


 30
30
 4
4


我给领导汇报AI框架用函数式编程好,没讲明白,说函数式就是写函数那样方便,都被领导吊飞了,啥玩意,写啥不是写函数,狗屁不通! 。
网上搜说用tensorflow那就是用声明式编程,用pytorch就是命令式编程。有兄弟能讲清楚,AI框架的编程范式到底如何区分?AI框架中的不同编程范式有什么作用吗?
。
。
编程范式、编程范型、或程式設計法(Programming paradigm),是指软件工程中的一类典型的编程风格。常见的编程范型有:函数式编程、 命令式编程 、声明式编程、面向对象编程等等,编程范式提供并决定了开发者对程序执行的看法。在开发者使用 AI 框架进行编程的过程中,主要使用到的编程范式主要有2种:1)声明式编程与2)命令式编程.

本节将会深入展开和介绍两种不同的编程范式对AI框架整体架构设计的影响,以及目前主流的 AI 框架在编程范式之间的差异.
编程是开发者编定程序的中文简称,就是让计算机代码解决某个问题,对某个计算体系规定一定的运算方式,使计算体系按照该计算方式运行,并最终得到相应结果的过程.
为了使计算机能够理解人的意图,我们就必须将需解决的问题的思路、方法和手段通过计算机能够理解的形式告诉计算机,使得计算机能够根据人的指令一步一步去工作,完成某种特定的任务。这种人和计算体系之间交流的过程称为编程.
命令式编程(Imperative programming)是一种描述计算机所需作出的行为的编程典范,几乎所有计算机的硬件工作都是命令式的.
其步骤可以分解为:首先,必须将带解决问题的解决方案抽象为一系列概念化的步骤。然后通过编程的方法将这些步骤转化成程序指令集(算法),而这些指令按照一定的顺序排列,用来说明如何执行一个任务或解决一个问题。这意味着,开发者必须要知道程序要完成什么,并且告诉计算机如何进行所需的计算工作,包括每个细节操作。简而言之,就是把计算机看成一个善始善终服从命令的装置.
所以在命令式编程中,把待解问题规范化、抽象为某种算法是解决问题的关键步骤。其次,才是编写具体算法和完成相应的算法实现问题的正确解决.
目前开发者接触到的命令式编程主要以硬件控制程序、执行指令为主。AI 框架中 PyTorch 则主要使用了命令式编程的方式.
下面的代码实现一个简单的声明式编程的过程:创建一个存储结果的集合变量 results,并遍历数字集合 collection,判断每个数字大于 5 则添加到结果集合变量 results 中。上述过程需要告诉计算机每一步如何执行.
results = [] def fun ( collection ): for num in collection : if num > 5 : results . append ( num )
声明式编程(Declarative programming)是一种编程范式,与命令式编程相对立。它描述目标的性质,让计算机明白目标,而非流程。声明式编程不用告诉计算机问题领域,从而避免随之而来的副作用。而命令式编程则需要用算法来明确的指出每一步该怎么做.
副作用:在计算机科学中,函数副作用(Side Effects)指当调用函数时,除了返回可能的函数值之外,还对主调用函数产生附加的影响。例如修改全局变量(函数外的变量),修改参数,向主调方的终端、管道输出字符或改变外部存储信息等。
声明式编程透过函数、推论规则或项重写(term-rewriting)规则,来描述变量之间的关系。它的语言运行器(编译器或解释器)采用了一个固定的算法,以从这些关系产生结果.
目前开发者接触到的声明式编程语言主要有:括数据库查询语言(SQL,XQuery),正则表达式,逻辑编程,函数式编程等。在AI框架领域中以 TensorFlow1.X 为代表,就使用了声明式编程.
以常用数据库查询语言 SQL 为例,其属于较为明显的一种声明式编程的例子,其不需要创建变量用来存储数据,告诉计算机需要查询的目标即可:
>>> SELECT * FROM collection WHERE num > 5
函数式编程(Functional Programming)函数式编程本质上也是一种编程范式,其在软件开发的工程中避免使用共享状态(Shared State)、可变状态(Mutable Data)以及副作用。即将计算机运算视为函数运算,并且避免使用程序状态以及易变对象,理论上函数式编程是声明式的,因为它不使用可变状态,也不需要指定任何的执行顺序关系.
其核心是只使用纯粹的数学函数编程,函数的结果仅取决于参数,而没有副作用,就像 I/O 或者状态转换。程序通过 组合函数 (function composition)的方法构建。整个应用由数据驱动,应用的状态在不同纯函数之间流动。与命令式编程的面向对象编程而言,函数式编程其更偏向于声明式编程,代码更加简洁明了、更可预测,并且可测试性也更好。因此实际上可以归类为属于声明式编程的其中一种特殊范型.
函数式编程最重要的特点是“函数第一位”(First Class),即函数可以出现在任何地方,比如可以把函数作为参数传递给另一个函数,不仅如此你还可以将函数作为返回值。以 Python 代码为例:
def fun_add ( a , b , c ): return a + b + c def fun_outer ( fun_add , * args , ** kwargs ): print ( fun_add ( * args , ** kwargs )) def fun_innter ( * args ): return args if __name__ == '__main__' : fun_outer ( fun_innter , 1 , 2 , 3 )
主流AI框架,无论PyTorch还是Tensorflow都使用都以Python为主的高层次语言为前端,提供脚本式的编程体验,后端用更低层次的编程模型和编程语言开发。后端高性能可复用模块与前端深度绑定,通过前端驱动后端方式执行。AI框架为前端用户提供声明式(declarative programming)和命令式(imperative programming)两种编程范式.
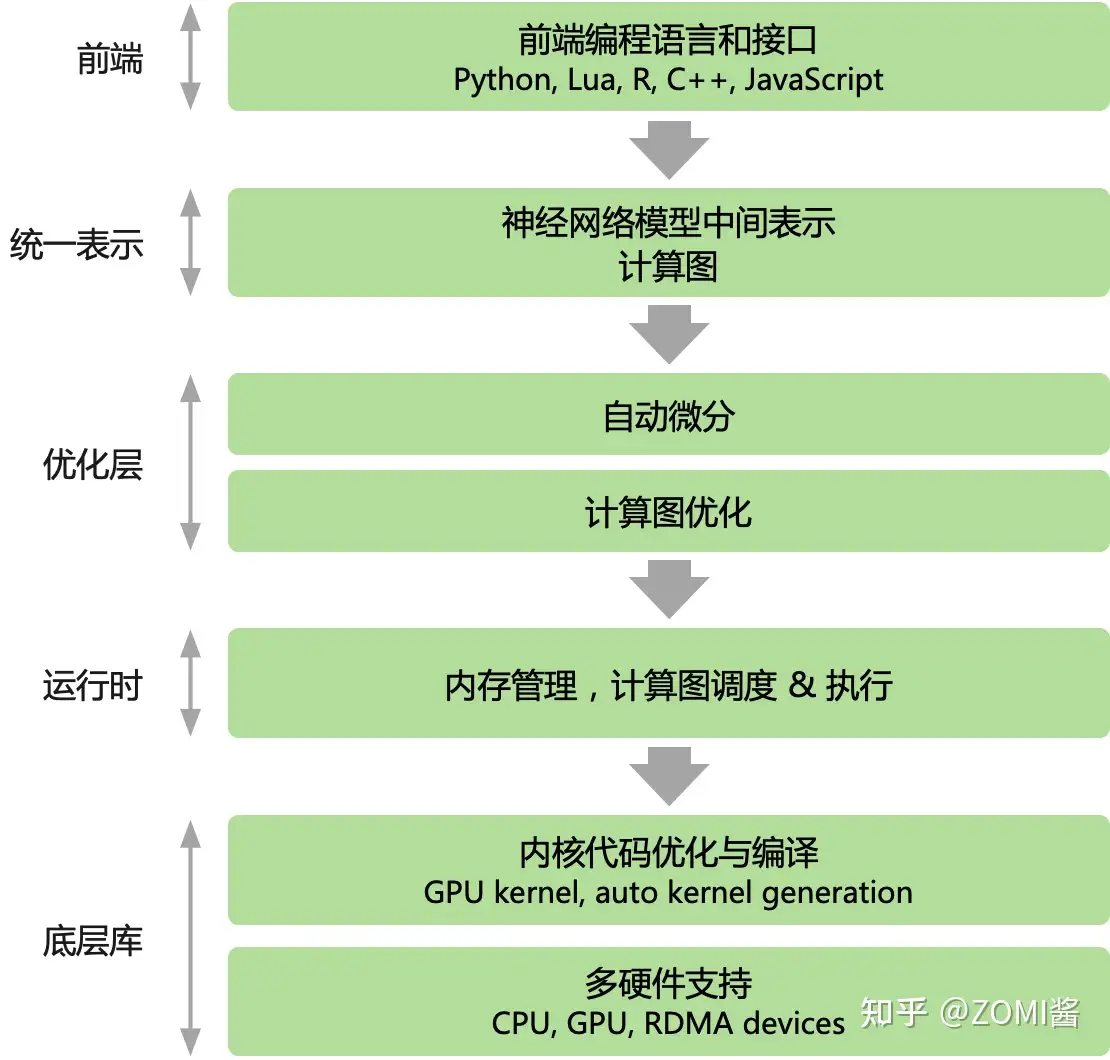
在主流的 AI 框架中,TensorFlow 提供了声明式编程体验,PyTroch 提供了命令式的编程体验。但两种编程模型之间并不存在绝对的边界,multi-stage 编程和及时编译(Just-in-time, JIT)技术能够实现两种编程模式的混合。随着 AI 框架引入更多的编程模式和特性,例如 TensorFlow Eager模式 和 PyTorch JIT 的加入,主流 AI 框架都选择了通过支持混合式编程以兼顾两者的优点.
在 命令式编程模型 下,前端 Python 语言直接驱动后端算子执行,用户表达式会立即被求值,又被称作define-by-run。开发者编写好 神经网络模型 的每一层,并编写训练过程中的每一轮迭代需要执行的计算任务。在程序执行的时候,系统会根据 Python 语言的动态解析性,每解析一行代码执行一个具体的计算任务,因此称为动态计算图(动态图).
命令式编程的优点是方便调试,灵活性高,但由于在执行前缺少对算法的统一描述,也失去了编译期优化的机会.
相比之下,命令式编程对数据和控制流的静态性限制很弱,方便调试,灵活度极高。缺点在于, 网络模型程序 在执行之前没有办法获得整个计算图的完整描述,从而缺乏缺乏在编译期的各种优化手段.
以 PyTorch 其编程特点为即时执行,它属于一种声明式的编程风格。下面使用 PyTorch 实现一个简单的 2层神经网络 模型并训练:
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split import torch import torch.nn as nn import torch.optim as optim # 导入数据 data = pd . read_csv ( 'mnist.csv' ) X = data . iloc [:, 1 :] . values y = data . iloc [:, 0 ] . values # 分割数据集 X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size = 0.2 ) # 将数据转换为张量 X_train = torch . tensor ( X_train , dtype = torch . float ) X_test = torch . tensor ( X_test , dtype = torch . float ) y_train = torch . tensor ( y_train , dtype = torch . long ) y_test = torch . tensor ( y_test , dtype = torch . long ) # 定义模型 class Net ( nn . Module ): def __init__ ( self ): super ( Net , self ) . __init__ () self . fc1 = nn . Linear ( 784 , 128 ) self . fc2 = nn . Linear ( 128 , 10 ) def forward ( self , x ): x = self . fc1 ( x ) x = self . fc2 ( x ) return x model = Net () # 定义损失函数和优化器 criterion = nn . CrossEntropyLoss () optimizer = optim . Adam ( model . parameters ()) # 训练模型 for epoch in range ( 5 ): # 将模型设为训练模式 model . train () # 计算模型输出 logits = model ( X_train ) loss = criterion ( logits , 
 个人中心
个人中心 文章发布
文章发布