
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 32
32
 4
4


浏览记录系统主要用来记录京东用户的实时浏览记录,并提供实时查询浏览数据的功能。在线用户访问一次商品详情页,浏览记录系统就会记录用户的一条浏览数据,并针对该浏览数据进行商品维度去重等一系列处理并存储。然后用户可以通过我的京东或其他入口查询用户的实时浏览商品记录,实时性可以达到毫秒级。目前本系统可以为京东每个用户提供最近200条的浏览记录查询展示.
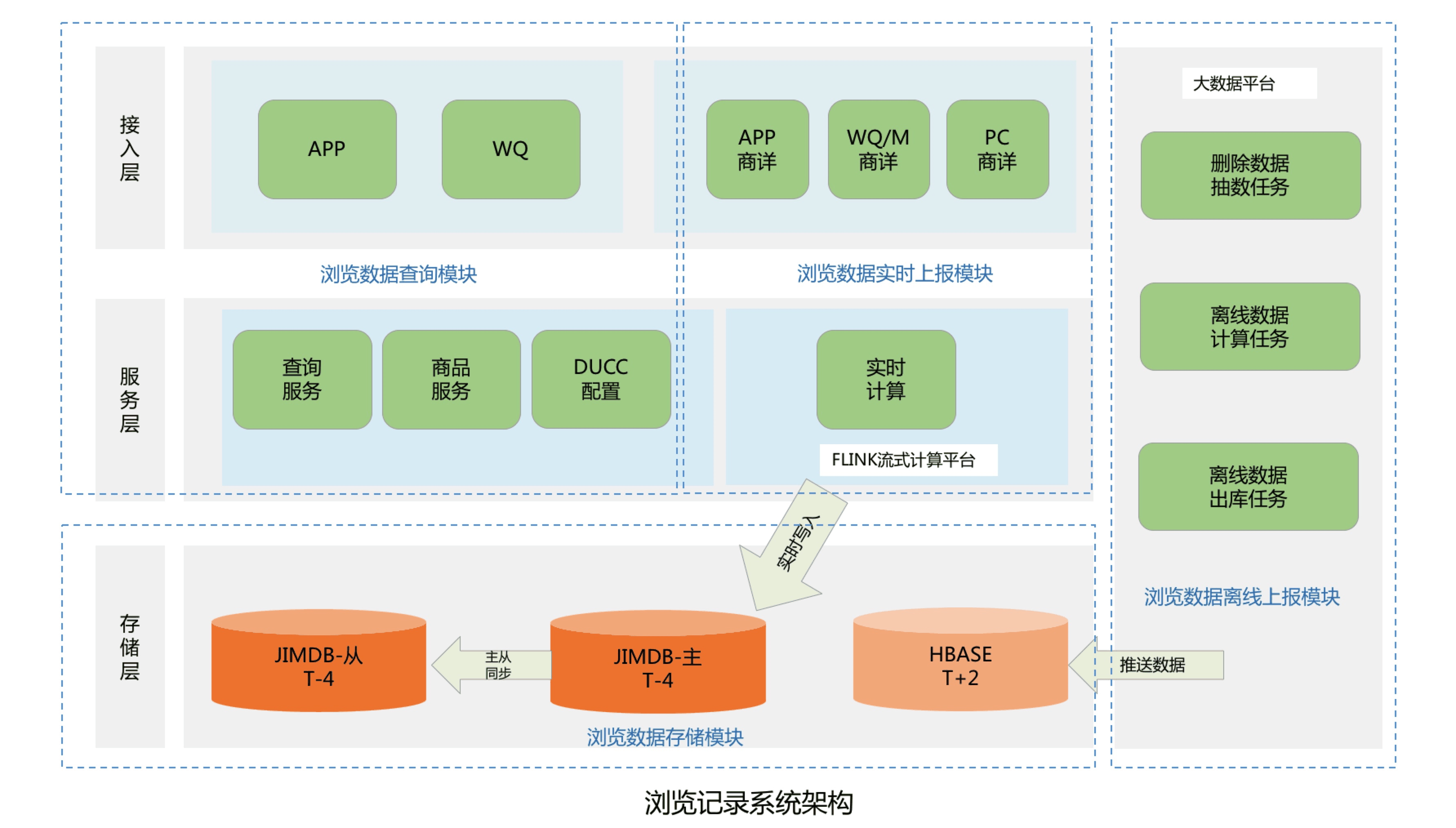
整个系统架构主要分为四个模块,包括浏览数据存储模块、浏览数据查询模块、浏览数据实时上报模块和浏览数据离线上报模块:
考虑到需要存储近千亿条的用户浏览记录,并且还要满足京东在线用户的毫秒级浏览记录实时存储和前台查询功能,我们将浏览历史数据进行了冷热分离。Jimdb纯内存操作,存取速度快,所以我们将用户的(T-4)浏览记录数据存储到Jimdb的内存中,可以满足京东在线活跃用户的实时存储和查询。而(T+4)以外的离线浏览数据则直接推送到Hbase中,存储到磁盘上,用来节省存储成本。如果有不活跃的用户查询到了冷数据,则将冷数据复制到Jimdb中,用来提高下一次的查询性能.
热数据采用了JIMDB的有序集合来存储用户的实时浏览记录,使用用户名做为有序集合的KEY,浏览商品SKU作为有序集合的元素,浏览商品的时间戳作为元素的分数,然后针对该KEY设置过期时间为4天.
这里的热数据过期时间为什么选择4天?
这是因为我们的大数据平台离线浏览数据都是T+1上报汇总的,等我们开始处理用户的离线浏览数据的时候已经是第二天,在加上我们自己的业务流程处理和数据清洗过滤过程,到最后推送到Hbase中,也需要执行消耗十几个小时。所以热数据的过期时间最少需要设置2天,但是考虑到大数据任务执行失败和重试的过程,需要预留2天的任务重试和数据修复时间,所以热数据过期时间设置为4天。所以当用户4天内都没有浏览新商品时,用户查看的浏览记录则是直接从Hbase中查询展示.
冷数据则采用K-V格式存储用户浏览数据,使用用户名作为KEY,用户浏览商品和浏览时间对应Json字符串做为Value进行存储,存储时需要保证用户的浏览顺序,避免进行二次排序。其中使用用户名做KEY时,由于大部分用户名都有相同的前缀,会出现数据倾斜问题,所以我们针对用户名进行了MD5处理,然后截取MD5后的中间四位作为KEY的前缀,从而解决了Hbase的数据倾斜问题。最后在针对KEY设置过期时间为62天,实现离线数据的过期自动清理功能.
查询服务模块主要包括三个微服务接口,包括查询用户浏览记录总数量,查询用户浏览记录列表和删除用户浏览记录接口.
1.如何解决限流防刷问题?
基于Guava的RateLimiter限流器和Caffeine本地缓存实现方法全局、调用方和用户名三个维度的限流。具体策略是当调用发第一次调用方法时,会生成对应维度的限流器,并将该限流器保存到Caffeine实现的本地缓存中,然后设置固定的过期时间,当下一次调用该方法时,生成对应的限流key然后从本地缓存中获取对应的限流器,该限流器中保留着该调用方的调用次数信息,从而实现限流功能.
2.如何查询用户浏览记录总数量?
首先查询用户浏览记录总数缓存,如果缓存命中,直接返回结果,如果缓存未命中则需要从Jimdb中查询用户的实时浏览记录列表,然后在批量补充商品信息,由于用户的浏览SKU列表可能较多,此处可以进行分批查询商品信息,分批数量可以动态调整,防止因为一次查询商品数量过多而影响查询性能。由于前台展示的浏览商品列表需要针对同一SPU商品进行去重,所以需要补充的商品信息字段包括商品名称、商品图片和商品SPUID等字段。针对SPUID字段去重后,在判断是否需要查询Hbase离线浏览数据,此处可以通过离线查询开关、用户清空标记和SPUID去重后的浏览记录数量来判断是否需要查询Hbase离线浏览记录。如果去重后的时候浏览记录数量已经满足系统设置的用户最大浏览记录数量,则不再查询离线记录。如果不满足则继续查询离线的浏览记录列表,并与用户的实时浏览记录列表进行合并,并过滤掉重复的浏览SKU商品。获取到用户完整的浏览记录列表后,在过滤掉用户已经删除的浏览记录,然后count列表的长度,并与系统设置的用户最大浏览记录数量做比较取最小值,就是该用户的浏览记录总数量,获取到用户浏览记录总数量后可以根据缓存开关来判断是否需要异步写入用户总数量缓存.
3.查询用户浏览记录列表 。
查询用户浏览记录列表流程与查询用户浏览记录总数量流程基本一致.
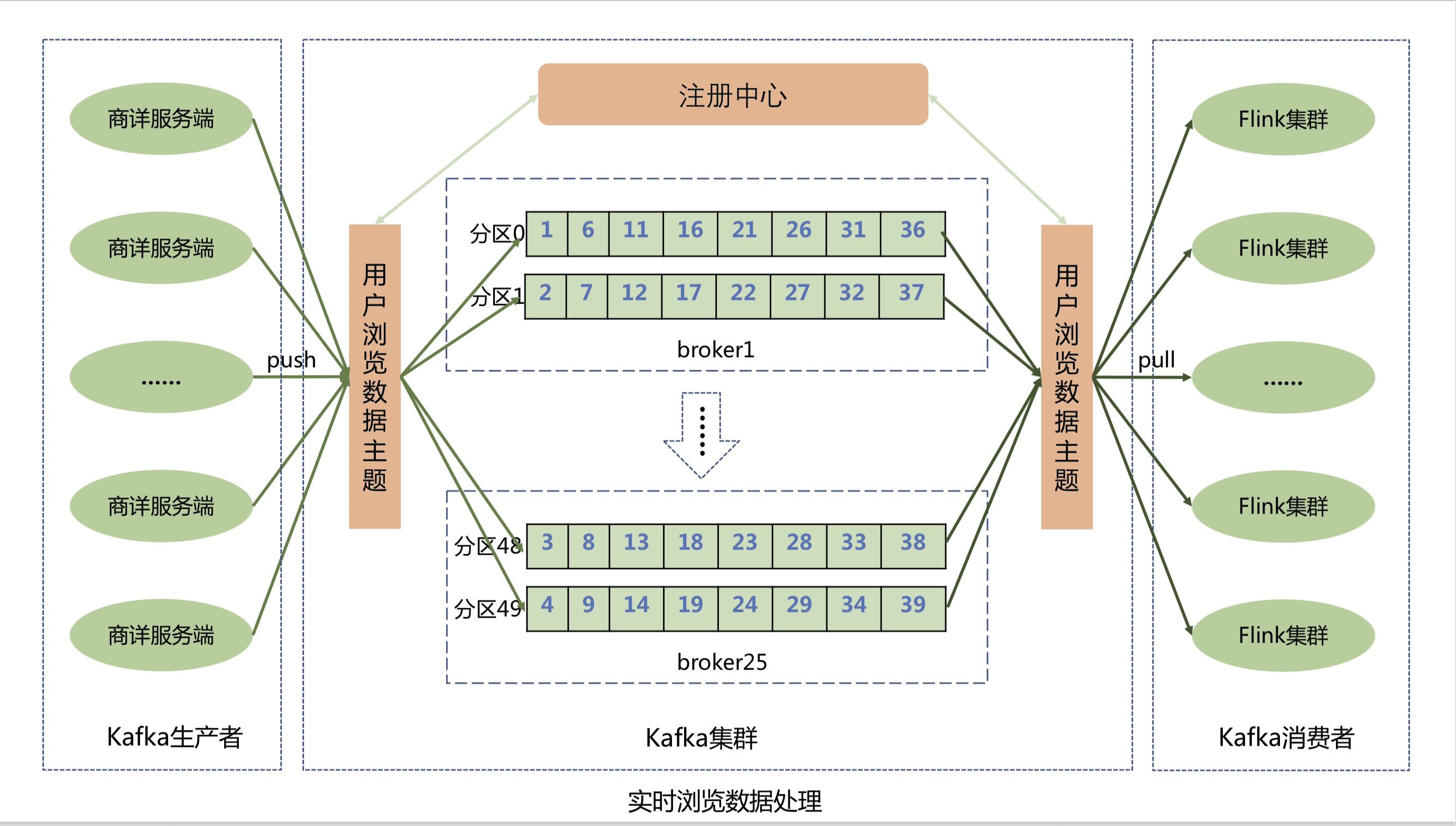
商详服务端将用户的实时浏览数据通过Kafka客户端上报到Kafka集群的消息队列中,为了提高数据上报性能,用户浏览数据主题分成了50个分区,Kafka可以将用户的浏览消息均匀的分散到50个分区队列中,从而大大提升了系统的吞吐能力.
浏览记录系统则通过Flink集群来消费Kafka队列中的用户浏览数据,然后将浏览数据实时存储到Jimdb内存中。Flink集群不仅实现了横向动态扩展,进一步提高Flink集群的吞吐能力,防止出现消息积压,还保证了用户的浏览消息恰好消费一次,在异常发生时不会丢失用户数据并能自动恢复。Flink集群存储实现使用Lua脚本合并执行Jimdb的多个命令,包括插入sku、判断sku记录数量,删除sku和设置过期时间等,将多次网络IO操作优化为1次.
为什么选择Flink流式处理引擎和Kafka,而不是商详服务端直接将浏览数据写入到Jimdb内存中呢?
首先,京东商城做为一个7x24小时服务的电子商务网站,并且有着5亿+的活跃用户,每一秒中都会有用户在浏览商品详情页,就像是流水一样,源源不断,非常符合分布式流式数据处理的场景.
而相对于其他流式处理框架,Flink基于分布式快照的方案在功能和性能方面都具有很多优点,包括:
第二,京东每天都会有很多的秒杀活动,比如茅台抢购,预约用户可达上百万,在同一秒钟就会有上百万的用户刷新商详页面,这样就会产生流量洪峰,如果全部实时写入,会对我们的实时存储造成很大的压力,并且影响前台查询接口的性能。所以我们就利用Kafka来进行削峰处理,而且也对系统进行了解耦处理,使得商详系统可以不强制依赖浏览记录系统.
这里为什么选择Kafka?
这里就需要先了解Kakfa的特性.
Kafka为什么这么快?
Kafka通过零拷贝原理来快速移动数据,避免了内核之间的切换.
Kafka可以将数据记录分批发送,从生产者到文件系统到消费者,可以端到端的查看这些批次的数据.
批处理的同时更有效的进行了数据压缩并减少I/O延迟.
Kafka采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费.
目前本系统已经经历多次大促考验,且系统没有进行降级,用户的实时浏览消息没有积压,基本实现了毫秒级的处理能力,方法性能TP999达到了11ms.
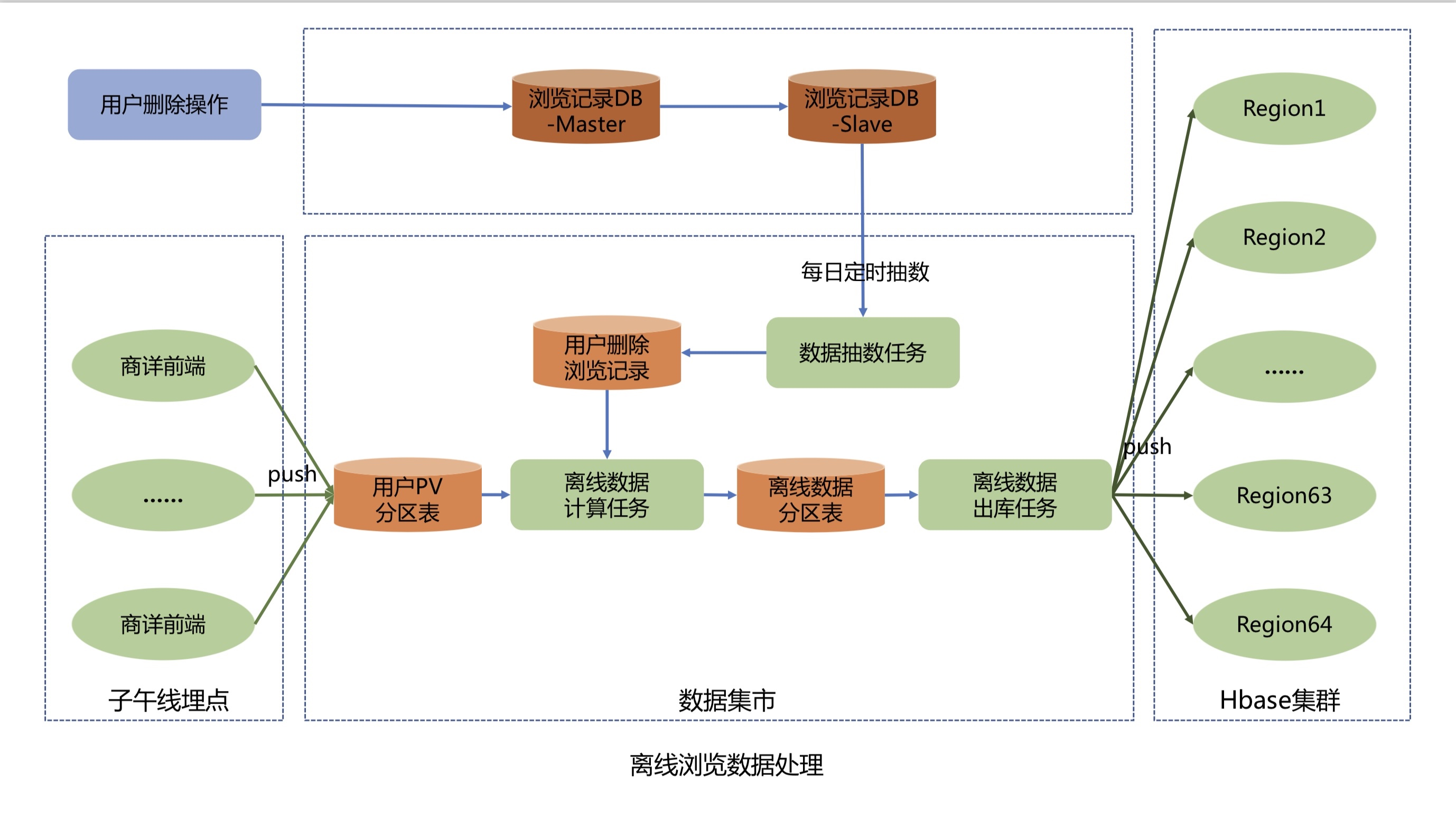
离线数据上报处理流程如下:
商详前端通过子午线的API将用户的PV数据进行上报,子午线将用户的PV数据写入到数据集市的用户PV分区表中.
数据抽数任务每天凌晨2点33分从浏览记录系统Mysql库的用户已删除浏览记录表抽数到数据集市,并将删除数据写入到用户删除浏览记录表.
离线数据计算任务每天上午11点开始执行,先从用户PV分区表中提取近60天、每人200条的去重数据,然后根据用户删除浏览记录表过滤删除数据,并计算出当天新增或者删除过的用户名,最后存储到离线数据分区表中.
离线数据出库任务每天凌晨2点从离线数据分区表中将T+2的增量离线浏览数据经过数据清洗和格式转换,将T+2活跃用户的K-V格式离线浏览数据推送到Hbase集群.
作者:京东零售 曹志飞 。
来源:京东云开发者社区 。
最后此篇关于百亿规模京东实时浏览记录系统的设计与实现的文章就讲到这里了,如果你想了解更多关于百亿规模京东实时浏览记录系统的设计与实现的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
32
4
 0
0
我遇到一个问题,即我的抓取工具正在跳过没有浏览引荐来源网址的浏览页面。我正在尝试解析 URL 中包含/browse/的所有页面,无论引用者如何。 以下是我的代码(根据 paul t 更新): from
我有4个屏幕。 X,A,B,C。导航模式应如下所示 这是代码 X 屏幕 class X extends StatelessWidget { @override Widget build(Bui
我想用 java 编写一个简单的网络浏览器,这是我的代码! import javax.swing.*; import java.io.*; import java.awt.*; import java
这个问题在这里已经有了答案: A home button in iOS 5, xcode 4.2, Story board (2 个回答) 8年前关闭。 来自 FirstView到SecondView
我使用 C#/ASP.Net 在 IIS7 中创建虚拟目录,以便外部人员可以浏览各种文档。 一切看起来都不错,除了浏览是一种沉闷的文本格式。当他们浏览到文件夹时,我如何创建更多的“Windows 资源
我想我在 Chrome 或 Internet Explorer 中见过 Gmail 这样做,但我从未在 Firefox 中见过它。我想我还是会问一下。是否可以在不需要的情况下进行文件上传?我看到你可以
我是 Java 的新手,作为第一次阅读,我阅读了几本有关 Java 语言的书籍。 我有几个关于 Java 文档的问题。如何“导航”它们?是否可以仅使用 Javadoc 来学习新概念? 这是一个示例 -
我有一个解析网络,现在我想浏览标签,或显示图表。我怎样才能得到图表?或者在树中导航。显示第一步然后其他等。并了解这棵树是如何 build 的。 import urllib from lxml impo
考虑以下情况: 杀戮戒指中的 N 项。需要拉取的项目是项目#k 数值论证解决方案不会真正起作用,因为计算或跟踪杀死环中事物的位置很烦人。 最佳答案 实际问题是什么?按 C-y 然后按 M-y k 次有
这是我之前的 question 的后续。 我试图从 here 了解 Haskell 中的列表拆分示例: foldr (\a ~(x,y) -> (a:y,x)) ([],[]) 我可以阅读 Haske
是否有任何 vim 工具通过 Latex 文档结构提供有效的导航。拥有像 NERDTree 面板这样的东西来表示 latex 文档的部分/子部分结构会非常有用。 最佳答案 扩展 mnosefishs
您好,我的应用程序中有一个模态视图 Controller ,当按下某个按钮时,该 Controller 会消失,并且其中带有 UITableView 的 View 会使用导航 Controller 滑
Glances v2.11.1 with psutil v5.4.3 /usr/lib/python3.6/site-packages/psutil/_pslinux.py:1152: Runtime
我正在使用 Eclipse,我希望我可以通过按 STRG 在以驼峰式书写的单词之间跳转。现在我正在使用 Sublime,我找不到这样做的快捷方式,也找不到实现它的插件。 下面的例子说明了我的问题 aF
我的主程序提示用户浏览文件以便使用 ffmpeg 进行转换。这是文件浏览的格式: 1. Select audio file for conversion ( mp3, wma):
我正在尝试浏览 SVN 存储库,而不必检查它: 是否可以在本地(Unix 上)执行此操作? 这可以通过 ssh 访问实现吗? 最佳答案 svn ls 有效。例如 svn ls http://my.sv
我有一个网站,其中列出了数据库中的企业列表。在每个页面上,您可以执行不同的操作,例如将其转发给 friend 、打印页面等。我的问题是我可以使用谷歌分析来跟踪每个列表的展示次数和浏览次数吗?因此,如果
在 Dart 我有一个嵌套的元素列表 void main() { var diction = {'1':'Alpha','2':'Beta','3':{'x':'Football','y':'
当我们的用户单击网页上的浏览按钮来上传任何文件时,我想更改窗口位置。我会给你一个场景 - 我的 html 表单上有一个浏览按钮,当用户单击一个弹出窗口时,该位置默认为“我的文档”。 实际上我想在单击“
关闭。此题需要details or clarity 。目前不接受答案。 想要改进这个问题吗?通过 editing this post 添加详细信息并澄清问题. 已关闭 9 年前。 Improve th

我是一名优秀的程序员,十分优秀!