} \\= & \mathbb{E}_{\boldsymbol{h}_{s}, \boldsymbol{h}_{s}^{\prime} \sim \mathbb{H}_{s}, \mathbb{H}_{S}} k\left(\boldsymbol{h}_{s}, \boldsymbol{h}_{s}^{\prime}\right) - 2 \mathbb{E}_{\boldsymbol{h}_{s}, \hat{\boldsymbol{h}}_{t} \sim \mathbb{H}_{s}, \mathbb{H}_{T}} k\left(\boldsymbol{h}_{s}, \hat{\boldsymbol{h}}_{t}\right) +\mathbb{E}_{\hat{\boldsymbol{h}}_{t}, \hat{h}_{t}^{\prime} \sim \mathbb{H}_{T}, \mathbb{H}_{T}} k\left(\hat{\boldsymbol{h}}_{t}, \hat{\boldsymbol{h}}_{t}^{\prime}\right),\end{aligned}$ 。
其中,核函数 $k(\boldsymbol{u}, \boldsymbol{v})=\sum_{i=1}^{m} \exp \left\{-\frac{1}{2 \delta_{i}}\|\boldsymbol{u}-\boldsymbol{v}\|_{2}^{2}\right\}$; 。
传统的方法将对目标样本设置一个硬标签(伪标签),这在重复训练过程中容易造成过拟合。为了缓解这一问题,利用知识蒸馏(KD),通过产生一个软概率分布来控制知识转移的程度.
软概率分布的优势:
接着将 $\boldsymbol{h}_{s}$、$\hat{\boldsymbol{h}}_{t}$ 放入放缩余弦分类器 。
$\boldsymbol{p}_{s}=C_{s}\left(\boldsymbol{h}_{s}\right)$ $\hat{\boldsymbol{p}}_{t}=C_{s}\left(\hat{\boldsymbol{h}}_{t}\right)$ $\boldsymbol{P}=\sigma\left(\boldsymbol{p}_{s} / T\right)$ $\boldsymbol{Q}=\sigma\left(\hat{\boldsymbol{p}}_{t} / T\right)$ 。
最终相似性约束如下:
$\begin{aligned}\underset{E_{t}}{\text{min}} \; & \mathcal{L}_{\mathrm{FSC}}\left(\boldsymbol{x}_{s}\right) \\& =T^{2} \cdot \operatorname{KL}(\boldsymbol{P} \| \boldsymbol{Q}) \\& =T^{2} \cdot \mathbb{E}_{\boldsymbol{x}_{s} \sim \mathbb{D}_{S}} \sum_{k=1}^{K} P_{k} \log \frac{P_{k}}{Q_{k}},\end{aligned}$ 。
2.1 节小结:综上所述,对源编码器和目标编码器的输入是相同的,目标编码器用“中间”和“fnal”来模拟源编码器,从而实现条件分布对齐的鉴别知识.
笔记 :
传统的余弦相似度计算公式为:
cosine similarity = dot product(A, B) / (norm(A) * norm(B)) 。
其中,dot product(A, B)表示向量 A 和 B 的点积,norm(A) 和 norm(B) 分别表示向量 A 和 B 的范数.
放缩余弦分类器通过引入放缩因子来调整余弦相似度的计算,公式如下:
scaled cosine similarity = dot product(A, B) / (scale_factor * norm(A) * norm(B)) 。
本文提出的 Moka-ADA 框架 如 Figure2 所示:
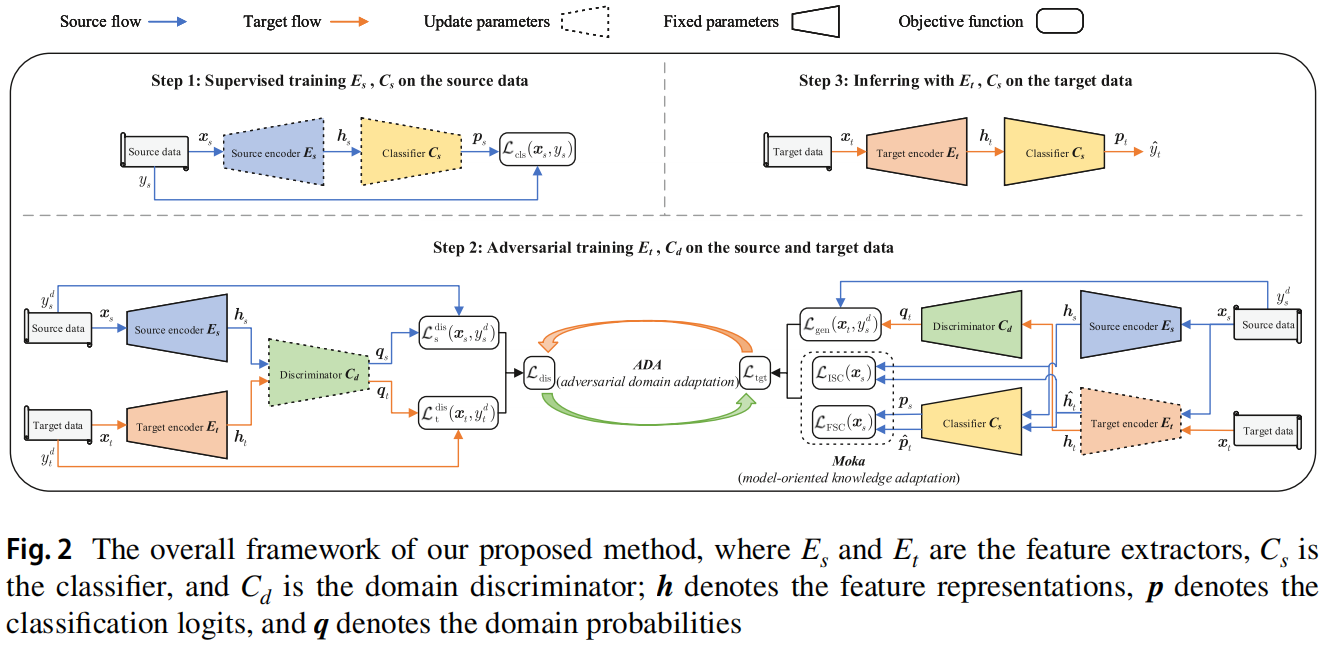
主要包括三个步骤:
Step1 ,目标是使用来自源域的标记数据来训练一个性能良好的源模型,它作为目标模型的后续训练的 “teacher”,通过使用交叉熵损失,通过对源编码器 $E_s$ 和分类器 $C_s$ 在 $(x_s,y_s)$ 进行监督训练,可以最小化源误差:
$\begin{array}{l}\underset{E_{s}, C_{s}}{\text{min}} \; \mathcal{L}_{\mathrm{cls}}\left(\boldsymbol{x}_{s}, y_{s}\right)=\mathbb{E}_{\left(\boldsymbol{x}_{s}, y_{s}\right) \sim \mathbb{D}_{S}}-\sum_{k=1}^{K} \mathbb{1}_{\left[k=y_{s}\right]} \log \sigma\left(\boldsymbol{p}_{s}\right)\end{array}$ 。
Step2 ,固定 $E_s$ 的参数,并使用 $E_s$ 初始化 $E_t$ 的参数,接着进行对抗性训练:
域分类损失最小化:
$\begin{aligned}\underset{C_{d}}{\text{min}} \; & \mathcal{L}_{\mathrm{dis}}\left(\boldsymbol{x}_{s}, \boldsymbol{x}_{t}, y_{s}^{d}, y_{t}^{d}\right) \\& =\min _{C_{d}}\left[\frac{\mathcal{L}_{\mathrm{s}}^{\mathrm{dis}}\left(\boldsymbol{x}_{s}, y_{s}^{d}\right)+\mathcal{L}_{\mathrm{t}}^{\mathrm{dis}}\left(\boldsymbol{x}_{t}, y_{t}^{d}\right)}{2}\right] \\& =\frac{\mathbb{E}_{\boldsymbol{x}_{s} \sim \mathbb{D}_{S}}-\log \left(1-\boldsymbol{q}_{s}\right)+\mathbb{E}_{\boldsymbol{x}_{t} \sim \mathbb{D}_{T}}-\log \boldsymbol{q}_{t}}{2} .\end{aligned}$ 。
域分类损失最大化(迷惑域鉴别器):
$\begin{aligned}\underset{E_{t}}{\text{min}} \;\; & \mathcal{L}_{\text {gen }}\left(\boldsymbol{x}_{t}, {\color{Red} y_{s}^{d}} \right) \\\quad & =\mathbb{E}_{\boldsymbol{x}_{t} \sim \mathbb{D}_{T}}-\left[y_{s}^{d} \log \boldsymbol{q}_{t}+\left(1-y_{s}^{d}\right) \log \left(1-\boldsymbol{q}_{t}\right)\right] \\& =\mathbb{E}_{\boldsymbol{x}_{t} \sim \mathbb{D}_{T}}-\log \left(1-\boldsymbol{q}_{t}\right),\end{aligned}$ 。
注意:对抗性训练中的 特征提取器这边指的是 目标编码器 $E_t$; 。
目标编码器的最终训练目标:
$\begin{array}{l}\underset{E_{t}}{\text{min}}\;\mathcal{L}_{\mathrm{tgt}}\left(\boldsymbol{x}_{s}, \boldsymbol{x}_{t}, y_{s}^{d}\right) \\\quad= \underset{E_{t}}{\text{min}}\left[\mathcal{L}_{\mathrm{gen}}\left(\boldsymbol{x}_{t}, y_{s}^{d}\right)+\mathcal{L}_{\mathrm{ISC}}\left(\boldsymbol{x}_{s}\right)+\mathcal{L}_{\mathrm{FSC}}\left(\boldsymbol{x}_{s}\right)\right]\end{array}$ 。
Step3 ,使用训练好的目标编码器 $E_t$ 和分类器 $C_s$ 对用于测试的目标数据情绪极性标签预测如下:
$\hat{y}_{t}=\arg \max \boldsymbol{p}_{t}$ 。
长这样的算法步骤:


情绪分类结果 。

可视化 。
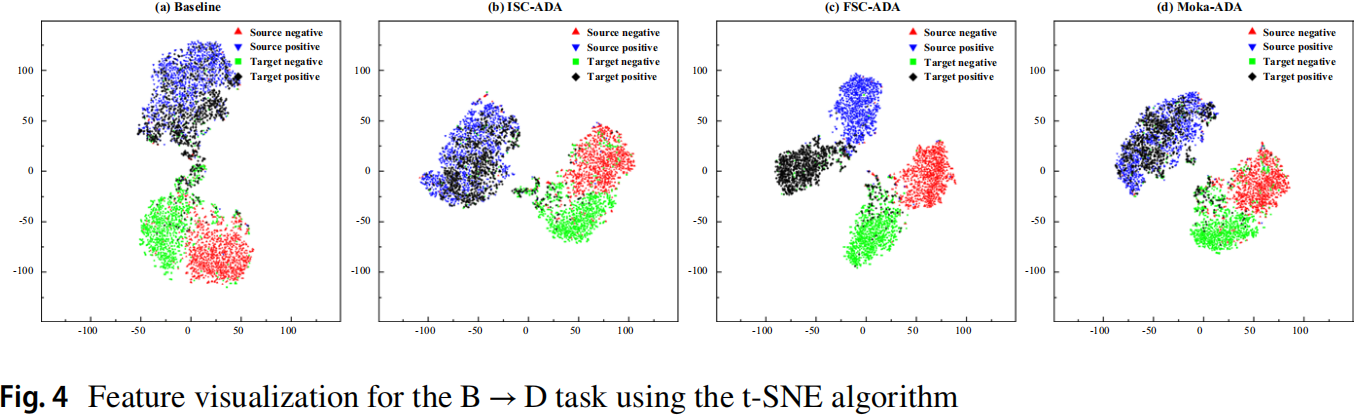
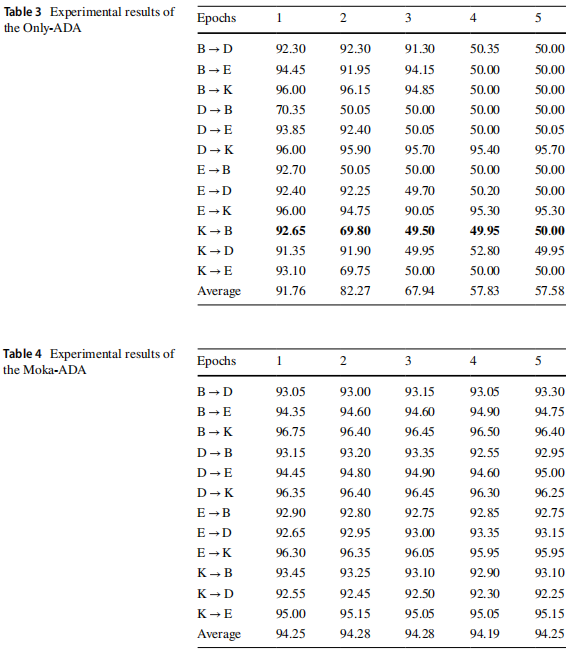
消融实验 。
最后此篇关于论文解读(Moka‑ADA)《Moka‑ADA:adversarialdomainadaptationwith model‑orientedknowledgeadaptationfor cross‑domainsentimentanalysis》的文章就讲到这里了,如果你想了解更多关于论文解读(Moka‑ADA)《Moka‑ADA:adversarialdomainadaptationwith model‑orientedknowledgeadaptationfor cross‑domainsentimentanalysis》的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
30
4
 0
0
如何在过程中编写迭代器?对不起我的转储问题,我是新手。感谢您的回答。 最佳答案 这完全取决于您需要迭代的内容。 数组?使用loop : plain, for, or while. predefined
我现在知道很多编程语言。回到我 18 岁的时候,我几乎加入了美国空军,并且对 Ada 进行了测试。那是十多年前的事了。 Ada 编程语言在军队中是否仍然像以前一样重要? 我想知道新的军事软件项目是否仍
在 Java 或 C# 中,您经常会拥有 final 的类成员。或 readonly - 它们设置一次,然后再也不碰。它们可以为类的不同实例保存不同的值。 艾达有没有类似的东西?我试图在 Ada 中创
即使使用这个简单的示例,我也无法让动态调度正常工作。我相信问题在于我如何设置类型和方法,但看不到在哪里! with Ada.Text_Io; procedure Simple is type A
我目前正在自学 Ada,尽管我可以从解决一些更传统的问题开始。 更具体地说,我尝试计算阶乘 n!,而 n>100。到目前为止,我的实现是: with Ada.Text_IO; with Ada.Int
目前正在学习 Ada 并真正享受它,有一件事情困扰着我:什么是 tagged类型?根据 John Barnes 的 Programming in Ada 2012,它表示实例化的对象在运行时带有标签。
你好 我正在尝试我在 Ada 中创建单人骰子游戏的第一个程序。 但面临着保持球员得分的问题。 目标:每个玩家有 10 个回合,如果 2 次掷骰总数为 7,则获得 10 分 问题:每次总分被重置并且 1
您可以通过让函数返回一个值来分配给变量: My_Int : Integer := My_Math_Func [(optional params)]; 或者你可以用一个过程来做到这一点(假设 My_In
我试图在 Ada 中将字符转换为整数,似乎没有任何效果,到目前为止我已经能够从 ASCII 返回 DEC,但我想返回 0(整数)。 Character'Pos('0'); 返回 48 --我希望它返回
假设我有以下常量来定义一个只接受其范围定义内的有效值的子类型: type Unsigned_4_T is mod 2**4; valid_1 : constant Unsigned_4_T :=
我正在尝试创建一个 tree-sitter解析器,以便 IDE(在本例中为 Vim)可以解析 Ada 程序文本并进行更高级的操作,例如 extract-subprogram 和 rename-vari
我正在写一篇关于 Ada 83 的论文。我们有一个作业,列出了论文的各个部分(历史、设计目标、语法等)。讲师提到我们中的一些人将有一些部分简单地说“此语言不支持此功能。” 其中两个部分是数据类型和
假设我有以下常量来定义一个只接受其范围定义内的有效值的子类型: type Unsigned_4_T is mod 2**4; valid_1 : constant Unsigned_4_T :=
我正在尝试创建一个 tree-sitter解析器,以便 IDE(在本例中为 Vim)可以解析 Ada 程序文本并进行更高级的操作,例如 extract-subprogram 和 rename-vari
我想声明一个元素类型为变体记录的数组。像这样: type myStruct (theType : vehicleType) is record ... when car => numOfWheels
我正在实例化一个带有枚举的通用包,以访问多个值之一并在子程序重载中使用。我想要一组定义明确、编译时检查过的值,我可以使用和查找。 generic -- Different types beca
我有以下包: ------------------- -- File: father.ads ------------------- package Father with SPARK_Mode =>
对于最后的程序,我从 gnat 收到以下错误消息: test2.adb:23:61: error: invalid operand types for operator "-" test2.adb:2
我编写了一个加密文件的 Ada 程序。它逐 block 读取它们以节省目标机器上的内存。不幸的是,Ada 的目录库读取 Long_Integer 中的文件大小,将读取限制为近 2GB 文件。尝试读取超
我想打印访问变量(指针)的地址以进行调试。 type Node is private; type Node_Ptr is access Node; procedure foo(n: in out No

我是一名优秀的程序员,十分优秀!