
 个人中心
个人中心 文章发布
文章发布
作者热门文章
- Java锁的逻辑(结合对象头和ObjectMonitor)
- 还在用饼状图?来瞧瞧这些炫酷的百分比可视化新图形(附代码实现)⛵
- 自动注册实体类到EntityFrameworkCore上下文,并适配ABP及ABPVNext
- 基于Sklearn机器学习代码实战



 25
25
 4
4


这里分类和汇总了欣宸的全部原创(含配套源码): https://github.com/zq2599/blog_demos 。
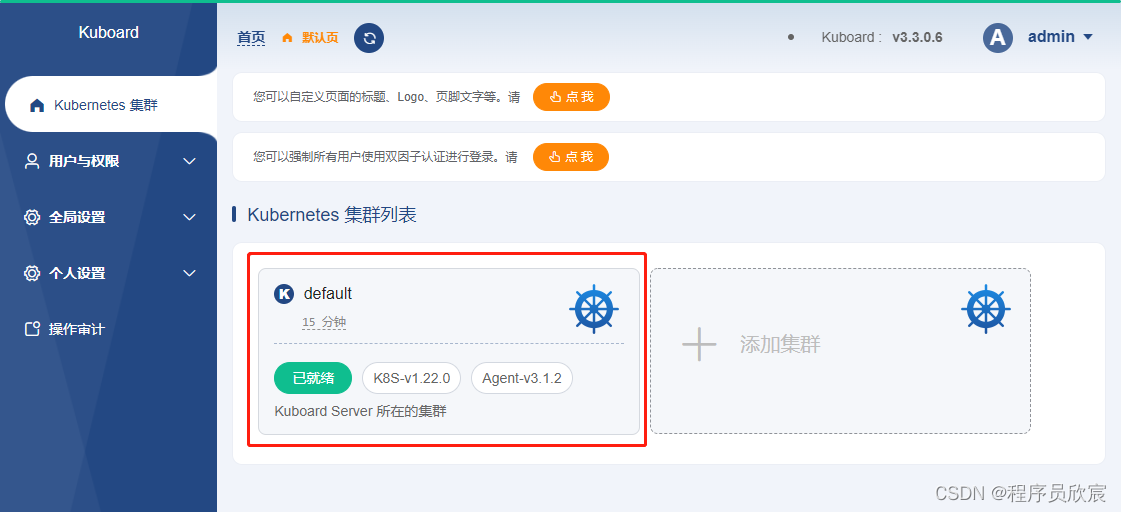
标题敢号称 极速 ,是因为使用了开源项目 sealos ,正是因为sealos,原本繁琐复杂的kubernetes部署操作变得简单高效 。
sealos是个热门开源项目,地址是: https://github.com/fanux/sealos,官方说明容易引发读者的舒适感:
sealos提供的免费部署版本是 kubernetes-1.22.0 ,其余版本虽然支持,但不在免费范围内 。
本次实战使用三台64位X86服务器,操作系统都是 CentOS-7.9.2009 ,基本情况如下表:
| 主机名 | IP地址 | 角色 | 配置 |
|---|---|---|---|
| master | 192.168.95.138 | 主控节点 | 2核2G |
| node0 | 192.168.95.139 | 工作节点 | 4核8G |
| node1 | 192.168.95.140 | 工作节点 | 4核8G |
yum install redhat-lsb lrzsz wget -y
systemctl stop firewalld && \
systemctl disable firewalld && \
setenforce 0
wget -c https://sealyun.oss-cn-beijing.aliyuncs.com/latest/sealos && \
chmod +x sealos && \
mv sealos /usr/bin
wget -c https://sealyun.oss-cn-beijing.aliyuncs.com/05a3db657821277f5f3b92d834bbaf98-v1.22.0/kube1.22.0.tar.gz
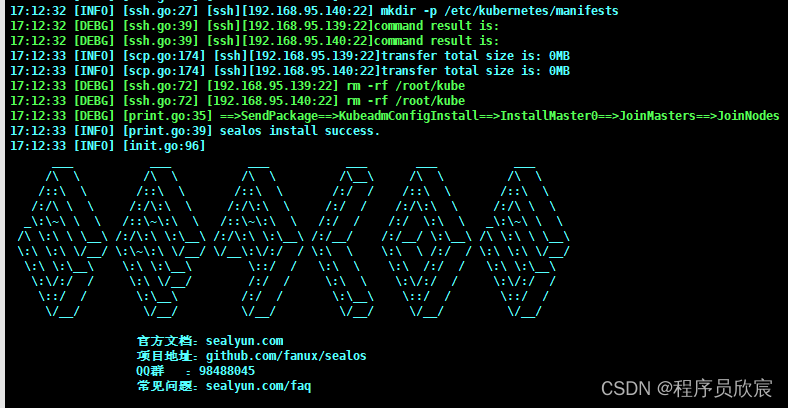
sealos init --passwd '888888' \
--master 192.168.95.138 \
--node 192.168.95.139 --node 192.168.95.140 \
--pkg-url /root/kube1.22.0.tar.gz \
--version v1.22.0

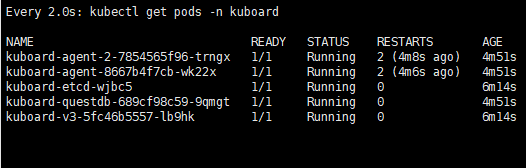
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
watch kubectl get pods -n kuboard
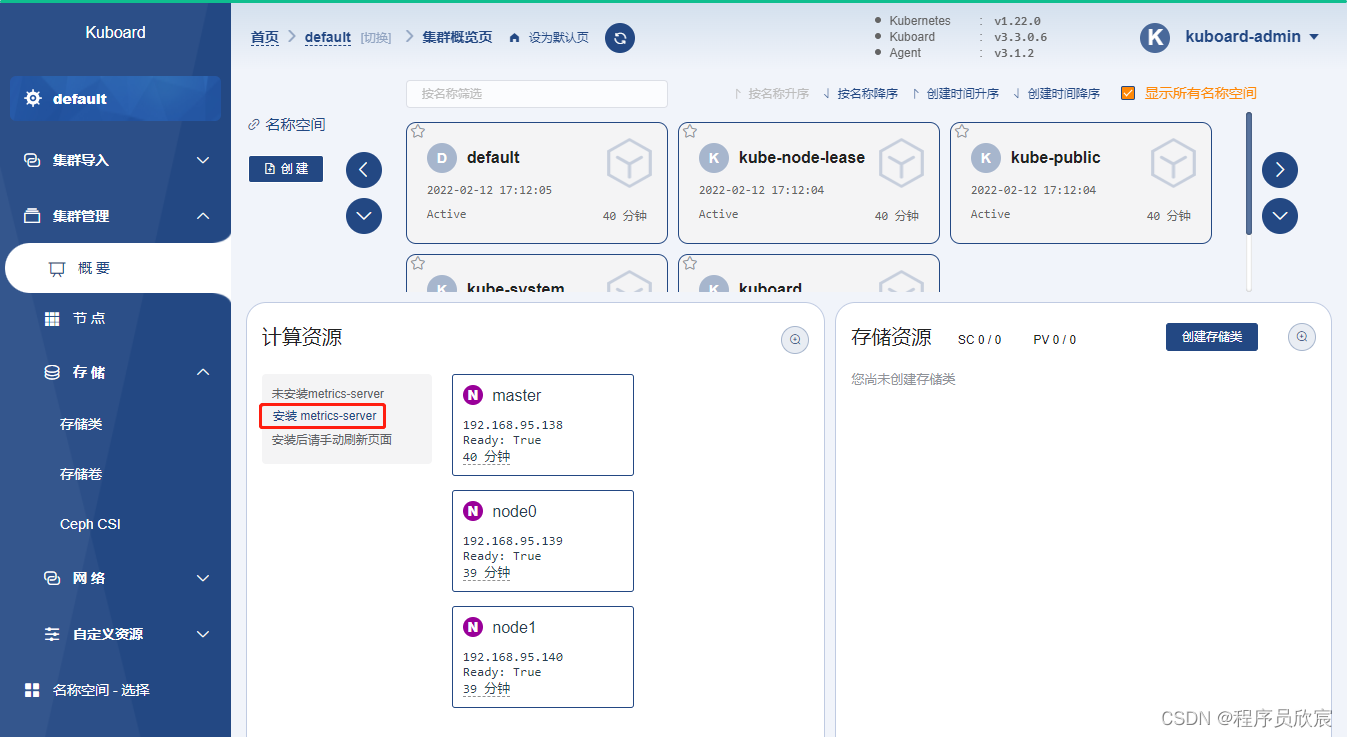
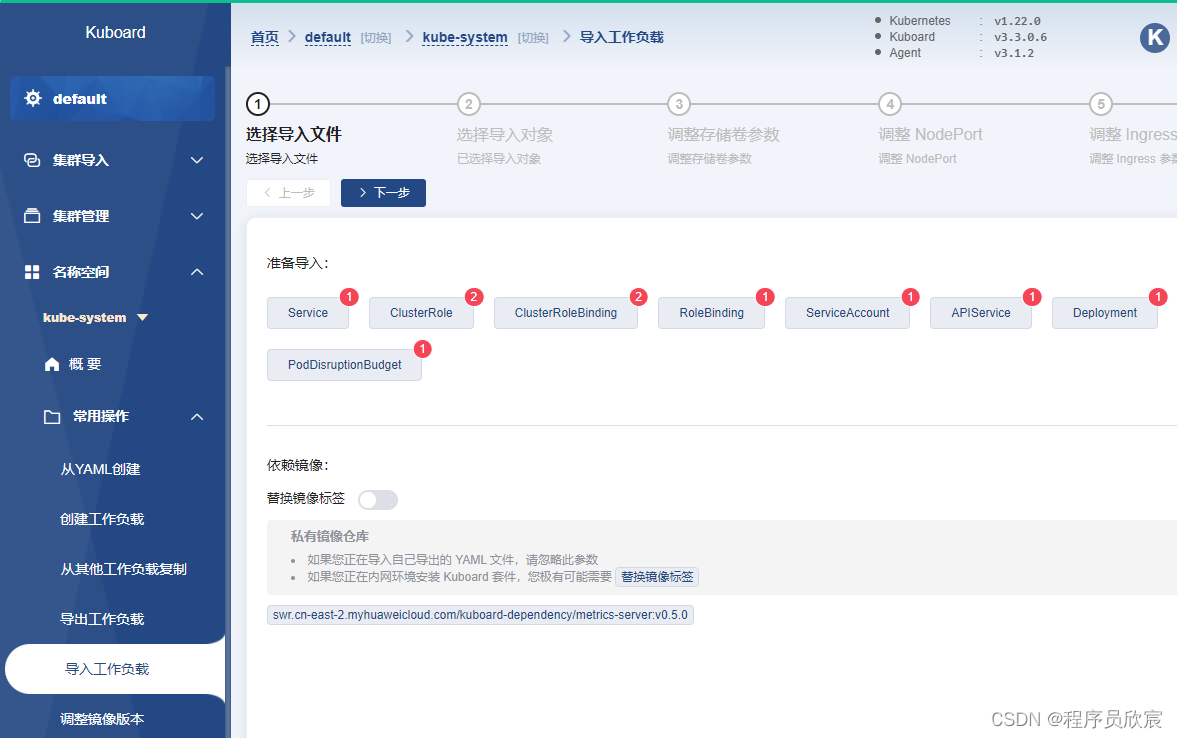
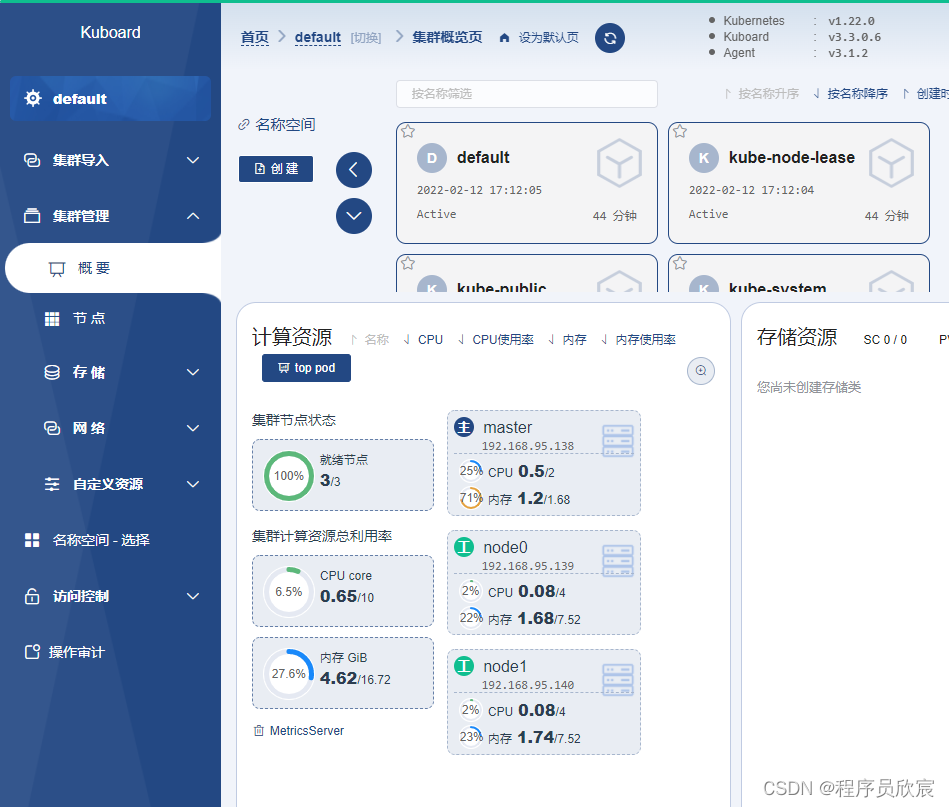
学习路上,你不孤单,欣宸原创一路相伴... 。
最后此篇关于极速安装kubernetes-1.22.0(三台CentOS7服务器)的文章就讲到这里了,如果你想了解更多关于极速安装kubernetes-1.22.0(三台CentOS7服务器)的内容请搜索CFSDN的文章或继续浏览相关文章,希望大家以后支持我的博客! 。
25
4
 0
0
core@core-1-94 ~ $ kubectl exec -it busybox -- nslookup kubernetesServer: 10.100.0.10Address 1: 1
我有一个节点错误地注册在集群 B 上,而它实际上为集群 A 服务。 这里“在集群 B 上注册”意味着我可以从 kubectl get node 看到节点来自集群 B。 我想从集群 B 中取消注册这个节
据我所知,Kubernetes 是一个用于部署和管理容器的编排框架。另一方面,Kubernetes Engine 负责集群的伸缩,以及管理容器镜像。 从上面看,它们似乎是同一件事或非常相似。从上面的定
我正在学习 Kubernetes 和 Docker,以启动一个简单的 Python 网络应用程序。我对上述所有技术都不熟悉。 下面是我计划的方法: 安装 Kubernetes。 在本地启动并运行集群。
我了解如何在 kubernetes 中设置就绪探测器,但是是否有任何关于在调用就绪探测器时微服务应实际检查哪些内容的最佳实践?两个具体例子: 一个面向数据库的微服务,如果没有有效的数据库连接,几乎所有
Kubernetes 调度程序是仅根据请求的资源和节点在服务器当前快照中的可用资源将 Pod 放置在节点上,还是同时考虑节点的历史资源利用率? 最佳答案 在官方Kubernetes documenta
我们有多个环境,如 dev、qa、prepod 等。我们有基于环境的命名空间。现在我们将服务命名为 environment 作为后缀。例如。, apiVersion: apps/v1
我有一个关于命名空间的问题,并寻求您的专业知识来消除我的疑虑。 我对命名空间的理解是,它们用于在团队和项目之间引入逻辑边界。 当然,我在某处读到命名空间可用于在同一集群中引入/定义不同的环境。 例如测
我知道角色用于授予用户或服务帐户在特定命名空间中执行操作的权限。 一个典型的角色定义可能是这样的 kind: Role apiVersion: rbac.authorization.k8s.io/v1
我正在学习 Kubernetes,目前正在深入研究高可用性,虽然我知道我可以使用本地(或远程)etcd 以及一组高可用性的控制平面(API 服务器、 Controller 、调度程序)来设置minio
两者之间有什么实际区别?我什么时候应该选择一个? 例如,如果我想让我的项目中的开发人员仅查看 pod 的日志。似乎可以通过 RoleBinding 为服务帐户或上下文分配这些权限。 最佳答案 什么是服
根据基于时间的计划执行容器或 Pod 的推荐方法是什么?例如,每天凌晨 2 点运行 10 分钟的任务。 在传统的 linux 服务器上,crontab 很容易工作,而且显然在容器内部仍然是可能的。然而
有人可以帮助我了解服务网格本身是否是一种入口,或者服务网格和入口之间是否有任何区别? 最佳答案 “入口”负责将流量路由到集群中(来自 Docs:管理对集群中服务的外部访问的 API 对象,通常是 HT
我是 kubernetes 集群的新手。我有一个简单的问题。 我在多个 kubernetes 集群中。 kubernetes 中似乎有多个集群可用。所以 kubernetes 中的“多集群”意味着:
我目前正在使用Deployments管理我的K8S集群中的Pod。 我的某些部署需要2个Pod /副本,一些部署需要3个Pod /副本,而有些部署只需要1个Pod /副本。我遇到的问题是只有一个 po
我看过官方文档:https://kubernetes.io/docs/tasks/setup-konnectivity/setup-konnectivity/但我还是没明白它的意思。 我有几个问题:
这里的任何人都有在 kubernetes 上进行批处理(例如 spring 批处理)的经验?这是个好主意吗?如果我们使用 kubernetes 自动缩放功能,如何防止批处理处理相同的数据?谢谢你。 最
我有一个具有 4 个节点和一个主节点的 Kubernetes 集群。我正在尝试在所有节点中运行 5 个 nginx pod。目前,调度程序有时在一台机器上运行所有 pod,有时在不同的机器上运行。 如
我在运行 Raspbian Stretch 的 Raspberry PI 3 上使用以下命令安装最新版本的 Kubernetes。 $ curl -s https://packages.cloud.g
container port 与 Kubernetes 容器中的 targetports 有何不同? 它们是否可以互换使用,如果可以,为什么? 我遇到了下面的代码片段,其中 containerPort

我是一名优秀的程序员,十分优秀!