
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 38
38
 4
4


现有主流消息中间件都是生产者-消费者模型,主要角色都是:Producer -> Broker -> Consumer,上手起来非常简单,但仍有需要知识点需要我们关注,才能避免一些错误的使用情况,或者使用起来更加高效,例如本篇要讲的kafka分区分配策略。 在开始前我们先简单回顾一下kafka消息存储设计,如下图:
topic是一个逻辑概念,一个topic可以包含多个partition,partition才是物理概念,kafka将partition存储在broker磁盘上。如图,test_topic只有一个partition,那么在broker上就会一个test_topic-0的文件夹。在partition内部,kafka为方便管理和高效处理消息,进一步将消息的存储划分为多个segment,segment也是个逻辑概念,一个segment下主要包含:.log消息日志文件,存储实际消息的地方,.index索引文件,.timeindex时间索引文件。segment是滚动的,当达到配置的大小或者时间,kafka就会重新创建一个新的segment,并且会在一定的时间后将过期的segment删除.
其中每一个部分都是一个大的知识点,本次我们主要关注partition。一个partition会分配给一个consumer group中的一个consumer消费,partition是可扩展的,这为kafka消息消费提供强大扩展能力,如上只有一个patition,那么所有的消息都会发到这里,并且只能由一个消费者消费,这无疑会很慢。我们可以创建两个partition,然后起两个消费者,这样kafka就会为每个消费者分配一个分区,它们可以并发消费,消费速度得以提升。 那如果有3个partition呢,这个时候是怎么分的?如果有多个topic呢,这个时候又是怎么分的?如果有consumer上下线,又是怎么分呢?这就是我们接下来要讨论分区分配策略.
在开始讨论分区分配策略之前,我们先了解一下rebalance这个概念。rebalance重平衡,是指在一定情况下,kafka将分区重新分配的过程。正常情况下我们的服务起来,分区分配好后,就稳定运行了,但一些情况下会导致kafka进行rebalance,将分区都重新分配一遍,这种情况主要包括:
举个例子,我们滚动发版,必然有的应用要先下线,再重新上线,这个时候对于kafka来说消费者就发生了变化,就会发生rebalance,rebalance也是按照我们配置的分区分配策略进行重新分配。 分区分配策略作用是将所有topic的partition按照一定规则分配给消费者,主要有4种分区分配策略,它们都实现了ConsumerPartitionAssignor接口,也可以实现该接口自定义分区分配算法.

分区的分配很容易会想到是有kafka server端计算和分配的,但其实不是,当触发分区分配时,kafka会从consumer中挑选一个作为leader,leader根据客户端配置的分配策略计算分区结果,然后发送回给kafka,再由kafka同步给其它的consumer follower.
举个例子,新增了一个消费者,rebalance过程大致如下: 该消费者发送一个请求告诉kafka,要加入消费者组。 kafka将消费者组状态切换到准备rebalance,关闭和消费者的所有链接,等待它们重新加入。 客户端重新申请加入,kafka从消费者组中挑选一个作为leader,其它的作为follower。 kafka将一些元信息同步给所有消费者。 follower不断发送请求给kafka,请求它们的partition。 leader根据分区分配策略计算分区结果,并将结果返回给kafka。 kafka将计算结果返回给follower。 所有消费者根据分区结果开始消费消息.
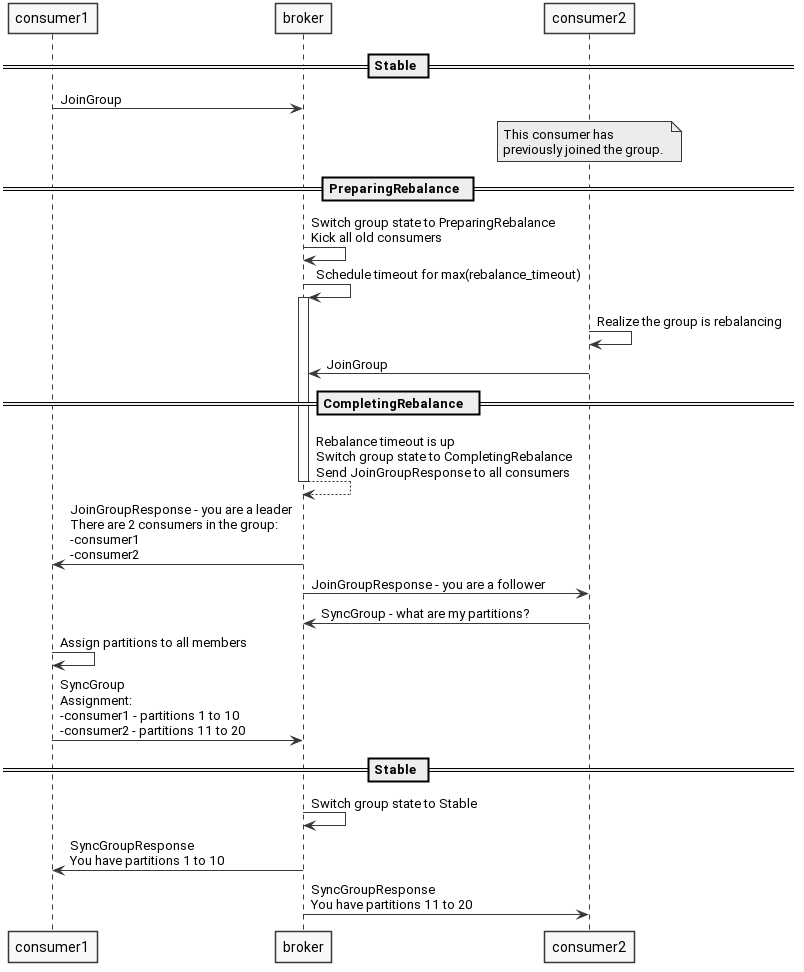
注意,rebalance的发生不是个好事情,kafka需要重新计算分区信息,重新分配,清理资源,当你的集群比较大的时候,频繁rebalance可能会影响性能.
范围分配,按照每个topic的partition数计算出每个消费者应该分配的分区数量,然后分配。 假设有2个topic,每个topic有2个分区,如下:
T0:P00,P01
T1:P10,P11
有两个消费者C0,C1,那么range分配结果如下:
C0:P00,P10
C1:P01,P11
看起来很顺畅,也很均衡,但如果T0新增一个P02呢,那么分配就会如下:
C0:P00,P01,P10
C1:P02,P11
看起来也还好,毕竟两个人分3个苹果,会有人多一个。那如果T1也新增一个P12呢,那么分配就会如下:
C0:P00,P01,P10,P11
C1:P02,P12
看起来好像不怎么好了,C0又多了一个分区,如果有更多的topic有这种情况,那么C0的压力无疑会比C1大很多。 这是由于range分配是按照每个topic来计算的,这可能会导致consumer的分配不均匀.
循环分配,按照所有topic的partition循环分配。 假设有2个topic,每个topic有2个分区,如下:
T0:P00,P01
T1:P10,P11
有两个消费者C0,C1,那么循环分配结果如下:
C0:P00,P10
C1:P01,P11
如果T0新增一个P02呢,那么分配就会如下:
C0:P00,P02,P10
C1:P01,P11
如果T1也新增一个P12呢,那么分配就会如下:
C0:P00,P02,P11
C1:P01,P10,P12
和range不同这里每个消费者分到的分区数还是相等的。按照循环分配逻辑,消费者分配到分区数偏差不会超过1.
range和roundrobin的问题是,当发生rebalance的时候,分区的分配结果变化会很大,理想情况是分配结果不要有很大变化,例如消费者可能根据partition做了本地缓存,分配结果都变了相当于缓存都失效了,可能对消费者会有影响。所有有了StickAssignor,粘性分配,从字面理解,粘性分配就是原本是你的,还是尽量分配给你,例如发生rebalance的时候。粘性分配的核心思想是优先保证分区分配均衡,然后尽可能保留现有的分配结果.
假设有3个topic,每个topic有3个分区,如下:
T0:P00,P01,P02
T1:P10,P11,P12
T2:P20,P21,P22
有3个消费者C0,C1,C2,那么roundrobin分配结果如下:
C0:P00,P10,P20
C1:P01,P11,P21
C2:P02,P12,P22
假设C2下线了,触发了rebalance,roundrobin重新分配结果如下:
C0:P00,P02,P11,P20,P22
C1:P01,P10,P12,P21
可以看到T0,T1的也重新分配了,有4个partition重新分配了。如果使用sticky分配,结果就会是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
可以看到,T0,T1的没有任何变化,还是原来的消费者,这就是粘性的含义.
上面的3种分配策略使用的都是eager协议,eager协议的特点是整个rebalance会"stop the world",消费者会放弃当前的分区,关闭连接,资源清理,然后静静等待分配结果。 CooperativeStickAssignor是2.4版本开始提供的,使用的cooperative协议,在sticky的基础上,优化rebalance过程,可以从RebalanceProtocol源码中看到这两个协议的解释:
ConsumerPartitionAssignor接口默认就指定了eager协议,如图:
CooperativeStickAssignor重写了这个协议,使用cooperative,如图:
还是上面的例子,假设C2下线了,触发了rebalance,使用sticky分配,结果就会是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
看起来和sticky并没有什么区别,毕竟它们都是sticky,但实际过程上有很大的差别,sticky会先放弃所有的分区,清理数据,然后再重新分配,整个过程较复杂耗时,而coopertive则比较轻量,首先会将原来的分区分配给原来的持有者,再rebalance重新分配P20,P21,P22分区。 关于eager、cooperative协议可以参考这篇文章: https://www.cnblogs.com/listenfwind/p/14146727.html 。
这4种分区分配策略是可以配置的,客户端通过partition.assignment.strategy参数进行设置,默认是RangeAssignor.
欢迎关注我的github: https://github.com/jmilktea/jtea 。
最后此篇关于kafka分区分配策略的文章就讲到这里了,如果你想了解更多关于kafka分区分配策略的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
38
4
 0
0
是一种在 Neo4j 分区之间进行物理分离的方法吗? 这意味着以下查询将转到 node1: Match (a:User:Facebook) 虽然此查询将转到另一个节点(可能托管在 docker 上)
我尝试在我的 SQL 服务器上使用分区函数对我的一个大表进行分区,但我收到一条错误消息 “只能在SQL Server企业版中创建分区功能。只有SQL Server企业版支持分区。” 所以我想知道没有企
在hadoop文件系统中,我有两个文件,分别是X和Y。通常,hadoop制作的文件X和Y的大小为64 MB。是否可以强制hadoop划分两个文件,以便从X的32 MB和Y的32 MB中创建一个64 M
据我了解,如果我们有一个主键,则使用该键对数据进行分区并将其存储在节点中(例如使用随机分区器)。 现在我不确定的是,如果我有多个键(又名复合键),是用于分区数据的键的组合还是它将是第一个主键? 例如,
我正在向我的 SSAS 多维数据集添加分区,我想知道是否有多个分区可以保留在下面?多少太多了,最佳实践限制是 20 还是 200?有没有人可以分享任何真实世界的知识? 最佳答案 这是 another
我有一个包含大约 200 万条记录的大表,我想对其进行分区。 我将 id 列设置为 PRIMARY AUTO_INCRMENT int (并且它必须始终是唯一的)。我有一列“theyear”int(4
我正在做 mysql 列表分区。我的表数据如下 ---------------------------------------- id | unique_token | city | student_
我有一个表,我们每天在其中插入大约 2000 万个条目(没有任何限制的盲插入)。我们有两个外键,其中一个是对包含大约 1000 万个条目的表的引用 ID。 我打算删除此表中超过一个月的所有数据,因为不
我想在一款足球奇幻游戏中尝试使用 MySQL Partitioning,该游戏的用户分布在联赛中,每个联赛都有一个用户可以买卖球员的市场。当很多用户同时玩时,我在这张表中遇到了一些僵局(在撰写本文时大
我是 jQuery 的新手,想知道是否可以获取一些变量并将它们的除法作为 CSS 宽度。到目前为止我在这里: var x = $(".some-container").length; var y =
所以我正在做家庭作业,我需要为分区、斯特林数(第一类和第二类)和第一类的切比雪夫多项式创建递归函数。我的程序应该能够让用户输入一个正整数 n,然后创建名为 Partitions.txt、Stirlin
我在数据框中有一列,其中包含大约 1,4M 行聊天对话,其中每个单元格中的一般格式为 (1): “名称代理 : 对话” 但是,并非列中的所有单元格都采用这种格式。有些单元格只是 (2): “对话” 我
我在尝试隐藏 a 时遇到了一些问题,直到用户单击某个元素为止。 HTML 看起来像: BRAND item 1 item 2 item 3
一.为什么kafka要做分区? 因为当一台机器有可能扛不住(类比:就像redis集群中的redis-cluster一样,一个master抗不住写,那么就多个master去抗写)
我有一些销售数据,我需要发送存储在单独表中的可用槽中的数量。 销售数据示例: id数量112131415369 create table sales (id serial primary key, q
我计划设置多个节点以使用 glusterfs 创建分布式复制卷 我使用主(也是唯一)分区上的目录在两个节点上创建了一个 gluster 复制卷。 gluster volume create vol_d
我正在尝试使用 sum() over (partition by) 但在总和中过滤。我的用例是将每个产品的 12 个月累计到一个月的条目,因此: ITEM MONTH SALES Item
是否可以创建多个 Enumerators出单Enumerator ? 我正在寻找的相当于 List.partition返回 (List[A], List[A]) ,比如 List().partitio
我正在创建一个基于 x86 的非常简单的 Yocto 图像。 我希望/文件系统是只读的,所以我设置了 IMAGE_FEATURES_append = " read-only-rootfs " 在原件的
是否可以使用一次 collect 调用来创建 2 个新列表?如果没有,我该如何使用分区来做到这一点? 最佳答案 collect(在TraversableLike上定义并在所有子类中可用)与集合和Par

我是一名优秀的程序员,十分优秀!