
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 37
37
 4
4


这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos 。
节点亲和性:直接告诉小明,你去一年级 。
pod亲和性:从小朋友中找出和小明同年的,找到了小张,发现小张是一年级的,于是让小明去一年级 。
requiredDuringSchedulinglgnoredDuringExecution:用于定义节点硬亲和性 。
nodeSelectorTerm:节点选择器,可以有多个,之间的关系是 逻辑或 ,即一个nodeSelectorTerm满足即可 。
matchExpressions:匹配规则定义,多个之间的关系是 逻辑与 ,即同一个nodeSelectorTerm下所有matchExpressions定义的规则都匹配,才算匹配成功 。
示例:
apiVersion: v1
kind: Pod
metadata:
name: with-required-nodeaffinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- {key: zone, operator: In, values: ["foo"]}
containers:
- name: nginx
image: nginx
特点:条件不满足时也能被调度 。
示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-with-node-affinity
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 60
preference:
matchExpressions:
- {key: zone, operator: In, values: ["foo"]}
- weight: 30
preference:
matchExpressions:
- {key: ssd, operator: Exists, values: []}
containers:
- name: nginx
image: nginx
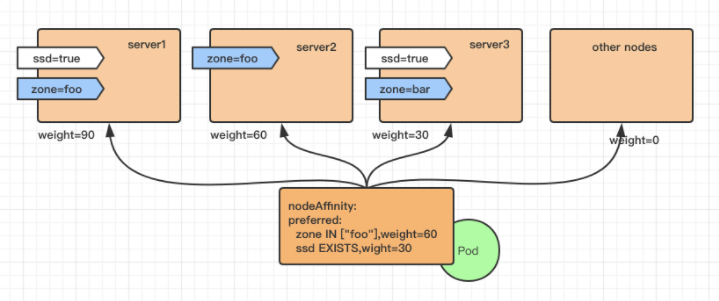
在优选阶段,节点软亲和性被用于优选函数 NodeAffinityPriority 。
注意:NodeAffinityPriority 并非决定性因素 ,因为优选阶段还会调用其他优选函数,例如 SelectorSpreadPriority (将pod分散到不同节点以分散节点故障导致的风险) 。
pod副本数增加时,分布的比率会参考节点亲和性的权重 。
如果需求是:新增的pod要和已经存在pod(假设是A)在同一node上,此时用节点亲和性是无法完成的,因为A可能和节点没啥关系(可能是随机调度的),此时只能用pod亲和性来实现 。
pod亲和性:一个pod与已经存在的某个pod的亲和关系,需要通过举例来说明 。
kubectl run tomcat -l app=tomcat --image tomcat:alpine
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity-1
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["tomcat"]}
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-with-pod-anti-affinity
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["myapp"]}
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
学习路上,你不孤单,欣宸原创一路相伴... 。
最后此篇关于Kubernetes亲和性学习笔记的文章就讲到这里了,如果你想了解更多关于Kubernetes亲和性学习笔记的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
37
4
 0
0
我只能在线找到有关将 pods 附加到基于标签的节点的文档。 有没有一种方法可以根据标签和计数将 pods 附加到节点上-那么只有带有标签y的x pods 吗? 我们的方案是,我们只想在每个节点上运行
假设一台机器上有两个处理器。线程 A 在 P1 上运行,线程 B 在 P2 上运行。 线程 A 调用 Sleep(10000); 是否有可能当线程 A 再次开始执行时,它在 P2 上运行? 如果是,谁
我想创建一个 C++11 线程,我希望它在我的第一个核心上运行。我发现 pthread_setaffinity_np 和 sched_setaffinity 可以改变线程的 CPU affinity
我正在从事计算密集型 C# 项目,该项目实现了多种算法。问题是,当我想分析我的应用程序时,特定算法所需的时间会有所不同。例如,有时运行该算法 100 次大约需要 1100 毫秒,而另一次运行 100
我想将父进程关联到一个特定的核心。在下面的代码中,变量 core 是用户提供的参数。之后,我想创建 NUM_CHILDREN 个进程,并且每个进程都以循环方式关联到其中一个核心。子进程跳出循环并执行更
我很少有与线程和进程调度相关的问题。 当我的进程进入休眠状态并唤醒时,它是否总是会被调度到之前调度的同一个 CPU 上? 当我从进程中创建一个线程时,它是否也总是在同一个 CPU 上执行?即使其他 C
我有一个服务器进程,它派生出许多子进程。服务器进程与 CPU 核心具有亲和性,但我不希望子进程继承这种亲和性(操作系统应该处理运行这些进程的位置)。有没有一种方法可以根据 cpu 亲和性解除父子进程的
尝试在 Amazon EC2 等虚拟化环境中的多核处理器上高效使用 L2 缓存时,CPU 关联性任务集是否适用? 最佳答案 不,尤其是对于较小的实例,CPU 共享量很大,您依赖于其他实例对 CPU 的
sched_setaffinity 或 pthread_attr_setaffinity_np 是否可以在 OpenMP 下设置线程关联? 相关:CPU Affinity 最佳答案 是的,命名调用将用
所以我有 4 个节点。 1是System,1是Dev,1是Qa,1是UAT。 我的亲和性如下: apiVersion: apps/v1 kind: Deployment metadata: nam
我找不到指定当附属部署使用多个副本扩展时 Kubernetes 服务行为方式的文档。 我假设有某种负载平衡。是否与服务类型有关? 此外,我希望在服务转发的请求中具有某种关联性(即,如果可能,所有具有特
我想获取有关启用了 ARR Affinity 和自动缩放的应用程序行为的详细信息? 假设我在 Azure Web App 上部署有状态 ASP.NET Web 应用。因此我启用了 ARR Affini
R 2.14.0 或更高版本包括 R package parallel它提供了对并行计算的支持。 在 类 Unix 下,此软件包提供 facility for setting CPU affinity
我想获取有关启用了 ARR Affinity 和自动缩放的应用程序行为的详细信息? 假设我在 Azure Web App 上部署有状态 ASP.NET Web 应用。因此我启用了 ARR Affini
在 Qt5 中使用线程,如何设置单个线程的 CPU affinity ? 我想指定线程可以在其下运行的可用 CPU 内核的掩码。 换句话说,Qt5相当于Posix线程的pthread_setaffin
我想通过以下方式将进程绑定(bind)到特定的核心#0(cpu 亲和性) taskset -c 0 ./run_prog 当它自己的程序在核心 #0 上运行时,操作系统可能会决定将其他后台和事件进程运
我刚刚发现了 Node.js 的worker_threads 模块,它看起来很有前途! 问题:将worker_threads与集群结合起来是否有趣/高效,或者创建的线程是否自动分布在机器的不同CPU上
我想测试在基于 64 位、2 CPU、16 核 Intel Xeon 5500 CPU 的服务器的不同物理 CPU 和不同嵌入式内存 Controller 分配和访问内存时可能发生的性能变化。 (戴尔
非常简单的问题 - 有没有办法通过 PHP 设置 CPU 亲和性?以下任何一项都可以: 通过 PHP 调用设置当前进程的亲和性。 通过 PHP 调用设置特定 PID 的亲和性。 作为最后的手段,通过命
我需要创建一个内核模块,在计算机的每个内核上启用 ARM PMU 计数器。我在设置 cpu 亲和性时遇到问题。我试过 sched_get_affinity,但显然,它只适用于用户空间进程。我的代码如下

我是一名优秀的程序员,十分优秀!